7 Mô Hình AI Lập Trình Nhỏ (SLM) Không Thể Thiếu Cho Phát Triển Cục Bộ Năm 2026
Với sự trỗi dậy của các công cụ lập trình Agentic (tự trị), việc chạy các mô hình AI cục bộ (local) đã trở thành giải pháp ưu tiên hàng đầu để các nhà phát triển đảm bảo quyền riêng tư của mã nguồn và giảm độ trễ. Các Mô hình Ngôn ngữ Nhỏ (SLM) hiện nay đã phát triển đến mức hiệu năng trong các tác vụ lập trình hàng ngày có thể cạnh tranh sòng phẳng với các mô hình mã nguồn đóng khổng lồ.
Dưới đây là 7 mô hình lập trình đáng chú ý nhất hiện nay — chúng có thể chạy mượt mà trên phần cứng máy tính cá nhân thông thường. Suy cho cùng, không cần phải "dùng dao mổ trâu để giết gà".
1. gpt-oss-20b

Đây là mô hình trọng số mở (open-weight) được OpenAI phát hành theo giấy phép Apache 2.0. Nó sử dụng kiến trúc Hỗn hợp chuyên gia (Mixture of Experts - MoE). Mặc dù có tổng cộng 21 tỷ tham số, nhưng nó chỉ kích hoạt 3,6 tỷ tham số cho mỗi token, giúp việc vận hành cực kỳ hiệu quả.
Mô hình này hỗ trợ cửa sổ ngữ cảnh khổng lồ lên đến 128k, lý tưởng để xử lý các kho mã nguồn lớn. Nó cũng có tính năng điều chỉnh mức độ suy luận (Thấp/Trung bình/Cao) thông qua các câu lệnh hệ thống, cho phép bạn cân bằng giữa tốc độ phản hồi và độ sâu phân tích.
Cài đặt & Sử dụng:
Cách nhanh nhất để cài đặt là thông qua Ollama. Bạn có thể tải xuống và cài đặt Ollama chỉ với một cú nhấp chuột thông qua ServBay.
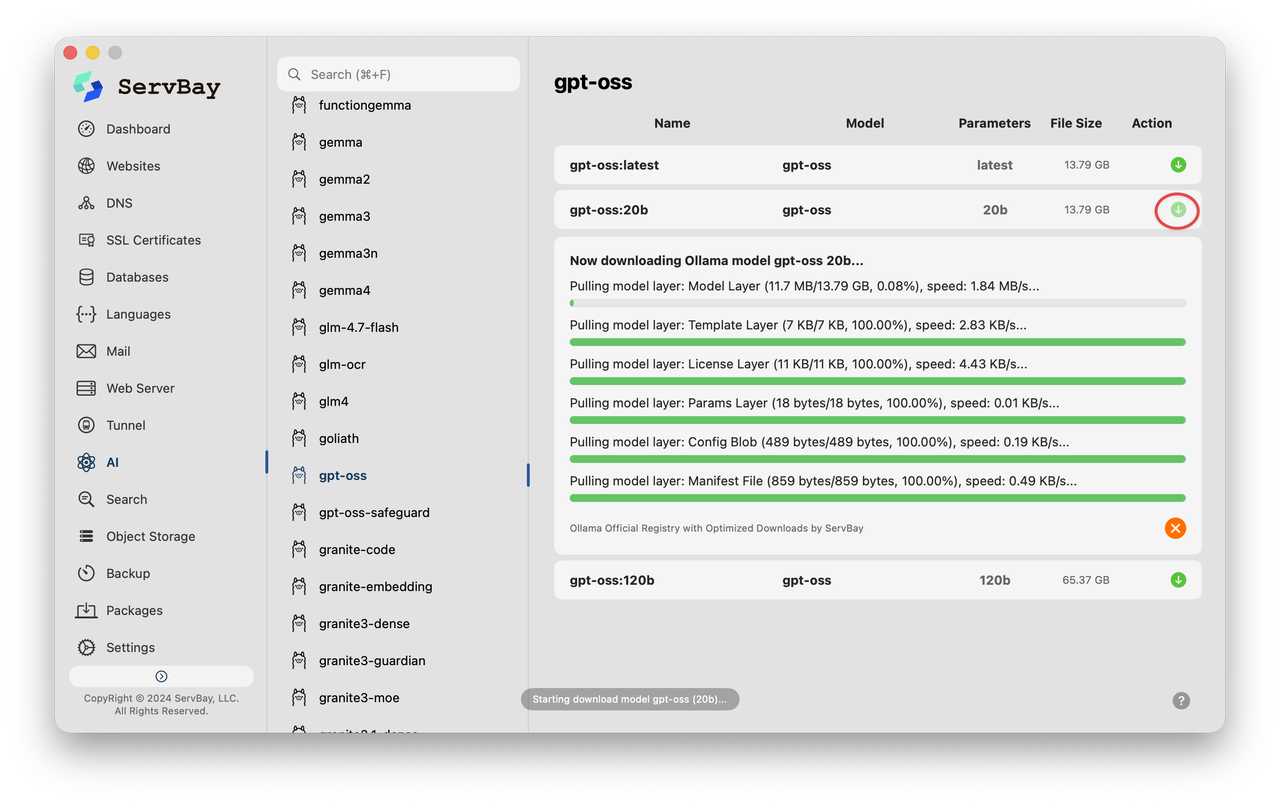
Sau khi cài đặt, chỉ cần nhấp để tải xuống gpt-oss.
Ngoài ra, bạn có thể gọi mô hình thông qua thư viện Transformers:
from transformers import pipeline
pipe = pipeline("text-generation", model="openai/gpt-oss-20b", device_map="auto")
2. Qwen3-VL-32B-Instruct

