VXLAN BGP EVPN phần 1 - Tổng Quan về VXLAN
Mở Đầu
Ngày nay, cho dù là mạng Layer3 IP đang phát triển thì nhu cầu mở rộng miền Layer 2 để kết nối giữa các Server trong một DC hoặc Multi-DC với nhau vẫn luôn rất cần thiết mà thậm chí các yêu cầu về VM Live Migration, iSCSI, FCoE, HPC, Cluster,... tốt nhất vẫn cần các Host phải kết nối với nhau qua Layer2. Với mô hình DC nhỏ thì không quá thành vấn đề, các công nghệ Switching, VLAN đều đáp ứng tốt nhu cầu đó. Nhưng với mô hình DC lớn và phức tạp thì các nhu cầu trên là một thách thức khá lớn với hạ tầng DC truyền thống. Chưa kể, nếu cần mở rộng Layer2 DC-to-DC mà chỉ có kết nối IP WAN, không có kênh truyền MPLS(L2VPN) hay DWDM(L1) thì khá là đau đầu. Cho nên cần phải có sự đổi mới về công nghệ Network Infra cho DC thì mới đáp ứng được nhu cầu và độ phát triển theo chiều ngang của hệ thống IT ngày nay được. Do đó, chuyển dịch Traditional DC sang Modern DC không chỉ là xu hướng, mà còn là nhu cầu cần thiết của các doanh nghiệp. Bây giờ, mình sẽ trình bày một công nghệ mới đang được phổ biến trong các hạ tầng DC hiện đại đó là VXLAN BGP EVPN. Vì nội dung này khá dài nên mình chia ra làm 3 bài viết:
Link phần 1 - Tổng Quan về VXLAN
Link phần 2 - BGP EVPN Signaling
Link phần 3 - L3VPN và Multicast over VXLAN
Kiến trúc của Traditional Data Center
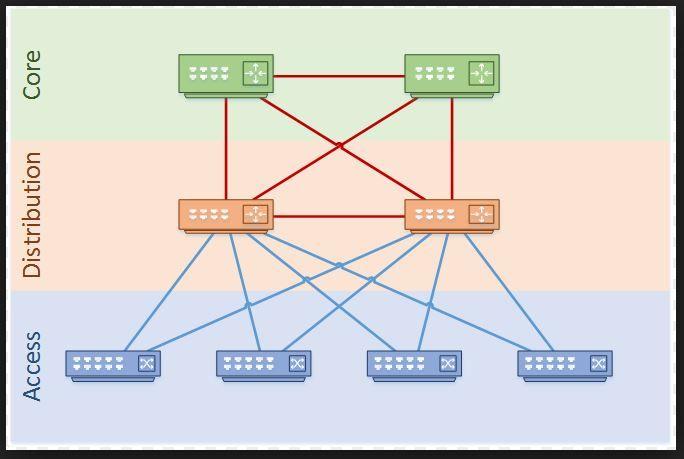
Ở mô hình Data Center truyền thống cơ bản được chia làm 3 phân lớp như trên Hình 1:
- Access Layer: Đóng vai trò là điểm kết nối của các End Device.
- Distribute Layer: Kết nối các Access Switch và thường đóng vai trò Inter-Vlan Routing.
- Core Layer: Đóng vai trò làm gateway của các traffic kết nối đi ra WAN.
Để đảm bảo dự phòng về kết nối, các thiết bị đấu nối Fullmesh giữa các Layer với nhau. Trong cùng 1 Layer, các thiết bị cũng tiếp tục kết nối trực tiếp sang nhau. Với kiểu thiết kế này, để chống Loop, cần phải sử dụng STP(Spanning Tree). Khi sử dụng STP, chắc chắn sẽ có những kết nối bị Block và không tận dụng được băng thông tại đó. Khi mô hình DC lớn dần, các thiết bị Switch ngày càng nhiều và nhu cầu mở rộng miền Layer2 tăng lên, đặc biệt là Multi-DC Layer2 Spread, dẫn đến việc quản lý cây STP phức tạp. Khi xảy ra sự cố trong mạng, STP là một giao thức hội tụ chậm, gây gián đoạn lâu cho nên không đảm bảo được chất lượng dịch vụ. Tất nhiên giao thức PVST (Per VLAN Spanning Tree) có thể được sử dụng để giảm bớt việc lãng phí băng thông đường truyền, nhưng tóm lại nó vẫn là cơ chế Load Sharing thủ công dựa trên VLAN. Việc Load Sharing theo từng VLAN mình thấy không tối ưu và không hiệu quả. STP còn gây hội tụ chậm, đặc biệt với mô hình DC lớn.
Bên cạnh đó, nếu như traffic North-South thường ổn định, mức độ tăng dễ kiểm soát hơn thì với ứng dụng ngày nay phát triển theo mô hình Microservice và để đảm bảo tính Resilency, các VM, Software Component được trải rộng theo chiều ngang, dẫn đến traffic East-Westsinh ra nhiều và mức độ tăng mạnh hơn.
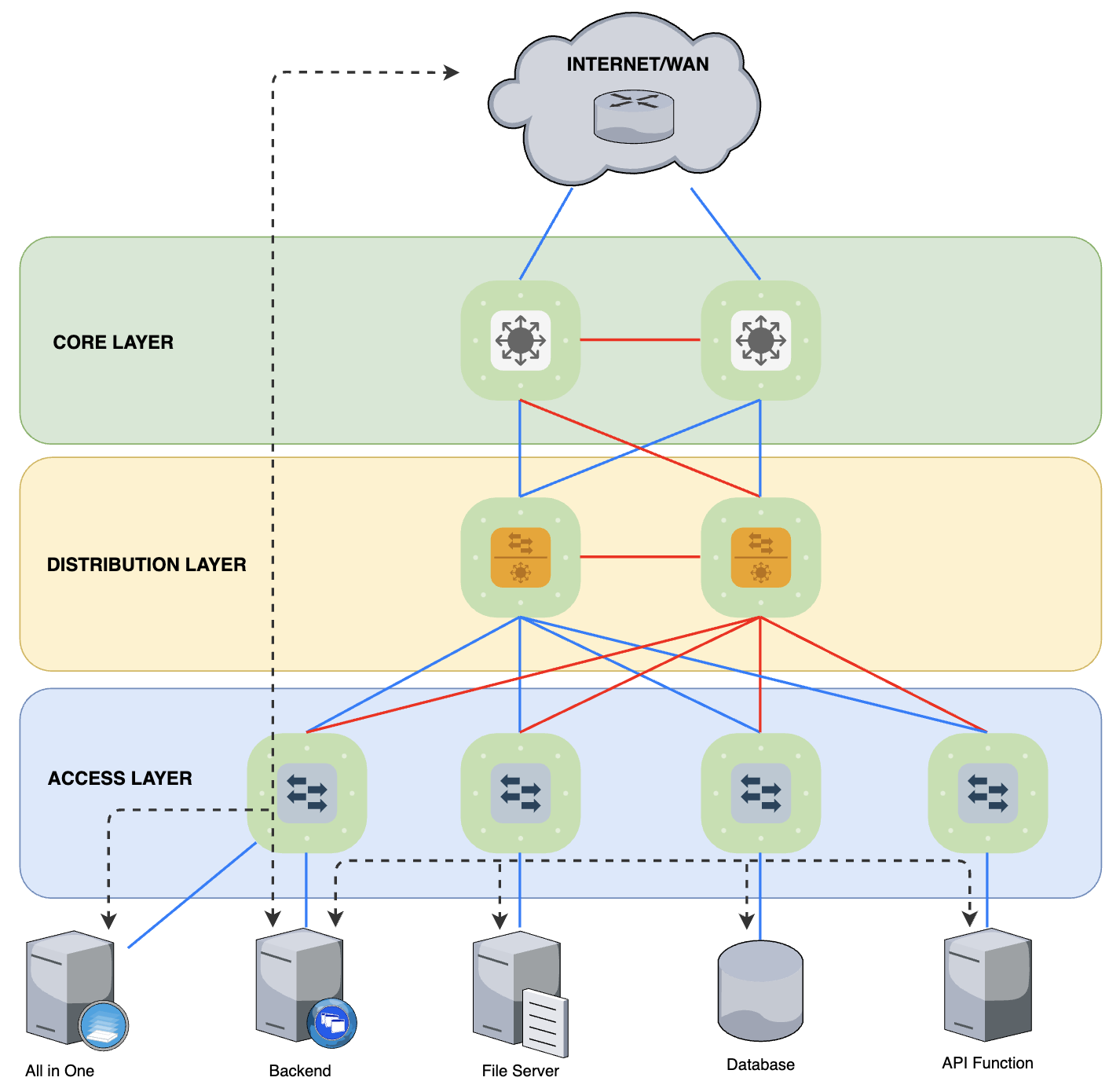
Ở ví dụ trên, nếu mình build một Web/App Service với tất cả các component trong 1 Server Host duy nhất (All-In-One), việc tính toán băng thông dịch vụ chỉ cần quan tâm đến lưu lượng North-South. Nhưng với mô hình Microservice, các Component nằm trên nhiều máy chủ vật lý khác nhau, sinh ra các lưu lượng phải gọi lẫn nhau để xử lý được các Function cụ thể khiến lưu lượng East-West tăng đáng kể. Để mà đáp ứng được sự phát triển này, với những yếu điểm kể trên thì DC truyền thống đang khá là cá đuối.
Kiến trúc mạng mới của mô hình Modern Data Center
Với những phân tích vừa rồi. Việc chuyển đổi từ Traditional Data Center sang Modern Data Center là một điều cần thiết. Mô hình được gọi là “Modern” cho DC hiện nay chính là mô hình Spine-Leaf như hình mô tả dưới đây.
