Apache Kafka và các khái niệm cơ bản của nó (Phần 1)
Bài đăng này đã không được cập nhật trong 6 năm
Kafka Topics
Topic là một kênh để các producers publish message và từ đó consumers nhận được messages.
Mỗi topic sẽ có tên do người dùng đặt và có thể coi mỗi topic như là một hàng đợi của thông điệp (mỗi dòng dữ liệu). Các thông điệp mới do một hoặc nhiều producer đẩy vào, sẽ luôn luôn được thêm vào cuối hàng đợi. Bởi vì mỗi thông điệp được đẩy vào topic sẽ được gán một offset tương ứng (ví dụ: thông điệp đầu tiên có offset là 1, thông điệp thứ hai là 2 ...) nên consumer có thể dùng offset này để điều khiển quá trình đọc thông điệp. Nhưng cần lưu ý là bởi vì Kafka sẽ tự động xóa những thông điệp đã quá cũ (thông điệp đẩy vào đã quá hai tuần hoặc xóa bởi vì bộ nhớ cho phép để chứa thông điệp đã đầy) vì vậy sẽ gặp lỗi nếu truy cập vào các thông điệp đã bị xóa.
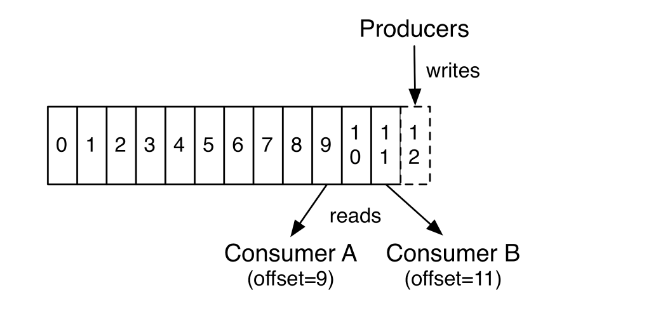
Ở trên mô tả 1 topic có duy nhất một partition. Trên thực tế một topic có rất nhiều partition, khi một thông điệp được đẩy vào topic, mặc định nó sẽ được gắn một chuỗi số bất kì. Thông điệp được đẩy vào topic nào phụ thuộc vào giá trị băm của chuỗi số đó, điều này đảm bảo số lượng thông điệp trên mỗi partition là tương tự nhau. Bởi vì tại một thời điểm, một partition chỉ được đọc bởi một consumer duy nhất, vậy với việc tăng số lượng partition sẽ tăng số lượng dữ liệu được đọc lên tương đương với việc song song hóa được việc đọc. Ngoài ra, offset chính là định danh duy nhất cho mỗi thông điệp ở trong partition chứ không phải trong toàn bộ topic, vì vậy để consumer đọc chính xác thông điệp, chúng ta cần cung cấp địa chỉ của thông điệp có dạng (topic, partition, offset).
Dưới đây là hình ảnh mô tả một topic có nhiều partition.
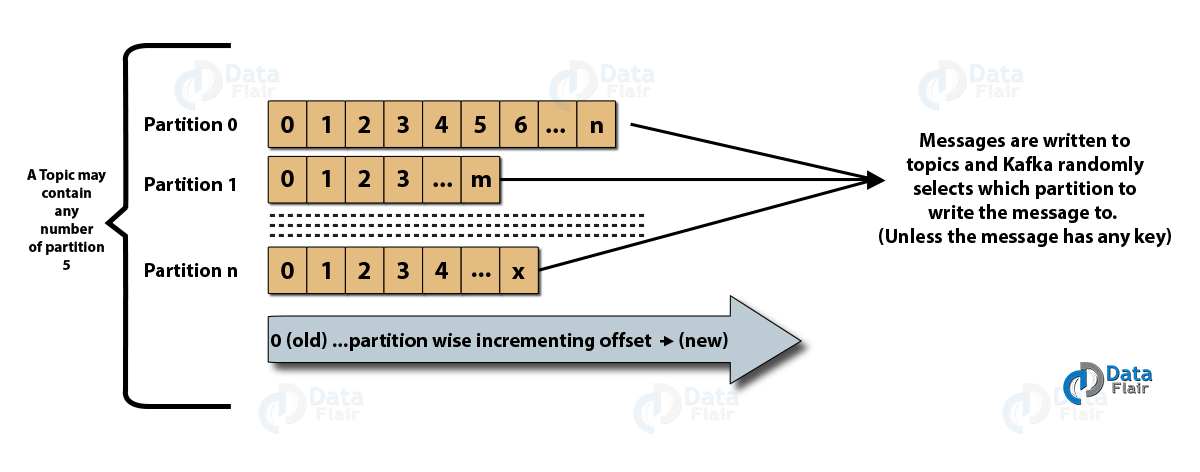
Kafka partition
Topics trong kafka có thể có kích cỡ rất lớn, như vậy không nên lưu trữ tất cả dữ liệu của một topic trên một node, dữ liệu cần đươc phân chia ra thành nhiều partition sẽ giúp bảo toàn dữ liệu cũng như xử lý dữ liệu dễ dàng hơn. Partitions cho phép chúng ta thực hiện subcribe song song tới một topic cụ thể bằng cách phân chia dữ liệu trong một topic cụ thể ra cho nhiều broker khác nhau (kafka node), mỗi partition có thể được đặt trên một máy riêng biệt – cho phép nhiều consumer đọc dữ liệu từ một topic diễn ra một cách song song.

