
Apache Kafka: Hệ thống truyền thông điệp thời gian thực
Mở đầu
Trong kỷ nguyên của Big Data và Microservices, việc truyền tải dữ liệu giữa các thành phần trong hệ thống không đơn thuần chỉ là gửi một gói tin từ A đến B. Hãy tưởng tượng bạn đang xây dựng một hệ thống thương mại điện tử: khi một đơn hàng được tạo, thông tin này cần được gửi đến kho hàng, đơn vị vận chuyển, hệ thống email thông báo, và cả bộ phận phân tích dữ liệu.
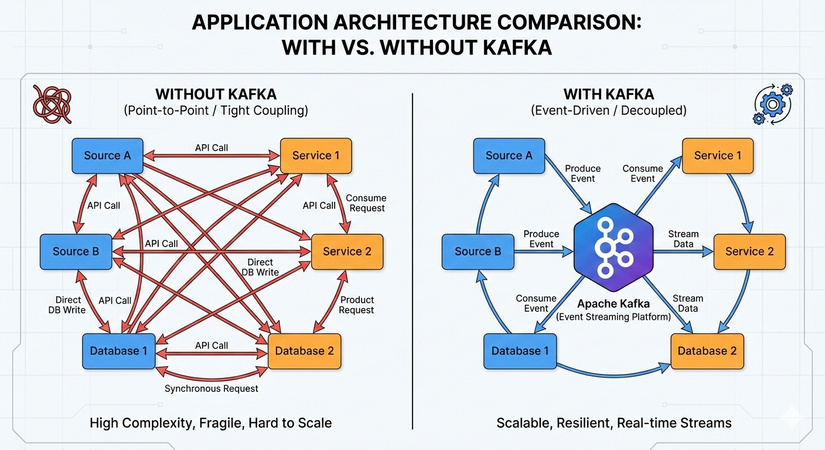
Nỗi lo mang tên "Kiến trúc mạng nhện" (Spaghetti Architecture)
Thời gian đầu, chúng ta thường dùng giao thức HTTP hoặc các kết nối trực tiếp (Point-to-Point). Nhưng khi hệ thống phình to ra với hàng chục dịch vụ, số lượng kết nối sẽ tăng lên theo cấp số nhân. Việc quản lý các kết nối này trở thành một cơn ác mộng: chỉ cần một dịch vụ đích gặp sự cố hoặc phản hồi chậm, toàn bộ dây chuyền phía trước có thể bị nghẽn theo.
Apache Kafka - Vị cứu tinh cho dòng chảy dữ liệu
Đó là lúc Apache Kafka xuất hiện. Được khởi tạo bởi LinkedIn và sau đó trở thành dự án mã nguồn mở của Apache, Kafka không chỉ đơn thuần là một "người đưa thư" (Message Broker) như RabbitMQ hay ActiveMQ.
Kafka được định nghĩa là một Distributed Streaming Platform (Nền tảng truyền dữ liệu phân tán). Thay vì chỉ gửi tin nhắn rồi xóa đi, Kafka hoạt động như một cuốn sổ cái (Log) khổng lồ, lưu trữ dữ liệu theo thời gian thực, cho phép nhiều bên cùng truy cập và xử lý dữ liệu đó một cách độc lập và bền bỉ.
Tại sao chúng ta cần quan tâm đến Kafka?
Nếu bạn đang tìm kiếm một giải pháp có:
- Tốc độ cực nhanh: Khả năng xử lý hàng triệu bản ghi mỗi giây với độ trễ cực thấp.
- Khả năng mở rộng (Scalability): Dễ dàng nâng cấp hệ thống bằng cách thêm server mà không cần dừng dịch vụ.
- Độ tin cậy cao: Dữ liệu được lưu trữ an toàn trên đĩa cứng và có cơ chế sao lưu tự động.
Thì Kafka chính là câu trả lời. Trong bài viết này, mình sẽ cùng các bạn bóc tách những khái niệm "vỡ lòng" nhất để hiểu tại sao Kafka lại trở thành xương sống cho hạ tầng dữ liệu của các ông lớn như Netflix, Uber hay LinkedIn.
Các khái niệm cốt lõi
Để làm việc với Kafka, trước hết chúng ta cần "đồng bộ" về mặt ngôn ngữ. Có 5 khái niệm cơ bản mà bạn nhất định phải nằm lòng:
Producer và Consumer
Đây là hai nhân vật chính trong mọi cuộc hội thoại của Kafka:
- Producer (Người sản xuất): Là các ứng dụng gửi dữ liệu vào Kafka. Ví dụ: Một dịch vụ web gửi log truy cập của người dùng.