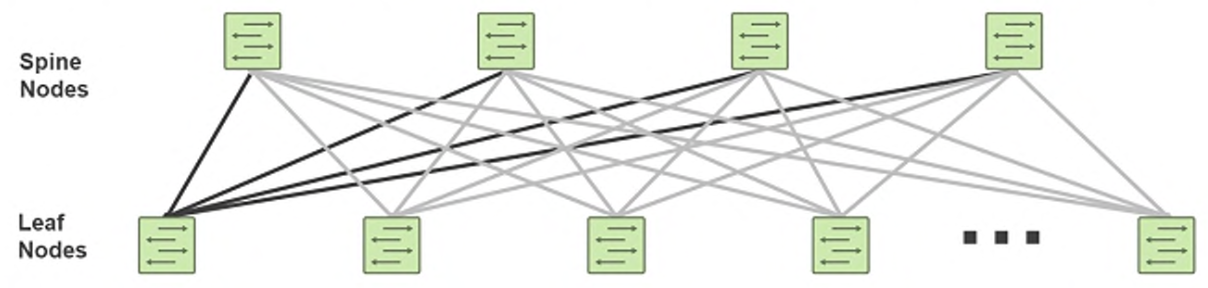
Thật ra mô hình này được phát triển bởi Charles Clos từ những năm 1950s. Nhưng đến tận bây giờ nó mới được áp dụng vào mô hình DC hiện đại. Clos Network dựa trên kiến trúc 3-Stage gồm: Ingress stage, Middle stage, Egress stage. Leaf Node đóng vai trò là Ingress/Egress Stage, Spine Node đóng vai trò là Middle Stage. Vì kiểu thiết kế này gồm rất nhiều các kết nối đan xen nhau và đều bằng IP nên hiện nay còn được gọi là "IP Fabric" hay "Clos Fabric". IP Fabric chính là Underlay vận chuyển các lưu lượng Data ở Overlay bằng IP.
Đặc trưng của mô hình này là các thiết bị nằm ở các Stage khác nhau sẽ được kết nối với nhau, các thiết bị trong cùng Stage sẽ không cần kết nối với nhau.
3-Stage IP Fabric Architecture
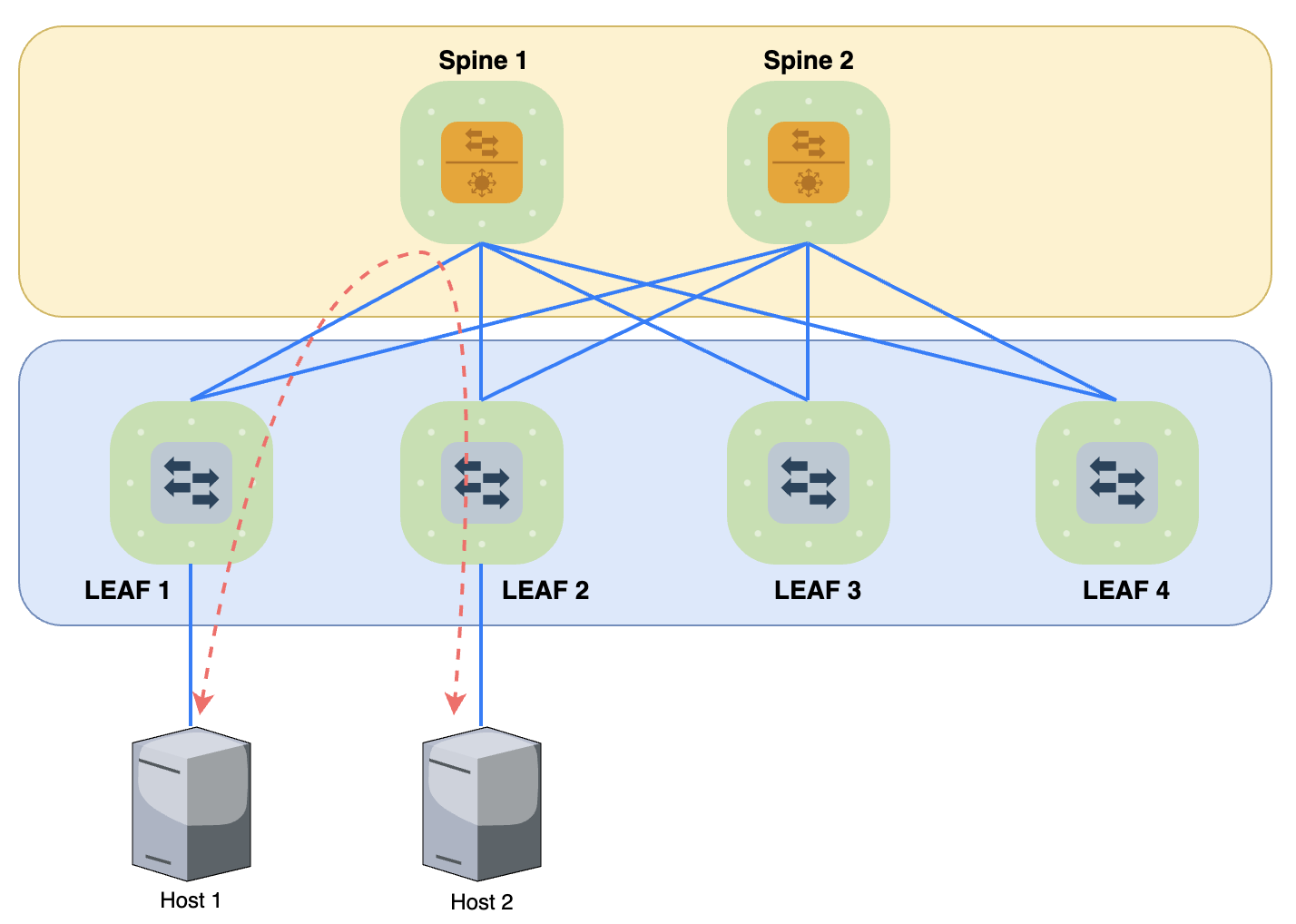
Tại sao lại là 3-Stage. Vì traffic kết nối giữa 2 Host đi qua Leaf-Spine-Leaf cho nên được gọi là 3-Stage. mô hình này phù hợp với các DC nhỏ cho tới vừa. Mỗi một kiến trúc này còn gọi là một POD.
5-Stage IP Fabric Architecture
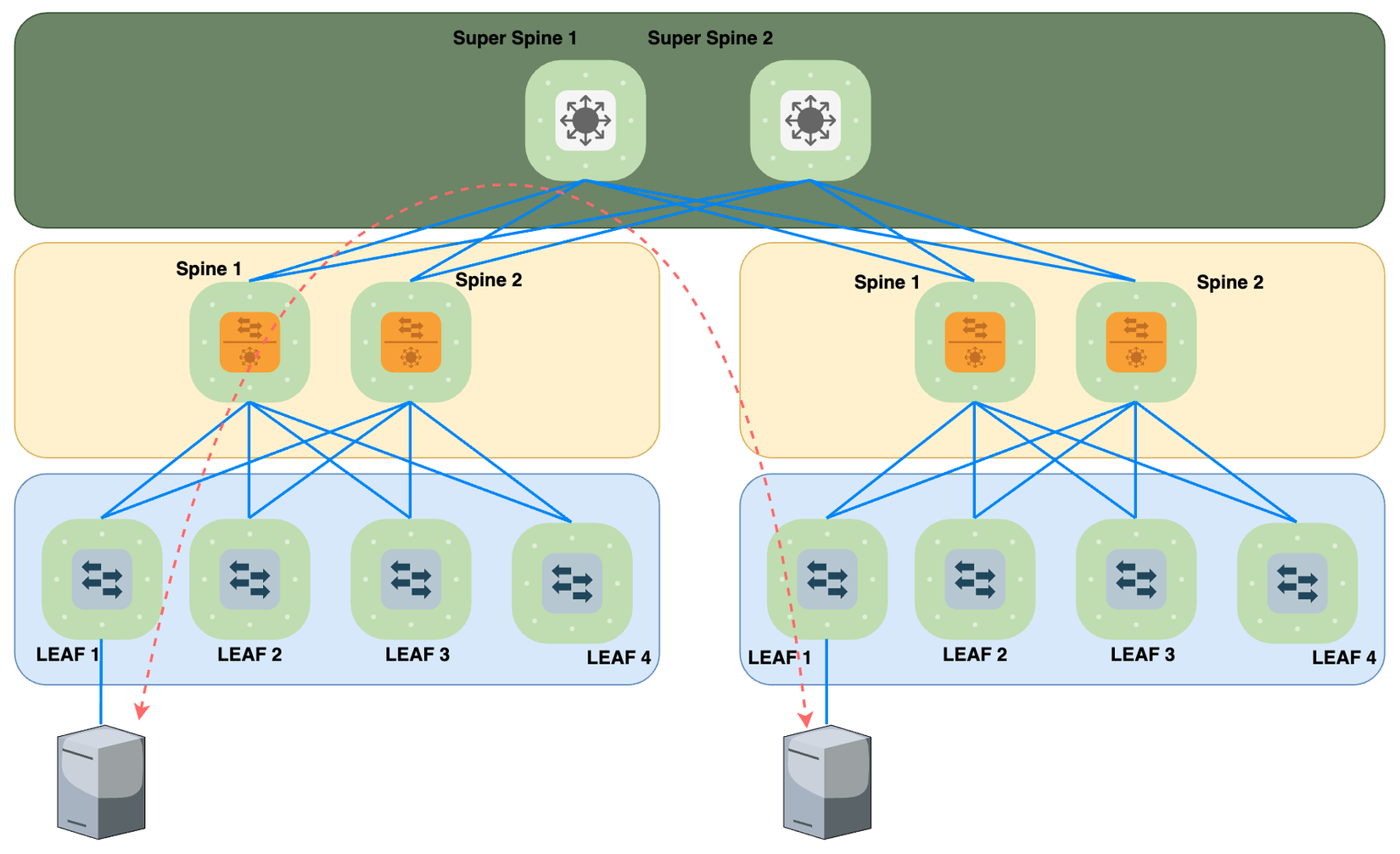
Với 5-Stage, Kết nối giữa 2 Host đi qua 5-Stage: Leaf-Spine-SuperSpine-Spine-Leaf. Kiến trúc này phù hợp với mô hình DC lớn, mang lại tính Scalability lớn hơn.
