Xây dựng hệ thống Monitoring "All-in-One" với OpenTelemetry và SigNoz
Xây dựng hệ thống Observability (Logs, Metrics, Traces) thường rất phức tạp và tốn kém. Trong bài viết này, mình sẽ chia sẻ cặp bài trùng giúp triển khai nhanh nền tảng monitoring toàn diện, giúp bạn tập trung hoàn toàn vào việc phát triển tính năng thay vì loay hoay với hạ tầng. Bắt đầu thôi 🙃🙃🙃
Nếu thấy hay, kết nối với mình tại: LinkedIn
Sau năm đầu làm Backend, thứ mình tự hào nhất không phải là một feature khó, mà là việc dựng thành công hệ thống Monitoring từ con số 0.
Nó giúp mình nhận ra một sự thật phũ phàng: Hiểu code thôi là chưa đủ. Khi nhìn thấy một request đi qua từng service, mình mới hiểu cách hệ thống thực sự vận hành. Lần đầu tiên, mình biết debug không phải là phán đoán, mà là quan sát
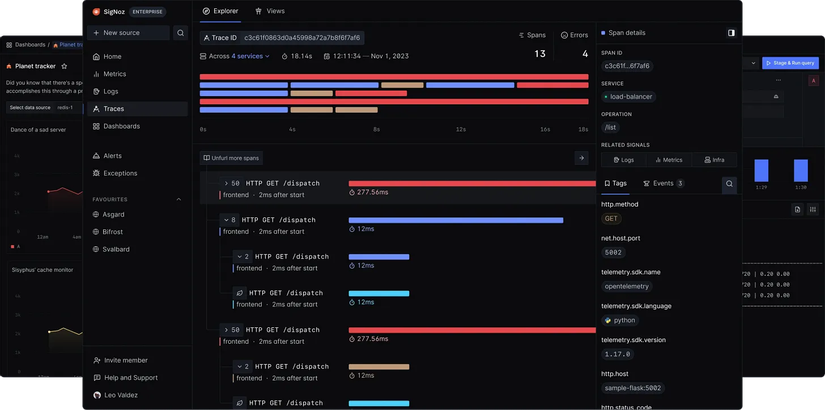
Tại sao mình phải dựng nền tảng monitoring
Thời điểm đó, hệ thống của mình gần như không có một nền tảng monitoring đúng nghĩa. Mỗi khi có sự cố, quy trình của mình đại khái là: Mở Terminal, SSH vào từng server, rồi dùng grep, tail -fđể tìm trong những file log dài vô tận.
Việc debug lúc ấy không khác gì một cuộc mò kim đáy bể giữa một biển log, switch qua lại giữa một đống services:
- Mất phương hướng: Không biết lỗi bắt đầu từ service nào trong cả một rừng microservices.
- Đứt gãy dấu vết: Một request đi qua 4-5 service, nhưng mình không có cách nào xâu chuỗi chúng lại. Nó giống như việc đi tìm một người giữa đám đông mà không hề có ảnh nhận diện.
- Áp lực deadline: Mỗi ca debug có thể kéo dài hàng giờ, thậm chí là vài ngày trong sự sốt ruột của cả team. Lỗi thì vẫn còn đó
Điều làm mình suy nghĩ là: “không biết ngoài kia có bao nhiêu công ty vẫn đang vận hành theo kiểu này?”
Ở công ty cũ, mình may mắn được tiếp cận với Datadog. Phải thừa nhận là nó quá "sướng". Mọi thứ đều hiện đại, UI trực quan, Logs - Metrics - Traces được ship tới tận răng 
Nhưng trớ trêu thay, ngày đó mình dùng Datadog chỉ ở mức "cưỡi ngựa xem hoa", thấy nó tiện để xem log nhanh hơn SSH chứ chưa thực sự thấu hiểu cái giá trị cốt lõi của Observability (khả năng quan sát). Cho đến khi không còn nó nữa, mình mới thấy… thiếu.
Và mình bắt đầu nghĩ:
Tại sao mình không tự tay xây dựng một hệ thống như thế? Một giải pháp mang lại sự trực quan cho hệ thống của mình?

