API NodeJS của tôi đã handle peak traffic như thế nào?
Bài đăng này đã không được cập nhật trong 3 năm
Một câu chuyện tối ưu được chuyển thể thành workshop ngay tại đây và trong chính bài viết này về chủ đề xây dựng ứng dụng API tải cao với NodeJS.
Đọc bài viết này các bạn sẽ không chỉ có keywork suông hay mũi tên chỉ hướng đâu mà sẽ có đoạn code trực tiếp để áp dụng vào dự án ngay hôm nay. Còn chần chờ gì nữa mà không cuộn xuống?

First things first
Ây nhưng mà từ từ đừng vội. Mình là Minh Monmen và hôm nay mình sẽ tiếp tục đem đến cho các bạn cách mà một người nông dân làm công nghệ thì nó sẽ khác so với khoa học gia làm công nghệ như thế nào.
Đây vẫn là câu chuyện trang livestream vạn CCU (thực tế là 3k rưỡi) từ bài viết Tôi, NuxtJS và trang livestream vạn CCU thôi nhưng lần này là đứng ở phía backend. Mặc dù vẫn là phèn nhưng mà cứ gọi là peak đi nó còn có câu chuyện để mà nói. Chứ chờ đến lúc mình được vạn CCU rồi triệu CCU rồi mình giấu hết bí kíp để inbox riêng trả xèng tư vấn chứ không đi chia sẻ công khai thế này nữa đâu.
Ok chưa? Tiếp nào!
Vài nét về bài toán
Vẫn như bài viết trước, thì bài toán của mình là một trang livestream vạn CCU (tức là hướng đến vạn CCU =))). Một số yêu cầu cơ bản như sau:
- Hệ thống chủ yếu là read data với tỷ lệ gần như là 99/1
- Data trên trang chủ yếu là động, có thể custom cho từng user
- Phần data hot thì có thay đổi tương đối thường xuyên và được cập nhật bởi hệ thống worker phía sau
Riêng phần hạ tầng livestream thì đã có 1 bên khác lo và tối ưu rồi, phần việc của mình chỉ đơn giản là làm trang web cho user truy cập và tương tác mà thôi.
Kiến trúc mình đang dùng
Hiện tại thì mình đang chạy với một mô hình rất cơ bản là... monolith. Tất nhiên thì mình đã tách ra frontend sử dụng NuxtJS riêng và backend API trên Nodejs riêng rồi. Đây là bước đầu tiên cần làm để có thể dễ dàng scale được chứ chưa cần kiến trúc gì đao to búa lớn như micro-service đâu.
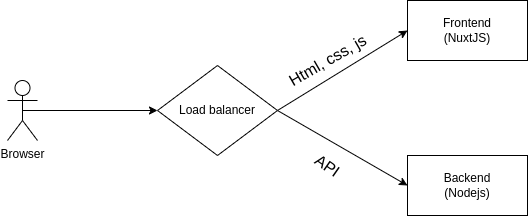
Trang livestream này thì có kha khá data động, và để phát triển cho nó nhanh, lại tương thích được với hầu hết các loại thiết bị từ cổ chí kim, từ laptop cho tới mobile hay tới cả trình duyệt nhúng thì lựa chọn kỹ thuật của tụi mình vẫn đang là cơ chế short-polling. Các bạn có thể google rất nhiều bài viết về các kỹ thuật realtime update data khác như long-polling, server-sent event, websocket,... nhưng mình đảm bảo là chẳng có gì dễ implement và làm được sản phẩm nhanh như thằng short-polling đâu. Đây cũng chính là yếu tố quan trọng nhất để lựa chọn cho sản phẩm này: tốc độ phát triển.
Về phía frontend thì framework ở đây là NuxtJS. Chủ yếu là do Vue (base của Nuxt) là 1 thằng có cú pháp dễ hiểu dễ học lại quen thuộc vậy thôi. Chọn Nuxt là để có được khả năng Server-Side Render ngay từ khi init project. Thằng Nuxt này nó có cả 2 chế độ SPA và SSR, nên là thích kiểu gì cũng chiều được tránh về sau muốn thêm lại lằng nhằng.
Về phía backend thì web server mình đang chọn Fastify. Tất nhiên là không phải chỉ đi nghe trên mạng nói thằng fastify nó nhanh với overhead thấp mà cứ áp dụng bừa đâu. Quan trọng là các bạn biết khi nào mình cần quan tâm tới overhead. Nếu như team mình vẫn đang ngụp lặn trong những chiếc query chậm, rồi những cái latency tính bằng trăm millisecond hay vài second thì chắc chắn là chả cần phải để ý đến cái gọi là framework overhead làm gì. Nhưng khi API tính thời gian bằng vài millisecond tới chục millisecond thì đó sẽ là lúc các bạn phải lựa chọn framework vì overhead.
Framework overhead là khái niệm sử dụng khi so sánh khả năng xử lý của 2 framework. Nôm na là so sánh thử 2 request empty xem thằng nào có latency nhỏ hơn thì tức là thằng đó nhanh hơn. Ví dụ khi cân nhắc fastify với express người ta so sánh overhead của 2 thằng thì fastify có overhead nhỏ hơn do đó nhanh hơn.
