Ai nói SPHINX chỉ là bức tượng? Gặp gỡ nhạc trưởng AI thế hệ mới!
Bài đăng này đã không được cập nhật trong 2 năm
A. Tổng quan
1. Giới thiệu
Nếu bạn là người yêu thích thần thoại Hy Lạp, SPHINX là một sinh vật huyền thoại với thân sư tử và đầu người. Nếu bạn là người yêu thích khảo cổ học, SPHINX là những bức tượng linh thiêng canh gác các kim tự tháp cổ kính. Hay nếu ở lĩnh vực hàng không, SPHINX lại là tên của một loại radar tiên tiến. SPHINX thật sự là một cụm từ xuất hiện ở khá nhiều lĩnh vực. Tuy nhiên, chỉ khi đặt trong bối cảnh công nghệ AI hiện nay, thì mình mới thấy SPHINX "xinh phết"!
Trong rừng rậm của các Multimodal Large Language Model (MLLM), SPHINX không chỉ là một "siêu nhân" mà còn là "nhạc trưởng" điều khiển dàn nhạc gồm các "ông lớn" của AI. Tưởng tượng nếu bạn có thể cho các chuyên gia như Albert Einstein, Isaac Newton, và Thomas Edison Nikola Tesla làm việc cùng nhau trong một dự án! Đó chính là những gì SPHINX làm - kết hợp sức mạnh của các mô hình AI hàng đầu vào một "rọ" để xử lý đa tác vụ một cách mượt mà. Và lý do mà mình gọi là “siêu nhân” (hơi nói quá) chính là vì SPHINX có thể xử lý rất nhiều tác vụ, và có tiềm năng phát triển nhiều hơn nữa.
Không dài dòng hơn nữa, từ đây, mình xin phép “học thuật” hơn trong cách diễn giải nhé (và vừa tiếng anh vừa tiếng việt).
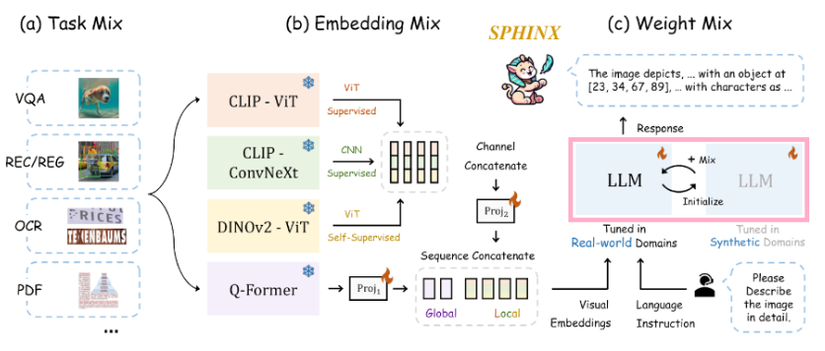
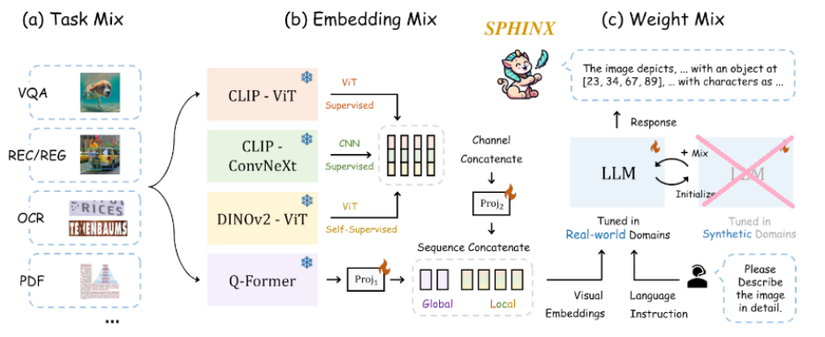
2. Pipeline
Dưới đây là những phương pháp, kỹ thuật mà tác giả đề xuất:
a. Liên quan đến dữ liệu:
- Chuẩn bị nhiều bộ dữ liệu đa dạng về nhiệm vụ (E).
- Chiến lược xử lý ảnh có độ phân giải cao (C).