Không dễ như mình tưởng tượng
Trong đầu mình, bắt đầu tìm kiếm những cách để xây dựng hệ thống Observability như vậy. Tiêu chí của mình lúc bắt đầu là:
- Sự đơn giản (Simplicity): Với một đứa “tay ngang” về DevOps, mình cần một thứ gì đó cài là chạy. Phức tạp hóa vấn đề ngay từ đầu là cách nhanh nhất để dẫn đến bỏ cuộc.
- Hạn chế động tới code: Hệ thống hiện tại đang chạy rất ổn định. Việc phải đụng chạm, chỉnh sửa logic code chỉ để thêm monitoring là một rủi ro cực lớn. “Cài đặt thêm” chứ không phải “viết lại”.
- Tối giản hóa số lượng công cụ: Càng nhiều công cụ, càng nhiều điểm lỗi (Single Point of Failure). Mình không muốn dành cả ngày chỉ để bảo trì các công cụ giám sát.
- Open-source: Không hẳn chỉ vì “ham rẻ”, mà quan trọng là cộng đồng hỗ trợ lớn và mình có quyền kiểm soát dữ liệu tuyệt đối mà không phụ thuộc vào việc đốt tiền cho nhà cung cấp.
Nhưng thực tế thì không có giải pháp nào hoàn hảo ngay từ đầu.
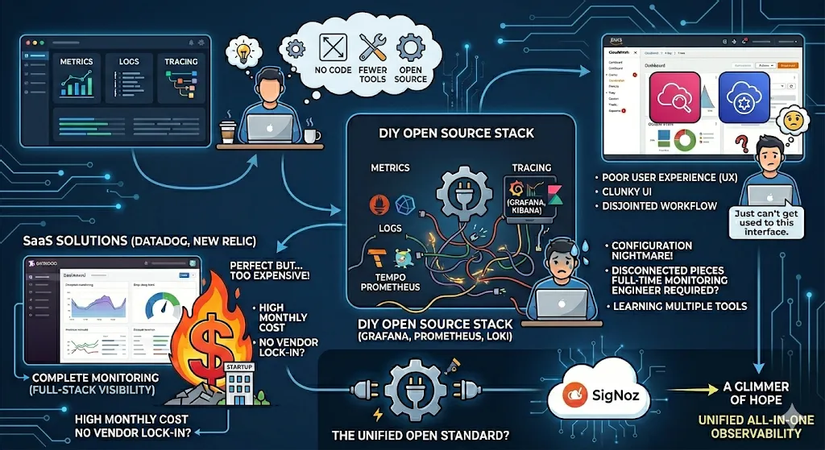
SaaS: Datadog, New Relic
Phải thừa nhận, đây là những giải pháp tiệm cận sự hoàn hảo. Nhưng cái giá phải trả thì... "quá đắt". Với một startup quy mô nhỏ, việc chi vài nghìn USD mỗi tháng chỉ để xem log có vẻ là một sự xa xỉ không cần thiết. Mình muốn tìm một thứ gì đó mang lại trải nghiệm Datadog nhưng với chi phí tự vận hành.
Grafana Tempo, Grafana Loki, Prometheus, influxdb, Kibana, Grafana
Đây là một “combo huỷ diệt” thực sự trong thế giới mã nguồn mở. Đầy đủ, mạnh mẽ nhưng lại cực kỳ rời rạc.
- Nỗi ám ảnh cấu hình: Bạn phải học cách vận hành Prometheus cho Metrics, Loki cho Logs, Tempo cho Tracing.
- Mảnh ghép rời rạc: Việc kết nối chúng lại để chúng “hiểu” nhau là một cực hình. Mình đã từng thử và sớm nhận ra: mình muốn làm Developer để xây dựng sản phẩm, chứ không muốn trở thành một Full-time Monitoring Engineer chỉ để duy trì cái stack này.
Aws Cloudwatch, X-Ray, Trace
Dù đang chạy trên hạ tầng AWS, nhưng thú thực mình không thể "thẩm" nổi giao diện của CloudWatch. Nó mang lại cảm giác cũ kỹ, rời rạc và trải nghiệm người dùng (UX) không được mượt mà.
Sorry AWS. I still love you ♥️♥️♥️
Giải pháp đến bất ngờ
Lần này không phải do mình đọc blog mà biết được, mình có tham gia một hội nghị về tech tên là Devoxx, có rất nhiều chủ đề thú vị mà mình tìm thấy ở đây.
