[Xử lý video] Ứng dụng ConvNets trong kiến trúc hai luồng (Two-stream) cho nhận dạng video
Bài đăng này đã không được cập nhật trong 5 năm
Convolutional Networks for Action Recognition
Tổng quát
Nhận diện hành động của con người trong video là một thách thức đầy khó khăn. So với phân loại dựa trên các đặc tính của ảnh tĩnh thì phân loại hành động trong video có những đặc tính mang tính nhất thời như: luồng sáng, gia tốc,.. đó là những thành phần quan trọng cung cấp thêm thông tin để nhận diện hành động. Ngoài ra video còn cung cấp thêm các thông số tự nhiên(natural data augmentation) (jittering) cho việc phân loại video frame.
Trong vấn đề này, chúng ta sẽ mở rộng mạng tích chập (Convolutional Network) [6] (ConvNets) từ việc phân loại ảnh tĩnh để nhận dạng hành động trong dữ liệu từ video. Ý tưởng ở đây là dựa trên 2 luồng nhận dạng riêng biệt đó là không-thời gian sau đó kết hợp chúng lại bằng hàm tổng cuối(the late fusion). Luồng không gian thực hiện nhận dạng hành động từ các video frames, luồng thời gian được training để nhận diện hành động từ chuyển động của các luồng quang học (optical flow). Và cả hai luồng này đều được triển khai dưới dạng mạng tích chập ConvNets. Việc tách biệt của hai luồng này cũng giúp tận dụng được các dữ liệu có sẵn. Ngoài ra, kiến trúc nhận dạng này được tác giả lên ý tưởng dựa vào thị giác của con người trong đó luồng không gian đóng vai trò nhận dạng đối tượng, luồng thời gian đóng vai trò nhận diện ra chuyển động.
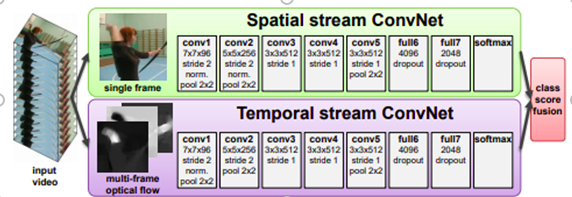
Giới thiệu kiến trúc hai luồng(Two-stream) và chỉ rõ Spatial ConvNets
Video có thể được phân chia thành các đặc tính theo không gian và các đặc tính theo thời gian. Về khía cạnh không gian, các đặc tính về phần này xuất hiện trong các frame riêng lẻ và mang các thông tin về bối cảnh, vật thể được mô tả trong video. Về khía cạnh thời gian, thông tin được mô tả trên các frames có mối quan hệ với nhau, nó cung cấp các thông tin về chuyển động của vật thể hay góc nhìn của người quan sát(camera). Trong tài liệu tham khảo tác giả đã đề xuất ra kiến trúc để nhận dạng đó là chia thành hai luồng nhận dạng như đã đề cập ở phần trước.
Mỗi luồng được triển khai bằng cách sử dụng mạng tích chập sâu (deep ConvNets), softmax scores sẽ được kết hợp bằng hàm tổng. Ở đây sẽ sử dụng hai phương thức cho hàm tổng đó là tính trung bình và training một Support Vector Machine [10] (SVM) tuyến tính đa lớp về các điểm số của softmax được chuẩn hóa bằng stacked L2-normalised.
Spatial stream ConvNet hoạt động trên từng frame riêng lẻ của video thực hiện nhiệm vụ nhận dạng hành động từ ảnh tĩnh. Phương pháp thực sự có hiệu quả trong nhận dạng hành động bởi vì hành động thường được gắn liền với đối tượng cụ thể nào đó. Trong thực tế thì việc phân loại hành động chỉ dùng các hình ảnh tĩnh riêng lẻ khá là không hiệu quả (cụ thể sẽ trình bày trong phần sau). Do bản chất của spatial ConvNet là một kiến trúc phân loại hình ảnh nên có thể vận dụng phương pháp nhận dạng hình ảnh quy mô lớn (large-scale image recognition) [4] với pre-training network dữ liệu trên tập dữ liệu phân loại hình ảnh đủ lớn (chi tiết sẽ được trình bày trong phần sau).