Ưu điểm của mô hình Underlay sử dụng kiến trúc IP Fabric
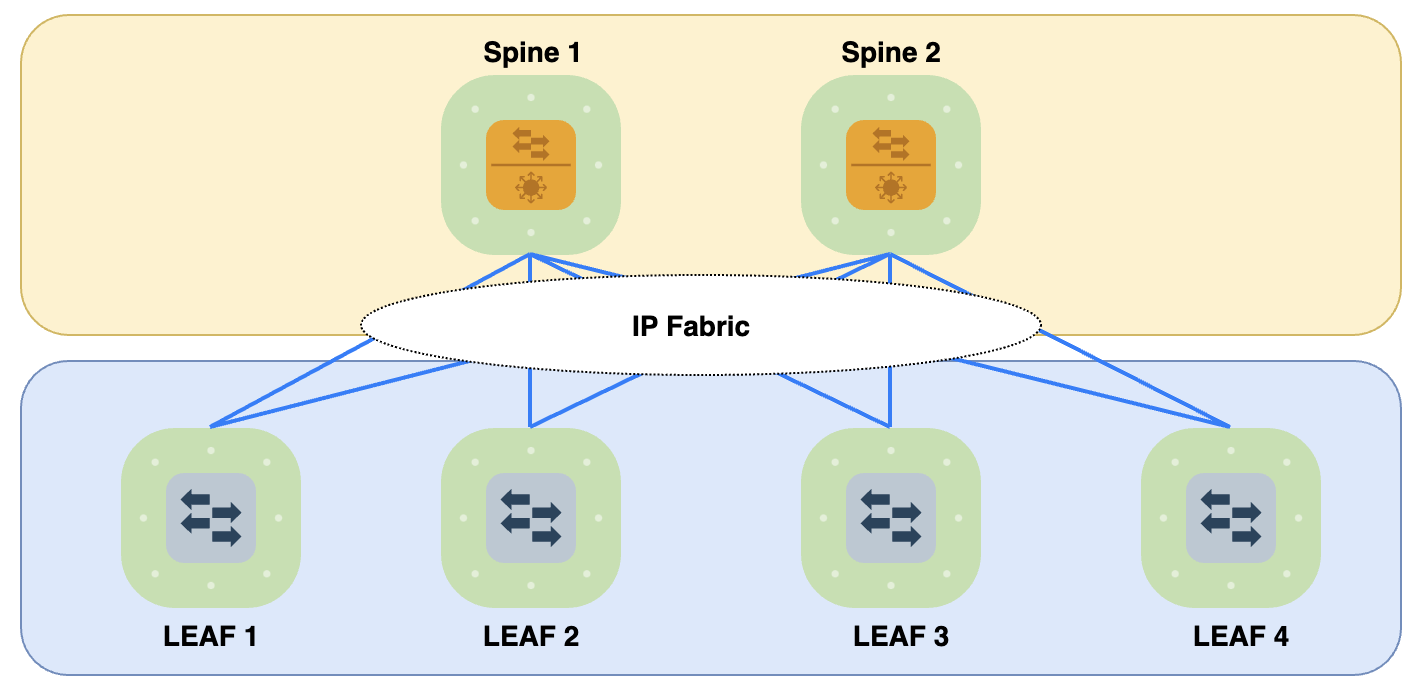
Toàn bộ phần kết nối giữa Spine-Leaf này đều là IP. các lưu lượng giữa Host-to-Host ở Overlay sẽ được tạo Tunnel trên IP Fabric Underlay cho nên điểm lợi đầu tiên có thể thấy là chống Loop Underlay nhờ sử dụng TTL. Tiếp theo là các giao thức IP như OSPF, IS-IS, BGP sử dụng ECMP(Equal-Cost Multi-Path)để Load Sharing traffic qua các kết nối giữa Spine-Leaf, tận dụng tối ưu được băng thông thay vì lãng phí như khi sử dụng STP trong môi trường DC truyền thống. Khi cần mở rộng theo chiều ngang, chỉ cần bổ sung thêm Leaf và kết nối tới các Spine, các Dynamic IP Routing Protocol này còn hội tụ nhanh nữa.
Dynamic IP Routing Protocol nào cho Underlay?
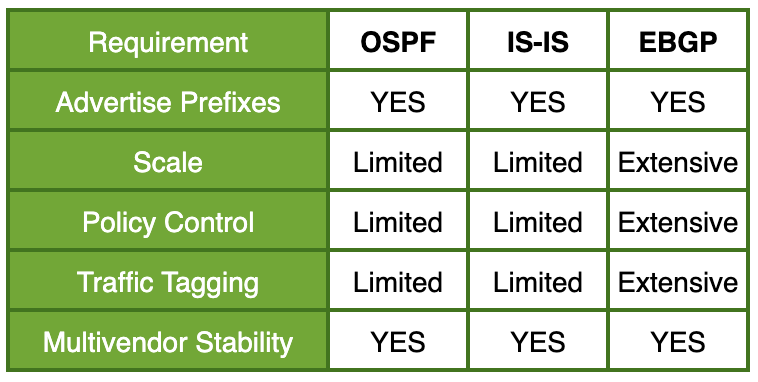
Với các giao thức Routing phổ biến, chúng ta có thể sử dụng OSPF hoặc IS-IS. Nhưng thông thường Best Practice trong thiết kế Underlay sẽ là sử dụng BGP. Khả năng Scalable của BGP là hơn hẳn so với OSPF/IS-IS. Nhưng ở DC vừa và nhỏ thì số lượng Route quảng bá ở Underlay không nhiều, chủ yếu là Loopback IP của các Node, cho nên OSPF/IS-IS vẫn đáp ứng được.
Bên cạnh đó, để Control Policy Route nâng cao thì BGP tốt hơn hẳn vì nó hỗ trợ rất nhiều Attribute/Tag/ExtCommunity cho các Route mà nó có thể quảng quá, dựa vào đó Network Admin có thể kiểm soát route một cách hiệu quả, thậm chí hỗ trợ cho cả việc Load Sharing khi muốn ECMP trên các đường vật lý không đều nhau về băng thông chẳng hạn. Nhưng nếu mà ae đầu tư đồng đều về mặt kết nối, thiết bị, mô hình DC vừa và nhỏ thì có thể chọn OSPF/IS-IS cho hội tụ nhanh cũng được.
Protocol nào cho Overlay Signaling?
Giống như Underlay, Overlay cũng có những giao thức sử dụng nền Underlay để vận chuyển các traffic của các dịch vụ khác bên trên như VXLAN, MPLS, GRE,…Trong đó, VXLAN là giao thức mới nhất và đang là giao thức tiêu chuẩn được sử dụng cho Overlay của mô hình DC hiện đại. GRE phù hợp với triển khai Tunneling đơn giản như Point-to-Point và GRE Header không chứa thông tin về Label để định nghĩa miền L2 như MPLS hay VXLAN nên GRE không phù hợp với kiểu triển khai này. còn MPLS và VXLAN hỗ trợ Point-to-Multipoint nên có khả năng mở rộng tốt hơn.
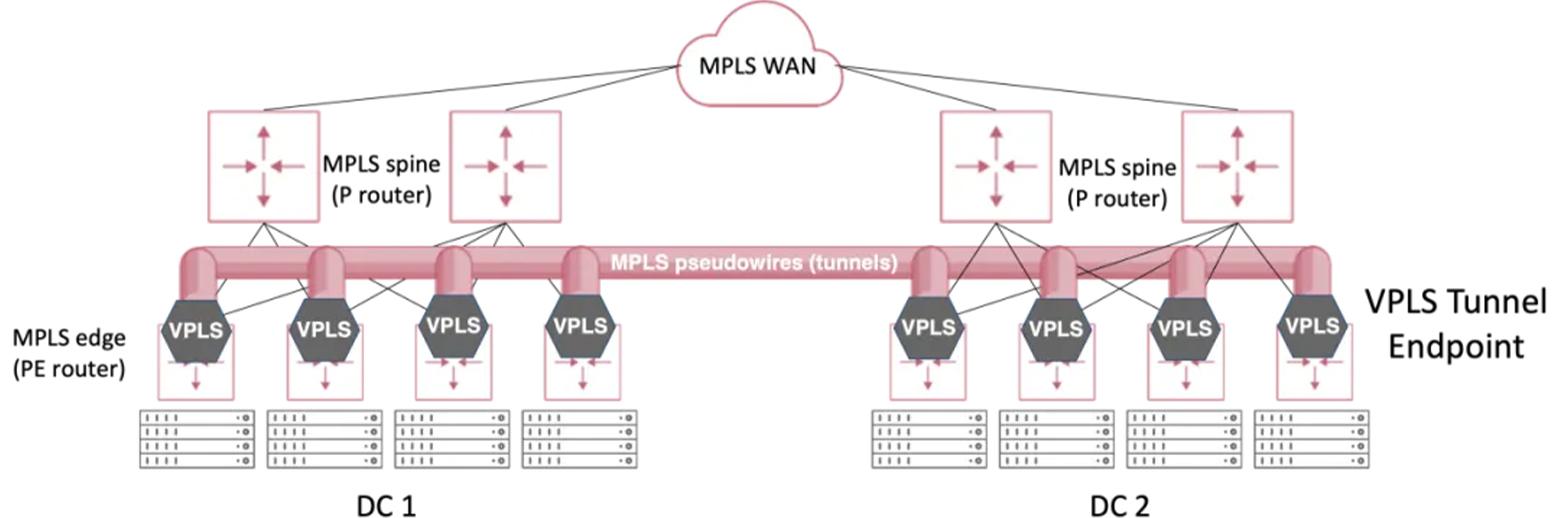
Với MPLS, chuyển mạch thực chất không dùng IP mà tất cả các P và PE Router đều chuyển mạch dựa vào Label (Nhãn) cho nên trong DC tất cả các Node đều phải hỗ trợ MPLS, dẫn đến tăng về chi phí đầu tư do MPLS Router thường đắt hơn Switch thông thường. Lại quay lại điểm hạn chế mà nãy mình có nói khi muốn Stretch Layer 2 qua đường WAN thì chính vì MPLS không dựa vào IP ở Underlay để chuyển mạch nên không tận dụng được IP WAN đơn thuần mà phải kéo được kênh DWDM hoặc thuê đường truyền MPLS (L2VPN) thì mới làm được điều này => 2 option này thì tốn tiền rồi.