Tình cờ, mình tham dự một buổi thuyết trình của một công ty phát trực tuyến phim. Họ giới thiệu một sự kết hợp chính xác là những gì mình đang tìm kiếm: OpenTelemetry + SigNoz.
Phản ứng của mình đại khái lúc đó là: “Wow, ngon rồi =))))”
OpenTelemetry: "Ngôn ngữ chung" của hệ thống phân tán
Nếu mỗi dịch vụ trong hệ thống của bạn nói một “ngôn ngữ” giám sát khác nhau, việc hiểu được toàn bộ bức tranh là điều không thể. OpenTelemetry (OTel) ra đời để giải quyết bài toán đó.
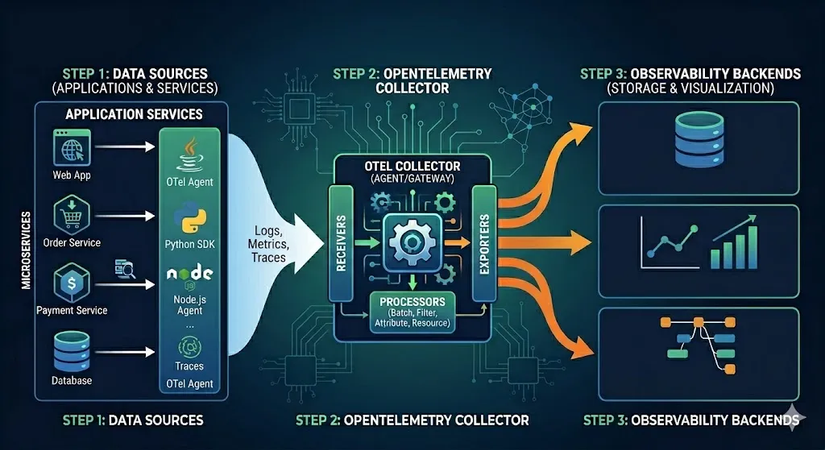
- Lớp trừu tượng mạnh mẽ: OTel không phải là nơi lưu trữ dữ liệu, mà là một framework tiêu chuẩn hóa cách chúng ta tạo ra (generate) và thu thập (collect) dữ liệu quan sát. Nó đóng vai trò như một “phiên dịch viên”, biến mọi tín hiệu từ logs, metrics đến traces về cùng một định dạng chuẩn.
- Dễ tuỳ biến: Đây là giá trị cốt lõi nhất. Với OTel, bạn không còn bị “khóa chặt” (vendor lock-in) vào Datadog hay New Relic. Bạn có thể đổi nhà cung cấp backend chỉ bằng cách thay đổi cấu hình dẫn luồng dữ liệu, mà không cần sửa một dòng code logic nào.
- Tracing xuyên suốt: OTel cho phép bạn gắn một “mã định danh” (Trace ID) vào mỗi request ngay từ khi nó bước vào hệ thống. Nhờ đó, bạn có thể theo dõi hành trình của nó đi qua hàng chục microservices, có thể ghi lại mọi ngõ ngách của dữ liệu.
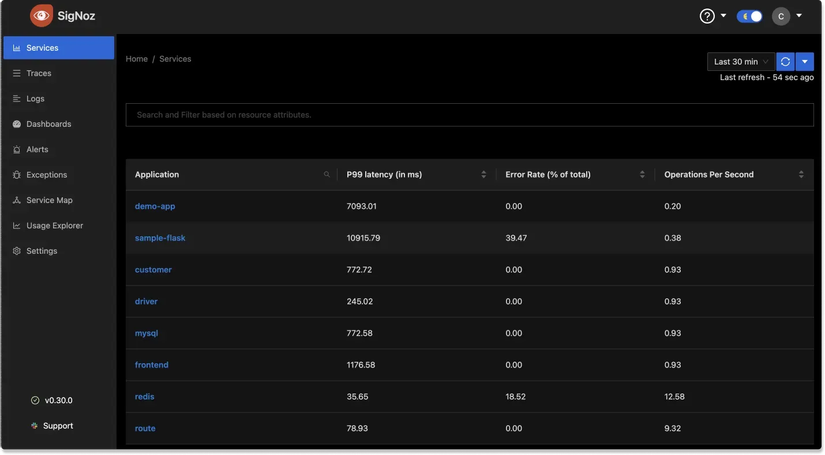
SigNoz: All-in-one
Nếu OpenTelemetry là người thu gom dữ liệu, thì SigNoz chính là nơi dữ liệu được chuyển hóa thành những thông tin có giá trị. Những gì mà bạn cần cho một hệ thống monitoring thì Signoz có hết (Chờ anh em khám phá =))))
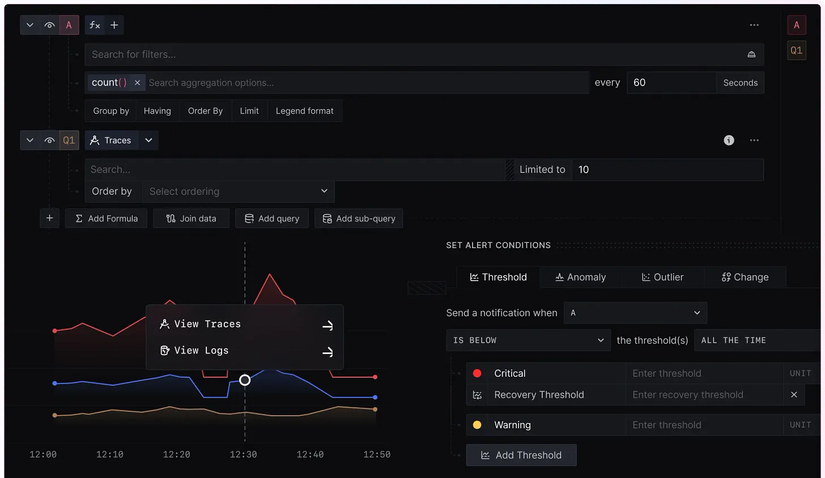