Điều quan trọng nhất khi đưa ra một lựa chọn với lý do vì performance là bạn phải thực sự hiểu mình đang đánh đổi điều gì và lựa chọn có xứng đáng với thứ nó mang lại hay không. Ví dụ khi lựa chọn fastify là mình phải ý thức được mình đang bỏ qua rất nhiều tính năng mà thằng express có sẵn chẳng hạn, rồi việc dev của mình có quen với fastify được như đang quen với express không,...
Tất nhiên là với một kiến trúc ứng dụng hợp lý thì việc thay đổi web server không phải là vấn đề quá lớn. Thậm chí là còn khá dễ dàng kia. Hãy nhìn qua cấu trúc thư mục project của mình:
livestream-project
├── src
│ ├── index.ts
│ ├── index-worker.ts
│ ├── config
│ │ ├── environment.ts
│ │ └── errors.ts
│ ├── common
│ │ ├── auth
│ │ │ ├── auth.request.ts
│ │ │ ├── auth.response.ts
│ │ │ ├── auth.service.ts
│ │ │ ├── auth.transformer.ts
│ │ └── logger.ts
│ ├── api
│ │ ├── application.ts
│ │ ├── auth
│ │ │ ├── auth.controller.ts
│ │ │ ├── auth.middleware.ts
│ │ │ ├── auth.route.ts
│ │ │ └── auth.validator.ts
│ │ ├── response.middleware.ts
│ │ ├── router.ts
│ │ └── server.ts
│ └── worker
│ ├── application.ts
│ ├── router.ts
│ ├── server.ts
│ └── sync
│ └── sync-realtime-data.job.ts
├── package.json
└── yarn.lock
Ở đây mình có triển khai cấu trúc multiple-entrypoint để start các thành phần khác nhau của project như api, worker,... Những logic chung sẽ được xử lý trong common. Trong thư mục API chỉ chứa các logic liên quan tới web server như Controller, router, validator,... chứ không chứa business logic. Do đó việc thay web server từ express quen thuộc sang fastify là tương đối dễ dàng.
Một vài con số cơ bản
Ok, trước khi bắt đầu thì chúng ta cùng điểm qua những con số cơ bản liên quan đến performance của hệ thống hiện tại nha.
Bắt đầu với 1 API được call nhiều nhất app là API get item detail đi:
- Cấu hình máy test: Core i5 4200H 4 cores, 12GB RAM + SSD
- Môi trường test: DB local trên docker, code chạy 1 process node
- Endpoint:
/items/:id
Tất cả các kết quả trong các bài test ở đây đều test trên code đang chạy thực của mình và data thực do đó sẽ phức tạp hơn kha khá so với đoạn code dưới đây. Tuy nhiên về cơ bản thì những điểm khác biệt liên quan đến performance đều đã được thể hiện.
async function getItemNoCache(req: FastifyRequest, res: FastifyReply): Promise<void> {
const { id } = req.params as { id: number };
// This will load item directly from database
const item = await ItemService.getItemById(id);
return res.sendJson({
data: item.transform(),
});
}
Để cho kết quả có tính chất so sánh được và loại trừ các yếu tố liên quan đến network thì mình có thêm 1 endpoint trống không làm gì mà chỉ return đúng cái response của endpoint /items/:id (để cho tất cả các API test đều có chung response size, triệt tiêu sự khác biệt về network và data transfer).
async function getItemEmpty(req: FastifyRequest, res: FastifyReply): Promise<void> {
return res.sendJson({
// Mock a item response
data: {
id: 10,
name: 'foo',
property: 'bar',
...
},
});
}
Kết quả test 100k request, concurrency 200 với tool k6.io như sau:
| No. | Test | Http time (s) | Http RPS | avg(ms) | min(ms) | max(ms) | p95(ms) | Node CPU |
|---|---|---|---|---|---|---|---|---|
| 1 | Empty GET | 18.5 | 5396 | 36.95 | 0.91 | 140.66 | 53.47 | 115.00% |
| 2 | Get by id | 154.9 | 645 | 309.59 | 174.96 | 557.06 | 349.28 | 230.00% |
Như đã nói trong series Chuyện anh thợ xây và write-heavy application thì Empty GET sẽ thể hiện cái overhead của framework và của data. Tức là giờ code gần như không làm gì hết chỉ response đúng cái data thôi thì sẽ có performance ra sao.
Về bản chất là 1 instance node của mình đã chạy full CPU (100% tức là full 1 core CPU), tức là đã dùng tối đa tài nguyên nó có thể. Thế nhưng ai cũng sẽ thắc mắc là tại sao Nodejs vẫn được bảo là single-threaded mà lúc thì dùng tới 115% CPU, lúc thì còn dùng tới cả 230% CPU (tức là > 2 core CPU luôn). Thế hóa ra cái mác single-threaded bấy lâu nay là lừa đảo à?
