Xây dựng hệ thống AI Document Understanding end-to-end
Khi nhắc đến Document AI, phần lớn mọi người thường nghĩ đến OCR. Nhưng trong thực tế doanh nghiệp, đặc biệt là các lĩnh vực như Ngân hàng, Tài chính, Bảo hiểm hay Kiểm toán, OCR chỉ là bước đầu tiên của bài toán.
Điều doanh nghiệp thực sự cần không phải là "đọc được văn bản", mà là "biến tài liệu thành dữ liệu có thể sử dụng được".
Ví dụ với một báo cáo tài chính dài hàng trăm trang, việc nhận diện được từng dòng chữ gần như không tạo ra nhiều giá trị nếu hệ thống vẫn không thể trả lời các câu hỏi như:
Tổng tài sản là bao nhiêu?
Doanh thu thuần nằm ở đâu?
Lợi nhuận sau thuế là bao nhiêu?
Các chỉ số này thuộc năm tài chính nào?
Bảng số liệu này thuộc Báo cáo kết quả kinh doanh hay Bảng cân đối kế toán?
Đó là lúc bài toán chuyển từ OCR sang Document Understanding.
Một trong những thách thức lớn nhất của Document Understanding là làm sao để hệ thống hiểu được cấu trúc và ngữ cảnh của tài liệu thay vì chỉ đọc được văn bản.
Trong thực tế, không tồn tại một mẫu báo cáo tài chính chuẩn cho tất cả doanh nghiệp. Mỗi đơn vị có thể sử dụng template khác nhau, cách trình bày khác nhau, số lượng bảng biểu khác nhau và thậm chí cùng một chỉ tiêu tài chính nhưng lại xuất hiện ở những vị trí hoàn toàn khác nhau.
Điều này đặt ra một câu hỏi rất khó: Làm sao để hệ thống vẫn có thể trích xuất đúng thông tin ngay cả khi gặp một layout chưa từng xuất hiện trong quá trình huấn luyện?
Đây cũng là lý do vì sao các hệ thống Document AI hiện đại không còn chỉ sử dụng OCR truyền thống mà phải kết hợp nhiều thành phần khác nhau như Layout Analysis, Key Information Extraction (KIE) và Vision-Language Models (VLM).
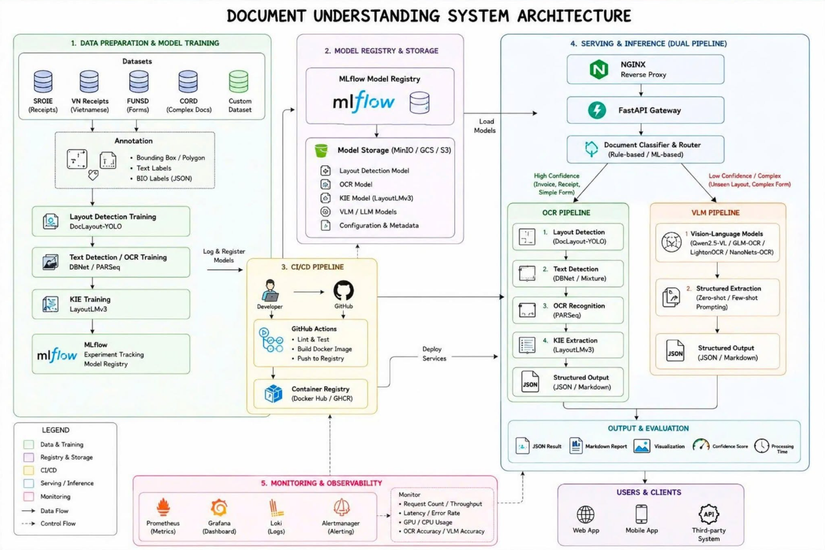
📌 Trong Final Project, học viên sẽ tiếp cận bài toán dưới góc nhìn của một AI Engineer đang xây dựng sản phẩm thực tế cho doanh nghiệp. Quy trình triển khai bao gồm: Document Upload → Layout Detection → OCR → Information Extraction → Validation → API Serving → Monitoring Trong quá trình xây dựng hệ thống, học viên sẽ liên tục phải đối mặt với các bài toán rất thực tế. OCR có thể hoạt động rất tốt trên notebook nhưng khi gặp file scan mờ, tài liệu nhiều cột hoặc bảng biểu phức tạp thì chất lượng suy giảm đáng kể. Một bounding box bị lệch nhẹ có thể khiến giá trị tài chính bị đọc sai. Một lỗi OCR ở giai đoạn đầu có thể lan truyền sang toàn bộ pipeline extraction phía sau. Đây là hiện tượng cascading error mà hầu như mọi hệ thống Document AI production đều phải xử lý. Bên cạnh đó, học viên cũng sẽ tiếp cận một câu hỏi rất phổ biến trong doanh nghiệp: "Nên sử dụng OCR + LayoutLM hay Vision-Language Model?" Các VLM