- Consumer (Người tiêu thụ): Là các ứng dụng đọc dữ liệu từ Kafka để xử lý. Ví dụ: Một ứng dụng phân tích dữ liệu đọc log để đếm số lượt xem trang.
Topic: "Thùng chứa" dữ liệu
Hãy tưởng tượng Topic giống như một cái tên bảng trong Database hoặc một thư mục trên máy tính. Dữ liệu trong Kafka được phân loại theo các Topic.
Ví dụ: Bạn có topic order_created để chứa thông tin đơn hàng và topic user_logs để chứa hành vi người dùng.
Một Topic có thể có rất nhiều Producer gửi vào và nhiều Consumer đọc ra cùng lúc.
Partition: Bí mật của sự mạnh mẽ
Đây là điểm khác biệt lớn nhất của Kafka. Một Topic không chỉ là một tệp đơn lẻ mà được chia thành nhiều Partition (phân vùng).
- Xử lý song song: Dữ liệu của một Topic được rải đều ra các Partition, giúp nhiều Consumer có thể đọc dữ liệu cùng lúc từ các Partition khác nhau.
- Thứ tự dữ liệu: Kafka chỉ đảm bảo thứ tự của các tin nhắn trong cùng một Partition. Điều này cực kỳ quan trọng khi bạn thiết kế hệ thống.
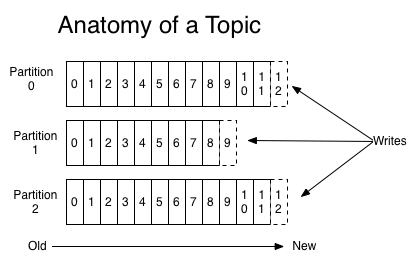
Tham chiếu: https://medium.com/javarevisited/kafka-partitions-and-consumer-groups-in-6-mins-9e0e336c6c00
Broker và Cluster
- Broker: Là một server vật lý hoặc server ảo chạy Kafka. Một Broker có thể chứa hàng nghìn Partition và xử lý hàng triệu tin nhắn.
- Cluster: Một nhóm các Broker làm việc cùng nhau được gọi là một Cluster. Khả năng chịu lỗi của Kafka nằm ở đây: nếu một Broker "ngỏm", các Broker khác trong Cluster sẽ gánh vác thay ngay lập tức.
Offset
Mỗi tin nhắn khi đi vào một Partition sẽ được gán một con số định danh duy nhất và tăng dần, gọi là Offset.
- Consumer sẽ dựa vào Offset để biết mình đã đọc đến đâu.
- Nếu Consumer bị crash và khởi động lại, nó chỉ cần hỏi Kafka: "Cho tôi đọc tiếp từ Offset thứ X" để không bỏ sót bất kỳ dữ liệu nào.
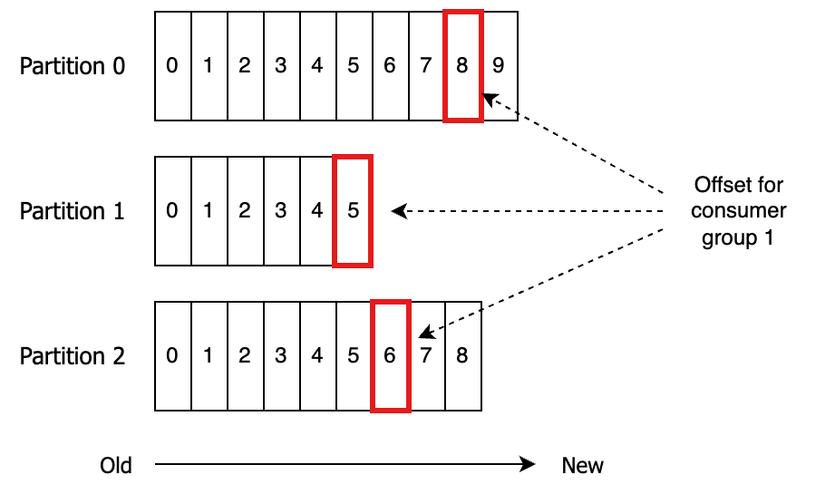
Tham chiếu: https://codingharbour.com/apache-kafka/kafka-consumer-committing-consumer-group-offset/
Cơ chế hoạt động của Kafka
Sau khi đã nắm rõ các khái niệm, câu hỏi đặt ra là: Kafka điều phối dòng dữ liệu khổng lồ đó như thế nào mà không bị rối?