Optical flow ConvNets
Trong phần này sẽ mô tả chi tiết Temporal stream ConvNet của mô hình two-stream. Input cho mô hình này là các optical flows giữa một số frames liên tiếp. Input này có vai trò mô tả chuyển động giữa các frame, nó giúp nhận dạng dễ dàng hơn vì mạng không cần phải ước tính chuyển động. Phương thức mô tả optical flow được mô tả trong hình sau:

Trong hình trên (a) và (b) là 2 frames liên tiếp nhau với hình bàn tay chuyển động được bao quanh bởi hình màu xanh. (c) là biểu đồ mô tả optical flow trong khung màu xanh đã được đánh dấu. (d) mô tả thành phần nằm ngang theo dx của optical flow. (e) là thành phần dọc theo dy.
Optical flow stacking. Một optical flow có thể được xem như là một tập các trường vectors dịch chuyển dt giữa frame t và t+1. Với dt(u,v) là biểu thị vector dịch chuyển của frame t và t+1 tại tọa độ (u,v). Mô tả của phần trước ta thấy rằng các biểu diễn của vector theo chiều dọc hay ngang đều có thể được xem như là một hình ảnh nên thích hợp để nhận dạng bằng mạng tích chập. Để biểu diễn chuyển động trên một chuỗi các frames chúng ta sẽ xếp chồng các luồng biểu diễn dtx,y của L frame liên tiếp thành tổng số là 2L inputs channels. Cho w, h lần lượt là chiều rộng, cao của video. Một khối input Iτ ∈ R(w×h×2L) cho ConvNet cho một frame t bất kỳ được định nghĩa như sau:
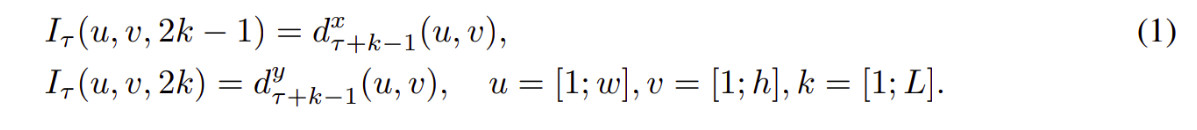
Với mỗi điểm bất kỳ (u,v) các channels input Iτ (u,v,c) với c ∈ [1: 2L] đã số hóa chuyển động lẫn lượt qua mỗi frame của L frames(Như hình dưới).
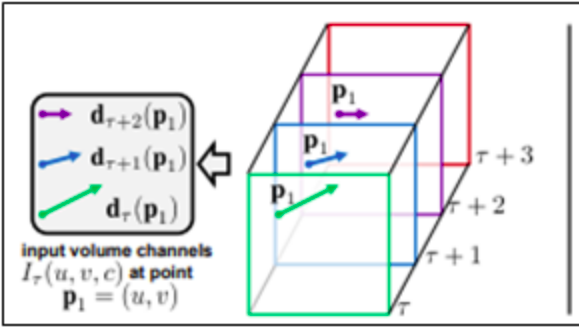
Trajectory stacking. Đây là một giải pháp mô tả chuyển động thay thế khác đó là trajectory stacking lấy ý tưởng từ các mô tả dựa trên quỹ đạo chuyển động và được lấy mẫu cùng một vị trí trên một số frames và dọc theo quỹ đạo chuyển động [11]. Trong trường hợp này đầu vào sẽ có dạng như sau
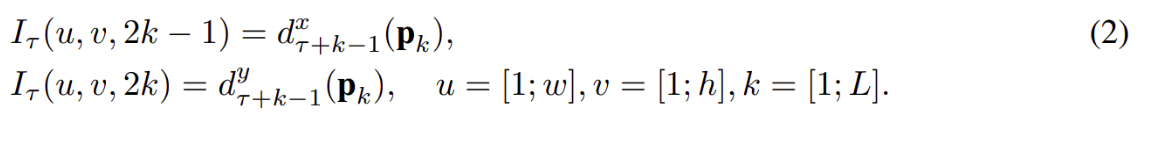
Trong đó pk là điểm thứ k dọc theo quỹ đạo, bắt đầu tại (u,v) và được xác định theo công thức sau:
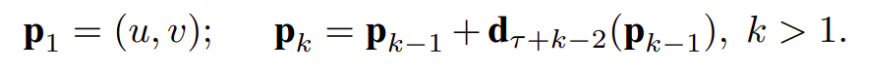
Điểm khác biệt giữa biểu diễn đầu vào của optical flow stacking và trajectory stacking đó là theo công thức (1) các Iτ lưu trữ các vector dịch chuyển tại vị trí (u,v) còn theo công thức (2) thì lưu trữ các vector được lấy mẫu tại các vị trí pk dọc theo quỹ đạo. Như hình mô tả sau:
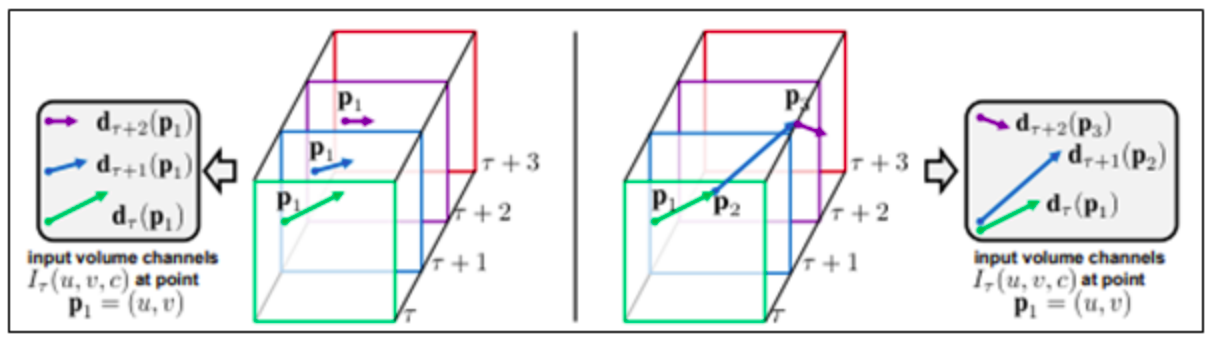
ta thấy rằng, bên trái: optical flow stacking (1) lấy mẫu các vectơ dịch chuyển d tại cùng một vị trí trong nhiều frame. Bên phải: tracjectory stacking (2) lấy mẫu các vectơ dọc theo quỹ đạo. Các frames và các vectơ dịch chuyển tương ứng được hiển thị với cùng màu.
Bi-directional optical flow. Với các phương thức biểu diễn optical flow (1) và (2) với mỗi input vào sẽ có một giá trị dt của frame thứ t sẽ quyết định vị trí lấy giá trị trong frame t+1. Trong thực tế, khi mở rộng optical flow thành bi-directional optical flow ta chỉ việc tính toán 1 đường chuyển vị bổ sung (d’t) theo chiều ngược lại. Khi này xây dựng các giá trị đầu vào Iτ cho mạng, ta sẽ xếp chồng L/2 forward flows bắt đầu từ frame thứ t đến frame thứ t+L/2 và L/2 backward flows (từ đường chuyển vị bổ sung d’t) từ vị trí t-L/2 đến t. Do vậy nên số đầu vào vẫn có cùng số channels là 2L như các phương thức trước đó. Các luồng biểu diễn này có thể sử dụng một trong hai công thức (1) hoặc (2) như đã đề cập bên trên.
Cấu trúc. Như ở trên đã trình bày về một số phương pháp kết hợp các optical flow thành các thành phần input cho mạng. Do ConvNet yêu cầu input có kích thức cố định nên chúng ta sẽ lấy mẫu và resize các mẫu đó theo kích thước cố định. Cụ thể ở đây là 224x224x2L với L là số frames. Và cấu trúc các hidden layer cũng giống như cấu trúc các hidden layer của spatial ConvNet đã được mô tả trong hình mở đầù.
Mô tả chi tiết cấu trúc
ConvNets configuration. Cấu trúc các lớp của ConvNets đã được mô tả trong hình. Cấu trúc của ConvNets này tương đồng với kiến trúc của convolutional neural networks-medium (CNN-M) và cụ thể là CNN-M-2048.