~> Không lừa đảo nhưng là nói chưa hết ý thôi. Về bản chất thì cái event-loop dùng để chạy code của chúng ta mới là single-threaded. Tức là chúng ta có thể đảm bảo việc chạy các đoạn code tính toán trên CPU của chúng ta là single-threaded, còn đâu những cái io ra bên ngoài - mà cụ thể là làm việc với libuv (1 thư viện trong core của node xử lý quá trình bất đồng bộ trong việc đọc file, call http, dns,...) sẽ được thực hiện trên 1 thead pool với số thread mặc định là 4. Số thread của libuv có thể config được qua biến môi trường UV_THREADPOOL_SIZE.
Mình đang sử dụng database postgres, có dùng node-postgres làm driver, mà sâu xa bên trong thằng này lại dùng libpq, libpq lại dùng libuv. Thế nên khi call API Get by id thì thằng node của mình đã dùng tới 230% CPU là vì thế.
Có 1 câu hỏi hay được dùng để lừa các bạn Node.js developer là: Nếu chỉ chạy 1 instance thì ứng dụng Node có thể sử dụng nhiều hơn 1 CPU được không?. Các bạn chiếu mới chỉ nghĩ tới single-threaded mà nhanh trí bảo không là sai đó nhé.
Thi triển mô hình cache-aside với Redis
Gọi trực tiếp database thì tất nhiên là performance sẽ không được tốt cho lắm rồi. Dựa trên kinh nghiệm của mình trên vài hệ thống là 10 CCU thì tạo ra 1 req/s thì con số 645 req/s ở trên chỉ có thể đáp ứng được 6k CCU (mà còn là trong điều kiện hết sức lý tưởng, database thì ít data mà user chỉ gọi mỗi get item by id đó nhé). Thế thì chặng đường đến 1 vạn CCU của mình có vẻ lại tốn thêm nhiều tiền tài nguyên roài.
Không, ai lại không dưng cống tiền cho tụi tư bản cloud như thế? Giờ mình thi triển giải pháp đơn giản nhất ai cũng dùng là Cache với Redis xem sao nhé.
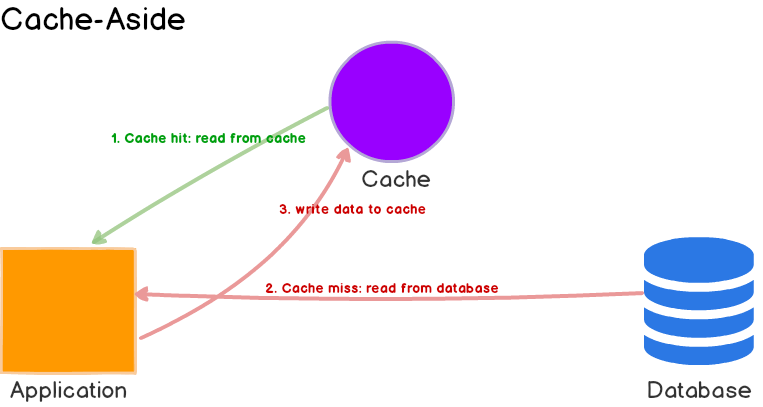
Cách đơn giản nhất để cache với Redis là dùng mô hình cache-aside. Mình có thể gói gọn việc implement cache này bằng function sau:
async function getOrSet<T>(key: string, getData: () => Promise<T>, ttl: number): Promise<T> {
let value: T = (await redisClient.get(key)) as T;
if (value === null) {
value = await getData();
if (ttl > 0) {
await redisClient.set(key, value, 'EX', ttl);
} else {
await redisClient.set(key, value);
}
}
return value;
}
Sau đó trong code của mình sẽ call như sau:
async function getItemFromRedis(req: FastifyRequest, res: FastifyReply): Promise<void> {
const { id } = req.params as { id: number };
const itemResponse = await redisAdapter.getOrSet<IItemResponse>(
`items:${id}`,
async () => {
// This will load item directly from database
const item = await ItemService.getItemById(id);
return item.transform();
},
30,
);
return res.sendJson({
data: itemResponse,
});
}
Đã xong, mình đã cache lại response của item với Time-to-live là 30s. Tiếp tục test lại performance với k6.io nhé:
| No. | Test | Http time (s) | Http RPS | avg(ms) | min(ms) | max(ms) | p95(ms) | Node CPU |
|---|---|---|---|---|---|---|---|---|
| 1 | Empty GET | 18.5 | 5396 | 36.95 | 0.91 | 140.66 | 53.47 | 115.00% |
| 2 | Get by id | 154.9 | 645 | 309.59 | 174.96 | 557.06 | 349.28 | 230.00% |
| 3 | Cache Redis | 24.1 | 4143 | 48.14 | 10.86 | 195.4 | 68.19 | 125.00% |
Chà, tốc độ khá tốt rồi đúng không? Vậy là bước đầu tiên đã xong, mình áp dụng cơ chế cache này có 1 cơ số API lấy data trên trang khác nữa tùy thuộc vào data từng chỗ sẽ có tần suất thay đổi ra sao.