Còn đối với VXLAN thì khác, chỉ có Tunnel Endpoint (ở đây là các Leaf) mới cần hỗ trợ công nghệ VXLAN, còn Spine chỉ cần đọc gói tin Layer3 rồi định tuyến thôi, không cần phải hiểu VXLAN Header. Và vì dùng IP ở Underlay để vận chuyển Data nên tận dụng luôn được IP WAN sẵn có mà không cần phải thuê kênh MPLS (L2VPN) của nhà mạng hoặc thuê đường DWDM, nghĩa là về mặt logic thì hoàn toàn có thể đáp ứng được mở rộng L2 giữa các DC đặt ở bất kì đâu trên toàn thế giới rất dễ, miễn là IP WAN đó thông tới nhau là được. Do đó, công nghệ VXLAN đang là lựa chọn tốt nhất cho mô hình DC hiện đại.
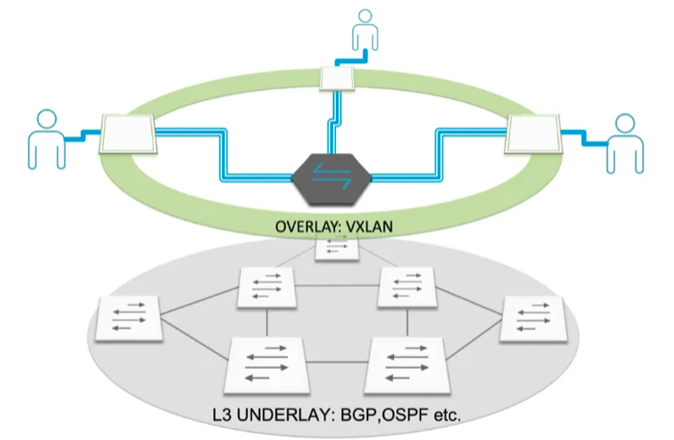
Tóm lại:
Underlayđược xây dựng với kiến trúc IP Fabric và sử dụng BGP để định tuyến.Overlaysử dụng VXLAN Tunnel để truyền các lưu lượng thực tế cho dịch vụ.- Để dễ hình dung thì hãy tưởng tượng
Overlaygiống như một Switch ảo chuyển gói tin giữa các Host, các LEAF Switch đóng vai trò như các interface của Switch ảo đó.
Cơ chế hoạt động của VXLAN Overlay
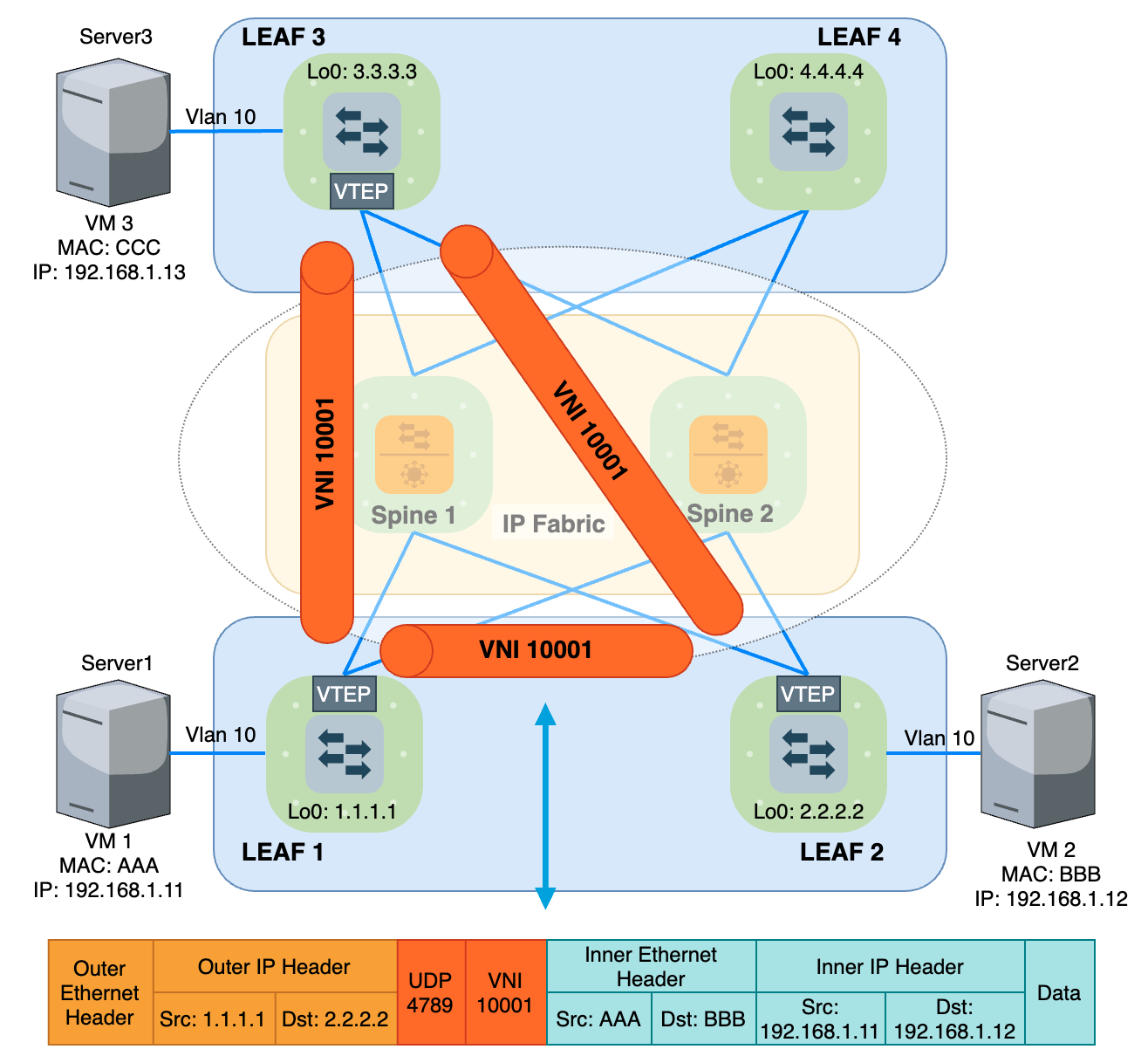
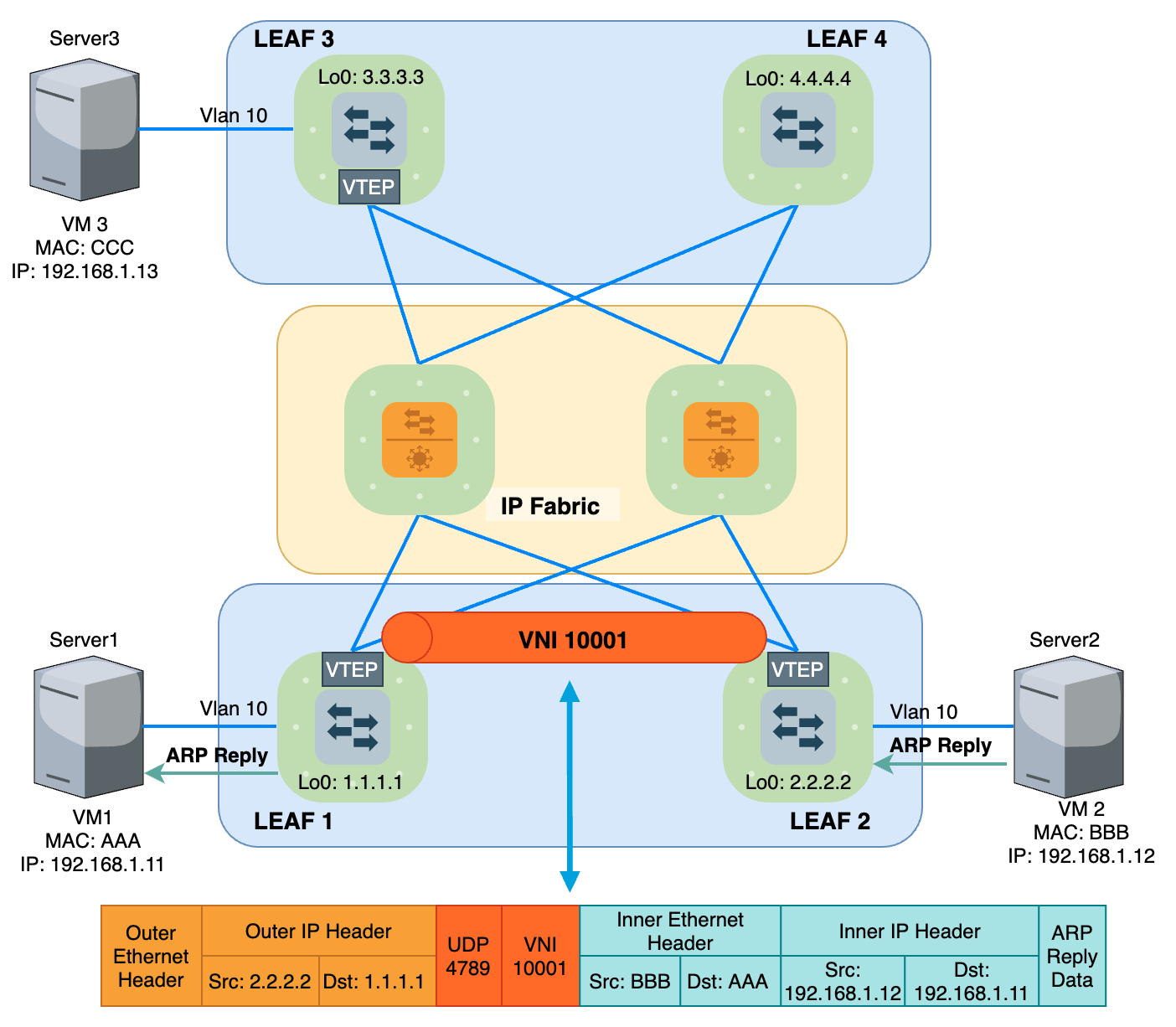
Bằng cách đóng gói dữ liệu bằng Outer IP Header + VXLAN Header và truyền trong miền IP Fabric, ta đã mở rộng được miền Broadcast Layer 2 trên nền IP. Xét ví dụ ở Hình 10, VM1 và VM2 kết nối tới 2 Leaf khác nhau và cùng thuộc VLAN 10, để 2 VM này chung một miền Broadcast Domain, Leaf1 và Leaf2 được cấu hình để Mapping VLAN 10 với VNI 10001.