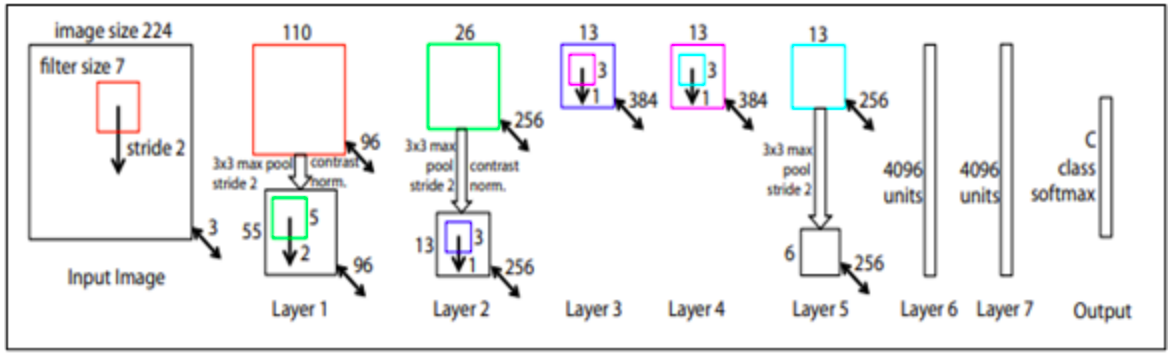
Tất cả các trọng số của các hidden layer sử dụng rectification (ReLU) làm hàm kích hoạt. maxpooling sử dụng của sổ trượt 3x3 với stride 2. Sự khác biệt duy nhất giữa spatial ConvNet với temporal ConvNet là loại bỏ lớp chuẩn hóa thứ 2 để giảm bộ nhớ sử dụng và tăng hiệu suất.
Training. Quy trình training có thể được xem là sự thích ứng của ImageNet[15] với các frame videos và cả spatial net và temporal net đều dùng chung cơ chế này. Các trọng số của mạng được học bằng cách sử dụng cơ chế mini-batch stochastics gradient descent với momentum mặc định là 0.9. Ở mỗi lần lặp một mini-patch gồm 256 mẫu được xây dựng từ cách lấy 256 mẫu training videos(thống nhất giữa các lớp) và mỗi frame sẽ được chọn một cách ngẫu nhiên. Trong quá trình đào tạo spatial net một sub-image với kích thước 224x224 sẽ được cắt một cách ngẫu nhiên từ frame được chọn và có thể lật ngang một cách ngẫu nhiên hoặc trải qua RGB jittering. Các videos sẽ được rescale sao cho chiều rộng là 256px. Khác với ImageNet các sub-image sẽ được lấy từ tất cả các vị có thể chứ không chỉ ở trung tâm. Với temporal net, optical flow được lấy mẫu cho training như đã được trình bày trong phần trước, input sẽ được cố định với kích thước là 224x224x2L và được cắt và lật một cách ngẫu nhiên. Learning rate ban đầu được đặt là 10-2 và được giảm dần theo một quy luật cố định cho tất cả các training sets. Cụ thể, khi huấn luyện ConvNet từ đầu, tốc độ được thay đổi thành 10−3 sau lần lặp 50K, sau đó thành 10−4 sau 70K lần lặp và sẽ dừng sau 80K lần.
Tổng kết
Trên đây đã trình bày một số kiến thức liên quan đến việc áp dụng Convnet vào mô hình 2 luồng để nhận diện hành động trong video. Trong bài viết có sử dụng một số khái niệm chuyên ngành các bạn đọc có thể tham khảo thêm các tài liệu sau.
[1] Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman. Return of the devil in the details: Delving deep into convolutional nets. In Proc. BMVC., 2014.
[2] Crammer and Y. Singer. On the algorithmic implementation of multiclass kernel-based vector machines. JMLR, 2:265–292, 2001.
[3] Jia. Caffe: An open source convolutional architecture for fast feature embedding. http://caffe. berkeleyvision.org/, 2013.
[4] Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, pages 1106–1114, 2012.
[5] Kuehne H, Jhuang H, Garrote E, Poggio T and Serre T. HMDB: a large video database for human motion recognition. IEEE Int. Conf. on Computer Vision IEEE pp 2556-63, 2011
All rights reserved
