002: Apache Kafka topic, partition, offset và broker
Bài đăng này đã không được cập nhật trong 4 năm
© Dat Bui | Buy me a coffee & give your kindness to the world
Bài viết nằm trong series Apache Kafka từ zero đến one.
Chính xác theo sách vở, Kafka là event streaming platform, hơn cả một message broker. Việc hơn thế nào bàn luận sau. Tập trung vào message broker trước đã.
Nói qua về lịch sử, Kafka được phát triển bởi LinkedIn (các anh em dev chắc chẳng xa lạ gì) và viết bằng ngôn ngữ JVM, cụ thể là Java và Scala. Sau đó trở thành open-source project với Apache license, nên còn gọi là Apache Kafka.
Bài viết này giới thiệu về các NFR chính mà Kafka được quảng cáo, sau đó là các thành phần chi tiết bao gồm:
- Topic.
- Partition.
- Offset.
- Broker.
Let's begin.
1) Apache Kafka
Không cần trình bày nhiều, các bạn có thể google với trả về 8 triệu kết quả trong 0.5s. Mình chỉ điểm qua 4 tính chất được quảng cáo của Kafka như sau:
- High scalable: Kafka là hệ thống phân tán - distributed system, có khả năng mở rộng rất nhanh và dễ dàng với zero downtime - mọi thứ vẫn hoạt động bình thường khi thêm hoặc bớt broker.
- High durable: message được lưu trên disk, đảm bảo nếu mất điện.. data vẫn còn nguyên. Ngoài ra, một message sẽ có nhiều bản sao lưu trên nhiều broker khác nhau, phụ thuộc vào config và set up. Nếu một broker die, flow vẫn hoạt động bình thường không bị ngắt quãng.
- High reliable: giống durable, lưu trữ message ở nhiều nơi. Ngoài ra có cơ chế cân bằng request trong trường hợp gặp sự cố về các broker. Đại khái là đáng tin cậy hơn các message broker hiện có trên thị trường.
- High performance: high throughput cho cả đầu gửi và nhận message với khả năng scale tuyệt vời. Nhờ vậy nó có thể xử lý hàng TB data mà không gặp nhiều vấn đề về performance.
Toàn high và rất high, tuy nhiên high đến mức nào còn phụ thuộc chúng ta có biết cách sử dụng không và apply ra sao.
Đưa một ông kĩ sư IT đi lái máy bay thì có khi cuốc bộ còn nhanh hơn. Mà cũng tùy loại máy bay
.
1) Kafka topic, partition và offset
Đi vào phần chính, có topic mà không có queue, lại mọc thêm partition và offset là thế nào?
Queue và Topic là đại diện cho hai concept gửi nhận message từ một nguồn đến một/nhiều nguồn. Với mỗi messsage broker khác nhau sẽ có tên gọi và hình thái khác nhau. Cụ thể với Kafka như nào thì.. đọc tiếp đã.
1.1) Topic
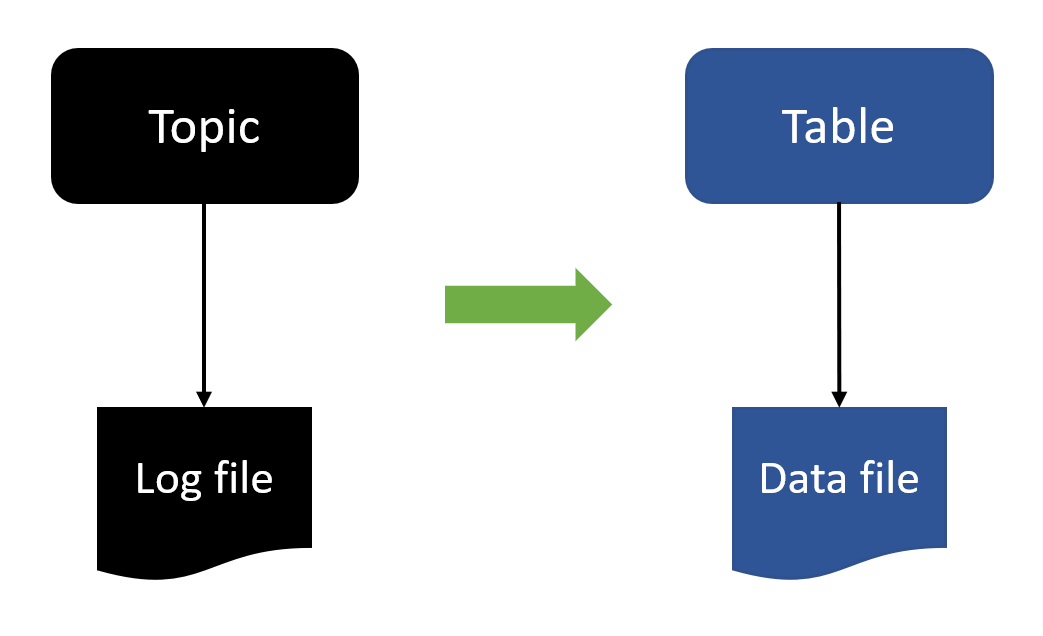
Topic là stream of data, luồng lưu trữ dữ liệu của Kafka. Nói thế cho nguy hiểm chứ hiểu đơn giản nó là một dãy các message nối tiếp nhau.
- Có thể coi topic giống như table trong relational databse: OracleBD, PostgreSQL... whatever.
- Table bao gồm name và row. Tương tự, sẽ có topic name và message. Các luồng dữ liệu được gửi vào topic giống như việc insert row vào table. Row mới được insert vào ngay sau row cũ.
Topic được lưu trữ ở log file phân chia thành các segment khác nhau.
1.2) Partition và offset
Chắc hẳn chúng ta còn nhớ đến kĩ thuật partition table trong series Performance optimization với PostgreSQL. Table có thể được chia thành một hoặc nhiều partition khác nhau, dữ liệu được lưu trên partition chứ không lưu trên table chính.
Topic cũng giống table, nó được chia thành một hoặc nhiều partition và message được lưu trên đó. Khi tạo topic cần xác định số lượng partition mong muốn.
- Partition được order và bắt đầu từ 0.
- Các message được lưu trong partition cũng được order theo thứ tự từ cũ đến mới, append liên tục bắt đầu từ giá trị 0, được gọi là offset.