Short-polling và bài toán băng thông public
Mọi chuyện khá ổn cho tới khi mình phát hiện ra một vấn đề khi số lượng CCU tăng cao: Băng thông output public của tụi mình tăng mạnh lên cả trăm Mbps. Tất nhiên là với một trang web bình thường thì con số gần 100Mbps này chưa nhằm nhò gì. Thế nhưng khi các bạn đang target 1 vạn CCU mà giờ mới được có 2-3k CCU đã thấy băng thông tăng cao như vậy thì cũng nên xem xét lại. Nhất là sau khi mình đã tách ứng dụng cho user sử dụng Nuxt CSR thay vì SSR (tức là gần như toàn bộ static asset đã được cache lại trên CDN và html có dung lượng cực kỳ nhẹ)
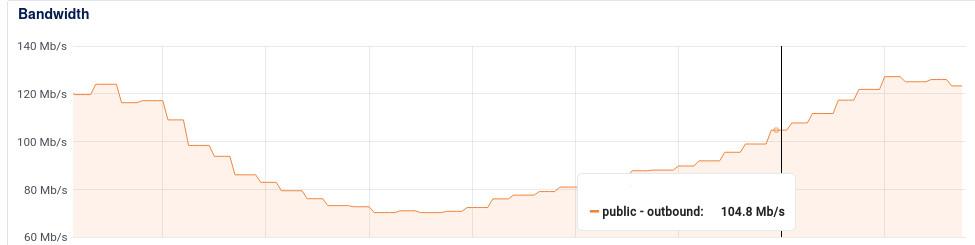
Rất nhanh mình đã tìm ra vấn đề: chính là do cơ chế short-polling mà bọn mình đang sử dụng.
Trong bài viết trước Tôi, NuxtJS và trang livestream vạn CCU thì mình cũng đã đề cập đến vấn đề này rồi. Giờ mình chỉ nhắc lại thêm việc chọn cơ chế short-polling là tương đối phù hợp với bài toán mà tụi mình đang làm cũng như chi phí nguồn lực dành cho dự án này.
Ở trên mình đã chọn Fastify làm web framework và đây là sự đánh đổi đầu tiên sau khi đưa ra một lựa chọn về performance: Mình phải học cách tự làm mọi thứ. Trước đây express đã giúp mình cấu hình sẵn việc sử dụng Etag để đánh dấu response không thay đổi và trả về HTTP status 304 giúp client không mất băng thông truyền tải response nữa. Còn giờ thì mình đã phải tự làm với Fastify. Tất nhiên là nó không khó, chỉ khó cái là bạn có biết mình cần phải tự làm hay không để ý thôi.
import fastifyEtag from '@fastify/etag';
import fastify from 'fastify';
const server = fastify();
await server.register(fastifyEtag, { weak: true });
Sau khi bật Etag thì mình giảm được khoảng ~4 lần băng thông output public (cũng hợp lý khi mà data của tụi mình thay đổi với tần suất khoảng 1p/lần và short-polling đang được cấu hình 15s / lần).
Ngoài ra thì với một số API đặc biệt dạng list, thay vì refresh toàn bộ list thì mình cũng làm thêm 1 vài động tác tối ưu đơn giản bằng việc cố gắng phân tách data ít thay đổi với data thường xuyên thay đổi. Từ đó có thể tách API refresh list thường xuyên thay đổi ra riêng. Việc này giúp mình giảm thêm được vài lần băng thông output public nữa.
Kết quả với 3k CCU thì băng thông output public của mình chỉ còn trên dưới 10Mbps.
Sức mạnh của promise và bài toán Thundering Herds
Mặc dù khá hài lòng với việc có một hệ thống chạy ổn trong thời gian ngắn. Tuy nhiên mình cũng không thể không để ý một vài dấu hiệu khá đáng ngại khi theo dõi tải vào database và slow query.
- Slow query xuất hiện khi CPU của database tăng cao.
- Xuất hiện nhiều query slow trùng lặp tại cùng 1 thời điểm.
Ok, hệ thống của mình thường có cron job chạy để update số lượng lớn dữ liệu được cập nhật bởi các hệ thống khác. Những lúc như vậy thì tải database cao lên là chuyện bình thường. Kể cả slow query có xuất hiện khi cao tải đó thì cũng có thể chấp nhận được. Thế nhưng xuất hiện nhiều slow query trùng lặp vào cùng một thời điểm thì lại là dấu hiệu của sự sụp đổ rồi.
