XÂY DỰNG HỆ THỐNG AGENTIC RAG - PHÁP LUẬT GIAO THÔNG VIỆT NAM - TỪ PDF VĂN BẢN LUẬT ĐẾN HỆ THỐNG AGENTIC RAG
1. Tổng Quan Dự Án Trợ Lý AI Pháp Luật Giao Thông
Mục tiêu dự án
Xây dựng một trợ lý AI có khả năng trả lời chính xác các câu hỏi về pháp luật giao thông đường bộ Việt Nam (cập nhật theo quy định mới nhất). Yêu cầu nghiêm ngặt là phải trích dẫn (citation) chính xác đến từng cấp Điểm/Khoản/Điều của các Nghị định, Thông tư, Luật; tuyệt đối không bịa số tiền phạt hay điểm trừ GPLX (hallucination).
Vấn đề giải quyết
Hiện tại, người dân muốn tra cứu mức phạt giao thông vẫn phải lật từng file PDF của Nghị định 168/2024, Luật 36/2024, Thông tư 47/2024… rất mất thời gian. Nếu dùng các công cụ như ChatGPT bản free thì rất hay gặp hiện tượng hallucinate (bịa ra các Điều/Khoản không tồn tại).
Dự án này sinh ra để tự động hóa quy trình tra cứu với ràng buộc trích dẫn chặt chẽ, đồng thời tích hợp cơ chế fallback web search có sự phê duyệt của con người (Human-in-the-Loop - HITL) khi kho dữ liệu nội bộ (corpus) không đủ thông tin.
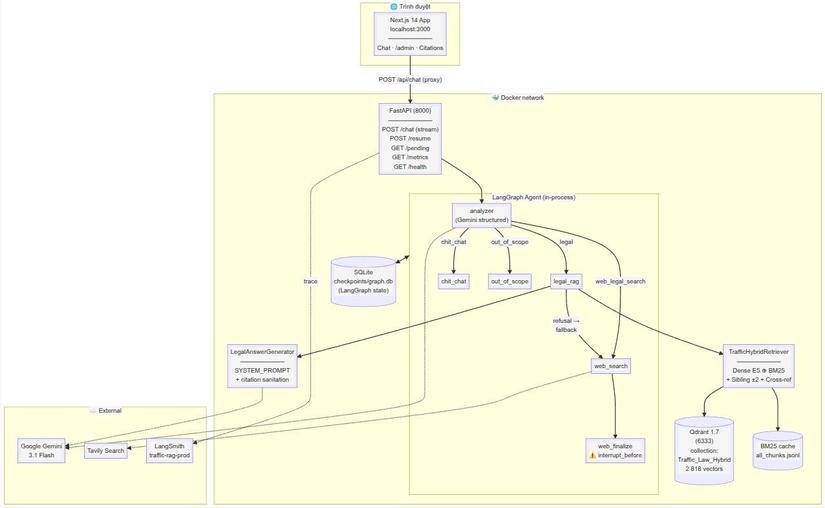
Sơ đồ Kiến trúc Công nghệ (Tech Stack)
Để hệ thống vận hành mượt mà, mình đã kết hợp các công cụ sau:
-
Orchestration (Điều phối): LangGraph quản lý dưới dạng state machine (luồng đi: router → retrieve → grade → generate → web HITL).
-
Vector Database: Qdrant 1.7 (triển khai qua Docker) – hỗ trợ hybrid dense + sparse và payload filter.
-
Embedding & Retrieval: Sử dụng intfloat/multilingual-e5-small (384d) kết hợp BM25 (dùng rank-bm25 với pyvi để tokenize tiếng Việt), sau đó hợp nhất kết quả bằng thuật toán Reciprocal Rank Fusion (RRF).
-
Large Language Model (LLM): Gemini 3.1 Flash (với 1M context, gói free tier rất tối ưu cho việc làm demo).
-
Web Fallback: Sử dụng Tavily API để tìm kiếm cứu cánh khi dữ liệu nội bộ thiếu.
-
Backend: FastAPI hỗ trợ streaming và dùng SQLite checkpointer để lưu trạng thái phục vụ tính năng HITL resume.
-
Frontend: Next.js 14 (App Router + Tailwind + Zustand + NextAuth) – tích hợp thêm trang /admin riêng biệt để duyệt câu trả lời từ web.
-
Evaluation & CI/CD: Hệ thống tracing LangSmith + RAGAS-lite (custom prompt) + pipeline kiểm thử pytest CI regression gate.
-
Bộ dữ liệu (Corpus): Mình đã thu thập và xử lý 26 văn bản pháp luật giao thông (bao gồm Luật, Nghị định, Thông tư có hiệu lực) và cắt thành 2.818 chunks nạp vào Qdrant.