VTEP (Virtual Tunnel EndPoint) đóng vai trò Encapsulation và De-Encapsulation Data giữa Underlay và Overlay. Khi Leaf1 nhận được lưu lượng từ VM1 gửi tới, VTEP trên Leaf1 sẽ đóng thêm VNI Header 10001 và Outer Header (IP+MAC) để có thể định tuyến được trên miền IP Fabric. Sau khi Data tới được Leaf2, VTEP trên Leaf2 thực hiện Mapping VNI Header 10001 ngược lại với VLAN 10, gỡ VXLAN Header rồi Forward xuống cho VM2. Vậy lúc này hình thành 1 Tunnel ảo nối giữa VM1 và VM2, tương tự với VM3. Từ đó, hình thành 1 miền Broadcast Domain ứng với VNI 10001 trên nền IP Fabric Underlay. Vì VTEP là thành phần đại diện của 1 Tunnel ảo và nằm trên Leaf, nên từ giờ mình sẽ gọi chung lại là Leaf cho gọn và đỡ rối rắm.
Việc đóng tunnel nghe có vẻ khá đơn giản, nhưng làm sao để một Leaf biết được phải đóng VNI nào? Outer IP Header nào? gửi qua Spine1 hay Spine2? thì mình sẽ đi vào chi tiết ngay sau đây. Nhưng trước hết đây là cấu trúc của một VXLAN Data Frame.
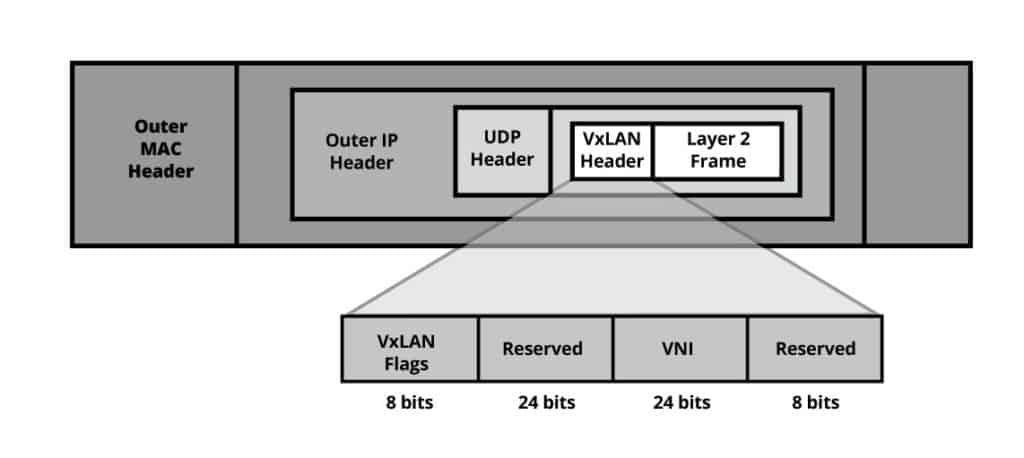
VXLAN Header gồm 24bit dành cho định danh VNI, tức là có thể sử dụng được 16 triệu VNI, nhiều hơn con số khiêm tốn 4094 của VLAN ID. Giá trị VNI này sẽ được cấu hình Mapping với VLAN ID trên từng Leaf.
Các cơ chế Signaling VXLAN
Có lẽ với bất kì một giao thức định tuyến nào thì cơ chế Signaling vẫn luôn đóng vai trò quan trọng và phức tạp nhất. Control Plane sẽ đảm nhiệm phần việc như quảng bá, học route,… giữa các Leaf/Spine với nhau. Data Plane sẽ dựa vào thông tin từ Control Plane đã tính toán được từ trước và cứ thế thực hiện Forwarding Data.

Giờ nói lại ví dụ ở Hình 10 và Hình 12, để VM1 (IP 192.168.1.11) có thể gửi một gói tin hoàn chỉnh tới VM2 (192.168.1.12) thì nó cần biết Destination Mac Address của VM2 để điền vào Data Frame. Còn Leaf1 để đóng được VXLAN Tunnel, nó cần biết VM2 thuộc Leaf nào để điền được thông tin Destination IP ở Outer Header rồi gửi tới Leaf đó (ở đây là Leaf2). Lúc này, giữa các VM cần có một cơ chế để quảng bá thông tin MAC cho nhau, ARP Request/Gratuitous đã làm được điều này. Còn giữa các Leaf, hiện nay cơ bản có 2 cách để quảng bá thông tin này.
1. Cấu hình thủ công
Trên mỗi Leaf sẽ phải cấu thủ công định nghĩa rõ các Remote Leaf còn lại (như ở ví dụ trên là Leaf1 Loopback và Leaf2 Loopback). Nếu với DC lớn, số lượng Leaf và VNI nhiều, mỗi khi cần thay đổi trong hạ tầng VXLAN thật sự là thách thức cho Network Admin và việc cấu hình thủ công chắc chắn là không đảm bảo về tốc độ cũng như độ chính xác. Cho nên không cần nói cũng thấy phương án này không hiệu quả 😌
2. Cấu hình Signaling động:
Với cấu hình động, việc mở rộng hạ tầng mạng sẽ nhanh, chính xác và hiệu quả hơn. Các thiết bị thiết lập Peer với nhau, tự quảng bá các thông tin cho nhau. Khi một Leaf muốn tham gia vào VNI Tunnel nào đó, chỉ cần bổ sung cấu hình ở Leaf mới đó thôi là các Leaf khác sẽ tự học được. Dynamic Signaling cho VXLAN thì hiện tại có một vài giao thức sau:
- OVSDB-VxLAN: Cái này liên quan tới giải pháp về
Controllernên mình sẽ không nói ở đây - Multicast Signaling: Sử dụng
PIMđể quảng bá và học MAC - BGP EVPN Signaling: Sử dụng
MP-BGP (Multiple Protocol BGP)để quảng bá cácBGP EVPN Route, ngoài MAC nó còn được phát triển để quảng bá cảMAC+IP Binding,IP-Prefixvà nhiều loại thông tin khác trênOverlaynữa, khiến EVPN trở giao thức tiêu chuẩn và được sử dụng rộng rãi nhất với công nghệVXLANhiện tại.
Với Multicast signaling, nói là quảng bá MAC thì không được đúng bản chất cho lắm. Vì nó không dùng một loại bản tin đặc biệt nào để quảng bá cả, mà nó chỉ đóng gói trực tiếp BUM Data trong VXLAN Header và gửi vào cây Multicast được phân phối bởi PIM. Cho nên có thể nói đây là hình thức Data Plane Signaling.