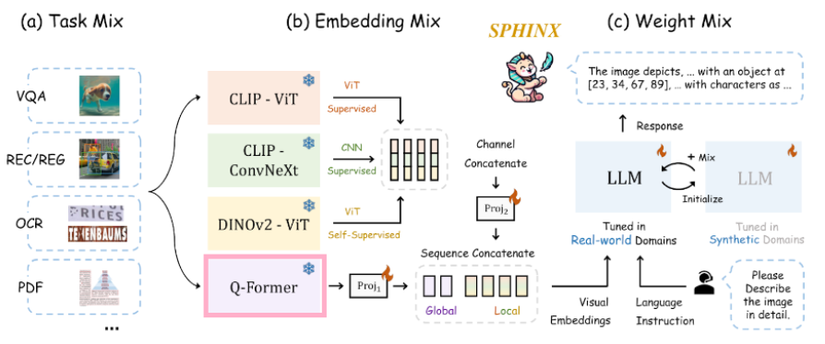
b. Module Vision Encoder:
- Kỹ thuật kết hợp thông tin của nhiều model Vision Encoder (B).
c. Module LLM Decoder:
- Unfreeze và pretrain LLM (D.2).
- Kết hợp weights của 2 LLMs (D.3).
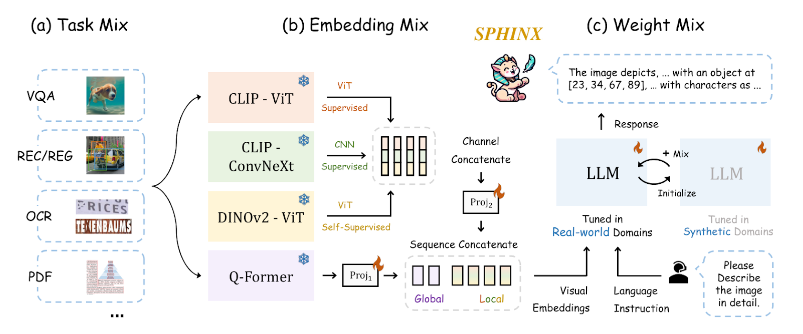
B. Vision Encoder: Kết hợp weights của nhiều model
1. Lý do
Mỗi một Vision Encoder đều mang trong mình những thông tin khác nhau về cả ngữ cảnh (semantic) lẫn độ chi tiết (fine-grained). Bạn có thể hiểu 5 người khác nhau cùng nhìn vào 1 bức ảnh thì chắc hẳn 5 góc nhìn ấy sẽ mang lại nhiều thông tin giá trị hơn 1 người đúng không nào?
2. Ý tưởng
Tác giả đã thiết kế một module với những sự kết hợp sau:
- Những backbone khác nhau (CNN và ViT).
- Cách mà model ấy được huấn luyện (supervised và self-supervised).
- Độ chi tiết của thông tin (global và local).
3. CNN và ViT
2 kỹ thuật này sẽ bổ trợ thông tin cho nhau:
- CNN với bộ kernel sẽ lấy thông tin chủ đạo về cách mà các vùng lân cận phụ thuộc lẫn nhau.
- ViT với kiến trúc transformer sẽ cung cấp thông tin tương tác tầm xa nhiều hơn.
Và 2 kỹ thuật này sẽ làm backbone cho CLIP và DINOv2 model, Cụ thể là CLIP-ConvNeXt và CLIP-ViT và DINOv2-ViT.
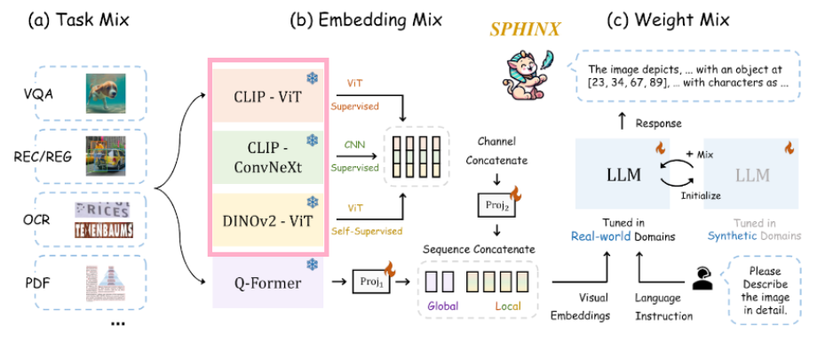
4. Supervised và self-supervised (DINOv2 + ViT)
Supervised model là model được huấn luyện để đưa ra dự đoán giống với label. Vậy thì còn self-supervised thì sao ?
