[Android] Sử dụng thư viện tesseract ocr cho nhận dạng chữ viết.
Bài đăng này đã không được cập nhật trong 4 năm
1. Giới thiệu về TESSERACT OCR
OCR - Optical Character Recognition tạm dịch là nhận dạng kí tự quang học, nôm na hiểu thì đây là kỹ thuật giúp nhận dạng các ký tự trên một bức ảnh, về định nghĩa cụ thể hơn thì các bạn có thể xem trên wiki: https://en.wikipedia.org/wiki/Optical_character_recognition TESSERACT OCR là một thư viện open source nhận dạng chữ viết được phát triển bởi google, nó hỗ trợ rất nhiều nển tảng Mac,Windows,iOS,Android... Bài viết dưới đây sẽ hướng dẫn mọi người cách intergrade tesseract vào trong android studio project. Hiện tại thì trong android sdk đã cung cấp api nhận dạng chữ viết, tuy nhiên số lượng ngôn ngữ được hỗ trợ không nhiều, chủ yếu là các ngôn ngữ có nguồn gốc latinh, ví dụ như Anh, Pháp,Ý... Vậy đối với những ngôn ngữ như tiếng Việt, tiếng Nhật, tiếng Trung thì sao. Câu trả lời là TESSERACT OCR sẽ giúp chúng ta thực hiện điều đó. tesseract-android-tools là repo chính thức của thử viện này, tuy nhiên để sử dụng được nó, thì chúng ta phải tự build lại thư viện qua hàng loạt command, nói chung là phức tạp. Thay vào đó ta có thể sử dụng một repo khác rmtheis/tess-two, repo này fork từ tesseract-android-tools, tuy nhiên tác giả đã thêm một số tiện ích vào đó, và việc intergrade vào android studio project cũng hoàn toàn đơn giản. Vậy giờ chúng ta sẽ làm việc với rmtheis/tess-two.
2. Sử dụng rmtheis/tess-two
Step 1. Tạo android project, ví dụ là tesseractdemo
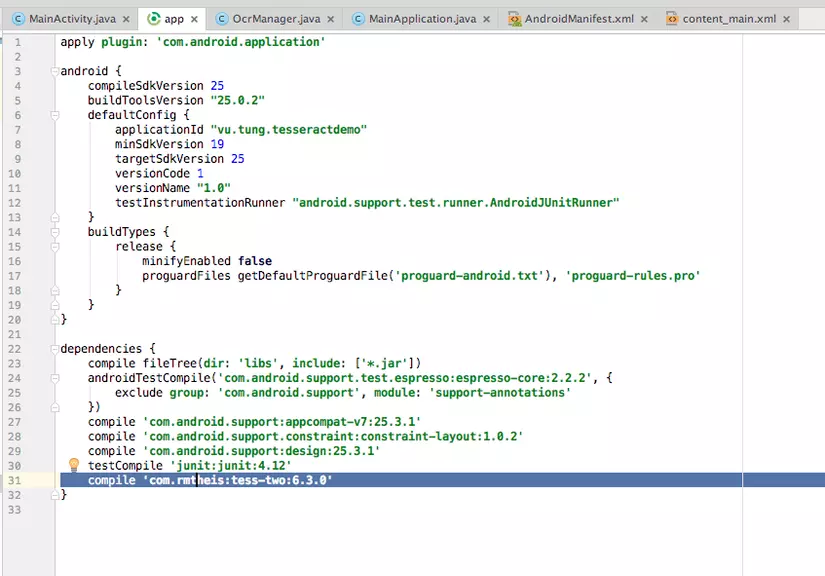
Step 2: thêm dependency của [ rmtheis/tess-two] vào file build.gradle trong thư mục app
Vào rmtheis/tess-two, copy đoạn mã sau compile 'com.rmtheis:tess-two:6.3.0' lúc này file build.gradle sẽ trong giống như sau:
 Vào
Vào Build-> Make Project, nếu không có lỗi thì việc intergrade thư viện vào project đã thành công.
Step 3: Download trainned data - có thể hiểu là tập dữ liệu này đã được "học", mỗi ngôn ngữ có một dữ liệu file học riêng.
Vào rmtheis/tess-two, tìm đến chỗ trained data file , đây là nơi chứa tất cả các tập dữ liệu đã được học tương ứng với các ngôn ngữ. Ví dụ giờ bạn muốn nhận dạng cho tiếng việt,
download file vie.traineddata .
Step 4: Sử dụng api, tạo một file OcrManager.java
package vu.tung.tesseractdemo;
import android.graphics.Bitmap;
import com.googlecode.tesseract.android.TessBaseAPI;
import vu.tung.tesseractdemo.MainApplication;
/**
* Created by vu.tien.tung on 4/24/17.
*/
public class OcrManager {
TessBaseAPI baseAPI = null;
public void initAPI()
{
baseAPI = new TessBaseAPI();
// after copy, my path to trainned data is getExternalFilesDir(null)+"/tessdata/"+"vie.traineddata";
// but init() function just need parent folder path of "tessdata", so it is getExternalFilesDir(null)
String dataPath = MainApplication.instance.getTessDataParentDirectory();
baseAPI.init(dataPath,"vie");
// language code is name of trainned data file, except extendsion part
// "vie.traineddata" => language code is "vie"
// first param is datapath which is part to the your trainned data, second is language code
// now, your trainned data stored in assets folder, we need to copy it to another external storage folder.
// It is better do this work when application start firt time
}
public String startRecognize(Bitmap bitmap)
{
if(baseAPI ==null)
initAPI();
baseAPI.setImage(bitmap);
return baseAPI.getUTF8Text();
}
}
Để ý đến code baseAPI.init(dataPath,"vie"); có 2 đối số truyền vào thứ nhất là dataPath và languageCode , chúng ta sẽ nói rõ hơn cho từng đối số:
- dataPath:
*.traineddatacó thể được lưu ở internal hoặc external storage, tuy nhiên*.traineddataphải nằm trong trong một thư mục được đặt tên làtessdata, giá trị củadataPathsẽ phải đường dẫn đến thư mục cha của thư mụctessdata. Giả sử đường dẫn tuyệt đối đến file*.traineddatalàx/y/z/t/tessdata/.traineddata, khi đó giá trị của đối sốdataPathsẽ làx/y/z/t/. Trong đoạn code trên filevie.traineddatađược lưu ởgetExternalFilesDir(null)+"/tessdata/"+"vie.traineddata";khi đó, giá trị cần truyền vào cho hàminit()làgetExternalFilesDir(null). - languageCode: tên của file
*.traineddata, ví dụvie.traineddatathìlanguageCodesẽ làvie,jpn.traineddatathìlanguageCodesẽ làjpn. Vậy là đã làm rõ đối số phải truyền vào cho hàminit()là gì, trongonCreatecủaMainActivitythêm đoạn code sau:
OcrManager manager = new OcrManager();
manager.initAPI();
Build lên thiết bị thật, nếu việc khở tạo thành công thì sẽ có đoạn log dưới
I/Tesseract(native): Initialized Tesseract API with language=vie
- Tiếp theo để nhận dạng chữ viết, ta để ý đến hàm
public String startRecognize(Bitmap bitmap), trong hàm này ta sẽ gọisetImage(bitmap)cho ảnh nào muốn nhận dạng,getUTF8Text();sẽ trả về kết quả là các kí tự được nhận dạng, - Toàn bộ quá trình trên được demo trong video phái dưới:
- Link source
All rights reserved
