Apache Kafka và các khái niệm cơ bản của nó (Phần 2)
Bài đăng này đã không được cập nhật trong 6 năm
Cấu trúc dữ liệu log trong Kafka
Chìa khóa chính dẫn tới khả năng mở rộng và hiệu suất của kafka chính là log. Log ở đây không phải là thuật ngữ được sử dụng trong log ứng dụng, mà là cấu trúc dữ liệu log. Log là một cấu trúc dữ liệu có thứ tự nhất quán mà chỉ hỗ trợ dạng nối thêm (append). Không thể chỉnh sửa hay xóa các bản ghi từ nó. Nó được đọc từ trái sang phải và được đảm bảo thứ tự các item.
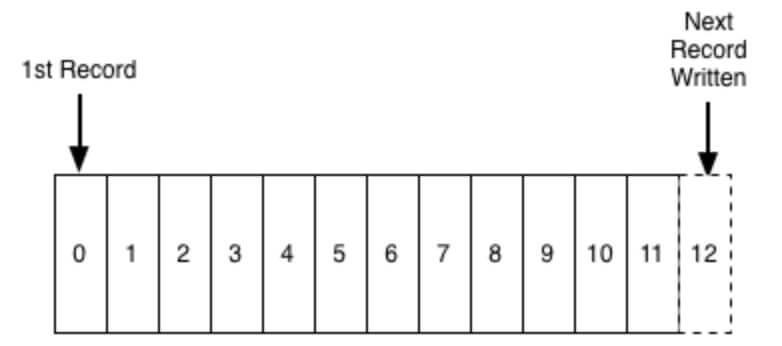
Một producer sẽ ghi message vào log và một hoặc nhiều consumer khác sẽ đọc message từ log tại thời điểm họ lựa chọn.
Mỗi entry trong log được định danh bởi một con số gọi là offset, hay nói một cách dễ hiểu hơn, offset giống như chỉ số tuần tự trong một array vậy.
Vì chuỗi/offset chỉ có thể được duy trì trên từng node/broker cụ thể và không thể được duy trì đối với toàn bộ cluster, do đó Kafka chỉ đảm bảo sắp xếp thứ tự dữ liệu cho mỗi partition.
Persistence data trong Kafka
Kafka lưu trữ tất cả message vào disk (không hề lưu trên RAM) và được sắp xếp có thứ tự trong cấu trúc log cho phép kafka tận dụng tối đa khả năng đọc và ghi lên disk một cách tuần tự.
Nó là một cách lựa chọn khá phổ biến để lưu trữ dữ liệu trên disk mà vẫn có thể sử dụng tối đa hóa hiệu năng, bới một số lý do chính dưới đây:
- Kafka có một giao thức mà nhóm các message lại với nhau. Điều này cho phép các request network nhóm các message lại với nhau, giúp giảm thiểu chi phí sử dụng tài nguyên mạng, server, gom các message lại thành một cục và consumer sẽ tìm nạp một khối message cùng một lúc – do đó sẽ giảm tải disk cho hệ điều hành.
- Kafka phụ thuộc khá nhiều vào pagecache của hệ điều hành cho việc lưu trữ dữ liệu, sử dụng RAM trên máy một cách hiệu quả.
- Kafka lưu trữ các messages dưới định dạng nhị phân xuyên suốt quá trình (producer > broker > consumer), làm cho nó có thể tận dụng tối ưu hóa khả năng zero-copy. Nghĩa là khi hệ điều hành copy dữ liệu từ pagecache trực tiếp sang socket, hoàn toàn bỏ qua ứng dụng trung gian là kafka.
- Đọc/ghi dữ liệu tuyến tính trên disk nhanh. Vấn đề làm cho disk chậm hiện nay thường là do quá trình tìm kiếm trên disk nhiều lần. Kafka đọc và ghi trên disk tuyến tính, do đó nó có thể tận dụng tối đa hóa hiệu suất trên disk.
Consumer và Consumer Group
Consumer đọc các messages từ bất kỳ partition nào, cho phép mở rộng lượng message được sử dụng tương tự như cách các producer cung cấp message.