Chắc hẳn các bạn cũng đã biết đến cách thiết kế mô hình này: Input -> Module 1 -> Module 2 -> Output. Mà ở đó, cả 2 module đều là Neural Network.
Chúng ta nói Module 2 là supervised model và module 1 là self-supervised model vì nó học “nhờ” từ kết quả của module 2. Mục tiêu duy nhất của kiểu model này là trích xuất đặc trưng có ích nhất từ input cho module 2.
Vậy nên việc kết hợp các phương thức training khác nhau thế này giúp cho thông tin trích xuất được đa chiều hơn.
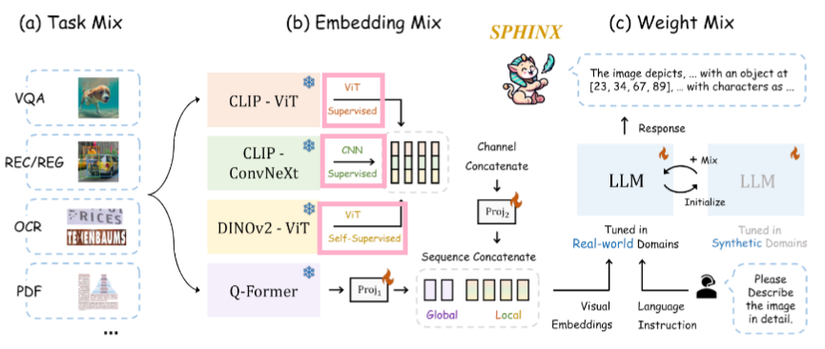
5. Thông tin global và local (Q-Former)
Như chúng ta đã biết, kernel của CNN được áp dụng trên từng mảnh vá của bức ảnh, và input của ViT là các mảnh vá của bức ảnh. Vậy nên cả CNN và ViT đều cung cấp thông tin dạng local.
Đó chính là lý do mà tác giả dùng Q-Former ở đây, kỹ thuật này sẽ trích xuất thông tin của bức ảnh một cách toàn cục, các bạn có thể tham khảo kỹ hơn ở BLIP2.
Cuối cùng, chúng ta kết hợp tất cả những đặc trưng thông tin của các module vào tạo thành 1 visual embeddings duy nhất, chứa cả global và local.
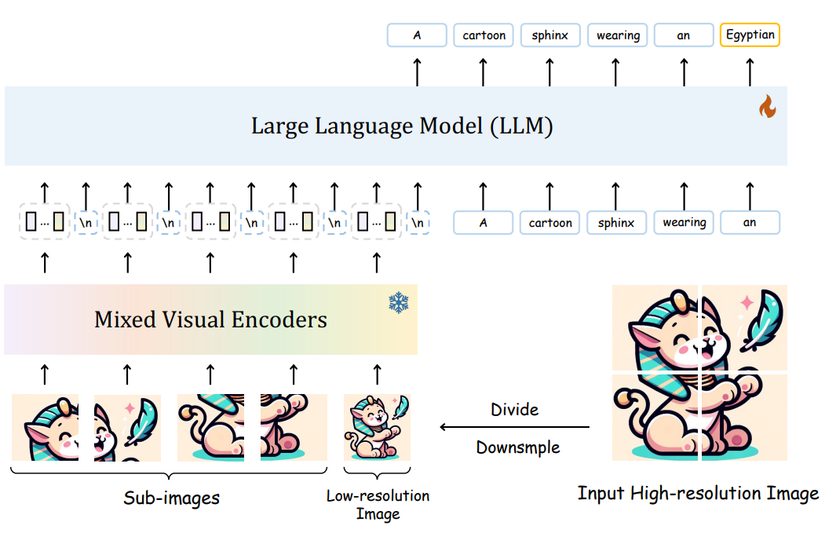
C. Chiến lược xử lý với ảnh có độ phân giải cao - Chia để trị
1. Lý do:
Một số open-source MLLMs nổi tiếng như BLIP, LLava đóng băng module Vision Encoder trong suốt quá trình training để có thể dùng lại được những pretrained weights. Chính vì thế, kích thước của ảnh thường giảm xuống còn 224x224. Và tất nhiên điều này sẽ làm bức ảnh bị bóp méo và giảm độ chi tiết.