Đây là mô hình thị giác-ngôn ngữ từ dòng Qwen. Trong lập trình, nó không chỉ viết mã — nó còn có thể "nhìn" ảnh chụp màn hình UI, sơ đồ kiến trúc hệ thống hoặc các bản phác thảo trên bảng trắng.
Nếu bạn cần tạo mã frontend từ một bản thiết kế mẫu hoặc yêu cầu AI phân tích ảnh chụp màn hình thông báo lỗi để gỡ lỗi, mô hình này là một lựa chọn xuất sắc. Nó đã được tinh chỉnh đặc biệt cho quy trình làm việc của nhà phát triển, hỗ trợ đối thoại đa lượt và cung cấp hướng dẫn lập trình từng bước.
Cài đặt & Sử dụng:
Cách dễ nhất là thông qua ServBay, công cụ hỗ trợ rất nhiều mô hình ngôn ngữ lớn (LLM) cục bộ.
Mô hình sẽ hoạt động tốt hơn nữa khi kết hợp với Flash Attention để tiết kiệm VRAM:
from transformers import Qwen3VLForConditionalGeneration
model = Qwen3VLForConditionalGeneration.from_pretrained("Qwen/Qwen3-VL-32B-Instruct", torch_dtype="auto", device_map="auto")
3. Apriel-1.5-15b-Thinker

Được phát hành bởi ServiceNow-AI, mô hình này tập trung vào khả năng suy luận. Nó hiển thị quá trình suy nghĩ trước khi đưa ra mã nguồn — một mô hình "suy nghĩ trước khi viết code" giúp tăng cường độ tin cậy cho các tác vụ phức tạp.
Nó đặc biệt giỏi trong việc truy vết các lỗi logic trong kho mã nguồn hiện có, đề xuất các phương án tái cấu trúc (refactoring) và tạo các trường hợp kiểm thử (test cases) đáp ứng các tiêu chuẩn doanh nghiệp. Nó sử dụng các thẻ đặc biệt để tách biệt quá trình suy nghĩ khỏi mã nguồn cuối cùng, giúp dễ dàng tích hợp với các công cụ khác.
Cài đặt & Sử dụng:
Khuyến khích triển khai với vLLM để tạo API tương thích với OpenAI:
python3 -m vllm.entrypoints.openai.api_server --model ServiceNow-AI/Apriel-1.5-15b-Thinker --trust_remote_code --max-model-len 131072
4. Seed-OSS-36B-Instruct

