Tutorial - Triển khai Cluster RabbitMQ - High Availability
Bài đăng này đã không được cập nhật trong 5 năm
- Mình vừa trải qua một khoảng thời gian dài kha khá, để nghiên cứu và dựng lab về việc xây dựng rabbitmq cluster. Dưới đây là toàn bộ "nhật ký" mình note lại.
1. Lời giới thiệu
- Bài viết mình sẽ không viết lại các khái niệm cơ bản.
- Bài viết này mình nghĩ có lẽ hợp với:
- Ai muốn tìm hiểu nhanh việc xây dựng cluster rabbitmq, để nắm được overview, trước khi muốn nghiên cứu (hoặc cấu hình) sâu hơn.
- Hiểu tư tưởng, các vấn đề của vận hành 1 cluster Message Queue nói chung. Mà mình nghĩ có thể trở thành background để tiếp cận với 1 hệ thống khác.
- Kiến thức nền để hiểu bài viết:
- Một chút về Rabbitmq
- Một chút về Docker
- Một chút về Networking
- Các thông tin có trong bài viết:
- Một chút lý thuyết về Quorum Queue trong RabbitMQ
- Lý do ra đời
- So sánh với Mirror Queue (support ở version cũ)
- Dựng hệ thống cluster
- Sơ đồ thiết kế
- Step by step triển khai
- Lab một số kịch bản khi cluster gặp sự cố
- Có node bị down/ và reUp
- Network Partitions - Split Brain
- Một chút lý thuyết về Quorum Queue trong RabbitMQ
2. Quorum Queue
2.1 Một vài ý chính
- Rabbitmq từ version 3.8.0 trở đi, có 1 thay đổi lớn về các feature support. Trong đó đặc biệt có Quorum Queue. Cái ra đời để giải quyết các vấn đề của Mirror Queue trong các version trước đó gặp phải. (Quorum Queue là 1 "type",
không liên quangì tới Exchange Type: Direct, Topic, Fangout ) - Khi tạo Quorum Queue, sẽ không có lựa chọn
Durabilitynhư Classic Queue. (khi node bị lỗi, hoặc sự cố khởi động lại thìqueuesẽ được "load" lại khi startup, nếunon-durablethì sẽ bị mất) - Khi sử dụng Quorum Queue sẽ không phải upgrade client. => tương thích ngược. Việc setup Quorum Queue nằm ở các node server. Client không tham gia.
- Khi 1 node fail, xong quay lại, thì nó chỉ đồng bộ các message mới. Mà ko phải sync lại từ đầu. Và quá trình sync các message mới này không bị blockking.
- Nếu broker bị lỗi gì đó làm mất dữ liệu, thì toàn bộ messge trên broker đó sẽ mất vĩnh viễn. Khi broker đó online trở lại, thì không thể đồng bộ lại data từ leader từ đầu.
- Khi xây dựng cluster để triển khai Quorum Queue, các định nghĩa như 1 node master, các node khác slave hay replicates sẽ không còn đúng nữa.
2.2 So sánh Quorum Queue vs Mirror Queue
- Mirror Queue => Mình nghĩ là nó đã Depreciation (quan điểm chủ quan). Tiền thân là Replicated queue
- Quorum queue dữ message mãi mãi trên disk. Còn Mirror Queue, thì với các lựa chọn Durable Queue và Persistent Message sẽ có các cách tính khác nhau:
- Non-durable Queue + Non-Persistent message = mất Queue + mất Message (sau khi Broker restart)
- Durable queue + Non-Persistent message = Còn Queue + mất Message
- Durable queue + Persistent message = Còn Queue + Còn Message
- Mirrored queue + Persistent message = Còn Queue + Còn Message\
- Khi có 1 node lỗi, và sau đó quay trở lại bình thường. Với Mirror Queue, sẽ block cả cluster. Vì nó cần đồng bộ lại toàn bộ message trong khoảng thời gian sự cố. Ngược lại với Quorum Queue thì nó không block. Nó chỉ đồng bộ các message mới.
