Vì sao OCR tiếng Việt vẫn là bài toán chưa có lời giải hoàn hảo?
OCR đã phát triển rất mạnh trong những năm gần đây. Nhiều mô hình có thể đạt độ chính xác rất cao trên các benchmark quốc tế và xử lý tốt tài liệu tiếng Anh. Nhưng khi bước vào các bài toán thực tế tại Việt Nam, câu chuyện thường phức tạp hơn nhiều.
Các hệ thống OCR phải xử lý:
- Hóa đơn VAT với hàng trăm biến thể layout khác nhau
- Chứng từ ngân hàng
- Hồ sơ khách hàng scan từ nhiều nguồn
- Tài liệu hành chính
- Biểu mẫu doanh nghiệp
- Tài liệu chất lượng thấp hoặc được chụp bằng điện thoại
Với tiếng Việt, thách thức không chỉ nằm ở dấu thanh hay ký tự có dấu. Hệ thống còn phải xử lý hóa đơn nhiệt bị mờ, tài liệu scan nhiều nhiễu, biểu mẫu nhiều cột, bảng biểu phức tạp và các cách trình bày không đồng nhất giữa các doanh nghiệp.
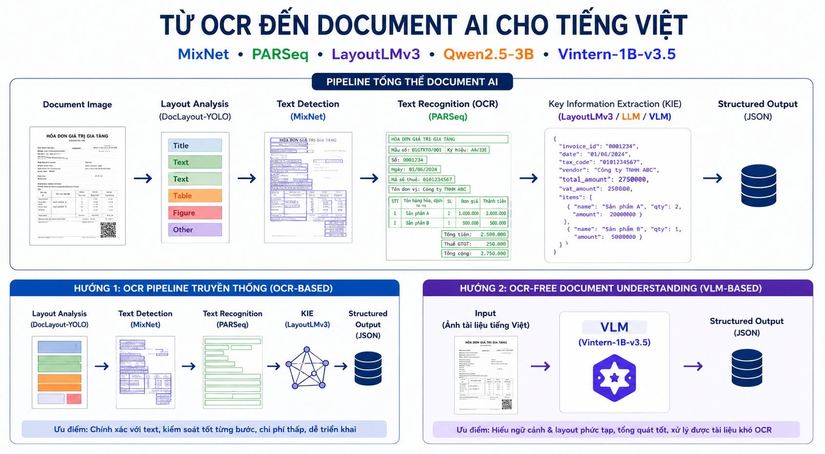
Trong thực tế, chỉ một lỗi OCR nhỏ cũng có thể ảnh hưởng đến toàn bộ pipeline phía sau.
Ví dụ: "Tổng tiền" → "Tổng tiến" hay "Mã số thuế" → "Mã số thuề" có thể khiến hệ thống trích xuất sai dữ liệu, làm giảm độ chính xác của toàn bộ quy trình xử lý tài liệu. Tuy nhiên, trong các hệ thống Document AI hiện đại, bài toán không còn dừng lại ở việc đọc đúng từng ký tự. Điều doanh nghiệp thực sự cần là khả năng hiểu nội dung tài liệu và trích xuất đúng thông tin phục vụ cho các quy trình nghiệp vụ. Đó là lý do trong những năm gần đây, Vision-Language Model (VLM) nổi lên như một hướng tiếp cận mới bên cạnh OCR pipeline truyền thống, đặc biệt với các bài toán tài liệu có cấu trúc phức tạp hoặc layout thay đổi liên tục. Thay vì chỉ nhận dạng văn bản, VLM có thể quan sát toàn bộ tài liệu, hiểu bố cục, ngữ cảnh và sinh ra kết quả dưới dạng dữ liệu có cấu trúc. Trong khóa học, học viên sẽ làm việc với Vintern-1B-v3.5 — một Vision-Language Model được tối ưu cho tiếng Việt — để xây dựng OCR-free Key Information Extraction pipeline và so sánh trực tiếp với các cách tiếp cận truyền thống như LayoutLMv3 hoặc Qwen2.5-3B.
Điều này giúp mô hình có lợi thế đáng kể khi xử lý:
- Hóa đơn tiếng Việt
- Chứng từ doanh nghiệp Việt Nam
- Biểu mẫu nội địa
- Các cách diễn đạt và thuật ngữ đặc thù trong tiếng Việt
📌 Trong khóa học, học viên sẽ trực tiếp:
- Xây dựng OCR pipeline hoàn chỉnh với MixNet → PARSeq → LayoutLMv3
- Đánh giá khả năng zero-shot của Vintern-1B-v3.5 trên bài toán Key Information Extraction
- Fine-tune Vintern bằng QLoRA trên dataset SROIE
- So sánh hai hướng tiếp cận:
- OCR-based Pipeline (LayoutLMv3)
- Vision-Language Model Pipeline (Vintern-1B-v3.5)
- Đánh giá F1 Score, Exact Match, Hallucination Rate và Latency
- Phân tích các trường hợp mà OCR pipeline thất bại nhưng VLM vẫn xử lý được
Một trong những câu hỏi quan trọng nhất trong doanh nghiệp hiện nay là: "Liệu Vision-Language Model có thể thay thế hoàn toàn OCR hay không?" Câu trả lời thường không đơn giản là có hoặc không.
OCR pipeline vẫn có lợi thế về chi phí, tốc độ và khả năng mở rộng. Trong khi đó, các mô hình như Vintern lại cho thấy tiềm năng rất lớn trong các bài toán tài liệu tiếng Việt có cấu trúc phức tạp hoặc nhiều biến thể layout. Mục tiêu của phần học này không phải là chạy theo một mô hình mới hay đạt thêm vài điểm F1 Score trên benchmark. Quan trọng hơn, học viên sẽ hiểu khi nào nên sử dụng OCR pipeline truyền thống, khi nào nên sử dụng Vision-Language Model và cách đánh giá các trade-off về độ chính xác, chi phí hạ tầng, latency và khả năng mở rộng trong môi trường doanh nghiệp thực tế.
Nếu bạn muốn tìm hiểu cách xây dựng các hệ thống Document AI dành cho tiếng Việt từ OCR pipeline đến Vision-Language Model, có thể đăng ký tại: Nhận Miễn Phí
All rights reserved