Series Seed-OSS của ByteDance là một đại diện hiệu năng cao nổi bật trong số các mô hình mã nguồn mở. Nó thể hiện ấn tượng trong nhiều bài kiểm tra lập trình và có thể xử lý trôi chảy hàng chục ngôn ngữ phổ biến như Python, Rust và Go.
Mô hình hỗ trợ kiểm soát "Ngân sách suy nghĩ" (Thinking Budget), cho phép các nhà phát triển điều chỉnh thủ công số lượng bước suy luận để đạt được các kết quả dẫn giải logic chính xác hơn.
Cài đặt & Sử dụng:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("ByteDance-Seed/Seed-OSS-36B-Instruct", device_map="auto")
# Kiểm soát chi phí suy luận thông qua tham số thinking_budget
5. Phi-3.5-mini-instruct

Dòng Phi của Microsoft nổi tiếng với kích thước nhỏ gọn. Mặc dù chỉ có 3,8 tỷ tham số, khả năng suy luận logic của nó vượt xa các mô hình có quy mô tương đương. Vì quá nhỏ, nó thậm chí có thể chạy trên máy tính xách tay không có GPU rời bằng cách dựa hoàn toàn vào CPU.
Nó hoàn hảo để tạo các đoạn mã đơn giản, giải thích logic hoặc đóng vai trò như một công cụ hỗ trợ nhẹ nhàng.
Cài đặt & Sử dụng:
Bạn có thể tải xuống và chạy trực tiếp trong ServBay.
Hoặc cài đặt qua dòng lệnh:
model = AutoModelForCausalLM.from_pretrained("microsoft/Phi-3.5-mini-instruct", trust_remote_code=True)
6. StarCoder2

StarCoder2, từ cộng đồng BigCode, là mô hình được huấn luyện chuyên biệt cho việc tự động hoàn thành mã (code completion). Nó được huấn luyện trên kho dữ liệu của hơn 600 ngôn ngữ lập trình, sử dụng dữ liệu sạch và tuân thủ các giao thức cấp phép.
Lưu ý rằng đây là một mô hình tiền huấn luyện (pre-trained), không phải là mô hình được tinh chỉnh theo hướng dẫn (instruction-tuned). Thay vì đối thoại trực tiếp, nó phù hợp nhất để tích hợp trong IDE để tự động hoàn thành mã dựa trên ngữ cảnh.
Cài đặt & Sử dụng:
Cài đặt trực tiếp thông qua ServBay.
Nó hỗ trợ nhiều phương pháp lượng tử hóa (quantization). Phiên bản 15B chỉ yêu cầu khoảng 16GB VRAM ở mức lượng tử hóa 8-bit:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained("bigcode/starcoder2-15b", quantization_config=quantization_config)
7. CodeGemma

Phiên bản lập trình của mô hình Gemma từ Google. Nó đã trải qua quá trình huấn luyện bổ sung trên 500 tỷ token dữ liệu lập trình, đặc biệt tăng cường khả năng "Điền vào giữa" (Fill-In-the-Middle - FIM).
Nó hiểu ngữ cảnh của mã nguồn cực kỳ tốt, giúp viết logic bên trong hàm hoặc hoàn thành các khối mã còn thiếu một cách rất chính xác.
Cài đặt & Sử dụng:
Cài đặt chỉ với một cú nhấp chuột qua ServBay.
Hoặc tải xuống qua CLI:
from transformers import GemmaTokenizer, AutoModelForCausalLM
tokenizer = GemmaTokenizer.from_pretrained("google/codegemma-7b-it")
model = AutoModelForCausalLM.from_pretrained("google/codegemma-7b-it")
Tóm tắt và Khuyến nghị
Mỗi mô hình này đều có những thế mạnh riêng. Nếu bạn có nhiều VRAM và muốn một mô hình toàn diện, gpt-oss-20b là lựa chọn hàng đầu. Nếu bạn cần xử lý thiết kế UI và kiến trúc, Qwen3-VL mang lại lợi thế thị giác không thể thay thế. Đối với môi trường phần cứng cấu hình thấp, Phi-3.5-mini cung cấp phản hồi cực nhanh với sự đánh đổi hiệu năng tối thiểu.
Bạn có thể sử dụng ServBay để cài đặt các LLM cục bộ chỉ với một cú nhấp chuột, giúp dễ dàng kết nối các mô hình này với các tiện ích mở rộng của VS Code như Continue hoặc Cursor để tạo ra một môi trường lập trình AI riêng tư và hiệu quả.
All rights reserved
