Những điều cần biết về MongoDB Cluster
Bài đăng này đã không được cập nhật trong 4 năm
Chào mọi người, hôm nay mình sẽ viết về mongodb cluster một chút.
Để đọc bài viết này, mình sẽ mặc định mọi người có những khái niệm cơ bản về NoSQL, phân biệt được SQL và NoSQL, phân biệt được document database, key-value database, collumn family hay graph database nhé.
Mình sẽ nói rõ hơn một chút về tính khả mở, khả năng nhân bản và cách mongo mở rộng hay nhân bản dữ liệu trước khi đi vào xây dựng 1 ví dụ với docker-compose
Các thành phần chính của mongoDB
Database
Database là một ô chứa dữ liệu ở mức vật lý, mỗi database bao gồm nhiều collection
Collection
Collection là một nhóm các văn bản (tương ứng với các bảng trong cơ sở dữ liệu quan hệ), mỗi collection chỉ thuộc về một database duy nhất. Nhưng điểm khác biệt đó là các collection không có sự rằng buộc về cấu trúc của document, nó chỉ là 1 cách gom lại các document tựa tựa nhau tùy theo người quản trị hệ thống. Và các collection không có sự rằng buộc với nhau.
Document
Là có thể hiểu giống như các bản ghi dữ liệu, có cấu trúc tương tự Json. Mỗi document có 1 _id là định danh duy nhất. Và các document không có cấu trúc giống nhau. Ví dụ về một document
{
"name" : "John Smith",
"phone" : {
"home" : "555-123-4567",
"cell" : "555-321-7654”
},
"address" : {
"street" : "123 Main Street",
"city" : "San Francisco",
"state" : "CA",
"zip" : 94115
}
}
Cách mongo nhân bản và tổ trức lưu trữ nhân bản
Kỹ thuật nhân bản của mongo đơn giản chỉ là sao một đối tượng dữ liệu ra nhiều máy chủ khác nhau. Trong nhóm máy chủ này có 1 máy chủ chính gọi là master còn các máy chủ khác là máy chủ thứ cấp (gọi là slaver). Máy chủ master đóng vai trò thực hiện các tác vụ đọc và ghi, trong khi các máy chủ slaver chỉ có vai trò backup dữ liệu và tác vụ đọc. Mongo có một cơ chế chuyển đổi dự phòng nếu máy master crash, một trong các máy slaver sẽ lên làm master thông qua thực hiện hàm bầu cử. (Chi tiết mình sẽ nói sau nếu có thời gian) Một cụm máy như này trong kiến trúc của mongo sẽ có 3 máy, gọi là 1 replicaset. Một replica set thông thường sẽ có 1 primary(master) và 2 secondary(slave). Hoặc 1 replica set sẽ có 1 primary, 1 secondary và 1 arbiter. Vai trò của arbiter và lí do vì sao xuất hiện thằng này, mình sẽ nói ở một bài viết khác nhé ^^.
Cách mongo cắt nhỏ dữ liệu để lưu trữ
Để chia nhỏ một khối dữ liệu lớn ra nhiều các máy trạm khác nhau, mongo có một cơ chế là sharding. Sharding là một kỹ thuật cho phép các bản ghi trong một cơ sở dữ liệu phân tán ra nhiều máy chủ khác nhau. Điều này giúp cho khả năng mở rộng, lưu trữ và xử lỹ của hệ thống. Một sharded cluster bao gồm các thành phần sau:
- shard: mọi người hãy hiểu shard là đơn vị quản lý dữ liệu của sharded cluster, mỗi shard thường là 1 replica set
- mongos: đóng vai trò như một bộ định tuyến, là interface đối với người dùng, người dùng chỉ giao tiếp với mongos và không cần quan tâm bên trong có cái gì
- config server: là một máy chủ mongo (mongod) chứa các thông tin cấu hình của cluster, như document nào nằm ở shard nào chẳng hạn. Từ bản 3.0 trở đi, config server cũng là 1 replicaset
Dưới đây là hình vẽ mình lấy trên trang chủ của mongo cho mọi người dễ hình dung:
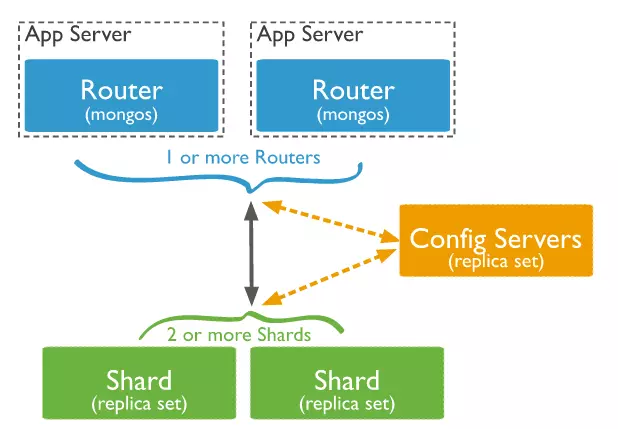 Đấy, đại khái cấu trúc tổng thể nó là như thế. Vậy chính xác các shard chứa gì, các shard chứa các collection hoặc chứa 1 phần của collection, rồi tất cả đống n chứa đấy được nhân lên làm 3 để thành 1 replica set.
