Web crawler và scrape data với gem Mechanize
Bài đăng này đã không được cập nhật trong 4 năm
1. Web crawler
Web crawler (hay còn gọi là web spider, web robot) là một chương trình được thiết kế để thu thập các tài nguyên trên internet từ các trang web khác. Web crawler được chủ yếu sử dụng để phục vụ cho các search engine (Google, Yahoo, Bing,...).
Khi có ai đó tìm kiếm một thông tin, các search engine lập tức hiển thị các thông tin lưu trữ tương ứng.
Cơ chế hoạt động
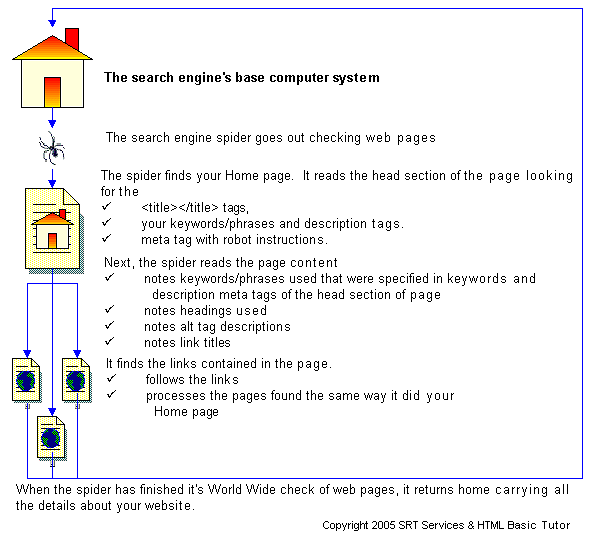 (nguồn: http://www.htmlbasictutor.ca/)
(nguồn: http://www.htmlbasictutor.ca/)
Từ một list các trang web, web crawler bắt đầu quá trình "crawl" dữ liệu, thường bắt đầu từ những trang web phổ biến, có nhiều lượt truy cập nhất.
Web crawler thu thập các thông tin về website và nội dung bên trong đó:
- Website url.
- Title.
- Thẻ meta tag.
- Nội dung page.
- Các đường link trên web.
- ...
Kết quả thu thập trả về được đánh dấu và sắp xếp lại bởi search engine.
2. Mechanize
- Nguồn: https://github.com/sparklemotion/mechanize
- Mechanize là một thư viện cung cấp các hàm để tương tác với websites. Nó có thể truy cập đường link, submit forms, tự động lưu trữ cookies,... giống như truy cập một cách bình thường trên browser.
Cài đặt:
gem install mechanize
**Một số dòng lệnh cơ bản:**
#Khởi tạo object
agent = Mechanize.new
#Fetch page
page = agent.get("http://google.com")
#Tìm tất cả các link có trong page
page.links.each do |link|
puts link.text
end
#Click link
agent.page.link_with(text: "News").click
**Xử lý form:**
Giả sử ta có 1 form HTML như sau:
<form name="form1">
<input type="text" name="username"/>
<input type="password" name="password"/>
<input type="submit" name="login"/>
</form>
Từ đó ta có:
login_form = page.form("form1")
#Điền thông tin vào input có name tương ứng
login_form.username = "vibloasia"
login_form.password = "12345678"
#Submit form sau khi đã điền đủ thông tin
home_page = agent.submit login_form
**Scraping Data:**
Để scraping data, Mechanize truy cập tới trang web cần scrape, sau đó sử dụng method của gem Nokogiri thực hiện scrape dữ liệu:
#Ta có thể sử dụng DOM hoặc XPath để chỉ định mục cần lấy dữ liệu
#Hàm search trả về 1 mảng các kết quả
list_post = agent.get("http://something.com").search("h1 a")
#Hàm at trả về kết quả đầu tiên
post = agent.get("http://something.com").at("h1 a")
3. Demo scrape data
-
Site: http://news.google.com
-
Mục tiêu: Lấy toàn bộ title, link, ảnh và small description trên trang chủ.
Bắt đầu khởi tạo:
agent = Mechanize.new
page = agent.get "http://news.google.com"
**Phân tích website:**
Xác định vị trí các title, description, image
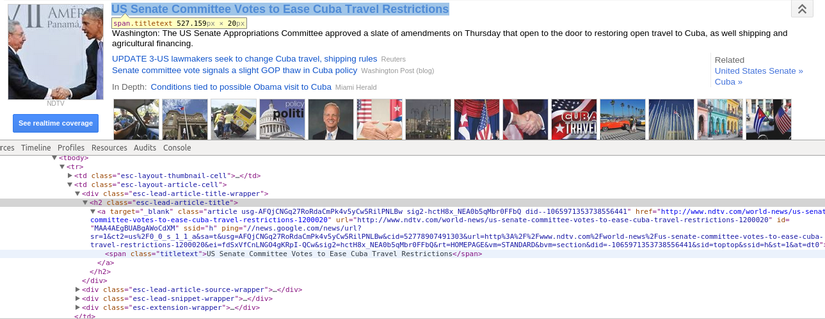
**Cấu trúc trang có thể hiểu đơn giản như sau: **
<div class="esc-body">
<h2>
<a href="Link in here">
<span class=titletext>Title here</span>
</a>
</h2>
...
<div class="esc-lead-snippet-wrapper">
Description here
</div>
...
<div>
<img src="Link image here"/>
</div>
</div>
Tiến hành scrape data:
@post_array = []
#Mỗi 1 post được bao bởi thẻ div esc-body
list_post = page.search "div.esc-body"
#Với mỗi post lấy được, tìm kiếm nội dung bên trong
list_post.each_with_index do |post, num|
#Lấy nội dụng title
title = post.search("h2 span.titletext").text
#Lấy description
description = post.search("div.esc-lead-snippet-wrapper").text
#Lấy đường link từ attributes của thẻ a
link = post.at("h2 a").attributes["href"].text
#Lấy link ảnh từ attributes của thẻ img
image = post.at("img.esc-thumbnail-image").attributes["src"].text
#Tạo hash và đưa vào mảng
@post_array[num] ={title: title, description: description, link: link, image: image}
end
Kết quả sau vòng lặp là mảng chứa tất cả các thông tin cần lấy.
Lưu ý:
Ví dụ trên chỉ là mang tính minh họa, cơ bản về crawler. Khi xây dựng ứng dụng ta cần lưu ý 1 số điều sau:
- Để lấy được thông tin, Crawler phụ thuộc vào cấu trúc trang web. Nếu trang web thay đổi format thì Crawler hoạt động không còn chính xác nữa. Vì vậy, ta cần xây dựng Crawler có tính mềm dẻo, có thể lấy thông tin từ nhiều nguồn khác nhau mà ít phải config hay code lại.
- Nên truy cập với tần suất hợp lý, tránh tình trạng trở thành tấn công DDos.
- Có thể sử dụng proxy để che dấu IP nếu cần thiết.
All rights reserved