- Khi gặp sự cố Network Partition. (mạng các node không kết nối được với nhau). Với Mirror Queue sẽ xảy ra tình huống
split-brain. (1 queue/cluster > 1 master). Với Quorum Queue, cung cấp các policyautoheal,pause_minority,pause_if_all_down, để người quản trị tự cấu hình hướng xử lý. - Với Mirror Queue, node master sẽ nhận tất cả các request đọc/ghi. Các node mirror sẽ nhận tất cả message từ node master và ghi vào disk. Các node mirror không có nhiệm vụ giảm tải "read"/"write" cho node master. Nó chỉ mirror message để phụ vụ việc HA. Với Quorum Queue, Queue A có thể master trên Node 1. Nhưng Queue B có thể master trên Node 1.
3. Xây dựng hệ thống cluster rabbitmq
3.1 Sơ đồ thiết kế
- Viết sơ đồ nghe lớn lao, chứ đơn giản thôi:
- Mình sử dụng 3 node. (nên lựa chọn là số lẻ. Để thuận lợi cho giải thuật bầu leader)
- 3 node này mình cài cụm Docker Swarm, với leader là Node 1. Và sử dụng
docker stackđể triển khai cluster. (Bạn hoàn toàn có thể không sử dụng Docker Swarm, mà chỉ dùng mỗi Docker container thường cũng được. Ở các bước step-by-step mình sẽ giải thích chi tiết để bạn có thể tùy chỉnh). - Nên set up số node (broker) là số lẻ. Ví dụ 3,5,7 để thuận lợi cho giải thuật bầu leader
- Môi trường triển khai:
- Các node chạy Ubuntu Server 18.04
- Các node cài Docker
- Node1 chạy rabbitMq, có hostname container là
rabbitmq1. Tương tự với node2, node3 làrabbitmq2,rabbitmq3.
3.2 Step by step
1). Chuẩn bị
- Mình lab sử dụng 3 instance AWS EC2. (cho mạng khỏe, máy nhanh, đỡ phải đợi chờ). Bạn thay thế bằng máy chủ nào cũng được, dùng docker-machine, hay ảo hóa vmware cũng được. Không quan trọng lắm. Miễn 3 node thông mạng nhau, và có internet để download là được.
- Thông tin hostname (ở bước triển khai docker-stack cần dùng).
- Node1 = ip-172-31-11-205
- Node2 = ip-172-31-3-230
- Node3 = ip-172-31-1-3
- (Lấy thông tin này bằng cách ssh vào server và gõ command
hostname.)
- Thông tin hostname (ở bước triển khai docker-stack cần dùng).
- Cài Docker Engineer
- Google cách cài hoặc run script mình viết này cho nhanh cũng được
wget -O - https://raw.githubusercontent.com/tungtv202/MyNote/master/Docker/docker_install.sh | bash - Cài cụm Docker Swarm trên 3 node.
- Lựa chọn node1 làm leader.