2. Giải pháp:
Giải pháp đơn giản nhất chính là tăng kích cỡ, tuy nhiên việc này không tối ưu vì 2 lý do sau:
- Kích cỡ ảnh tăng đồng nghĩa với việc positional encoding vectors trong ViT cũng phải tăng, điều này sẽ làm hại đến spatial cues (thứ tự không gian).
- Độ phức tạp tính toán của ViT sẽ tăng bậc hai theo kích thước của ảnh đầu vào.
-> Tác giả đã đề xuất ra một chiến lược tối ưu hơn: Chia để trị
3. Ý tưởng:
Từ 1 ảnh phân giải cao, chúng ta chia thành 5 ảnh: 4 ảnh góc của bức ảnh và ảnh bị thu nhỏ xuống còn 224x224. Quá trình đi vào bộ Vision Encoder là độc lập. Sau đó chúng ta sẽ concatenate 5 visual embeddings thành 1 embedding cuối cùng để làm đầu vào của LLM decoder.
Điểm lợi của kĩ thuật này: Vừa có thông tin global, vừa tập trung hơn được vào những đặc trưng local, vừa giữ được những chi tiết vốn có.
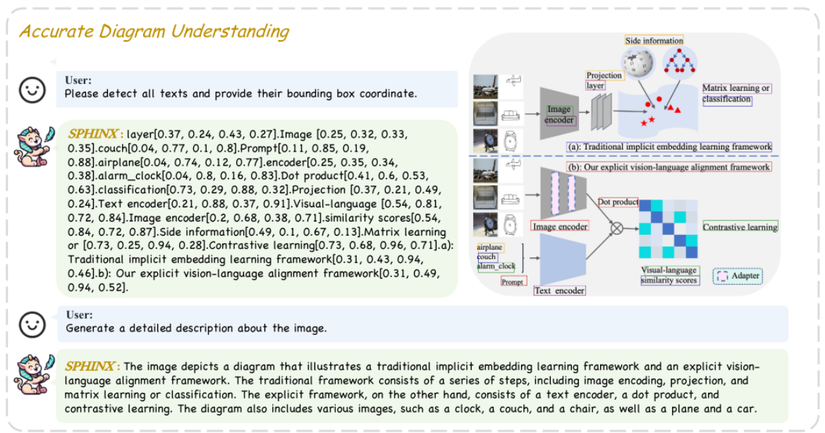
D. Training giai đoạn 1- Vision-language alignment
1. Mục đích:
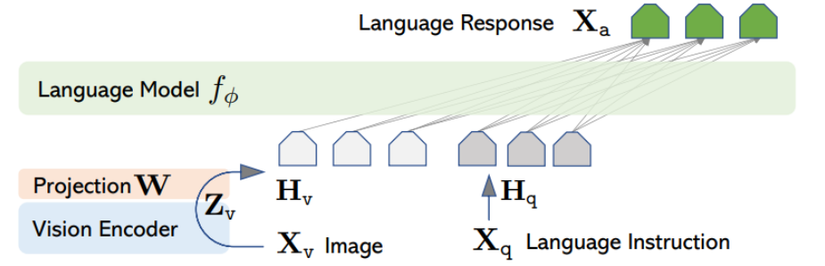
Khác với LLM, chỉ xử lý với dữ liệu dạng chữ, bài toán MLLM Vision-Language phải xử lý thêm cả phần ảnh, có nghĩa là input của bộ LLM decoder không phải chỉ thông tin của mỗi chữ nữa, mà còn có cả ảnh. Tuy nhiên đây là một dạng thông tin mà LLM không hiểu.
Vậy thì để tận dụng được sức mạnh sinh văn bản của các mô hình ngôn ngữ lớn hiện nay, thuật ngữ Vision-language alignment được ra đời, đề cập đến quá trình huấn luyện sao cho Vision model và Language model hiểu nhau hơn. Kiến trúc chung như sau: Vision Encoder -> Projection layers -> LLM decoder.