Với mỗi partition, tùy thuộc vào người dùng cấu hình sẽ có một số bản sao chép (replica partion) nhất định để đảm bảo dữ liệu không bị mất khi một node trong cụm bị hỏng, tuy nhiên số lượng bản sao không được vượt quá số lượng broker trong cụm, và những bản sao đó sẽ được lưu lên các broker khác. Broker chứa bản chính của partition gọi là broker “leader”. Những bản sao chép này có tác dụng giúp hệ thống không bị mất dữ liệu nếu có một số broker bị lỗi, với điều kiện số lượng broker bị lỗi không lớn hơn hoặc bằng số lượng bản sao của mỗi partition. Ví dụ một partition có hai bản sao được lưu trên 3 broker sẽ không bị mất dữ liệu nếu có một broker bị lỗi. Còn một điều quan trọng nữa phải lưu ý, do các phiên bản sao chép này không nhận dữ liệu trực tiếp từ producer hay được đọc bởi consumer, mà nó chỉ đồng bộ với paritition chính vì vậy nó không làm tăng khả năng song song hóa việc đọc và ghi.
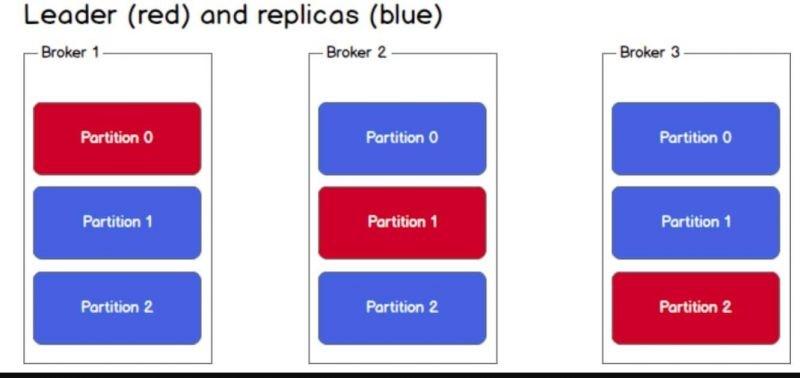
Để tăng tính khả dụng (availability) của partition, mỗi partition cũng có giá trị replicas của riêng nó. Dưới đây là ví dụ với 3 node/broker.
Bây giờ, một topic sẽ được chia ra thành 3 partitions và mỗi broker sẽ có một bản copy của partition. Trong số những bản copy partition này, sẽ có một bản copy được bầu chọn làm leader, trong khi những bản copy khác chỉ thực hiện đồng bộ dữ liệu với partition leader.
Tất cả các hành động ghi và đọc tới một topic sẽ đều phải đi qua partition leader tương ứng và leader sẽ phối hợp để cập nhật dữ liệu mới tới các replica parition khác. Nếu leader bị hỏng, một trong các replica partition sẽ đảm nhận vai trò là một leader mới.
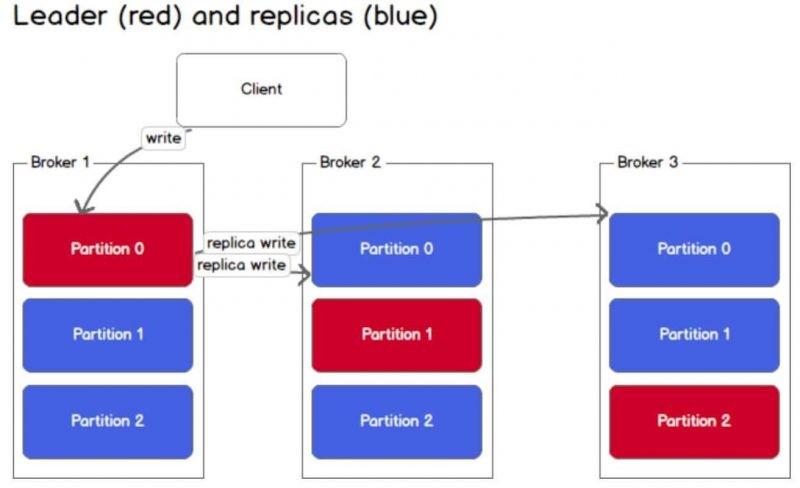
Để một producer/consumer ghi/đọc message từ một partition, chắc chắn chúng cần phải biết leader. Kafka lưu trữ những thông tin như vậy là metadata trong Zookeeper.
Nguồn tham khảo
- https://viblo.asia/p/hang-doi-thong-diep-apache-kafka-jvEla6145kw
- https://www.tutorialspoint.com/apache_kafka/apache_kafka_cluster_architecture.htm
- https://blog.vu-review.com/kafka-la-gi.html
- https://viblo.asia/p/kafka-apache-WAyK8pa6KxX
- https://data-flair.training/blogs/kafka-architecture/
- https://www.cloudkarafka.com/blog/2016-11-30-part1-kafka-for-beginners-what-is-apache-kafka.html
- https://www.facebook.com/notes/cộng-đồng-big-data-việt-nam/tiếp-cận-kafka-thông-qua-confluent-platform/884414712076055/
All rights reserved
