Web crawler nâng cao với Mechanize (P1)
Bài đăng này đã không được cập nhật trong 4 năm

Thời gian gần đây, mình đang tìm hiểu và code về Web crawler - chắc hẳn đây là khái niệm không mấy xa lạ với developer
Nhưng nếu chưa rõ về khái niệm này thì bạn có thể xem qua một chút về web crawler là gì, hoặc là có thể tìm kiếm các định nghĩa về crawler bằng google đại pháp. =))
Rails có cung cấp một thư viện để chúng ta thực hiện crawl một cách rất hiệu quả là gem Mechanize
Về việc cài đặt và sử dụng một cách cơ bản gem Mechanize để get dữ liệu từ một website nguồn thì bạn có thể đọc tại bài viết Web crawler và scrape data với gem Mechanize của tác giả Nguyễn Tấn Đức
Đặt vấn đề
Thực chất cách mà gem Mechanize làm việc thì cũng chỉ đi đến địa chỉ url nào đó và tiến hành get toàn bộ nội dung của website đó về dưới dạng kiểu dữ liệu của nó - đối tượng Mechanize::Page. Từ đó chúng ta có thể xử lý thông tin của website đó theo ý mình
Thông thường, những website mà chúng ta tiến hành crawl đều có một lượng thông tin, bài viết rất lớn, và dĩ nhiên website đó sẽ sắp xếp phân trang chúng để giúp cho giao diện web gọn gàng mà nguời dùng cũng dễ dàng sử dụng hơn. Mỗi trang trong danh sách phân trang thì chỉ chứa một số lượng nhất định các thông tin mà mình cần (30, 50...)
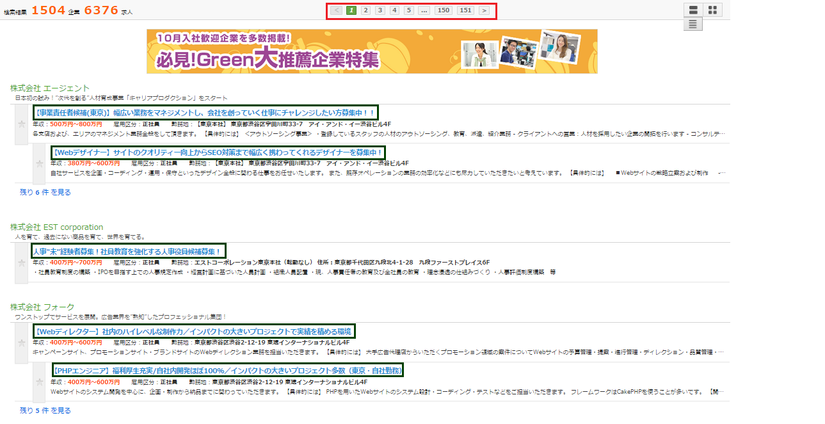
Ở hình trên thì có 2 phần
- Phần màu đỏ là danh sách các trang đã được phân ra (hiện tại thì đang ở trang 1)
- Phần màu xanh chính là link các bài viết cụ thể mà chúng cần phải click vào để xem thông tin chi tiết.
Cũng như khi chúng ta đọc tin online, lướt qua danh sách (đã được phân trang) để xem có bài viết nào hay, hấp dẫn thì click vào để đọc chi tiết. Nếu trang này không có gì hay ho thì lại click sang trang phân trang tiếp theo... Việc crawler ở đây chỉ khác là chúng ta chỉ cần tự động vào từng trang chi tiết, lấy toàn bộ thông tin chứ không quan tâm đến nội dung bên trong nó như thế nào
Chỉ với bài viết mình nêu ở trên thì chúng ta chưa thể crawl hết toàn bộ lượng thông tin cần thiết của một website vì thực chất mỗi trang trong danh sách phân trang sẽ có url khác nhau. Do đó ta chỉ crawl được một số lượng thông tin nhất định mà thôi
Vậy cần phải sử dụng gem Mechanize để click chuyển trang trong danh sách phân trang

Cơ bản thì cách làm của mình như sau
-
B1 : vào đến danh sách phân trang như hình trên
-
B2 : Lấy ra danh sách toàn bộ link các bài viết có trong trang đó
-
B3 : Click sang trang tiếp theo
-
B4 : Lặp đi lặp lại B2 và B3 cho đến khi nào hết
Website có thể dùng nhiều cách để làm cái button click chuyển trang, có thể là HTML, JavaScript nên cách làm cũng có đôi chút khác nhau. Ở phần này, mình xin trình bày cách click vào button chuyển trang là HTML
Phần 1 : Click link HTML.
Bắt đầu.
- Nguồn crawler : http://doda.jp/DodaFront/View/JobSearchList.action?so=50&tp=1&pic=1&ss=1&ds=0
- Mô tả :
- Input : Trang danh sách tất cả bài viết đã được phân trang.
- Output : Mảng chứa tất cả link bài viết chi tiết của website đó.
Cùng bắt tay vào làm thôi nào. Hình dưới là button chuyển sang trang tiếp theo mà chúng ta cần quan tâm