- Tập trung mọi thứ: Thay vì phải nhảy qua lại giữa Prometheus để xem metrics, Loki để soi logs và Jaeger để xem traces, SigNoz gom tất cả vào một giao diện duy nhất. Sự tương quan (correlation) này là cực kỳ quan trọng: khi thấy một biểu đồ Metric vọt lên (Spike), bạn có thể ngay lập tức click vào điểm đó để xem các Logs và Traces tương ứng tại đúng thời điểm đó.
- Tích hợp sâu với OpenTelemetry: SigNoz được xây dựng dựa trên nền tảng của OTel ngay từ ngày đầu. Nó không chỉ đơn thuần là hiển thị dữ liệu, mà còn cung cấp các tính năng cao cấp như lọc traces theo độ trễ, phân tích lỗi (exception) và thiết lập cảnh báo (alerts) thông minh.
- Hiệu năng và Chi phí: Được viết bằng Go và tận dụng ClickHouse (một cơ sở dữ liệu dạng cột cực nhanh), SigNoz có khả năng xử lý hàng tỷ bản ghi với chi phí vận hành thấp hơn nhiều so với các giải pháp SaaS truyền thống. Bạn có toàn quyền kiểm soát dữ liệu của mình (Data Sovereignty) — một yếu tố then chốt cho các doanh nghiệp ưu tiên bảo mật (có thể self-host một cách dễ dàng)
Combo OpenTelemetry + Signoz
Hãy tưởng tượng hệ thống Microservices của bạn là một tòa nhà chọc trời. OpenTelemetry chính là hệ thống đường dây điện và ổ cắm tiêu chuẩn quốc tế được lắp đặt sẵn trong mọi căn phòng. Còn SigNoz chính là chiếc TV màn hình lớn 8K được cắm vào hệ thống đó để hiển thị toàn bộ camera an ninh.
Cái hay ở đây là: Nếu sau này bạn muốn đổi sang một chiếc ‘TV’ khác (như Datadog hay Jaeger), bạn chỉ việc rút phích cắm và cắm vào cái mới. Bạn không cần phải đục tường, đi lại dây điện (sửa code) từ đầu. Sự tự do này chính là giá trị lớn nhất mà OpenTelemetry mang lại.
Nếu không có sự gắn kết giữa Logs và Metrics, bạn sẽ rơi vào tình trạng: Metrics báo CPU nhảy vọt lên 95%, nhưng khi mở Log ra thì thấy hàng nghìn dòng trôi qua mỗi giây. Bạn bắt đầu hoảng loạn: ‘Lỗi ở đâu trong đống rác này?’