2. Điểm Nổi Bật & Những Thử Thách Gian Nan Khi Làm RAG Tiếng Việt
Điều mình tâm đắc nhất trong dự án này là đã tự xây dựng được một semantic chunker có khả năng hiểu cấu trúc phân cấp đặc thù của văn bản pháp luật Việt Nam (Chương → Điều → Khoản → Điểm). Mỗi đoạn dữ liệu (chunk) đều được đính kèm metadata chi tiết: {doc_id, dieu, khoan, diem, page, status}. Nhờ vậy, câu trả lời của AI luôn trích dẫn chuẩn xác đến từng điểm/khoản, vượt trội hơn hẳn các hệ thống RAG "ngây thơ" thông thường vốn chỉ chỉ ra được "nằm ở trang số mấy".
Tuy nhiên, để hệ thống chạy ổn định là cả một chuỗi ngày debug trầy trật. Dưới đây là 6 bài học xương máu mình rút ra được:
2.1. Nỗi ác mộng mang tên Parse PDF Luật giữ cấu trúc (Hierarchy)
Đây là phần khó nhằn nhất ở giai đoạn Ingestion (nạp dữ liệu). Các file PDF Luật/Nghị định thường dính các lỗi như lặp lại Header/Footer, OCR cắt câu tùy tiện giữa trang, hoặc các cụm từ như "Điều 6" nằm đầu dòng rất dễ khiến AI hiểu lầm.
Để giải quyết, mình phải viết riêng 3 bộ cleaner chuyên dụng (clean_luat_pdfs.py, clean_nghidinh_pdfs.py, clean_thongtu_pdfs.py). Mình dùng Regex kết hợp với logic gộp câu (merge) tỉ mỉ để vừa giữ được từ khóa định danh như "Điều 6", vừa không gộp nhầm các câu mới bắt đầu bằng chữ thường.
2.2. Bài toán Hybrid Retrieval tối ưu riêng cho Tiếng Việt
Nếu chỉ dùng Dense Retrieval đơn thuần (e5-small), chỉ số MRR (Mean Reciprocal Rank) trả về rất thấp. Lý do là tiếng Việt có quá nhiều biến thể từ đồng nghĩa (ví dụ người dân hay gõ "vượt đèn đỏ", nhưng văn bản luật lại ghi là "không chấp hành tín hiệu đèn điều khiển giao thông").
Giải pháp của mình là bổ sung BM25. Tuy nhiên, thư viện rank_bm25 chuẩn không hỗ trợ tiếng Việt, bắt buộc phải dùng pyvi để tokenize (tách từ) trước, sau đó mới tiến hành gom hai bảng xếp hạng bằng thuật toán RRF (Reciprocal Rank Fusion). Sau khi thử nghiệm (ablation test), việc kết hợp hybrid + lấy thêm các khoản lân cận (sibling ±2 khoản) + cross-reference đã giúp cải thiện đáng kể chỉ số MRR.
2.3. Cân bằng giữa Chống Hallucination (Bịa ý) và Từ chối trả lời (Refusal Rate)
Khi mình siết chặt Prompt để ép LLM không được tự bịa số liệu, hệ thống lập tức sinh ra tác dụng phụ: AI từ chối trả lời hàng loạt ngay cả những câu nó có khả năng giải quyết (Tỷ lệ từ chối - Refusal rate có lúc vọt lên 56%).
Để khắc phục, mình phải thiết kế một Legal Reasoning Prompt nghiêm ngặt với 14 quy tắc. Đặc biệt là cơ chế ghi đè (override) Quy tắc số 4 dành riêng cho dạng câu hỏi mang tính tình huống như "lỗi do ai trong vụ va chạm". Do luật không bao giờ chỉ mặt đặt tên ai có lỗi sẵn, mình hướng dẫn LLM suy luận theo quy trình 4 bước:
-
Liệt kê hành vi thực tế.
-
Đối chiếu với các chunk vi phạm trong DB.
-
Kết luận lỗi đơn hay lỗi hỗn hợp.
-
Đưa ra lưu ý quan trọng: "Tỷ lệ % lỗi cuối cùng phải do CSGT xác định".
2.4. Triển khai cơ chế Human-in-the-Loop với LangGraph
Mình thiết kế hệ thống cho phép Agent dừng lại ở node web_finalize, lưu trạng thái (persist state) vào SQLite checkpointer (checkpoints/graph.db), và chỉ tiếp tục chạy (resume) khi có Admin bấm phê duyệt tại trang quản trị /admin.
Tài liệu về tính năng interrupt_before của LangGraph hiện tại khá khan hiếm. Mình đã mất rất nhiều thời gian để nhận ra rằng: thread_id giữa request gọi /chat ban đầu và request /resume sau đó bắt buộc phải đồng nhất thì hệ thống mới load lại đúng state cũ được.