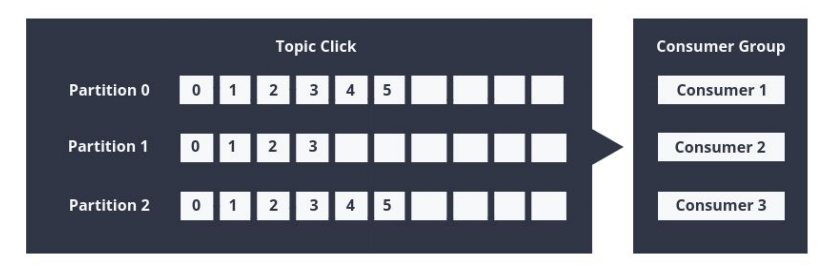
Consumer cũng được tổ chức thành các consumer groups cho một topic cụ thể bằng cách thêm thuộc tính nhóm Group.id vào mỗi consumer. Đưa cùng một group id cho consumer khác nhau có nghĩa là chúng sẽ cùng tham gia một group. Mỗi consumer bên trong group đọc message từ một partition, để tránh việc có 2 consumer cùng xử lý đọc cùng một message 2 lần và toàn bộ group xử lý tất cả các message từ toàn bộ topic.
- Nếu số consumer > số partition, khi đó một số consumer sẽ ở chế độ rảnh rỗi bởi vì chúng không có partition nào để xử lý.
- Nếu số partition > số consumer, khi đó consumer sẽ nhận các message từ nhiều partition.
- Nếu số consumer = số partition, mỗi consumer sẽ đọc message theo thứ tự từ 1 partition.
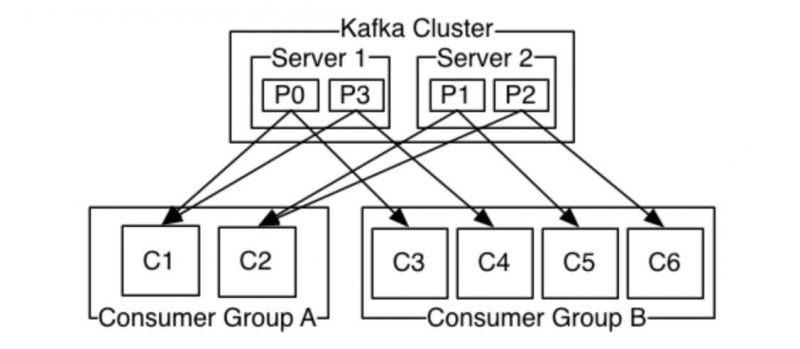
Server 1 giữ partition 0 và 3 và server 2 giữ các partition 1 và 2. Chúng ta có 2 consumer groups là A và B. Group A có 2 consumer và group B có 4 consumer. Consumer group A có 2 consumer, vậy nên mỗi consumer sẽ đọc message từ 2 partition. Trong consumer group B, số lượng consumer bằng số partition nên mỗi consumer sẽ đọc message từ 1 partition.
Mỗi khi consumer được thêm hoặc xóa khỏi group, mức tiêu thụ được cân bằng lại giữa các consumer trong nhóm. Tất cả consumer đều dừng lại trên mỗi lần tái cân bằng, vì vậy việc client thường xuyên restarted hoặc bị time out sẽ làm giảm thông lượng.
Kafka tuân theo các quy tắc được cung cấp bởi broker và consumer. Nghĩa là kafka không theo dõi các record được đọc bởi consumer và do đó không biết gì về hành vi của consumer. Việc giữ lại các messages trong một khoảng thời gian được cấu hình trước và nó tùy thuộc vào consumer, để điều chỉnh thời gian sao cho phù hợp. Bản thân consumer sẽ thăm dò xem Kafa có message nào mới hay không và cho Kafka biết những record nào chúng muốn đọc. Điều này cho phép chúng tăng/giảm offset mà consumer muốn, do đó nó có thể đọc lại các message đã được đọc rồi và tái xử lý các sự kiện trong trường hợp gặp sự cố.