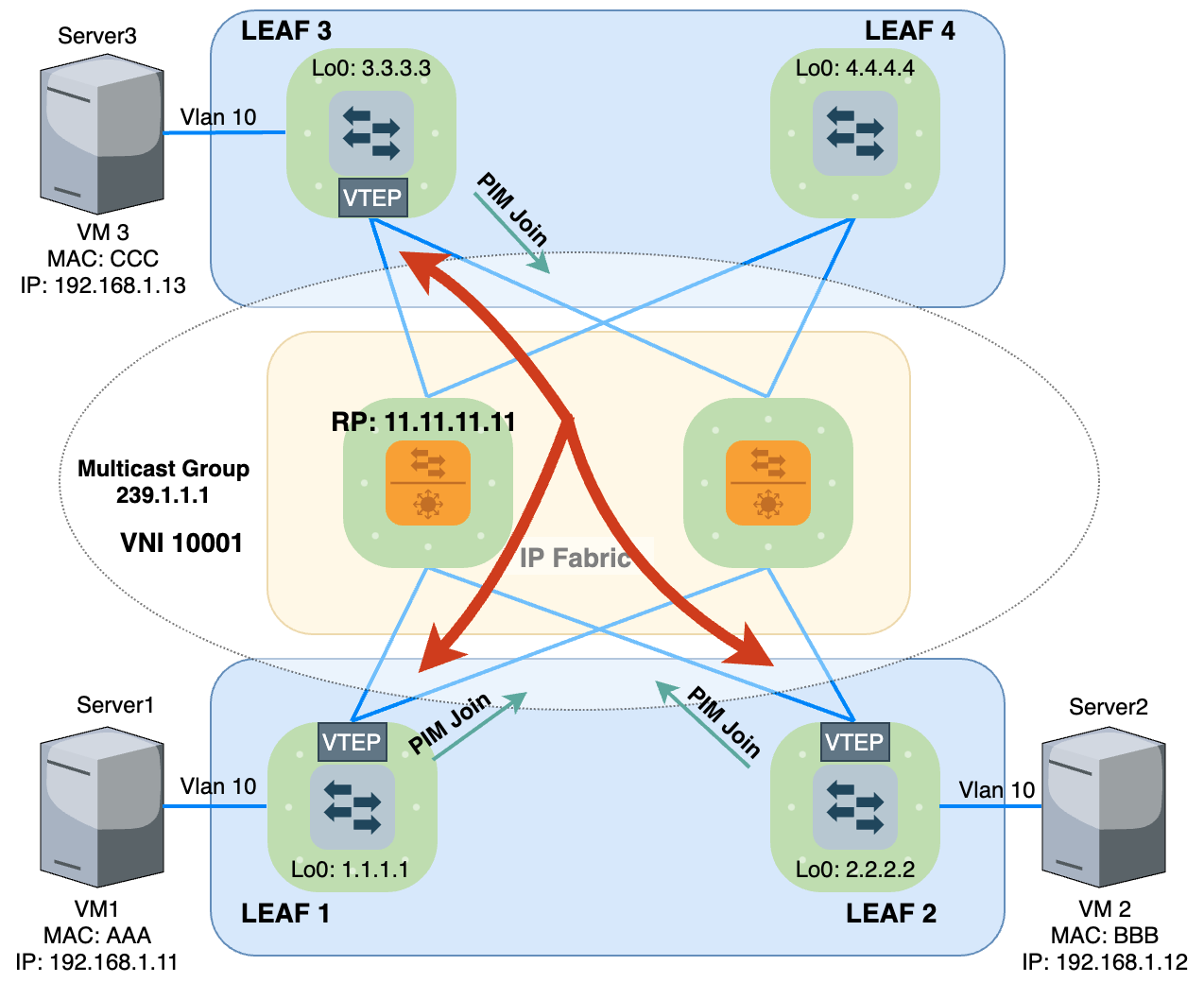
Các thiết bị Spine/Leaf đều phải thực hiện cấu hình giao thức PIM. Với mô hình LAB ở hình 13, mình cấu hình PIM Sparse mode và chỉ định RP là 11.11.11.11 (Loopback của Spine1). Mình sẽ không nói sâu về PIM ở bài viết này, coi như là ae đã biết cách hoạt động của PIM rồi. Chỉ nói qua là RP (Rendezvous Point) sẽ đóng vai trò làm gốc của cây Multicast. Các Leaf muốn nhận lưu lượng của Group Multicast 239.1.1.1 thì chủ động gửi PIM Join tới RP định kỳ thì RP mới đổ lưu lượng xuống các thiết bị đó. Ở đây, Group Multicast 239.1.1.1 chính là địa chỉ đại diện cho VNI Tunnel 10001. Dưới đây là nội dung của bản tin PIM Join được gửi từ Leaf2 gửi tới RP để thông báo muốn tham gia nhận lưu lượng của Group Multicast 239.1.1.1.
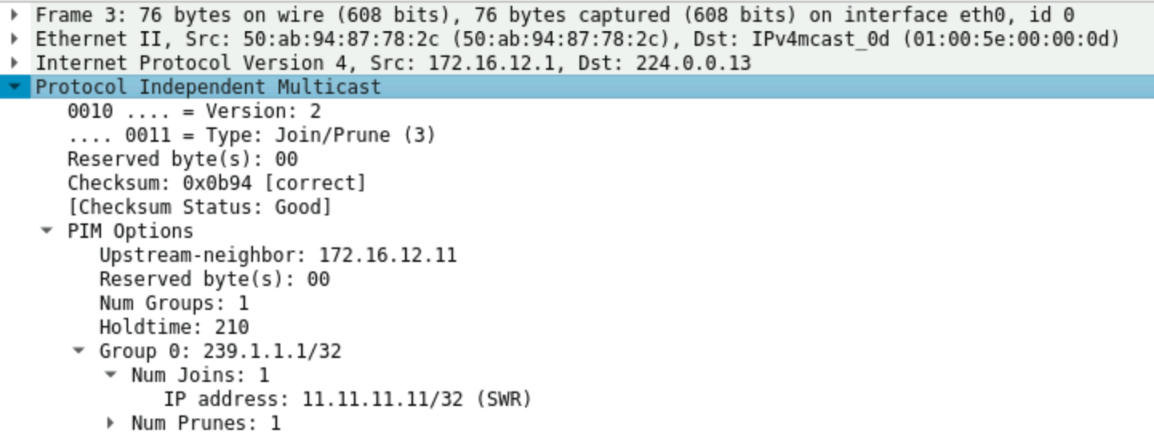
Bây giờ, khi Leaf nhận được BUM traffic (Broadcast, Unknown Unicast, Multicast) từ VM1, nó không cần biết Remote LEAF của nó gồm những ai mà nó chỉ cần đóng gói bản tin đó với VNI 10001 rồi gửi cho RP và nói rằng: "Tôi muốn phát lưu lượng này cho Group Multicast 239.1.1.1" . RP sẽ phân phối lưu lượng này tới tất cả các nhánh của cây Multicast 239.1.1.1, nhánh của cây chính là các Downlink Interface mà nối tới Leaf2 và Leaf3. Các LEAF khác muốn nhận lưu lượng của VNI 10001 như Leaf 4 … hay Leaf N chỉ cần gửi PIM join cho RP là sẽ nhận được Data từ Leaf1.
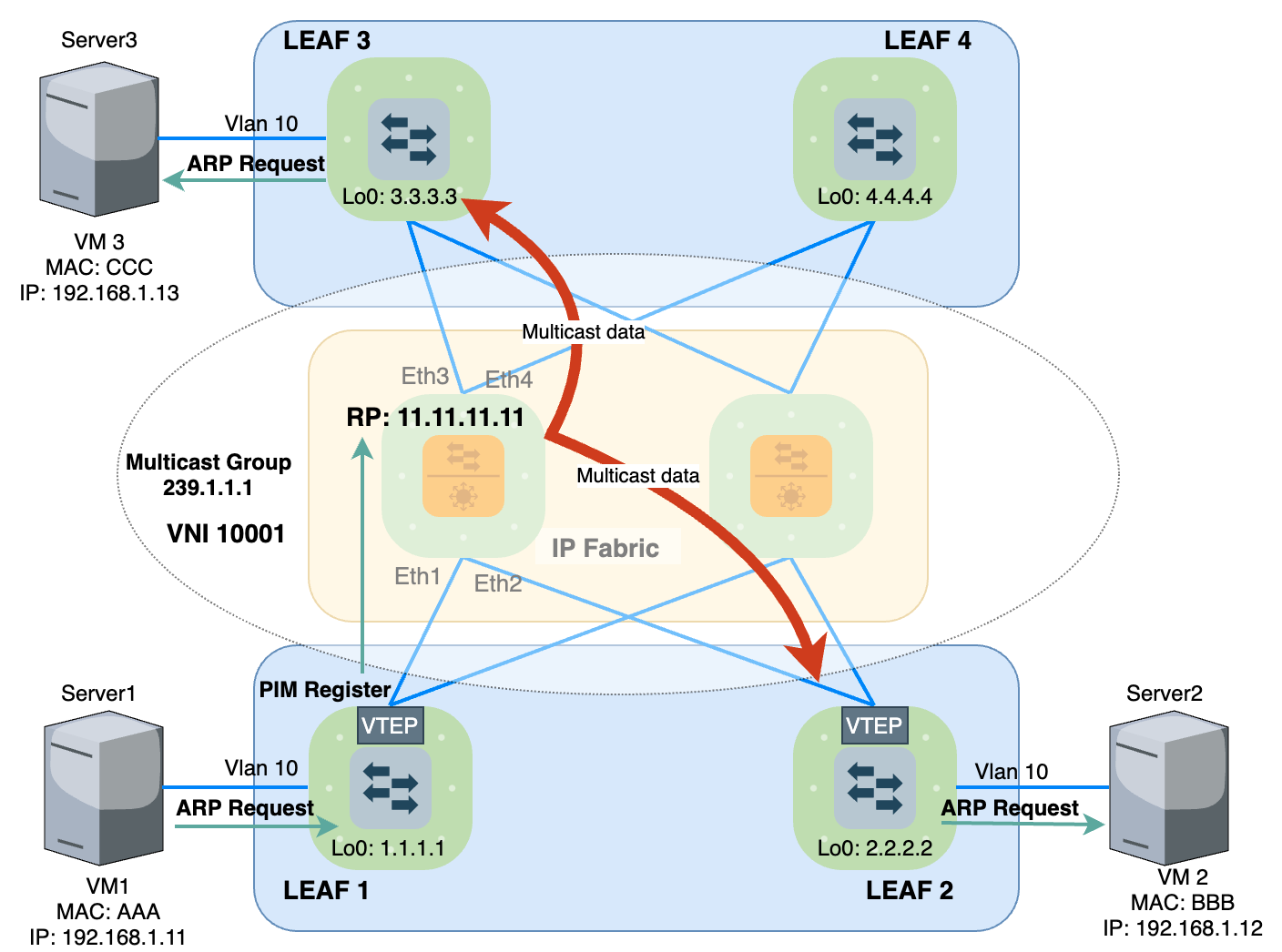
Để gửi được BUM traffic cho RP, theo cơ chế của PIM, nó sẽ phải đóng gói Data vào bản tin PIM Register để thực hiện đăng ký làm nguồn phát cho lưu lượng đó rồi mới gửi tới RP.