hiện đại như Qwen2.5-VL cho thấy khả năng xử lý rất tốt đối với những tài liệu có cấu trúc phức tạp hoặc các layout chưa từng xuất hiện trong dữ liệu huấn luyện. Tuy nhiên trong production, bài toán không chỉ là độ chính xác. Doanh nghiệp còn phải cân nhắc: Latency GPU Cost Throughput Khả năng mở rộng hệ thống Độ ổn định khi vận hành Một mô hình tốt hơn chưa chắc là lựa chọn phù hợp hơn. Đây cũng là lý do project được thiết kế theo hướng so sánh và kết hợp cả hai cách tiếp cận: OCR-based Pipeline VLM-based Pipeline để học viên hiểu rõ các trade-off thực tế khi triển khai AI trong doanh nghiệp. ⚙️ Về mặt hệ thống, project không chỉ dừng ở model training. Học viên sẽ được tiếp cận các thành phần thường xuất hiện trong một hệ thống AI production hiện đại: DocLayout-YOLO cho Layout Detection DBNet + PARSeq cho OCR Pipeline LayoutLMv3 cho Document Understanding & Information Extraction Qwen2.5-VL cho Vision-Language Understanding FastAPI Gateway MLflow Model Registry Docker Deployment GitHub Actions CI/CD Monitoring với Prometheus, Grafana và Loki Quan trọng hơn, học viên sẽ hiểu được cách các thành phần này phối hợp với nhau để tạo thành một hệ thống hoàn chỉnh thay vì chỉ là những mô hình hoạt động độc lập trong notebook. 💡 Một khía cạnh khác thường bị bỏ qua khi học AI là các yêu cầu của doanh nghiệp sau khi mô hình được triển khai. Trong các lĩnh vực như Ngân hàng hay Tài chính, hệ thống không chỉ cần chính xác mà còn phải đáp ứng các yêu cầu về: Bảo mật dữ liệu Khả năng audit và truy vết kết quả Kiểm soát hallucination Validation theo business rules Tích hợp với các hệ thống nghiệp vụ hiện hữu Đây là những yêu cầu ít khi xuất hiện trong các benchmark nghiên cứu nhưng lại đóng vai trò quyết định trong quá trình triển khai thực tế. Giá trị lớn nhất của Final Project không nằm ở việc fine-tune thêm một mô hình OCR hay đạt thêm vài điểm F1 Score. Giá trị lớn nhất nằm ở việc hiểu cách xây dựng một hệ thống AI Document Understanding có thể vận hành trong môi trường doanh nghiệp thực tế. Trong doanh nghiệp, giá trị của một giải pháp AI không được đo bằng vài điểm Accuracy hay F1 Score cao hơn trên benchmark. Điều quan trọng hơn là liệu hệ thống có thể vận hành ổn định, xử lý được khối lượng tài liệu thực tế, đáp ứng yêu cầu về tốc độ và tạo ra kết quả đủ tin cậy để hỗ trợ các quy trình nghiệp vụ hay không. Đó cũng chính là tư duy và kỹ năng mà Final Project hướng tới: giúp học viên chuyển từ việc xây dựng mô hình trong notebook sang thiết kế và triển khai các hệ thống AI có khả năng ứng dụng thực tế. Tìm hiểu nhiều lộ trình học tập khác tại: https://cole.vn/danh-sach-khoa-hoc
All rights reserved