2.5. Trận chiến Reranker: Chỉ số đẹp nhưng Latency cao
Mình có tích hợp thử bge-reranker-v2-m3 để tối ưu kết quả. Chỉ số đo đạc trên giấy tăng rất đẹp: MRR tăng 21.6%, nDCG@10 tăng 14.9%.
Tuy nhiên, thực tế phũ phàng là Latency (độ trễ) bị nhân lên gấp 78 lần khi chạy trên CPU (từ 608ms vọt lên tới 47 giây cho một câu trả lời). Khi đưa vào chạy thực tế (Production), mình buộc phải tắt tính năng này đi (để default off) và chỉ kích hoạt qua biến môi trường ENABLE_RERANKER=1 khi hệ thống được trang bị GPU. Bài học rút ra: Metric trên giấy có đẹp đến mấy mà không tối ưu được thời gian phản hồi (serve) thì cũng bằng không.
2.6. Vượt qua giới hạn Rate-Limit của RAGAS (Throttle 93.5%)
Trong lần đầu tiên chạy thử khung đánh giá RAGAS gốc với bộ câu hỏi test (25 câu × 4 metrics), hệ thống phải thực hiện tới khoảng 6.000 cuộc gọi thẩm định (judge calls). Hệ quả là tài khoản Gemini free tier bị dính lỗi rate-limit ngay lập tức, trả về toàn bộ kết quả là NaN.
Để giải quyết, mình đã tự viết lại một bản RAGAS-lite tối giản với prompt Chain-of-Thought (CoT) tùy chỉnh, gom lại chỉ còn 1 call/metric/sample thay vì 60 calls như bản gốc. Số lượng request giảm xuống chỉ còn 20 calls cho mỗi lượt chạy, hệ thống không còn bị nghẽn (throttle) nữa. Kết quả đánh giá này cũng giúp mình nhìn ra điểm nghẽn (bottleneck) thực sự của hệ thống nằm ở độ chính xác của tầng tìm kiếm (Retrieval Precision chỉ đạt 0.20), chứ không phải ở chất lượng câu trả lời (Answer Relevancy đạt tới 1.00).
2.7. Xây dựng rào chắn kiểm thử (CI Regression Gate)
Ban đầu, thư mục tests/ của mình hoàn toàn trống trơn. Sau khi nhận được góp ý rất thấm từ mentor: "Nếu sau này em thay đổi mô hình Embedding, làm sao em biết được chất lượng hệ thống có bị thụt lùi (regression) hay không?", mình đã bổ sung ngay file tests/test_retrieval_regression.py.
File này sẽ chạy tự động 5 câu query mẫu và kiểm tra điều kiện (assert) xem chỉ số mean Recall@10 có đạt ≥ 0.40 hay không. Nếu điểm số bị rơi xuống dưới ngưỡng này, hệ thống kiểm thử tự động (CI) sẽ báo Fail và chặn không cho gộp code (block merge). Trên GitHub Actions, mình thiết lập chia làm 2 jobs: smoke (luôn chạy để test tính năng cơ bản) và regression (kích hoạt service Docker để khởi động Qdrant và test sâu).
3. Tổng kết bài học kinh nghiệm
Mặc dù dự án hiện tại vẫn còn một vài điểm hạn chế cần cải thiện như: bộ dữ liệu chuẩn (gold dataset) còn khá mỏng (25 câu), độ trễ khi chạy agentic hơi cao (~18 giây), và tầng Reranker chưa chạy tốt trên CPU.
Thế nhưng, sau 3 tháng lăn lộn, cái mình nhận được nhiều nhất chính là tư duy hệ thống (system thinking) thay vì chỉ biết viết prompt vu vơ. Mình đã học được cách làm ablation test có kỷ luật, biết đo lường hệ thống bằng các chỉ số kiểm thử chuẩn hóa, biết cách thiết lập bộ quy tắc từ chối (refusal rules), quản lý và giám sát hệ thống với LangSmith, và xây dựng các rào chắn chất lượng tự động thông qua CI/CD pipeline.
4. Link Source Code Dự Án (Github)
Nếu mọi người quan tâm đến kiến trúc Agentic RAG, muốn tham khảo source code chi tiết, báo cáo kỹ thuật đầy đủ cũng như các notebook chạy thử nghiệm ablation, có thể ghé qua repo GitHub của mình tại đây nhé. Rất mong nhận được những ý kiến đóng góp, gạch đá từ mọi người để mình hoàn thiện dự án hơn nữa. À mấy cái này mình học được từ Khóa học AI Engineer này, bạn có thể tham khảo nha.
Link GitHub: https://github.com/MacPhuPhong?tab=repositories
All rights reserved