docker swarm init --advertise-addr=172.31.11.205- Node2 và Node3 join cluster
docker swarm join --token SWMTKN-1-5xv7z2ijle1dhivalkl5cnwhoadp6h8ae0p7bs5tmanvkpbi3l-5ib6sjrd3w0wdhfsnt8ga7ybd 172.31.11.205:2377- Kết quả

- Chi tiết hơn có thể tham khảo bài hướng dẫn của thầy xuanthulab.net
2). Dockerfile
-
Dockerfile
FROM rabbitmq:3-management COPY rabbitmq-qq.conf /etc/rabbitmq/rabbitmq.conf COPY rabbitmq-qq-definitions.json /etc/rabbitmq/rabbitmq-definitions.json #ENV RABBITMQ_CONF_ENV_FILE /etc/rabbitmq/rabbitmq-env.conf ENV RABBITMQ_ERLANG_COOKIE cookieSecret #RUN apt-get update && apt-get install -y iputils-ping && apt-get install -y telnet && apt-get install -y nano- Lưu ý biến môi trường
RABBITMQ_ERLANG_COOKIErất quan trọng. Các node rabbitmq muốn giao tiếp được với nhau thì giá trị cookie này cần phải giống nhau thì mới có thểauthenđược. (Nếu không set giá trị này, thì giá trịerlang.cookiesẽ được sinh ngẫu nhiên, và khác nhau trên mỗi node). Thông tin các biến môi trường khác mà rabbitmq hỗ trợ, tham khảo tại https://www.rabbitmq.com/configure.html#customise-environment
- Lưu ý biến môi trường
-
File cấu hình
rabbitmq-qq.confloopback_users.guest = false listeners.tcp.default = 5672 management.listener.port = 15672 management.listener.ssl = false vm_memory_high_watermark.absolute = 1536MB cluster_name = rabbitmq-qq cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config cluster_formation.classic_config.nodes.1 = rabbit@rabbitmq1 cluster_formation.classic_config.nodes.2 = rabbit@rabbitmq2 cluster_formation.classic_config.nodes.3 = rabbit@rabbitmq3 management.load_definitions = /etc/rabbitmq/rabbitmq-definitions.json # background_gc_enabled = true # Increase the 5s default so that we are below Prometheus' scrape interval, # but still refresh in time for Prometheus scrape # This is linked to Prometheus scrape interval & range used with rate() collect_statistics_interval = 10000 # Enable debugging log.file = rabbit.log log.dir = /var/log/rabbitmq log.console.level = info cluster_partition_handling = pause_minoritylisteners.tcp.default=5672. port để client kết nối vào broker. Mặc định port này là 5672. Có thể đổi sang port khác nếu conflictmanagement.listener.port = 15672. port để vào webadmin gui- Có 1 port là
epmdmình không để trong file config. Mặc định port này là4369. Port này rất quan trọng, các node dùng port này đểdiscoverynhau. Bắt buộc số port phải là giống nhau trên các node - Thông tin các port có thể tham khảo thêm tại https://www.rabbitmq.com/networking.html#ports
rabbitmq1,rabbitmq2,rabbitmq3lần lượt là hostname của 3 node. (Lưu ý 3 hostname này khác với hostname của instance ec2, mình viết bên trên). Mặc định rabbitmq không hỗ trợ FQDN. Muốn dùng hostname dài. thì cần set envRABBITMQ_USE_LONGNAME =true. Chi tiết hơn https://www.rabbitmq.com/clustering.html#node-namescluster_partition_handling=pause_minority: khi có sự cố networking partition, rabbitmq cung cấp 3 policy để handler, làpause-minority,pause-if-all-down,autoheal. Nếu bạn không khai báo cấu hình này thì mặc định nó sẽignore, không làm gì cả. Sau khi mình tham khảo thì thấypause-minoritycó lẽ mình sẽ dùng nhiều nhất. Với mode này thì bên phía các node có số lượng ít hơn, sẽ bịdownluôn. Các message, queue sẽ được gửi về bên phía có số lượng node nhiều hơn. Thông tin về vấn đề này mình sẽ viết chi tiết hơn bên dưới. Có thể tham khảo https://www.rabbitmq.com/partitions.html
-
File
rabbitmq-qq-definitions.json{ "global_parameters": [ {"name": "cluster_name", "value": "rabbitmq-qq"} ], "permissions": [ { "configure": ".*", "read": ".*", "user": "tungtv", "vhost": "/", "write": ".*" } ], "users": [ { "name": "tungtv", "password": "tungtv", "tags": "administrator" } ], "vhosts": [{"name": "/"}] }- File này mình chỉ để define account đăng nhập
- Bạn có thể khai báo file này để
declarecác queue, và nhiều hơn nữa.
-
Có thể build docker image bằng command
docker build -t rabbitmq_ha_qq -f Dockerfile .