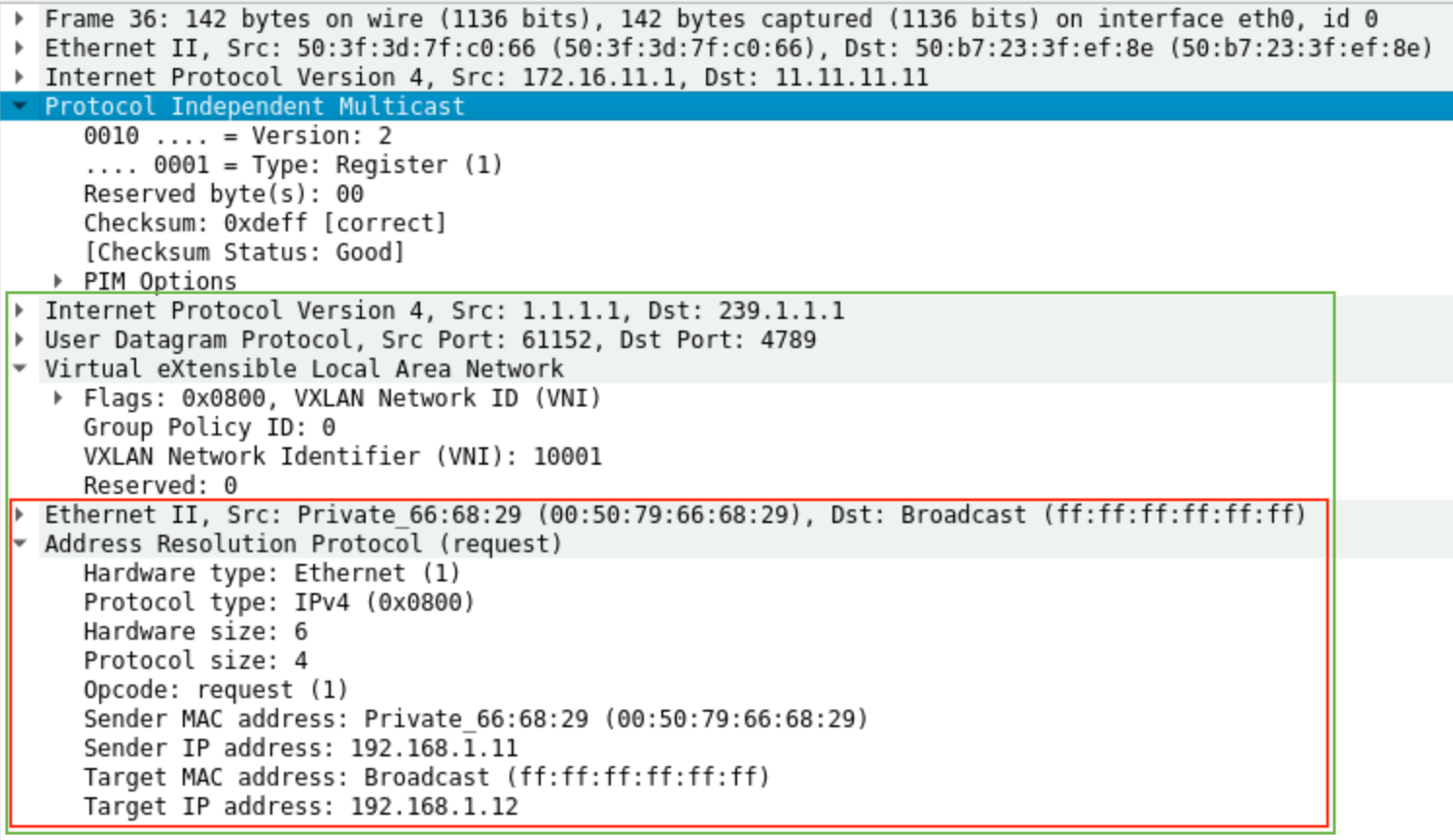
Ở Hình 16, khung màu đỏ là bản tin ARP request chính là BUM traffic được gửi từ VM1 để hỏi về MAC của VM2. Leaf1 nhận được, nó đóng gói bản tin này với VNI 10001 và UDP Port 4789 để thành VXLAN Data Frame hoàn chỉnh. Tiếp theo, Leaf1 đóng gói tiếp Data này vào PIM Register rồi gửi cho RP ở đây là Spine1.
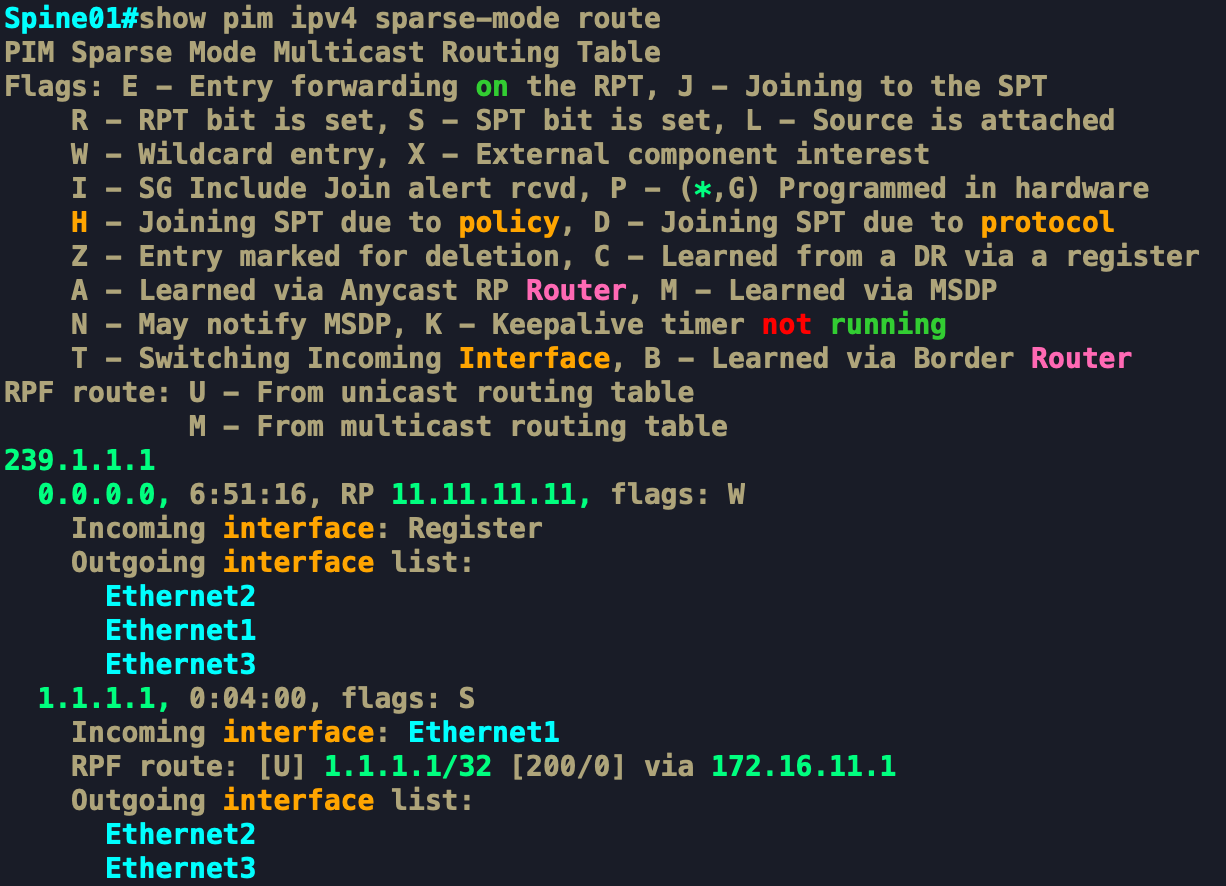
Thực hiện show cây Multicast ở trên RP. Sau khi nó nhận được PIM Register từ Leaf1 (1.1.1.1) ở Interface Ethernet1, nó sẽ đẩy Multicast Data tới các nhánh của cây 239.1.1.1 (Chính là các cổng mà nó nhận được được bản tin PIM join) gồm cổng Ethernet2 và Ethernet3.
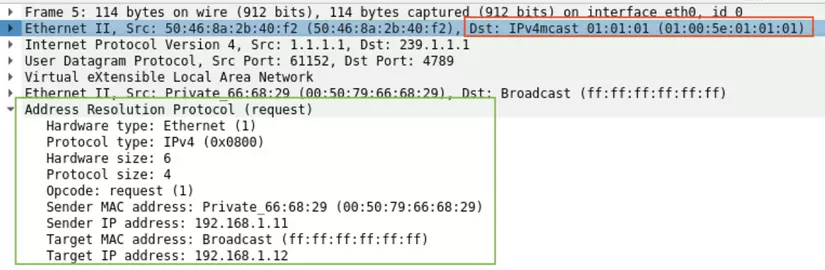
Ta có thể thấy ở khung màu đỏ trong hình, Spine sẽ chuyển tiếp Data này xuống cho các Leaf nhưng địa chỉ MAC đích là 01:00:5e:01:01:01, đây là địa chỉ MAC tương ứng của group Multicast 239.1.1.1.
Leaf2 và Leaf3 sau khi nhận được Data từ RP đổ xuống, nó Mapping VNI 10001 với VLAN 10, gỡ VXLAN Header và Forward xuống VLAN 10 ở Downlink. Lúc này VM2 và VM3 đã nhận được ARP Request xuất phát từ VM1.
