
[B5'] Smooth Adversarial Training
Bài đăng này đã không được cập nhật trong 5 năm
Đây là một bài trong series Báo khoa học trong vòng 5 phút.
Nguồn
Được viết bởi Xie et. al, John Hopkins University, trong khi đang intern tại Google. Hiện vẫn là preprint do bị reject tại ICLR 2021.
https://arxiv.org/abs/2006.14536
Là top 1 method trong 1 task Adversarial Defense trên Papers With Code.
Các bạn có thể đọc qua trước bài này của mình về tấn công và phòng thủ trong học máy để có các khái niệm cơ bản trong mảng này.
Ý tưởng chính
TL;DR:
Sử dụng các hàm kích hoạt mượt (liên tục cả hàm và cả ở đạo hàm bậc nhất) sẽ làm giảm khả năng bị tấn công do chất lượng đạo hàm tốt lên.
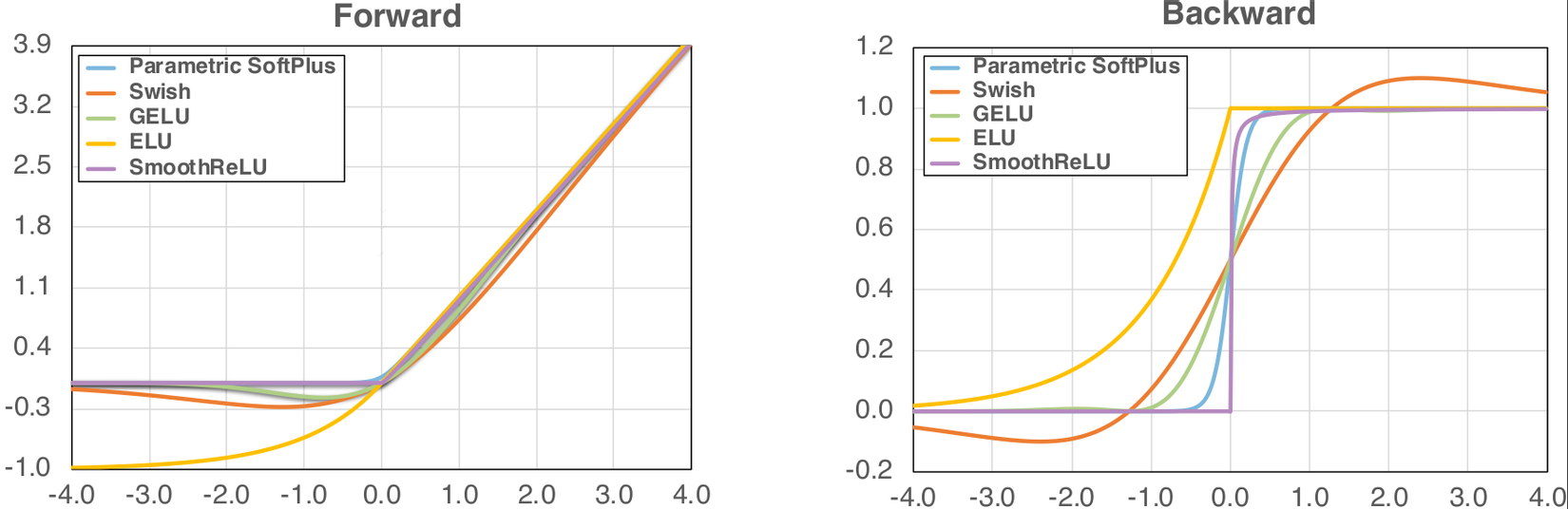
- Vấn đề của adversarial vulnerabilities nằm ở gradient chất lượng thấp — bị gãy tại 0 với ReLU. Vì vậy, tác giả đề xuất sử dụng các hàm kích hoạt mượt thay thế cho ReLU như Parametric Softplus, ELU, GELU, v.v.
- (Parametric) Softplus: , trong đó bản không parametric có , và thí nghiệm sử dụng .
- Swish: , trong đó là hàm sigmoid.
- Gaussian Error Linear Unit (GELU): , trong đó là hàm cumulative distribution function (CDF) của phân phối chuẩn tắc ()
- Exponential Linear Unit (ELU): .
- Trong thí nghiệm, tác giả sử dụng PGD-AT trong với các hàm kích hoạt kể trên, và cho thấy khi sử dụng SmoothReLU và GELU cao hơn ~10% so với khi sử dụng ReLU và ELU (bị gãy khi ).