Quy trình gửi và nhận tin nhắn
Mọi thứ trong Kafka đều xoay quanh một mô hình gọi là Pub/Sub (Publish/Subscribe) nhưng được nâng cấp:
- Publish: Producer đẩy dữ liệu vào một Topic cụ thể. Kafka sẽ quyết định dữ liệu đó nằm ở Partition nào (dựa trên Key của tin nhắn hoặc thuật toán Round-robin).
- Store: Broker nhận tin nhắn, ghi nó xuống đĩa cứng (Commit Log). Điều này đảm bảo dù hệ thống có mất điện, dữ liệu vẫn còn đó.
- Subscribe: Consumer chủ động "kéo" (Pull) dữ liệu từ Broker về thay vì đợi Broker đẩy sang. Điều này giúp Consumer tự kiểm soát tốc độ xử lý của chính mình (Backpressure).
Consumer Group: Sức mạnh của sự hiệp lực
Đây là một cơ chế cực kỳ hay của Kafka để giải quyết bài toán cân bằng tải (Load Balancing). Nhiều Consumer có thể cùng tham gia vào một Consumer Group để cùng nhau chia sẻ việc đọc dữ liệu từ một Topic.
- Mỗi Partition trong một Topic sẽ chỉ được đọc bởi duy nhất một Consumer trong cùng một Group tại một thời điểm.
- Nếu bạn có 3 Partition và 3 Consumer trong một nhóm, mỗi Consumer sẽ xử lý 1 Partition. Nếu 1 Consumer bị hỏng, 2 Consumer còn lại sẽ tự động chia nhau gánh vác Partition "mồ côi" đó.
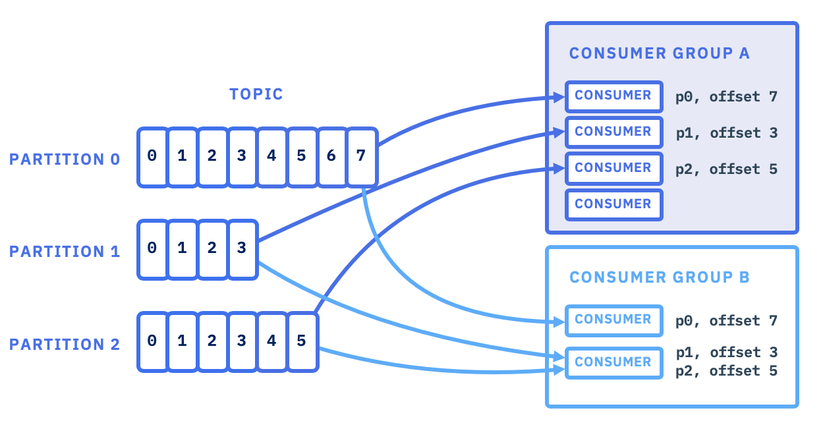 Tham chiếu: https://ibm-cloud-architecture.github.io/refarch-eda/technology/kafka-consumers/
Tham chiếu: https://ibm-cloud-architecture.github.io/refarch-eda/technology/kafka-consumers/
Cơ chế lưu trữ "Append-only"
Kafka không cập nhật hay xóa dữ liệu ngay khi vừa đọc xong. Thay vào đó:
- Dữ liệu mới luôn được ghi vào cuối của tệp log (Append-only). Việc ghi tuần tự này cực kỳ nhanh vì không tốn thời gian tìm kiếm trên đĩa (Disk seek).
- Dữ liệu sẽ tồn tại trong một khoảng thời gian nhất định (mặc dù mặc định thường là 7 ngày) hoặc cho đến khi Topic đạt một dung lượng tối đa, sau đó Kafka mới xóa các dữ liệu cũ nhất.
Vai trò của Zookeeper / KRaft
Để các Broker trong Cluster biết ai đang làm "Trưởng nhóm" (Leader) cho Partition nào, chúng cần một người điều phối:
- Zookeeper: Đóng vai trò quản lý metadata, bầu chọn Leader và giám sát trạng thái của các Broker.
- KRaft: Đây là cơ chế mới (từ Kafka 2.8+), giúp Kafka tự quản lý metadata mà không cần phụ thuộc vào Zookeeper, giúp hệ thống gọn nhẹ và dễ vận hành hơn.