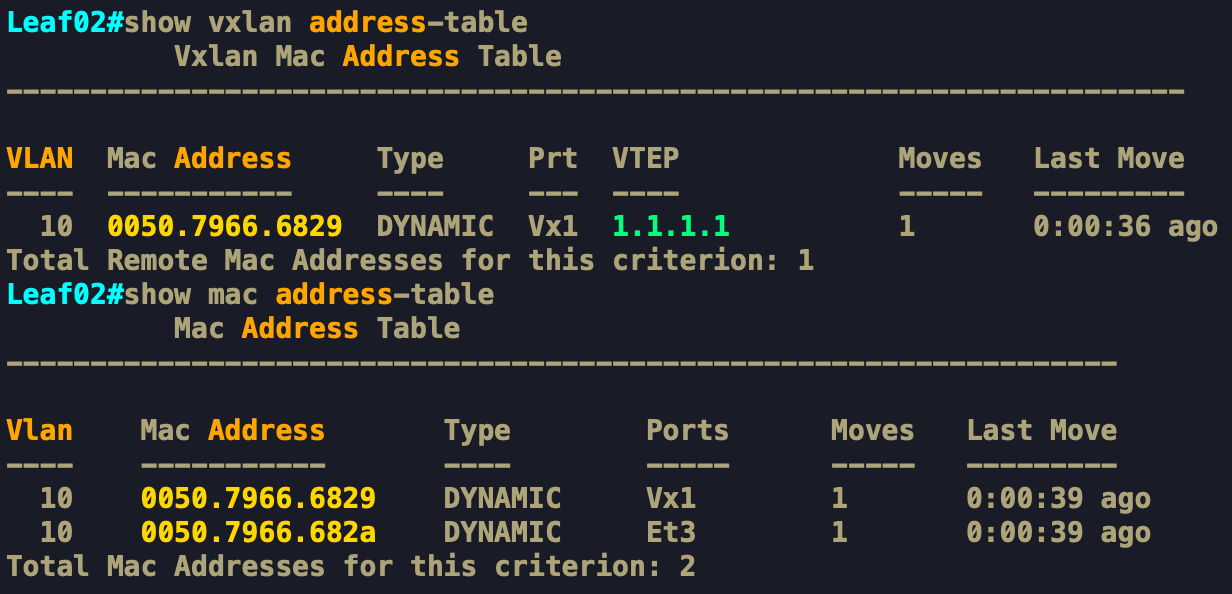
Cũng như cơ chế học MAC của Switch truyền thống, Leaf2 lúc này cũng "Tiện tay" học luôn MAC của VM1 thông qua VXLAN Tunnel 1. Ở đây, 00:50:79:66:68:29 là MAC của VM1 (được biểu diễn là AAA trên hình), được học qua VXLAN Tunnel 1 và từ LEAF1(1.1.1.1), còn 00:50:79:66:68:2a (được biểu diễn là BBB trên hình) là MAC của VM2, được kết nối trực tiếp với Leaf2 nên được học qua cổng Downlink xuống LAN là Ethernet3.
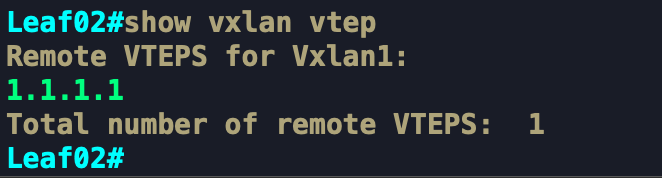
Lúc này Tunnel VXLAN 1 của Leaf2 đã có Peer là LEAF1(1.1.1.1). Tương tự trên Leaf3 cũng sẽ show được thông tin như trên. Bản chất, gói tin ARP Request từ VM1 được gửi qua VNI 10001 được coi là Data của Data Plane, Các Leaf2 và Leaf3 tận dụng Data này để học MAC luôn. Chính vì thế cho nên mình mới nói đây là cơ chế Signaling qua Data Plane chứ không phải Control Plane.

Tiếp theo, khi VM3 nhận được bản tin ARP Request hỏi về MAC của VM2, nó sẽ Drop và không hành xử gì cả. Nhưng khi tới VM2, đây là gói tin nó phải trả lời. Lúc này, vì đã có MAC của VM1 rồi, cho nên nó gửi Unicast ARP Reply tới VM1 được luôn.
Như đã nói ở trên, Leaf2 đã tiện học luôn được MAC của VM1 qua Leaf1. Nên với ARP Reply từ VM2 phản hồi về cho VM1 thì Leaf2 đã biết được phải đóng gói với VNI 10001 và Outer Destination IP là 1.1.1.1 rồi gửi được luôn mà không cần qua PIM nữa.
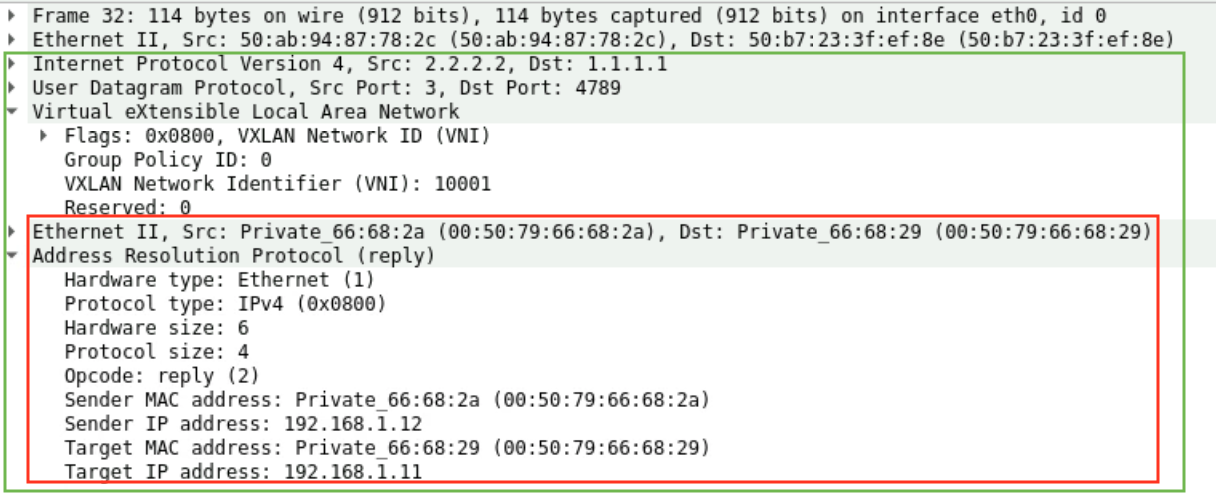
Vì đã biết MAC đích, Leaf2 gửi trực tiếp VXLAN Data tới Leaf1 với IP đích là 1.1.1.1 trên IP Fabric Underlay mà không cần thực hiện PIM Register như gói tin ARP Request lúc ban đầu nữa.
Leaf1 tương tự sẽ gỡ VXLAN Header, mapping vào VLAN 10 và gửi tới VM1. Nhận được ARP Reply, VM1 đã có đầy đủ thông tin MAC đích, quá trình để học MAC đã hoàn thành nhờ có PIM. Lúc này, Data của dịch vụ thực tế đã bắt đầu có thể truyền từ VM1 tới VM2. Các Leaf sẽ đóng gói Data bằng VNI tương tự như các bước bên trên.
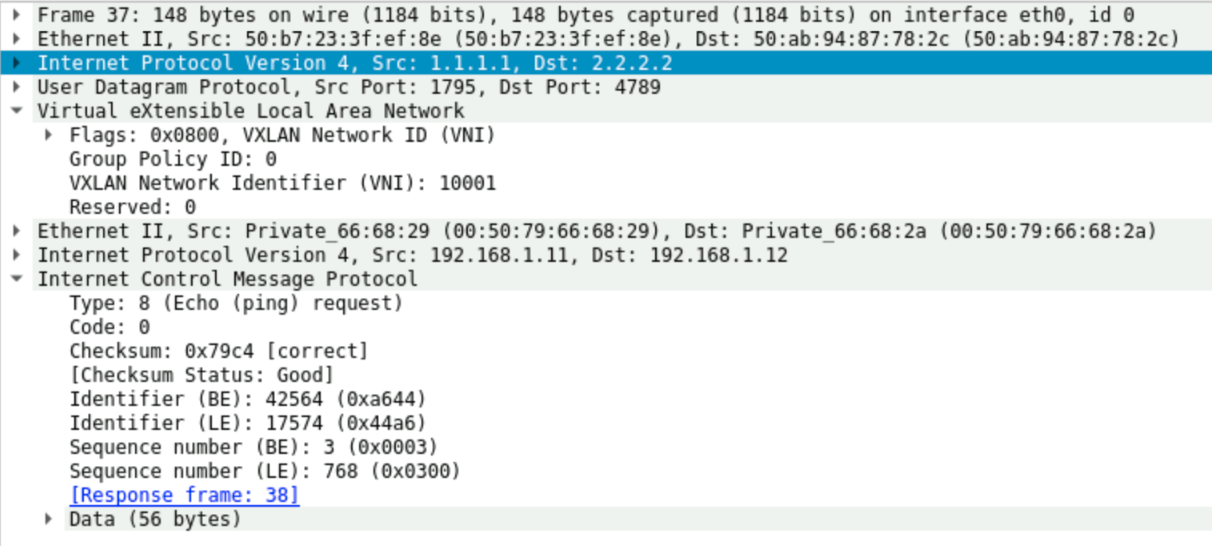
Hình 23 thể hiện Data thực tế được Capture của 1 gói tin Ping Request được đóng gói bằng VXLAN.
Có thể thấy, trường hợp các VM được remove khỏi Leaf, thì các Leaf đầu xa không có cách nào biết rằng MAC này nên xoá khỏi Mac-Table vì thiếu đi các loại bản tin quảng bá chuyên biệt để cả thông báo hoặc thu hồi lại những địa chỉ đã quảng bá cho nhau. Khiến cơ chế này không thật sự hiệu quả trong việc Signaling.
Có thể thấy bất kì giao thức nào cũng thế chứ không phải nguyên VXLAN, nếu chỉ để Data Plane thực hiện Encapsulation và De-Encapsulation Data khi đã biết đầy đủ thông tin nguồn/đích thì rất đơn giản, nhưng làm sao để các thiết bị trong mạng biết được các thông tin đó thì phức tạp hơn nhiều. Cho nên cơ chế Signaling chính là nội dung chính của bài viết này. Sau đây mình sẽ nói về cơ chế Signaling tiêu biểu và tốt nhất hiện nay dành cho VXLAN là MP-BGP EVPN.
All rights reserved