- Vision Encoder: Nhận input là ảnh, nhiệm vụ là trích xuất nhiều thông tin có ích nhất.
- LLM Decoder: Nhận input là thông tin của cả ảnh và text, nhiệm vụ là sinh ra text.
- Projection layers:
- Nhận những thông tin mà Vision Encoder “nói” và “phiên dịch” cho LLM Decoder hiểu.
- Điều chỉnh kích thước sao cho đúng với kích cỡ đầu vào của LLM Decoder.
2. Unfreeze và pretrain LLM
a. Lý do:
Những open-source MLLMs hiện có đều đóng băng weights của LLM trong suốt của trình pretrain cho bài toán vision-language alignment với dữ liệu dạng image-caption, và chỉ train lớp projection layers .
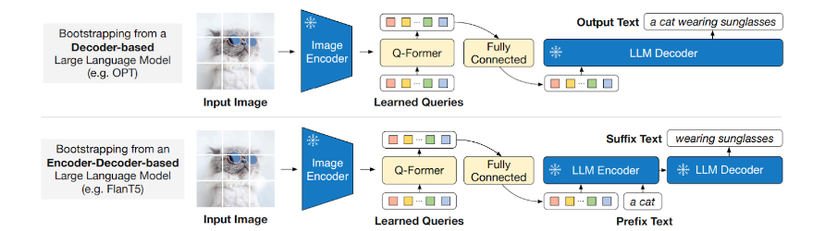
Điều này vừa có lợi, vừa có hại:
- Về mặt lợi: Giúp cho LLMs không bị overfit vào việc sinh ra những câu text ngắn, vì phần text trong bộ dữ liệu image-caption thường khá ngắn.
- Về mặt hại: LLMs không thể học được thông tin của ảnh và thông tin tương quan giữa text và ảnh, đồng nghĩa với việc bỏ qua một lượng lớn thông tin từ ảnh khi sinh ra các đoạn văn.
Vậy thì có cách nào giải quyết phần hại mà vẫn giữ nguyên mặt lợi không?
b. Giải pháp
Câu trả lời nằm ở ý tưởng: Unfreeze và pretrain LLM và bắt model học thêm 1 bộ dữ liệu nữa trong quá trình này (Đây là một điểm khác biệt của SPHINX). Chi tiết các bước trong giai đoạn này như sau:
-
Chúng ta sẽ pretrain LLM (LLama2) trên bộ dữ liệu thực tế (LAION-400M). Input ở đây sẽ là visual embeddings (output của module Vision Encoder).
-
Sau khi pretrain xong LLM đầu tiên, chúng ta sẽ lấy weights làm điểm bắt đầu để train chính LLM đó nhưng trên một bộ dữ liệu nhân tạo (LAION-COCO). Lý do thì ngay phần sau mình sẽ giải thích.
-
Ngoài ra, chúng ta sẽ pretrain LLM với 1 bộ dữ liệu nữa, đó là RefinedWeb (một bộ dữ liệu toàn chữ).
-
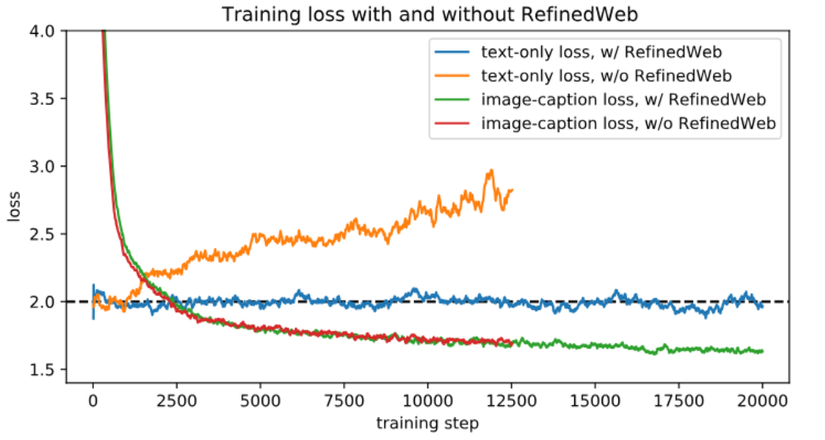
Mỗi một lần huấn luyện, chúng ta sẽ lấy ra một điểm dữ liệu trong RefinedWeb và một vài điểm dữ liệu trong bộ image-caption. Sau đó huấn luyện lần lượt với 2 hàm loss, một hàm loss bắt model phải giữ được khả năng sinh ra được đoạn văn dài, hàm còn lại bắt model phải mô tả đúng nội dung của bức ảnh.