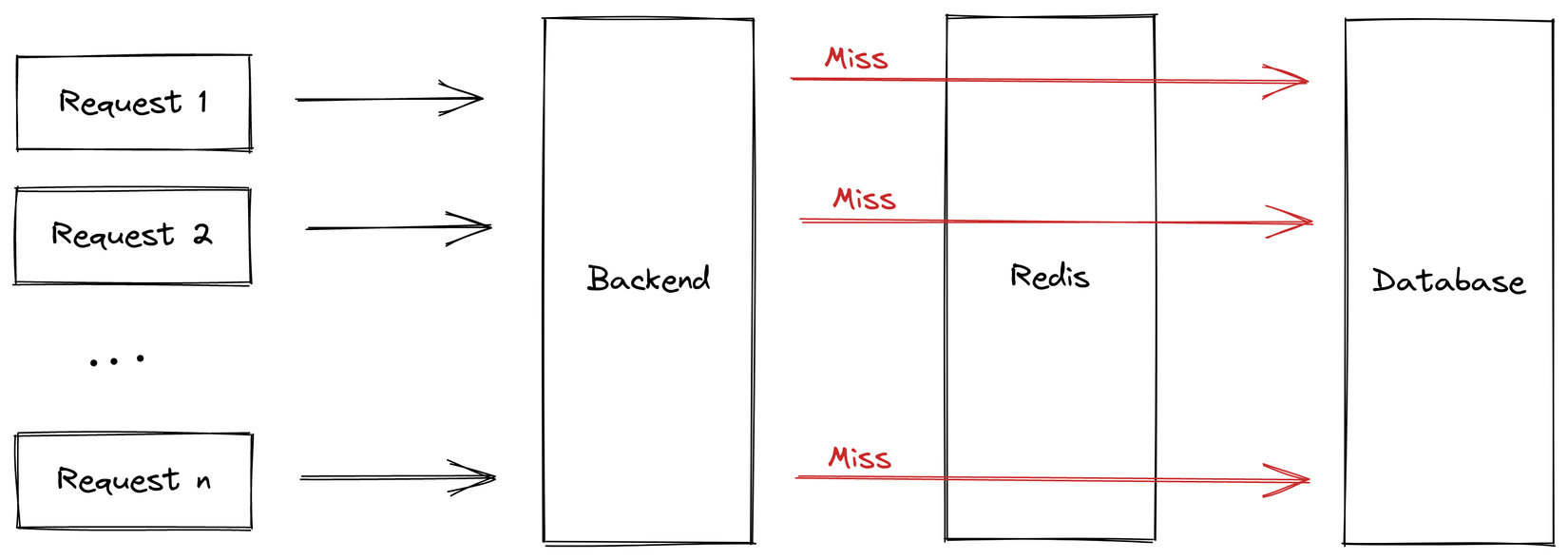
Nếu anh em đã đọc series Caching đại pháp của mình thì cũng sẽ nhận ra điều này có ý nghĩa gì. Đó chính xác là vấn đề Thundering herds hay còn gọi là Cache stampede. Tức là hệ thống cache liên tục bị miss tại 1 thời điểm do chưa xử lý xong yêu cầu trước (để cache lại kết quả) thì yêu cầu tiếp theo đã tới. Điều này dẫn đến việc request chạy thẳng vô database và tiếp tục gây ra gánh nặng lên db dẫn đến quá tải và chết hệ thống.
Để giải quyết vấn đề này thì tất nhiên mình sẽ nghĩ đến việc khi có request đầu tiên miss cache, mình sẽ đánh dấu việc call db đang được thực hiện, từ đó ngăn không cho các request tiếp theo gọi trực tiếp vào db mà sẽ chờ cùng với request đầu tiên. Rất may mắn là Node.js của chúng ta về cơ bản là single-threaded, do đó việc khởi tạo và access một global variables tương đối dễ dàng mà không phải quan tâm tới vấn đề race-condition bao giờ.
Để khóa được việc call database, mình sử dụng đoạn code sau:
// Define a global map to store calling promise
const callingMaps: Map<string, Promise<unknown>> = new Map();
async function getOrSet<T>(key: string, getData: () => Promise<T>, ttl: number): Promise<T> {
let value: T = (await redisClient.get(key)) as T;
if (value === null) {
// Check if key is being processed in callingMaps
if (callingMaps.has(key)) {
return callingMaps.get(key) as Promise<T>;
}
try {
const promise = getData();
// Store key + promise in callingMaps
callingMaps.set(key, promise);
value = await promise;
} finally {
// Remove key from callingMaps when done
callingMaps.delete(key);
}
if (ttl > 0) {
await redisClient.set(key, value, 'EX', ttl);
} else {
await redisClient.set(key, value);
}
}
return value;
}
Ở đây các bạn hãy để ý dòng const promise = getData();. Không phải là mình quên chữ await khi call getData đâu mà là cố tình đó nhé. Kết quả của getData() sẽ trả về một promise. Mình sẽ ngay lập tức set promise cùng key đang gọi vào một cái Map global gọi là callingMaps. Lúc này nếu có một request nào đó tới hệ thống mà phần value = await promise; chưa thực hiện xong thì cũng sẽ tìm thấy promise đang chạy ở trong callingMaps và sẽ cùng chờ kết quả của chính promise đang chạy đó luôn chứ không request vào db nữa.