Với ví dụ trên, cả 3 partition không có cùng số lượng message. Số lượng message của mỗi partition là độc lập, không phụ thuộc vào nhau. Như vậy, một message trong Kafka được xác định bởi 3 yếu tố:
- Topic name.
- Partition.
- Offset.
Vài điều cần chú ý:
- Dù 2 message có cùng offset nhưng thuộc 2 partition khác nhau thì chúng cũng khác nhau. Offset chỉ có ý nghĩa trong cùng một partition.
- Offset có thứ tự, nhưng chỉ đảm bảo thứ tự trong cùng partition. Ví dụ trong cùng partition 1, message có offset = 3 chắc chắn đến sau message có offset = 2.
- Kafka là Data pipeline, đã giới thiệu ở bài trước. Message sau khi được consume không bị xóa ngay, default giữ lại trong 7 ngày - có thể config. Sau 7 ngày message bị xóa nhưng offset không reset mà tiếp tục tăng. Offset is never go back.
- Data sau khi lưu vào partition là immutable - bất biến, không thể thay đổi. Không thể update, không thể swap sang offset khác.
Một điều vô cùng quan trọng mình chưa đề cập đến - Nếu define nhiều partition, message sẽ được lưu vào partition nào?
Câu trả lời là.. nó không quan trọng lắm, chỉ quan tâm đến việc message gửi nhận đúng thứ tự, gửi A, B nhận A, B chứ không phải B, A là ok. Vậy mục đích của partition là gì, nếu muốn các message cùng được lưu trên một partition để đảm bảo thứ tự thì làm thế nào?
Ghim lại đã, trả bài sau
.
1.3) Topic example
Lấy ví dụ bài toán thực tế với Kafka topic.
Mình đóng vai công ty Grab - cung cấp dịch vụ vận chuyển con người và hàng hóa. Mình muốn tracking vị trí của từng tài xế, cập nhật mỗi 20 giây. Áp dụng Kafka vào hệ thống để xử lý bài toán:
- Tạo topic driver_gps chứa thông tin về vị trí của toàn bộ tài xế.
- Cứ 20 giây, thiết bị của tài xế sẽ gửi một message bao gồm: driver_id và driver_position lên partition của driver_gps topic.
Túm cái váy lại, toàn bộ vài trăm nghìn tài xế của mình sẽ gửi message lên duy nhất một topic driver_gps. Lúc này topic driver_gps là stream of data của toàn bộ các tài xế. Khá dễ hiểu.
Sau khi message được đẩy lên Kafka, sẽ có rất nhiều consumer phía sau nhận message để xử lý:
- Consumer cho việc tracking location, hiển thị vị trí hiện tại của tài xế trên map.
- Consumer cho notification. Tài xế đã xuất phát chưa, đã đến nơi chưa.
- Consumer để tracking tài xế. Đang làm việc hay nghỉ ngơi, đã làm quá giờ chưa.. vân vân và mây mây.