-
Trước tiên, mình phải lưu ý với các bạn là đầu vào của bước này là biến
workpagechứa thông tin website nhắc ở trên được get về bởi gemMechanize- một đối tượngMechanize::Page(byebug) workpage.class Mechanize::Page
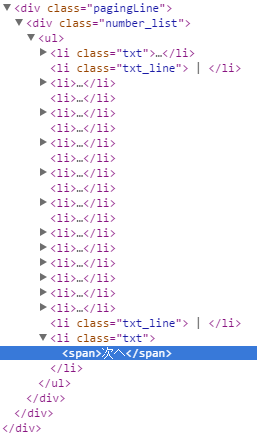
Khi kiểm tra phần tử button chuyển trang đó ta thấy
- Phần button nằm trong thành phần :
li.txt - Ta kiểm tra và thấy button đó ở đây có 2 trường hợp.
- Không ở trang cuối cùng thì gắn với một thẻ
<a>=>workpage.search("li.txt").present? = true
- Đang ở trang cuối cùng thì chỉ có nội dung text trong thẻ
<span>=>workpage.search("li.txt").present? = false
- Không ở trang cuối cùng thì gắn với một thẻ
Logic của mình ở đây như sau
- Đầu tiên là lấy tất cả các link ở trang phân trang đầu tiên, click next trang
- Tiếp theo là khi vẫn thỏa mãn
workpage.search("li.txt").present? = truethì sẽ :- Click sang trang kế tiếp
- Lấy tất cả link ở trang đó và lại tiếp tục
Trong đó
-
Link button click next page :
workpage.search("li.txt") -
Link của từng bài viết cụ thể trong danh sách của từng trang :
workpage.search("p.left_btn a")
Đây chỉ đơn giản là get dữ liệu bằng gem Mechanize thôi
- Mình xây dựng hàm
get_list_job_linkvới code đầy đủ ở đây như sau:
def get_list_job_link workpage
list_job_link = workpage.search("p.left_btn a").map {|link| link["href"]}
while workpage.search("li.txt").present?
next_link = workpage.search("li.txt")[1].children[0].attributes["href"].text
workpage = workpage.link_with(href: next_link).click
list_job_link += workpage.search("p.left_btn a").map {|link| link["href"]}
end
return list_job_link
end
Kết quả
(byebug) list_job_link
["http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001030835/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001044217/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001011745/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001000787/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001061324/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001058164/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3000941130/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3000987983/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001040438/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001061274/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001052267/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001018640/-fm__list/-tp__1/-mtmd__0/",
"http://doda.jp/DodaFront/View/JobSearchDetail/j_jid__3001000824/-fm__list/-tp__1/-mtmd__0/"]
Như vậy là ở đây thì chúng ta đã có được mảng chứa danh sách tất cả link bài viết chi tiết, việc còn lại đơn giản chỉ là sử dụng gem Mechanize để lấy thông tin từ các bài viết đó về mà thôi.
Với 1 lượng thông tin rất lớn (nghìn, chục nghìn và thậm chí là trăm nghìn bài viết) thì chúng ta nên kết hợp sử dụng Mechanize với Background Job để làm việc được hiệu quả tốt hơn.
Lời kết.
Việc crawl phụ thuộc rất nhiều vào cấu trúc, thiết kế của từng website cụ thể và cũng còn tùy vào thời điểm.
Có khi cùng 1 website nhưng thỉnh thoảng người ta lại thay đổi cấu trúc, bố cục nội dung cho đẹp hơn chẳng hạn... Cho nên, bạn đừng quá ngạc nhiên là vì sao mới hôm qua, code của mình còn get website đó ngon lành mà bỗng nhiên hôm nay lại chết ngỏm củ tỏi nhé. =))
Do vậy, người crawler cần phải linh hoạt, kiểm tra cấu trúc website cẩn thận và phải làm sao để code của mình có thể dễ dàng thay đổi cho phù hợp với dữ liệu.
Cách làm click vào link "HTML" để chuyển trang mà mình đề cập ở trên chỉ là một trường hợp đơn giản. Ngoài ra khi phân trang, còn có kiểu click link JavaScript, AJAX... Mà nếu thế thì gem Mechanize thần thánh này cũng phải chịu bó tay.(rofl)
Tuy nhiên, chúng ta vẫn còn cách để "xử đẹp" vấn đề này và mình xin trình bày ở phần 2 của bài viết (vì để vào cùng một bài viết thì sẽ dài lắm luôn, nó không hay =)).
Tham khảo.
- https://viblo.asia/nguyen.tan.duc/posts/eBYjv410RxpV
- https://github.com/sparklemotion/mechanize
- http://cafefreelancer.com/crawler-la-gi-lay-tin-tu-dong-la-gi.html
Cám ơn bạn đã đọc bài viết!!! tribeo
All rights reserved