Với SigNoz, Log không còn đứng cô đơn. Một dòng log báo lỗi 500 Internal Server Error giờ đây đi kèm với một Context đầy đủ:
- Nó thuộc về Trace ID nào? (Hành trình request).
- Lúc đó CPU/RAM của service đó đang là bao nhiêu?
- Độ trễ (Latency) tại bước gọi Database là bao nhiêu?
Khi mọi dữ liệu ‘nói chuyện’ được với nhau, việc debug không còn là đoán mò, mà là một quá trình điều tra dựa trên bằng chứng xác thực.
Bắt tay vào làm luôn
Sau khi trở về, mình bắt tay vào làm luôn (cho nóng, haha). Trái với những lo ngại ban đầu về việc hệ thống sẽ phức tạp, quy trình tích hợp thực tế diễn ra mượt mà đến ngạc nhiên. Mình chia lộ trình ra làm 3 bước:
- Chuẩn hóa Log: Chuyển đổi log của Spring Boot sang định dạng JSON bằng Logback (một tính năng có sẵn trong Spring Boot).
- Triển khai SigNoz: thông qua Docker — nhanh, gọn và không cần tốn quá nhiều tài nguyên cấu hình.
- Kích hoạt OpenTelemetry: Chạy file OpenTelemetry Agent cùng ứng dụng Java (mình thêm trong Dockerfile như bên dưới). Đây là bước kỳ diệu nhất: Không cần chạm vào một dòng code logic nào, dữ liệu bắt đầu đổ về SigNoz ngay lập tức.
ENTRYPOINT ["java", "-javaagent:/opentelemetry-javaagent.jar", "-Dotel.exporter.otlp.protocol=grpc", "-jar", "/myapp.jar"]
Mọi thứ hoạt động gần như ngay lập tức. Chỉ mất vỏn vẹn 2 tuần để mình đưa phiên bản đầu tiên lên Production (bao gồm cấu hình mọi thứ, dựng server EC2 cho test và production, thiết lập backup các thứ).
Lần đầu tiên sau nhiều năm vận hành, cả team mình đã có thể:
- Xem Traces: Tận mắt nhìn thấy một request đi qua các service như thế nào.
- Xác định Bottlenecks: Theo dõi chính xác service nào đang kéo chậm toàn bộ hệ thống (không còn đoán mò p99 dựa trên trực giác).
- Debugging: Rút ngắn thời gian tìm lỗi từ hàng giờ xuống còn vài phút.
Những thứ học được từ monitoring
Trong khi làm việc với monitoring, mình đã khám phá ra nhiều khái niệm mà trước đây mình chưa thực sự hiểu rõ.
Monitoring có ba trụ cột:
- Logs: Các bản ghi sự kiện có dấu thời gian, ghi lại từng sự kiện riêng lẻ xảy ra, chẳng hạn như lỗi, cảnh báo và thông báo thông tin. Chúng được sử dụng để debug các sự cố cụ thể và hiểu điều gì đã xảy ra và tại sao.
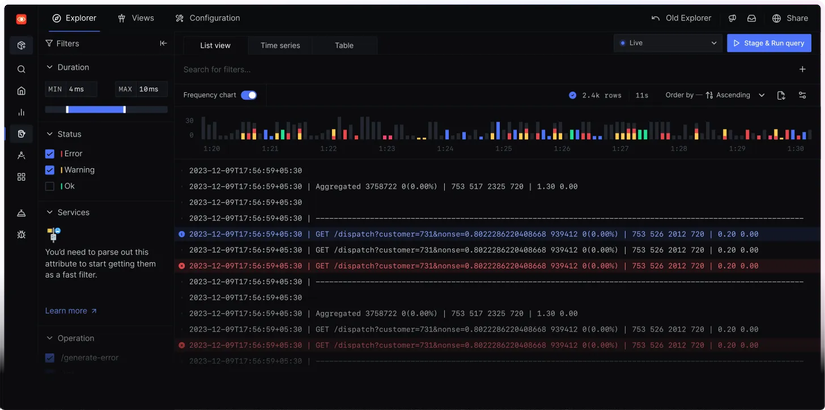
- Metrics: Dữ liệu chuỗi thời gian dạng số như counters, gauges và histograms. Chúng thể hiện xu hướng và mức sử dụng tài nguyên theo thời gian, như CPU, bộ nhớ, tốc độ request, tỷ lệ lỗi và các percentiles của độ trễ. Chúng được dùng cho dashboard, cảnh báo và phân tích xu hướng dài hạn.