Như vậy, ta đã có cái nhìn tổng quan nhất về Kafka với topic, partition và offset. Tiếp tục hành trình với Kafka broker nhé. Let's go.
2) Kafka broker
Message được lưu tại offset của partition, partition được lưu ở topic. Vậy topic được lưu ở đâu?
Topic được lưu trữ trên file, trên disk, và tất cả đều được lưu trữ trên server. Và server là một Kafka broker trong Kafka cluster.
Chúng ta đã nghe nhiều về single-point failure: nếu chỉ deploy trên một server, không may server đó gặp sự cố thì.. còn cái lịt. Do vậy, các bài toán đều triển khai với multi-node trên multi-server, replicate hoặc cluster. Để đảm bảo 4 tính chất đã nêu ở đầu bài và xử lý single-point failure, Kafka sẽ triển khai Kafka cluster.
Có thể hiểu Kafka cluster là nhiều server tập trung lại thành một cụm làm việc với nhau - multi-brokers (multi-servers). Broker bao gồm 3 nhiệm vụ:
- Receive message từ Producer và ack.
- Lưu message tại log file để đảm bảo an toàn, tránh trường hợp mất message.
- Gửi message đến Consumer trong trường hợp được yêu cầu.
Ngoài lề, cluster và replicate đều nói về multi-node nhưng khái niệm và cơ chế hoạt động khác nhau.
Số lượng broker trong Kafka cluster thường là 3, 5, 7, 10... Những bài toán siêu to khổng lồ có thể lên đến vài trăm broker, sách giáo khoa nói vậy chứ mình cũng chưa được làm với bài toán đó.
Mỗi Kafka broker được định danh bằng ID, là số nguyên integer. Mỗi broker lưu trữ một vài partition, không lưu trữ tất cả partition của topic.
Cuối cùng, khi connect đến bất kì broker nào trong mạng Kafka cluster, chúng ta sẽ connect tới toàn bộ mạng cluster đó. Không quan tâm cluster có bao nhiêu broker.
Làm thế nào Kafka thực hiện được điều đó, để sau nhé. Tạm thời cứ hiểu như vậy đã
.

3) Kafka broker & topic
Tiếp tục ví dụ trên, Kafka cluster của mình có 3 broker. Tạo thêm Topic-A cũng chia thành 3 partition, Kafka tổ chức chúng như sau:

Để đảm bảo high reliable, Kafka tự động phân tán các partition trên tất cả broker đang có. Mỗi partition nằm trên một broker. Topic-A partition 1 có thể nằm trên bất kì broker nào mà không phụ thuộc thứ tự.
Trong trường hợp Topic-B khác có 2 partition:

Case cuối cùng, Topic-C có số lượng partition lớn hơn số lượng broker:

Không có gì phức tạp, Kafka cluster sẽ phân tán các partition của cùng một topic ra nhiều broker nhất có thể.
Không bỏ trứng vào cùng một giỏ.
4) Topic replication
Với cách tổ chức broker và partition như trên vẫn chưa giải quyết triệt để single-point failure.

Broker 103 gặp sự cố cũng chẳng sao, nhưng nếu là Broker 101 hoặc Broker 102 thì.. Quang tèo.
Cơ chế xử lý single-point failure cho partition chẳng có gì kì diệu. Vẫn dựa trên ý tưởng cổ điển, tạo ra nhiều bản sao cho partition và lưu trên những broker khác nhau thông qua replication factor. Với ví dụ trên replication factor = 1. Nếu tăng lên 3, mô hình sẽ như sau:

Như vậy, trong trường hợp Broker 102 gặp sự cố đã có back-up từ Broker 101 và Broker 103. Đảm bảo 2 yếu tố performance và reliability:
- Không lost message trong trường hợp một broker gặp sự cố.
- Hệ thống hoạt động bình thường, message vẫn có thể read/write trên broker còn lại.

Như vậy, chúng ta đã nắm được khái niệm cơ bản trong Apache Kafka và mối liên quan giữa Topic, partition và replication.

Các bài sau khi thực hành mình sẽ nói kĩ hơn về log file và segment.
Reference
Reference in series https://viblo.asia/s/apache-kafka-tu-zero-den-one-aGK7jPbA5j2
After credit
Nếu một partition có nhiều replication thì việc read/write message diễn ra trên replication nào hay tất cả các replication?
Nếu muốn các message cùng được lưu trên một partition để đảm bảo thứ tự thì làm cách nào?
Câu trả lời sẽ có trong phần tiếp theo  .
.
© Dat Bui | Buy me a coffee & give your kindness to the world
All rights reserved