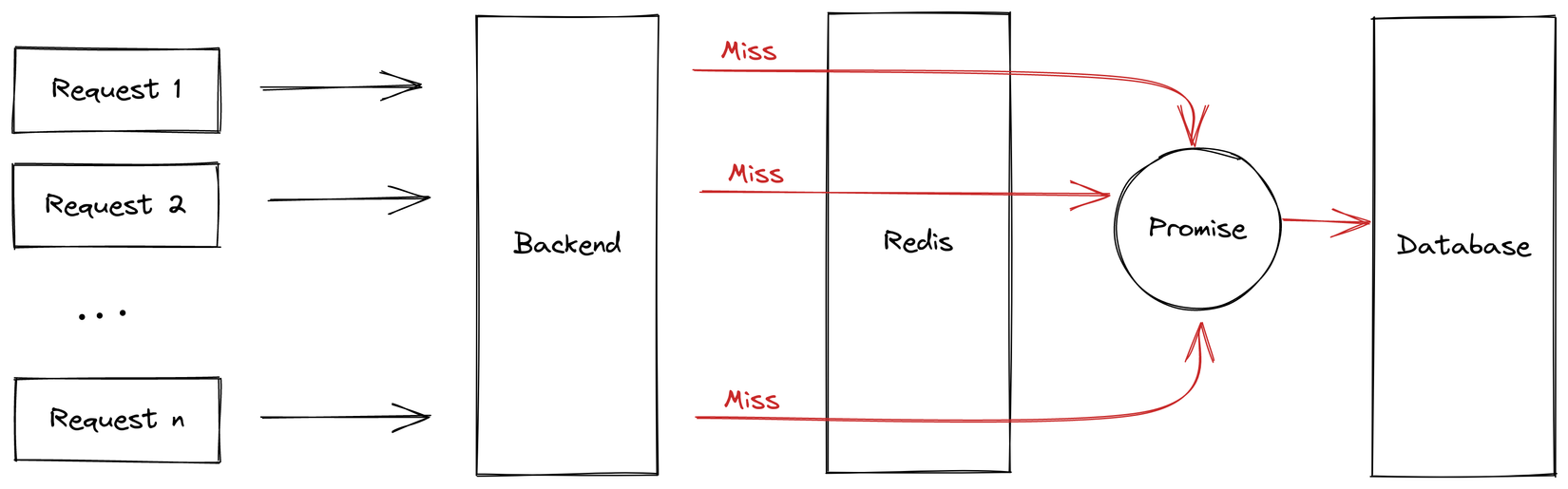
Bằng việc lưu lại promise khi call db thì mình đã triệt tiêu toàn bộ các request thừa tới database khi xảy ra hiện tượng Thundering Herds. Dù có 1000 request tới cùng lúc và bị miss cache thì cũng chỉ có 1 request tới được db mà thôi.
Cache promise là một kỹ thuật cực kỳ lợi hại nếu các bạn biết sử dụng đúng cách. Nhớ đừng có quen tay thêm await ở chỗ
const promise = getData();không là hỏng hết cả bánh kẹo đó nhé =)))
Memory cache và bài toán băng thông internal
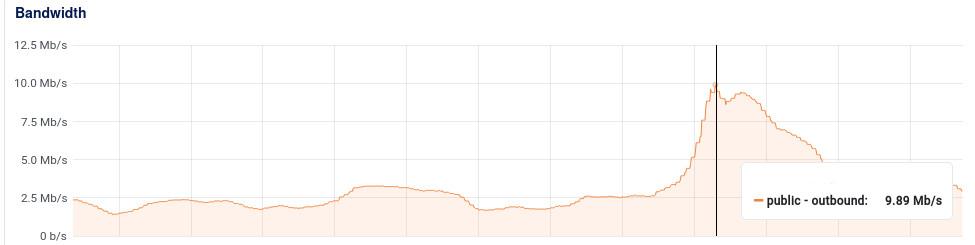
Sau khi giải quyết tương đối bài toán băng thông public thì lại tiếp tục tới công chuyện với bài toán băng thông internal. Mặc dù đã sử dụng promise để chống hiện tượng Thundering Herds bằng phương pháp lưu lại running promise tuy nhiên bọn mình cũng nhanh chóng nhận ra nhiêu đó là chưa đủ với một hệ thống CCU tăng dần.
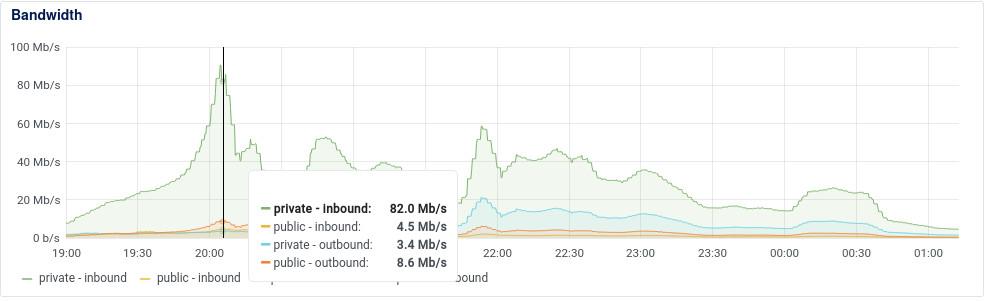
Như các bạn đã thấy trong ảnh thì băng thông internal của tụi mình bằng khoảng 10 lần băng thông public. Đây là kết quả sau quá trình tối ưu băng thông public bằng Etag ấy. Tức là hệ thống thì vẫn tốn băng thông internal để lấy data từ Redis, nhưng nếu response không thay đổi so với etag thì sẽ không tốn băng thông public để truyền về client nữa.