Ví dụ: nếu Kafka được cấu hình để giữ các messages tồn tại trong một ngày và consumer bị down lâu hơn 1 ngày, khi đó consumer sẽ mất message. Tuy nhiên, nếu consumer chỉ bị down trong khoảng 1 giờ đồng hồ, khi đó nó hoàn toàn có thể bắt đầu đọc lại message từ offset mới nhất.
Apache Kafka Workflow | Kafka Pub-Sub Messaging
Pub-Sub Messaging
- Kafka Producer gửi message đến topic.
- Kafka Broker lưu trữ tất cả các messages trong các partion được định cấu hình topic cụ thể đó, đảm bảo rằng các message được phân phối cân bằng giữa các partion. Ví dụ, Kafka sẽ lưu trữ một message trong partion đầu tiên và message thứ hai trong partion thứ hai nếu producer gửi hai message và có hai partion.
- Kafka Consumer subscribes một topic cụ thể.
- Sau khi consumer subscribes vào một topic, Kafka cung cấp offset hiện tại của topic cho consumer và lưu nó trong Zookeeper.
- Ngoài ra, consumer sẽ liên tục gửi request đến Kafka (như 100 Ms) để pull về các message mới.
- Kafka sẽ chuyển tiếp tin nhắn đến consumer ngay khi nhận được từ Producer.
- Consumer sẽ nhận được message và xử lý nó.
- Kafka broker nhận được xác nhận về message được xử lý.
- Kafka cập nhật giá trị offset hiện tại ngay khi nhận được xác nhận. Ngay cả trong khi máy chủ outrages, consumer có thể đọc được message tiếp theo một cách chính xác, bởi ZooKeeper quản lí các offset.
- Quy trình này lặp lại cho đến khi consumer dừng việc subscribes lại
Kafka Queue Messaging/Consumer Group
Một nhóm Kafka consumer có cùng group id có thể đăng ký một chủ đề, thay vì chỉ một consumer. Tuy nhiên, với cùng một group id tất cả consumer đang đăng ký topic được coi là một single group và chia sẻ các message. Quy trình công việc của hệ thống này như sau:
- Kafka Producer gửi message đến topic
- Tương tự như với pub-sub messaging, ở đây Kafka cũng lưu trữ tất cả các tin nhắn trong các partion được định cấu hình cho topic cụ thể đó.
- Một single consumer subscribes vào một topic cụ thể.
- Cũng giống như pub-sub messaging, Kafka tương tác với consumer cho đến khi consumer mới đăng ký vào cùng một chủ đề.
- Khi consumer mới đến, chế độ chia sẻ bắt đầu trong các hoạt động và chia sẻ dữ liệu giữa hai Kafka consumer. Hơn nữa, cho đến khi số lượng Kafka consumer bằng với số lượng partion được định cấu hình cho topic cụ thể đó, việc chia sẻ sẽ lặp lại.
- Một khi số lượng Kafka consumer vượt quá số lượng partion, consumer mới ở Kafka sẽ không nhận được bất kỳ message nào nữa. Nó duy trì cho đến khi bất kỳ một trong những consumer hiện tại hủy đăng ký. Điều này phát sinh bởi vì ở Kafka có một điều kiện là mỗi Kafka consumer sẽ có tối thiểu một partion và nếu không có partion nào trống, thì consumer mới sẽ phải chờ.
Nguồn tham khảo
- https://viblo.asia/p/hang-doi-thong-diep-apache-kafka-jvEla6145kw
- https://www.tutorialspoint.com/apache_kafka/apache_kafka_cluster_architecture.htm
- https://blog.vu-review.com/kafka-la-gi.html
- https://viblo.asia/p/kafka-apache-WAyK8pa6KxX
- https://data-flair.training/blogs/kafka-architecture/
- https://www.cloudkarafka.com/blog/2016-11-30-part1-kafka-for-beginners-what-is-apache-kafka.html
- https://www.facebook.com/notes/cộng-đồng-big-data-việt-nam/tiếp-cận-kafka-thông-qua-confluent-platform/884414712076055/
All rights reserved