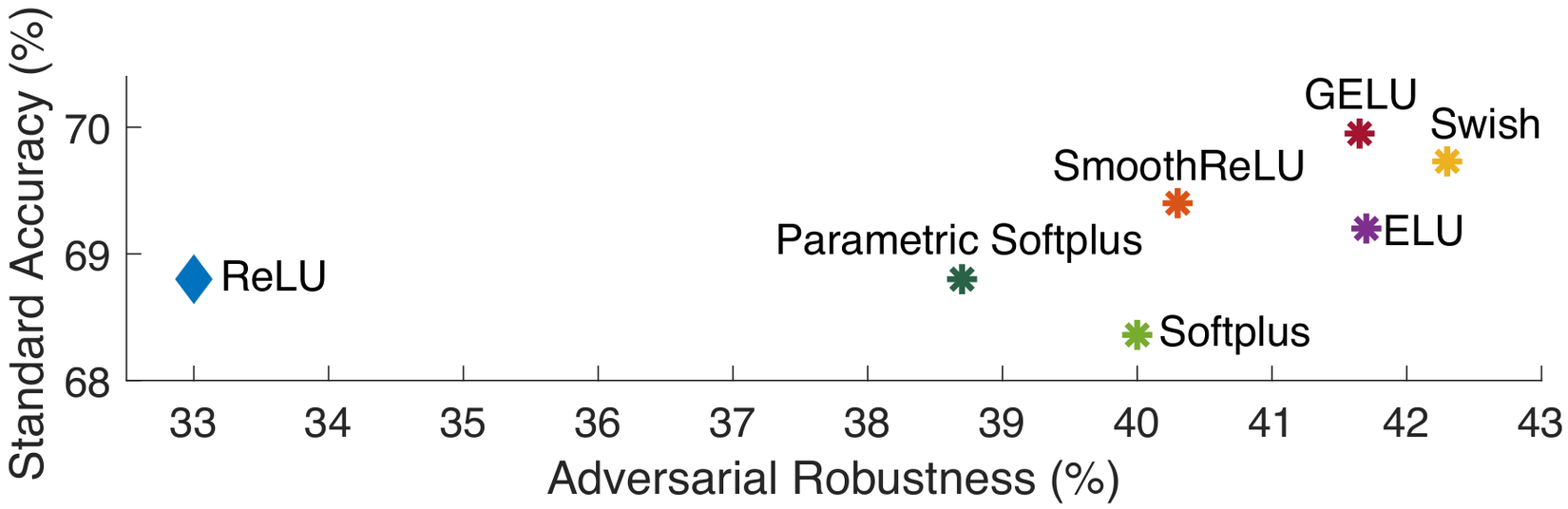
Cuối cùng, tác giả chọn sử dụng Swish do cho kết quả cao nhất.
Thí nghiệm chứng minh tác dụng của hàm kích hoạt mượt:
- Trong quá trình PGD-AT, mô hình được huấn luyện với adversarial example thay vì data thật. Tác giả sử dụng PGD-1 (chạy 1 iteration, tương tự với FGSM) trong quá trình training.
- Tác giả thí nghiệm với việc sử dụng hàm kích hoạt mượt chỉ trong bước backprop, nhưng khi forward pass vẫn sử dụng ReLU. Phương pháp đó được thử với bước sinh dữ liệu adversarial để training (gọi là inner maximization step), và bước huấn luyện mô hình trên dữ liệu đó (outer minimization step), và xem kết quả. Cụ thể, kết quả trở nên tốt hơn khi sử dụng các hàm kích hoạt mượt trong cả 2 bước:

Tuy nhiên, thiết kế mô hình cuối cùng của tác giả sử dụng hàm kích hoạt mượt trong toàn bộ quá trình thay vì chỉ sử dụng trong bước backprop.
Các thí nghiệm khác:
- Tác giả thử các phương pháp khác để giảm vấn đề adversarial vulnerability:
- Bước tạo PGD training example kỹ hơn bằng cách sử dụng PGD-2: có tăng adversarial robustness
- Training lâu hơn: adversarial robustness bị giảm (như paper Robust Overfitting có nói, paper này không cite paper kia)
- Tác giả sử dụng CELU, phiên bản mượt của ELU, thay thế cho ELU trong quá trình training, do ELU bị gãy khi (nhưng CELU thì không). Kết quả cho thấy ELU chỉ hoạt động tốt khi , còn CELU hoạt động tốt với mọi giá trị của .
- Tác giả thử thay đổi cấu trúc ResNet để xem ảnh hưởng:
- Tăng độ phức tạp: tăng adversarial robustness
- Tăng kích cỡ ảnh đầu vào: tăng adversarial robustness
- Tăng cả 2 cái trên: đương nhiên là tăng adversarial robustness
- Tác giả sử dụng quá trình training với cả ResNet và EfficientNet, và kết quả tốt lên như dự đoán với cả 2 mô hình.
Nhận xét
- Đơn giản, dễ chơi, dễ trúng thưởng.
- Kết quả tốt (duh)
- Thí nghiệm sử dụng PGD yếu (chỉ sử dụng PGD-1)
- Hiện tượng robust overfitting đã được phát hiện từ trước tầm 4 tháng, nên có thể literature survey bị hụt.
Hết.
Hãy like và subscribe vì nó miễn phí?
All rights reserved