Điều này thực sự rất có hiệu quả, khi không được huấn luyện cùng với bộ RefinedWeb, model bị overfit rất nặng (màu cam). Trong trường hợp ngược lại, model không thể bị overfit trong việc sinh ra các đoạn văn ngắn (màu xanh lá cây).
3. Tổng hợp kiến thức bằng cách kết hợp LLM weights
a. Lý do
Một bộ dữ liệu nhân tạo có thể chứa những thông tin riêng biệt mà bộ dữ liệu thực tế không có. Vậy nên tác giả muốn LLM có khả năng xử lý cả 2 loại thông tin này.
b. Giải pháp
Chúng ta có thể huấn luyện model trên 2 bộ dữ liệu cùng một lúc, tuy nhiên tác giả bảo rằng điều này sẽ khiến model khó hội tụ và dường như là quá sức.
Vậy thì giải pháp chính là kết hợp weights của 2 LLMs
Sau khi thu được 2 LLMs ở bước pretrain, chúng ta sẽ kết hợp weights của 2 LLMs theo như công thức:
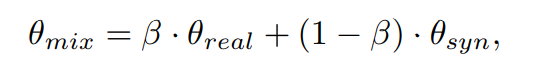
Trong đó, θ là weights, 𝛽 là một hằng số để quyết định xem weights của LLM nào có ảnh hưởng hơn.
Phương pháp này đem đến điểm lợi: Mô hình ngôn ngữ lớn của chúng ta sẽ không bị ảnh hưởng bởi 2 loại dữ liệu trái ngược nhau (một là dữ liệu thực, một là dữ liệu nhân tạo).
E. Training giai đoạn 2: Visual instruction-following learning
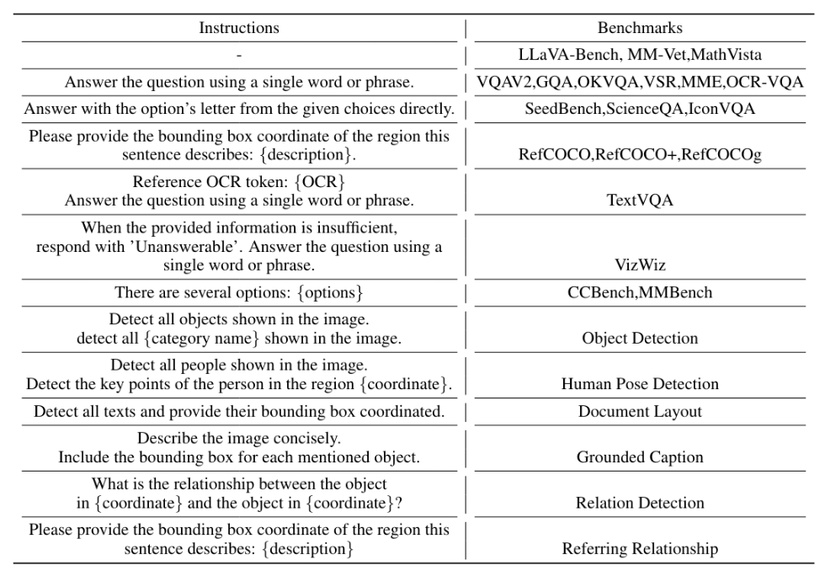
Với mục tiêu là cải thiện khả năng làm theo hướng dẫn cho đa tác vụ, thay vì là tập trung vào 1 khía cạnh cụ thể, tác giả đã thu thập dữ liệu với các tác vụ khác nhau và tiến hành training giai đoạn 2.
Một phần động lực để tác giả làm điều này đó là những open-source MLLMs :
- BLIP-series chỉ có thể thực hiện tác vụ VQA, Captioning, Reasoning.