- Hoặc có thể dùng trực tiếp docker image mà mình đã build sẵn, và public tại https://hub.docker.com/repository/docker/tungtv202/rabbitmq_ha_qq
3). Docker stack file
-
docker-compose.yml file
version: '3.7' volumes: rabbitmq_volume: services: rabbitmq1: image: tungtv202/rabbitmq_ha_qq ports: - "5672:5672" - "15672:15672" hostname: rabbitmq1 volumes: - rabbitmq_volume:/var/lib/rabbitmq deploy: replicas: 1 placement: constraints: - node.hostname == ip-172-31-11-205 resources: limits: cpus: '1' memory: '500MB' reservations: cpus: '0.5' memory: '50MB' restart_policy: condition: on-failure rabbitmq2: image: tungtv202/rabbitmq_ha_qq ports: - "5677:5672" - "15677:15672" hostname: rabbitmq2 volumes: - rabbitmq_volume:/var/lib/rabbitmq deploy: replicas: 1 placement: constraints: - node.hostname == ip-172-31-3-230 resources: limits: cpus: '1' memory: '500MB' reservations: cpus: '0.5' memory: '50MB' restart_policy: condition: on-failure rabbitmq3: image: tungtv202/rabbitmq_ha_qq ports: - "5666:5672" - "15666:15672" hostname: rabbitmq3 volumes: - rabbitmq_volume:/var/lib/rabbitmq deploy: replicas: 1 placement: constraints: - node.hostname == ip-172-31-1-3 resources: limits: cpus: '1' memory: 500MB reservations: cpus: '0.5' memory: 50MB restart_policy: condition: on-failureimage: tungtv202/rabbitmq_ha_qq: docker image mà mình đã build sẵnrabbitmq_volume: tạo volume để persistent data. (trường hợp bạn lab bị lỗi gì đó, thì nên xóa volume đi, rồi tạo lại volume mới)- ports: route thêm port nếu cần thêm public port nào đó khác