- Traces: Một cái nhìn toàn diện end-to-end về hành trình của một request khi nó đi qua nhiều service, bao gồm các span và một trace ID. Chúng cực kỳ hữu ích trong việc xác định nơi độ trễ hoặc lỗi được sinh ra trong các hệ thống microservices.
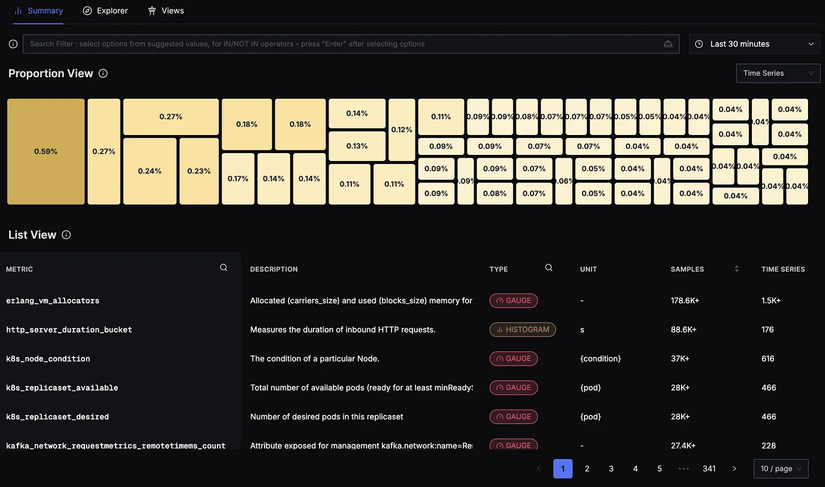
Các khái niệm liên quan:
- SLA (Service Level Agreement): Một cam kết giống như hợp đồng với khách hàng. Nếu bị vi phạm, có thể sẽ có hình phạt hoặc bồi thường.
- SLO (Service Level Objective): Các mục tiêu độ tin cậy nội bộ do chính team đặt ra, thường nghiêm ngặt hơn so với giá trị SLA.
- SLI (Service Level Indicator): Chỉ số thực tế được đo lường để đánh giá xem chúng ta có đáp ứng SLO hay không.
Latency percentiles:
- p50: Một nửa người dùng trải nghiệm tốc độ này hoặc nhanh hơn. Đây là giá trị phổ biến nhất.
- p95: Chỉ còn 5% người dùng gặp phải tốc độ chậm hơn mức này. Nếu p95 của bạn quá cao, nghĩa là cứ 20 người dùng thì có 1 người đang "khó chịu".
- p99: Giá trị mà 99% request nhanh hơn. Chỉ có 1% chậm hơn.
Tại sao chúng ta phải đặc biệt chú ý tới p99? > Hãy tưởng tượng một trang web hiện đại phải gọi tới 100 microservices để render xong trang chủ. Nếu mỗi service có p99 là 1s, thì xác suất để ít nhất một service bị chậm (và kéo theo cả trang web chậm) là cực kỳ lớn. Trong hệ thống phân tán, p99 không phải là ngoại lệ, nó là tương lai của hệ thống nếu bạn không kiểm soát tốt. Mình đã giải thích giá trị này trong bài viết chuyên sâu về latency, các bạn đọc thêm nhé.