- LLava-series thì có thêm OCR.
Những tác vụ mà SPHINX có thể làm được là:
- VQA
- Region-level referring expression comprehension/generation (REC/REG)
- Multi-object detection and relation reasoning
- Text-oriented chart/document VQA
- Human pose estimation


F. Kết quả
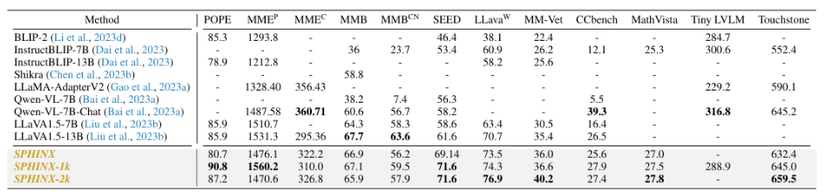
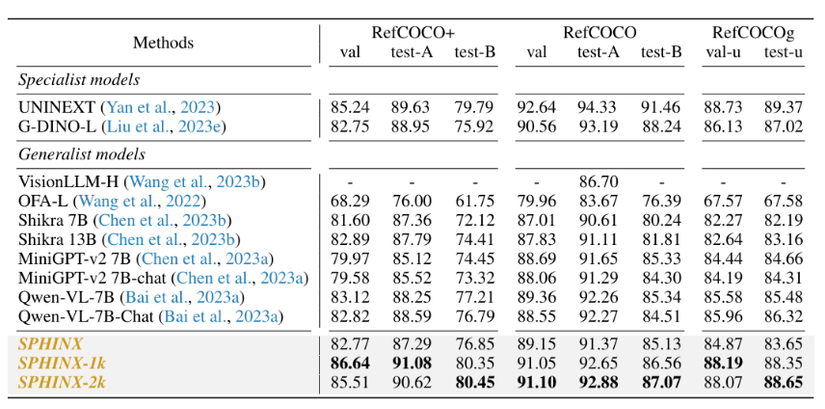
G. Ứng dụng
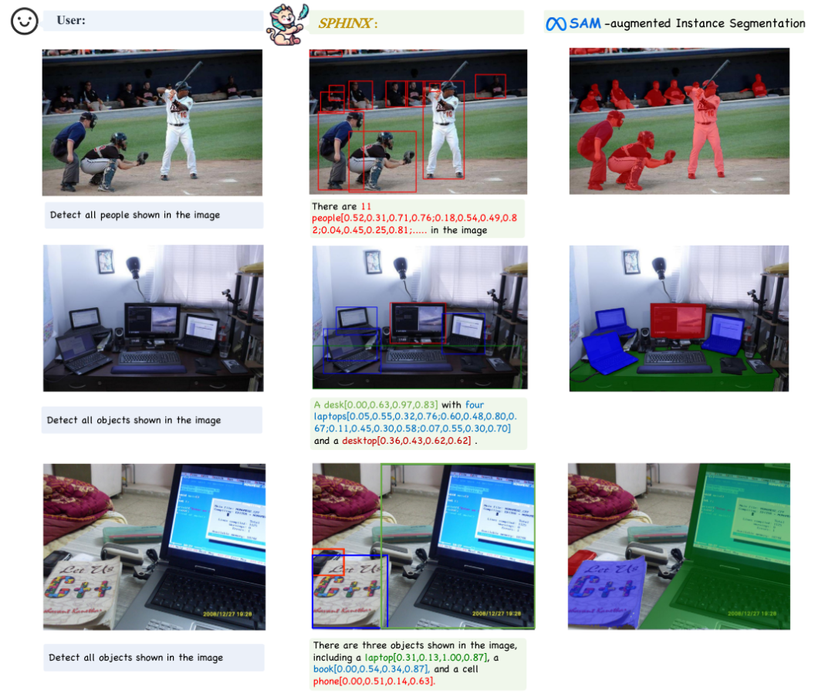
1. Kết hợp với SAM
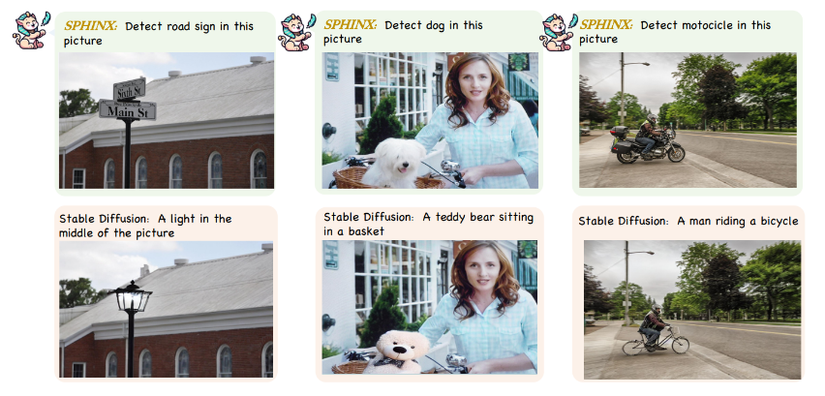
2. Kết hợp với Stable Diffusion
Phát hiện vật thể bằng SPHINX và segment bằng SAM, LaMa sẽ chịu trách nhiệm xóa vật thể đó. Cuối cùng, người dùng có thể đưa ra câu lệnh cho Stable Diffusion để tạo nội dung mới cho phần bị xóa.