Vẫn lại câu chuyện cũ thôi, 100Mbps internal thì vẫn chưa là gì cả, nhưng sau khi vận hành nhiều hệ thống chạy với Redis trên cloud thì bọn mình cũng đã gặp nhiều trường hợp băng thông Redis lên tầm vài trăm Mbps và xuất hiện hiện tượng waiting network khá nhiều. Thêm vào đó là network internal VPS trên cloud thì không có một cam kết cụ thể nào do đó dùng tới vài trăm Mbps thì cũng khá rủi ro.
Vậy làm sao để tối ưu được băng thông internal với hệ thống đang chạy đây? Tất nhiên là tiết kiệm bằng cách... không dùng nữa rồi.
Nếu mình chuyển hoàn toàn Redis cache sang Memory cache thì vấn đề network sẽ gần như được giải quyết. Thế nhưng chỉ dùng Memory cache thì lại phát sinh vô số vấn đề khác như:
- Invalidate cache khó khăn
- Memory cho 1 instance có giới hạn
- Cold cache khi re-deploy service
- Horizontal scale dẫn đến hiệu quả cache giảm (cache hit ratio thấp) ...
Vân vân và mây mây. Bài toán trang livestream lần này có backend tương đối phức tạp với nhiều API và nhiều loại data khác nhau chứ lại không đơn giản như chiếc service trong Bài toán "Super fast API" với Golang và Mongodb của mình, do đó chuyển hoàn toàn sang Memory cache lúc này là không phù hợp.
Ok nếu không chuyển hẳn thì dùng cả hai vậy. Chúng ta có thể thêm 1 function nữa để wrap cái getOrSet phía trên như sau:
async function getOrSet<T>(key: string, getData: () => Promise<T>, ttl: number): Promise<T> {
let value: T = (await redisClient.get(key)) as T;
if (value === null) {
value = await getData();
if (ttl > 0) {
await redisClient.set(key, value, 'EX', ttl);
} else {
await redisClient.set(key, value);
}
}
return value;
}
const burstCache = new NodeCache({
useClones: false,
});
async function burstGetOrSet<T>(key: string, getData: () => Promise<T>, ttl: number, burstTtl: number): Promise<T> {
if (burstTtl === 0) {
return getOrSet<T>(key, getData, ttl);
}
let value = burstCache.get<Promise<T>>(key);
if (value === undefined) {
value = getOrSet<T>(key, getData, ttl);
burstCache.set(key, value, burstTtl);
}
return value;
}
Ở đây mình sẽ bỏ cái cơ chế callingMaps mới làm ở phần trên đi vì không cần thiết nữa. Các bạn lại để ý là khi mình call getOrSet lúc return hoặc value = getOrSet() thì đều không có await để kết quả trả về dưới dạng promise nhé.
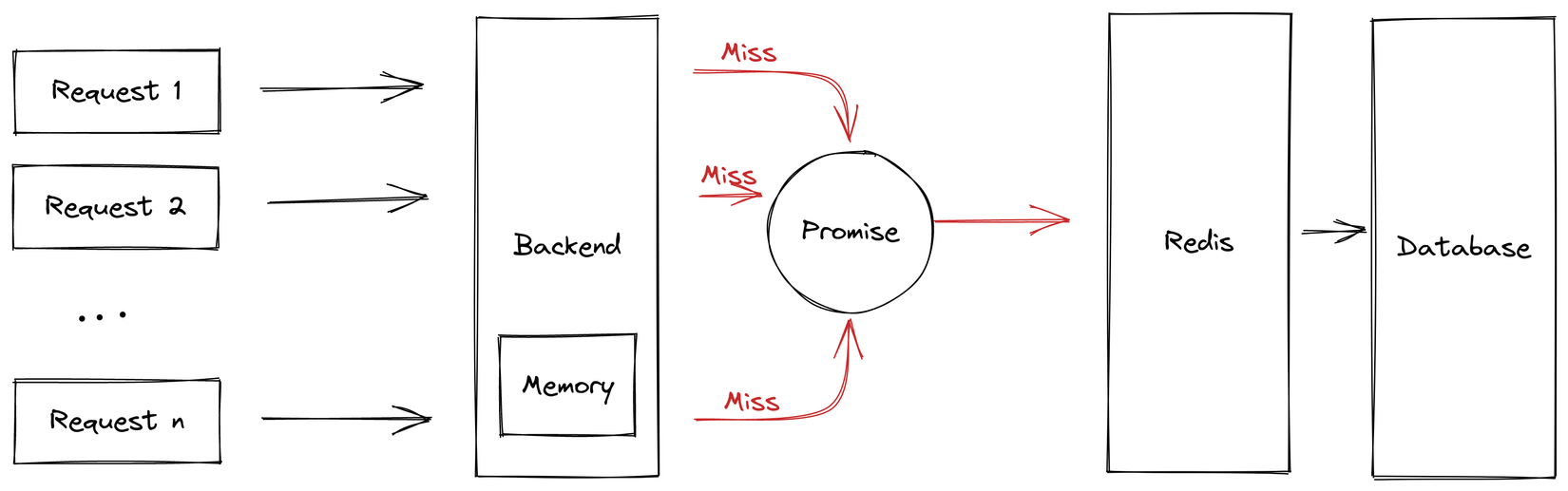
Trong này có sử dụng một thư viện memory cache rất nổi tiếng cho Node là node-cache, các bạn cũng lưu ý luôn là khi khởi tạo thì mình có thêm option useClones: false để thằng node-cache giữ nguyên object promise của mình mà không clone ra 1 promise mới nhé. Làm như này sẽ tiết kiệm được memory hơn và sử dụng lại đúng cái promise sinh ra từ request đầu tiên.