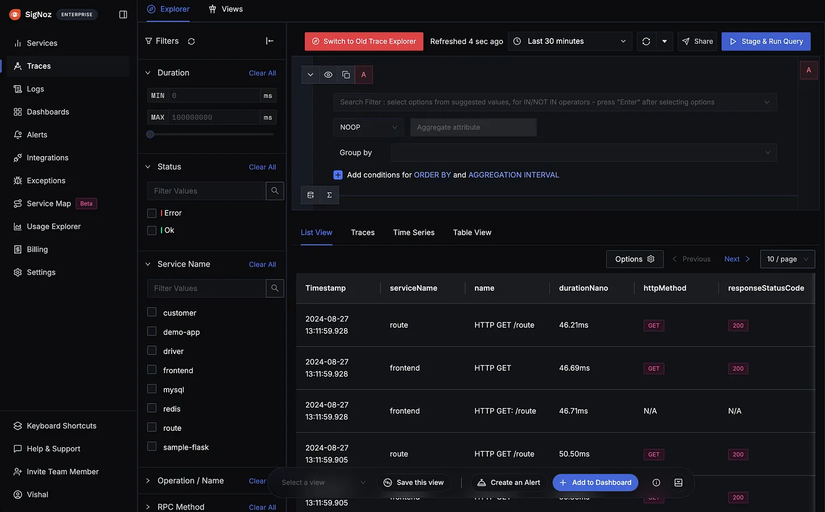
Tracing: sợi dây liên kết
Nếu Metrics cho bạn biết hệ thống có độ trễ lớn, thì Tracing sẽ giúp chúng ta biết chính xác vị trí nào đang gây nghẽn cho hệ thống
Khi nhìn vào một Trace trên SigNoz, hành trình của request không còn là một hộp đen:
Client → API Gateway → Order Service → Payment Service → Database
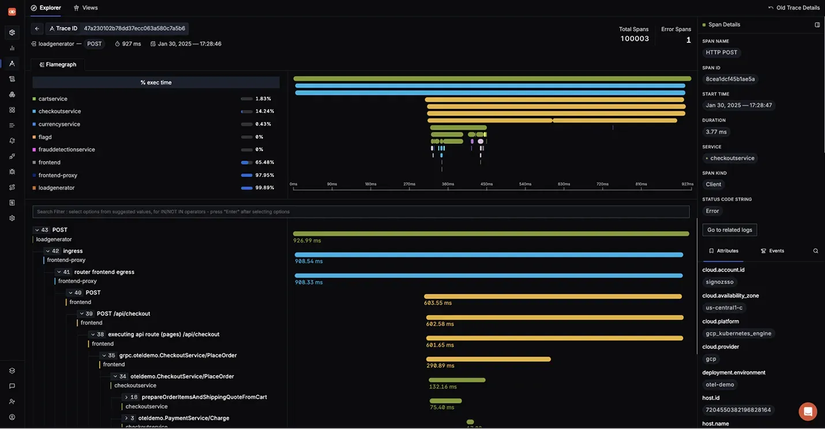
Mọi thứ hiển thị dưới dạng một biểu đồ Gantt trực quan:
- Service tham gia: Service A gọi Service B hay bị lỗi ngay từ Gateway?
- Nghẽn ở đâu: Bước gọi Database mất 800ms trong khi toàn bộ request mất 1s? Bạn biết ngay mình cần tối ưu query thay vì đi sửa code Java.
- Bất đối xứng: Có những request chạy 10 bước nhưng cực nhanh, có những cái chỉ 2 bước lại cực chậm. Tracing giúp bạn nhìn ra những vị trí đó.
Ngay cả đến bây giờ, mình vẫn chưa khám phá hết mọi ngóc ngách của SigNoz, nhưng có một điều chắc chắn: Tư duy của mình đã thay đổi. Thay vì phải SSH vào server đi dò từng line log, mình đã có thể nhìn trực tiếp các biểu đồ, quan sát toàn bộ dòng chảy dữ liệu. Công cụ này không chỉ cứu mình khỏi những bug không biết từ đâu tới, mà còn giúp mình tự tin hơn khi thiết kế những hệ thống lớn hơn, vì mình biết mình có khả năng kiểm soát chúng.
Kết
Nhìn lại hành trình vừa qua, mình nhận ra Monitoring không chỉ là câu chuyện về công cụ, mà là về sự hiểu biết. Thú thật, mình chưa phải là một 'cao thủ' về observability, nhưng SigNoz và OpenTelemetry đã giúp mình hiểu hệ thống gấp trăm lần so với việc chỉ ngồi grep log như trước kia
Đừng đợi đến khi hệ thống sập mới đi dựng monitoring. Hãy dựng nó khi hệ thống còn đang chạy tốt, để bạn biết thế nào là 'tốt' trước khi biết thế nào là 'tệ'
Bài viết này cũng được mình dịch sang tiếng Anh trên blog substack của mình.
Mình viết lại những điều này như một cách để ghi nhớ hành trình làm nghề của mình. Nếu bạn cũng đang làm backend, devops hoặc cloud, hy vọng những chia sẻ này có thể giúp bạn một chút gì đó. Còn nếu có chỗ nào mình hiểu chưa đúng, mình vẫn luôn sẵn sàng học thêm.
All rights reserved