3. Finetune SPHINX cho bài toán phân loại hình ảnh
Cụ thể ở đây là bộ dữ liệu ImageNet-1K. Tác giả sẽ chuyển câu lệnh hướng dẫn thành “Classify the image” và sửa đổi format phản hồi là “This is a [CLASS]”.
Chỉ với 1 epoch, SPHINX đạt 70.8% độ chính xác mà không dùng bất kì kĩ thuật data augmentation.
Kết quả hội tụ này nhanh hơn rất nhiều so với phương pháp truyền thống: ResNet, ViT, vì chúng tốn gần 300 epochs và yêu cầu nhiều phương pháp data augmentation.


H. Thử trên web demo (checkpoint: SPHINX-v2-1k)

Câu hỏi 1: What’s in the image ?
SPHINX: The image shows a group of three men standing on a golf course, engaged in conversation and laughing together. They are standing near their golf carts, which are parked on the grass.
Câu hỏi 2: Detect all people shown in image and provide correspondence bounding boxes coordinate
SPHINX: There are three people[0.45,0.20,0.63,0.74;0.56,0.21,0.73,0.72;0.74,0.20,0.90,0.72] in the image.

Câu hỏi 3: Detect the keypoints of the person in the region [0.56,0.21,0.73,0.72]
SPHINX: The detected keypoints are nose[0.65,0.26], left eye[0.66,0.25], right eye[0.64,0.25], left ear[0.68,0.26], right ear[0.63,0.25], left shoulder[0.70,0.32], right shoulder[0.61,0.30], left elbow[0.72,0.39], right elbow[0.58,0.35], left wrist[0.69,0.37], right wrist[0.59,0.35], left hip[0.67,0.46], right hip[0.61,0.46], left knee[0.66,0.57], right knee[0.60,0.57], left ankle[0.65,0.68], and right ankle[0.59,0.68].

J. Kết luận
Mình tin rằng trong tương lai gần, chúng ta sẽ chứng kiến sự ra đời của các mô hình AI có khả năng xử lý đa dạng các tác vụ hơn, nhằm tiến gần hơn tới mục tiêu là con người nhân tạo. Và các kỹ thuật mà mình đã giới thiệu ở trên chỉ là một phần trong số nhiều phương pháp giúp chúng ta thực hiện điều này.
Cuối cùng, mình xin cảm ơn các bạn đã quan tâm và đọc đến dòng này, mình hi vọng bài viết này đã mang lại điều gì đó cho các bạn. Chúc mọi người thành công ^^.
H. Tham khảo
- Paper: https://arxiv.org/abs/2311.07575v1
- Code: https://github.com/Alpha-VLLM/LLaMA2-Accessory
- BLIP2: https://arxiv.org/abs/2301.12597
- LLava: https://llava-vl.github.io/
Liên hệ: nduc90313@gmail.com
🔗 Tìm hiểu thêm về Pixta Vietnam: http://bit.ly/3kdkzvW
All rights reserved
