An Introduction to Neural Network Part: 01
Bài đăng này đã không được cập nhật trong 4 năm
In each hemisphere of our brain, humans have a principal visual cortex, also known as V1, containing 140 million neurons, with tens of billions of connections between them. And yet human vision involves not just V1, but an entire series of visual cortices - V2, V3, V4, and V5 - doing progressively more complex image processing. We carry in our heads a supercomputer, tuned by evolution over hundreds of millions of years, and superbly adapted to understand the visual world.From there the idea of Neural Network has come.
An Artificial Neural Network (ANN) is an data processing paradigm that is inspired by the brain’s nerval systems,The key element of this paradigm is the novel structure of the information processing system. NNs, like people, learn by example information, and tries its best to act accordingly. Learning in nerval systems involves adjustments to the synaptic connections that exist between the neurons. This is true of NNs as well.
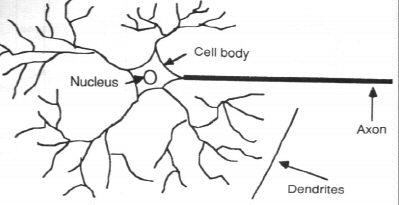 fig: Biological Neuron
Form the figure above, the human brain, a typical neuron collects signals from others through a host of fine structures called dendrites. The neuron sends out spikes of electrical activity through a long, thin stand known as an axon, which splits into thousands of branches. At the end of each branch, a structure called a synapse converts the activity from the axon into electrical effects that inhibit or excite activity in the connected neurons.
fig: Biological Neuron
Form the figure above, the human brain, a typical neuron collects signals from others through a host of fine structures called dendrites. The neuron sends out spikes of electrical activity through a long, thin stand known as an axon, which splits into thousands of branches. At the end of each branch, a structure called a synapse converts the activity from the axon into electrical effects that inhibit or excite activity in the connected neurons.
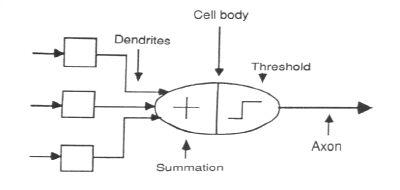 **fig: Model of a neuron **
**fig: Model of a neuron **
When a neuron receives excitatory input that is sufficiently large compared with its inhibitory input, it sends a spike of electrical activity down its axon. Learning occurs by changing the effectiveness of the synapses so that the influence of one neuron on another changes. We conduct these neural networks by first trying to deduce the essential features of neurons and their interconnections. We then typically program a computer to simulate these features.
An artificial neuron is a device with many inputs and one output. The neuron has two modes of operation; the training mode and the using mode. In the training mode, the neuron can be trained to fire (or not), for particular input patterns. In the using mode, when a taught input pattern is detected at the input, its associated output becomes the current output. If the input pattern does not belong in the taught list of input patterns, the firing rule is used to determine whether to fire or not. The firing rule is an important concept in neural networks and accounts for their high flexibility. A firing rule determines how one calculates whether a neuron should fire for any input pattern. It relates to all the input patterns, not only the ones on which the node was trained on previously.
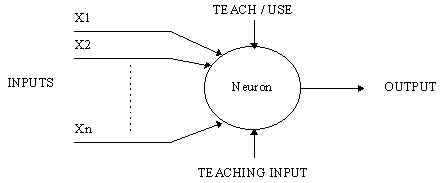 fig: Artificial Neuron
fig: Artificial Neuron
- Input Layer - The activity of the input units represents the raw information that is fed into the network.
- Hidden Layer- The activity of each hidden unit is determined by the activities of the input units and the weights on the connections between the input and the hidden units.
- Output Layer- The behavior of the output units depends on the activity of the hidden units and the weights between the hidden and output units. *
This simple type of network is interesting because the hidden units are free to construct their own representations of the input. The weights between the input and hidden units determine when each hidden unit is active, and so by modifying these weights, a hidden unit can choose what it represents. In general, initial weights are randomly chosen, with typical values between -1.0 and 1.0 or -0.5 and 0.5. There are two types of NNs. The first type is known as
- Fixed Networks – where the weights are fixed
- Adaptive Networks – where the weights are changed to reduce prediction error. The most basic method of training a neural network is trial and error. If the network isn't behaving the way it should, change the weighting of a random link by a random amount. If the accuracy of the network declines, undo the change and make a different one. It takes time, but the trial and error method does produce results.
- Recall: Adaptive networks are NNs that allow the change of weights in its connections. The learning methods can be classified in two categories:
Supervised Learning
Supervised learning which incorporates an external teacher, so that each output unit is told what its desired response to input signals ought to be. An important issue concerning supervised learning is the problem of error convergence, ie the minimization of error between the desired and computed unit values. The aim is to determine a set of weights which minimizes the error. One well-known method, which is common to many learning paradigms is the least mean square (LMS) convergence. In this sort of learning, the human teacher’s experience is used to tell the NN which outputs are correct and which are not. This does not mean that a human teacher needs to be present at all times, only the correct classifications gathered from the human teacher on a domain needs to be present. The network then learns from its error, that is, it changes its weight to reduce its prediction error.
Unsupervised Learning
Unsupervised learning uses no external teacher and is based upon only local information. It is also referred to as self-organization, in the sense that it self-organizes data presented to the network and detects their emergent collective properties. The network is then used to construct clusters of similar patterns. This is particularly useful is domains were a instances are checked to match previous scenarios. For example, detecting credit card fraud.
All rights reserved