replicas: 1: chỉ cần 1 container trên mỗi node là đủ.- Sử dụng
constraints.constraintsđể chỉ định các container được deploy trải đều trên 3 node riêng biệt. Thông tin hostname ở đây chính là hostname EC2, mình remind bên trên. - Vì mình sử dụng docker-swarm triển khai, nên khi chung 1 network, các container sẽ tự hiểu các hostname của nhau. (rabbitmq1, rabbitmq2, rabbitmq3). Trường hợp bạn không sử dụng docker swarm, có thể sửa file trên thành file docker compose. Và thêm thông tin
extra_hosts: - rabbitmq1:172.31.11.205 - rabbitmq2:172.31.3.230 - rabbitmq3:172.31.1.3- Cuối bài mình có share source file config sẵn 3 file
docker-compose.ymlđể chạy độc lập trên 3 instance. Trong trường hợp bạn không sử dụng docker-swarm, docker stack
-
Chạy
docker stackđể triển khai servicedocker stack deploy --compose-file docker-compose.yml rabbitmq
4). Kiểm tra kết quả
-
docker
- node1

- node2

- node3

- node1
-
Web admin
- 172.31.11.205:15672
- 172.31.3.230:15677
- 172.31.1.3:15666
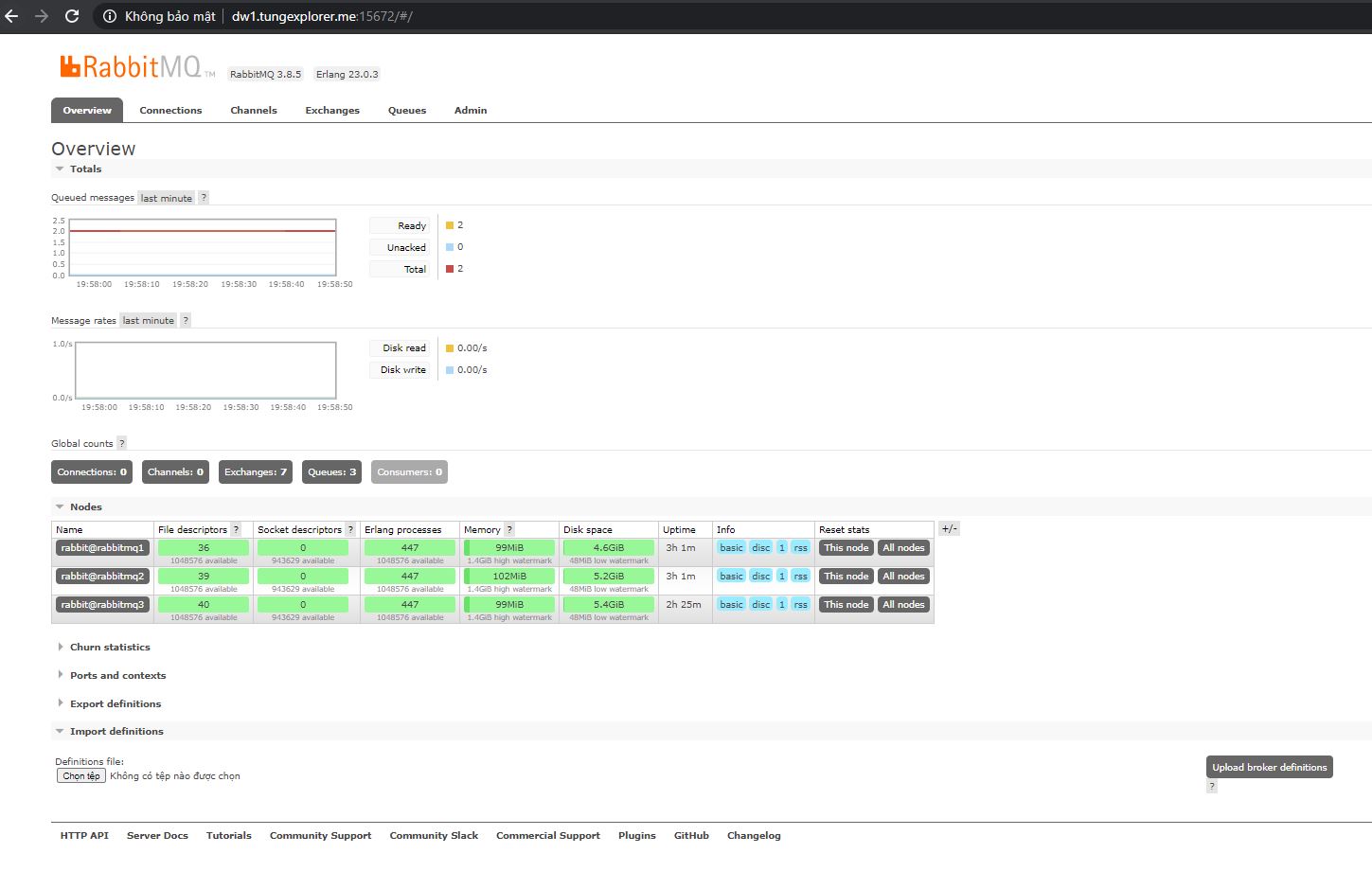
- Thông tin các node trong cluster được show ở tab
Overview
-
Tạo Quorum Queue
- Vào tab Queues để tạo queue, và trải nghiệm bật tắt các node. Để test việc Hight Avalibility của queue
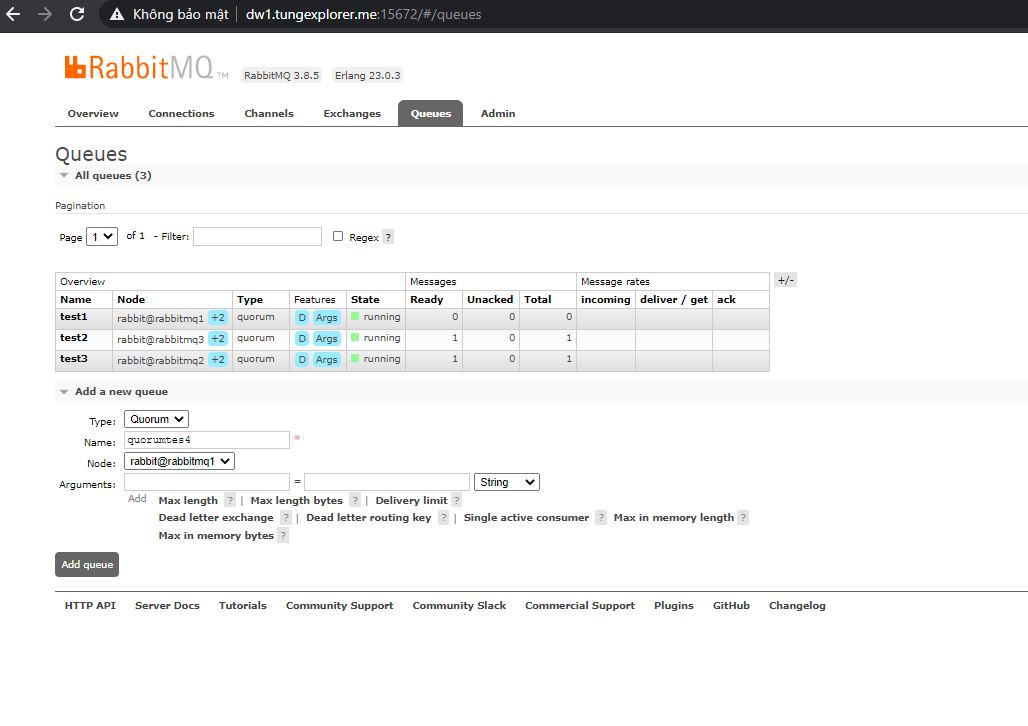
- Lưu ý: chọn bất kỳ 1 node để làm leader cho queue. (không quan trọng, sau này có sự cố tự động cluster sẽ bầu lại leader mới)
- Vào tab Queues để tạo queue, và trải nghiệm bật tắt các node. Để test việc Hight Avalibility của queue
5.) Một vài command để debug lỗi trong quá trình setup
- Check log container