Khi dùng thì khá đơn giản, chỉ việc thêm 1 tham số là burstTtl tức là thời gian cache memory nữa thôi.
async function getItemFromMemory(req: FastifyRequest, res: FastifyReply): Promise<void> {
const { id } = req.params as { id: number };
const itemResponse = await redisAdapter.burstGetOrSet<IItemResponse>(
`items:${id}`,
async () => {
// This will load item directly from database
const item = await ItemService.getItemById(id);
return item.transform();
},
30, // Redis cache TTL
5 // Memory cache TTL
);
return res.sendJson({
data: itemResponse,
});
}
Thời gian này sẽ ngắn hơn thời gian ttl là thời gian cache của redis. burstTtl thường mình chỉ set trong vài s, tức là chỉ để tránh việc call lặp lại rất nhiều vào redis tại những thời điểm request nhiều thôi. Do đó gần như sẽ vẫn giữ được những tính chất của hệ thống cache redis như việc chấp nhận invalidate trễ vài s, lượng memory mà instance sử dụng tương đối nhỏ,...
Thử test lại performance với k6.io xem sao:
| No. | Test | Http time (s) | Http RPS | avg(ms) | min(ms) | max(ms) | p95(ms) | Node CPU |
|---|---|---|---|---|---|---|---|---|
| 1 | Empty GET | 18.5 | 5396 | 36.95 | 0.91 | 140.66 | 53.47 | 115.00% |
| 2 | Get by id | 154.9 | 645 | 309.59 | 174.96 | 557.06 | 349.28 | 230.00% |
| 3 | Cache Redis | 24.1 | 4143 | 48.14 | 10.86 | 195.4 | 68.19 | 125.00% |
| 4 | Cache Mem (burst) | 22.1 | 4516 | 44.16 | 2.92 | 176.58 | 59.81 | 120.00% |
Như các bạn đã thấy, việc sử dụng kèm memory cache với hệ thống của mình không phải để giải quyết bài toán tốc độ. Điều này có thể dễ dàng thấy qua kết quả benchmark thì việc cache memory chỉ nhỉnh hơn cache Redis ở trên khoảng 10% về performance. Cái mà phương pháp này giải quyết là việc mình gần như giữ nguyên các đặc tính dữ liệu và code nhưng đã giảm được khoảng 5-6 lần băng thông internal.
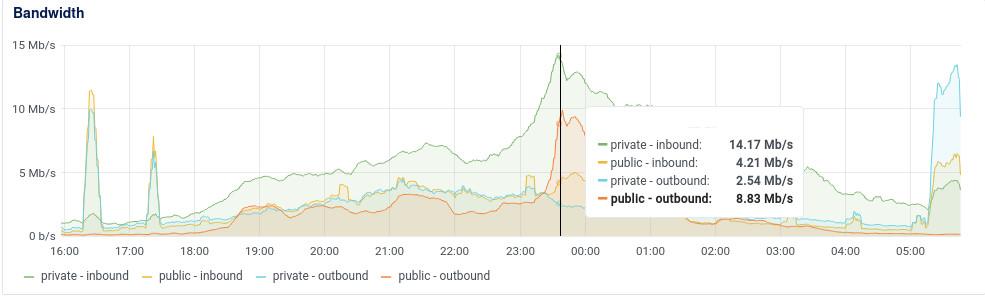
Đây mới là cách một cử nhân kinh tế tối ưu hệ thống, chứ không phải là thay đổi hết các giải pháp và đẻ ra nhiều vấn đề hơn.
Tổng kết
Qua bài viết này mình rút ra 3 điều:
- Tối ưu là tổng hòa của quá trình tăng kết quả đầu ra và chi phí đầu vào.
- Tăng kết quả đầu ra với một chi phí đánh đổi hợp lý mới là điều khó nhất chứ không phải là đánh đổi mọi thứ để có được kết quả lớn nhất.
- Cache vẫn là dễ, kết hợp các loại cache như thế nào để phù hợp với bài toán cụ thể mới là khó. Và đó là lý do cần có kinh nghiệm chinh chiến nhiều đó.
Hết rồi. Upvote nếu thấy hay ho nhé.
All rights reserved