Đấy, đại khái cấu trúc tổng thể nó là như thế. Vậy chính xác các shard chứa gì, các shard chứa các collection hoặc chứa 1 phần của collection, rồi tất cả đống n chứa đấy được nhân lên làm 3 để thành 1 replica set.
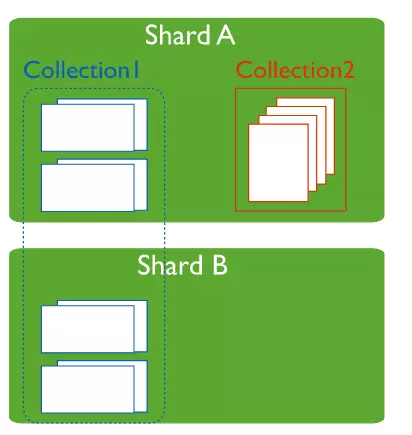 1 shard chứa nhiều collection và 1 collection có thể trải dài trên nhiều shard. OK chốt.
1 shard chứa nhiều collection và 1 collection có thể trải dài trên nhiều shard. OK chốt.
Sharding strategy
OK, giờ đến chiến lược sharding. Mongo có 2 chiến lược sharding, nhưng trước hết mọi người cần biết đến khái niệm shard-key đã.
Shard key
Shard key là gì, shard key là 1 trường trong văn bản, mà trường đó là unique, và quan trọng hơn hết, đó là chúng ta thích trường đó, chúng ta chọn trường đó làm key (đùa thôi, có hẳn 1 chiến lược để chọn shard key đó, nhưng viết trong bài này thì dài quá, vì mãi chưa đi đến đoạn xây dựng mongo cluster). Như đã nói ở trên, shard key là 1 trường unique, nhưng dùng để làm gì, đơn giản, dùng shard key để quyết định xem, document này sẽ nằm ở shard nào. Có 2 cách để chốt xem document nằm ở đâu với shard key
Ranged sharding:
Đây là cách đơn giản dễ làm dễ hiều, chỉ đơn giản là chia các shard ra thành các range liền nhau, kiểu như shardA chiến từ -10 đến 10. shardB chiếm từ 11 đến 31 chẳng hạn, shard-key của document rơi vào khoảng nào thì nằm vào shard đó. dễ hiểu đúng không
Hashed Sharding:
Cách này càng đơn giản, mỗi giá trị của shard key đưa qua 1 hàm bằm, sau đó lại lắm vào range như cách trên, nhưng cách này có gì hay hơn, cách này giúp đảm bảo document phân tán được triệt để hơn. (Như mình đã chạy thì 1 triệu bản ghi phân tán ra 10 shard, mỗi shard chứa từ 99899 đến 10100 bản ghi). Mình sẽ giải thích cái này 1 lần nữa ở bài viết khác =)) OK, đến đây mà mọi người đã hình dung ra lý thuyết cách mongo phân tán rồi đúng không. Ở bài viết tiếp mình sẽ hướng dẫn mọi người về docker vả dùng dockert-compose xây dựng 1 cụm mongo ngay trên máy tính cá nhân nhé. Hôm nay mệt lắm rồi.
All rights reserved