Tại sao nên chọn Kafka?
Tại sao không phải là một hàng đợi tin nhắn (Message Queue) thông thường mà lại là Kafka? Câu trả lời nằm ở 3 trụ cột:
- Khả năng mở rộng (Scalability): Kafka được thiết kế để chạy trên một cụm (Cluster). Khi lượng dữ liệu tăng lên, bạn chỉ cần ném thêm Broker vào hệ thống. Việc phân chia Partition giúp tải trọng được dàn đều trên các máy chủ.
- Hiệu suất cực cao (High Throughput): Nhờ cơ chế ghi log tuần tự (Sequential I/O) và kỹ thuật Zero-copy, Kafka có thể xử lý hàng triệu tin nhắn mỗi giây với phần cứng thông thường.
- Độ tin cậy và Khả năng chịu lỗi (Fault Tolerance): Kafka sao chép (Replication) dữ liệu qua nhiều Broker khác nhau. Nếu một máy chủ "cháy", dữ liệu vẫn an toàn ở máy chủ khác.
Các trường hợp sử dụng thực tế
Kafka không chỉ là lý thuyết suông, nó đang vận hành những hệ thống lớn nhất thế giới:
- Messaging: Dùng làm hệ thống truyền tin giữa các Microservices, giúp chúng giao tiếp bất đồng bộ và giảm sự phụ thuộc lẫn nhau (Decoupling).
- Website Activity Tracking: Theo dõi mọi click chuột, lượt view trang của người dùng theo thời gian thực để đưa ra gợi ý sản phẩm ngay lập tức (như cách Netflix hay Shopee đang làm).
- Log Aggregation: Thay vì log nằm rải rác ở hàng trăm server, Kafka thu thập tất cả về một nơi tập trung để xử lý hoặc đẩy vào Elasticsearch/Logstash.
- Stream Processing: Xử lý dữ liệu "trên đường đi". Ví dụ: Hệ thống ngân hàng phân tích dòng tiền ngay khi giao dịch vừa xảy ra để phát hiện dấu hiệu lừa đảo (Fraud Detection).
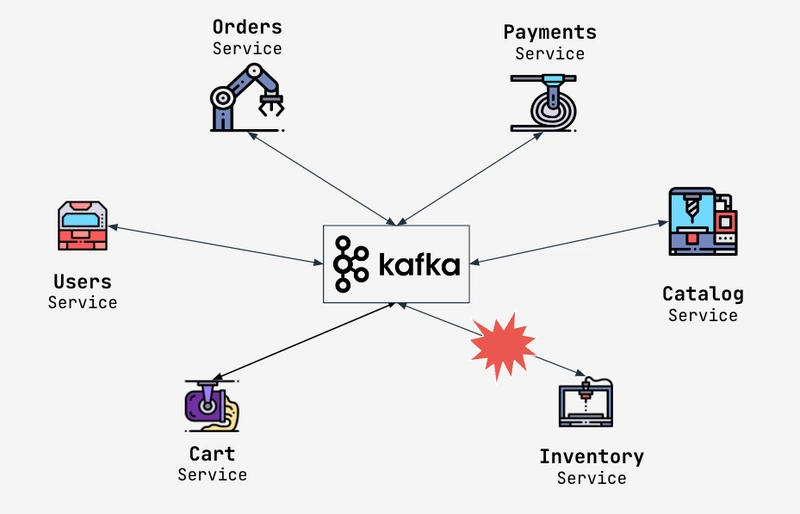
Tham chiếu: https://dev.to/aadarsh-nagrath/understanding-the-need-for-apache-kafka-i44
Lời kết
Apache Kafka có vẻ phức tạp khi mới tiếp cận, nhưng một khi đã hiểu được tư duy về Log và Partition, bạn sẽ thấy nó cực kỳ logic và mạnh mẽ. Đây chính là chìa khóa để mở ra cánh cửa bước vào thế giới Big Data và hệ thống phân tán.
Hy vọng bài viết này giúp các bạn có cái nhìn tổng quan nhất về Kafka. Ở các bài viết sau, mình sẽ đi sâu hơn vào cách cài đặt và code demo cụ thể bằng một ngôn ngữ phổ biến nhé!
Tài liệu tham khảo:
- Apache Kafka Documentation: https://kafka.apache.org/documentation/
- Kafka: The Definitive Guide (Gwen Shapira).
All rights reserved