docker logs CONTAINER_ID - Truy cập vào container và sử dụng
rabbitmqctlcli. Tham khảo https://www.rabbitmq.com/rabbitmqctl.8.htmlrabbitmq status epmd -port 4369 -names
3. Lab một số kịch bản
3.1 Có node bị down/ và reUp
- Kịch bản này khá đơn giản, mình thấy không có gì phức tạp. Bạn có thể stop container. Hoặc scale service=0 để test.
- Ví dụ ban đầu Queue A, có node master
rabbit@rabbitmq1, sau đó stop container trên node1. Thì node master được chuyển sang node2, hoặc node3. Và message không bị mất
3.2 Network parttion
-
Kịch bản này có thể tái hiện bằng cách "drop network" giữa node3 vs 2 node còn lại. Mình dùng aws ec2, nên vào sửa Secure Group là được. Hoặc không bạn có thể tạo firewall trên các node. Để chặn, không cho network kết nối.
-
(1) Nếu trong file
rabbitmq-qq.confmình không có cấu hìnhcluster_partition_handling = pause_minoritythì kịch bản sau sẽ diễn ra:-
node3 nghĩ rằng 2 node kia down. Nó tự nó làm leader của cluster đó.
-
cụm node1 + node2, nghĩ rằng node3 down. 2 thằng này tự bầu nhau làm leader.
-
Vấn đề này gọi là
split-brain -
Và khi client tạo queue mới, hoặc ghi message vào queue trên node3. Thì sẽ không có đồng bộ data tương ứng với cụm node1+node2. Và ngược lại.
-
Lúc này cả 2 phe node3, và node1+node2 đều nghĩ rằng bên kia down. Chứ chưa phát hiện ra sự cố
network partition. Chỉ tới khi chúng ta cho thông lại network giữa 3 node với nhau. Lúc này cluster mới phát hiện được. (Rabbitmq viết rằng, họ sử dụng Mnesia database để phát hiện vấn đề này) -
Ảnh chụp webadmin của node1+node2
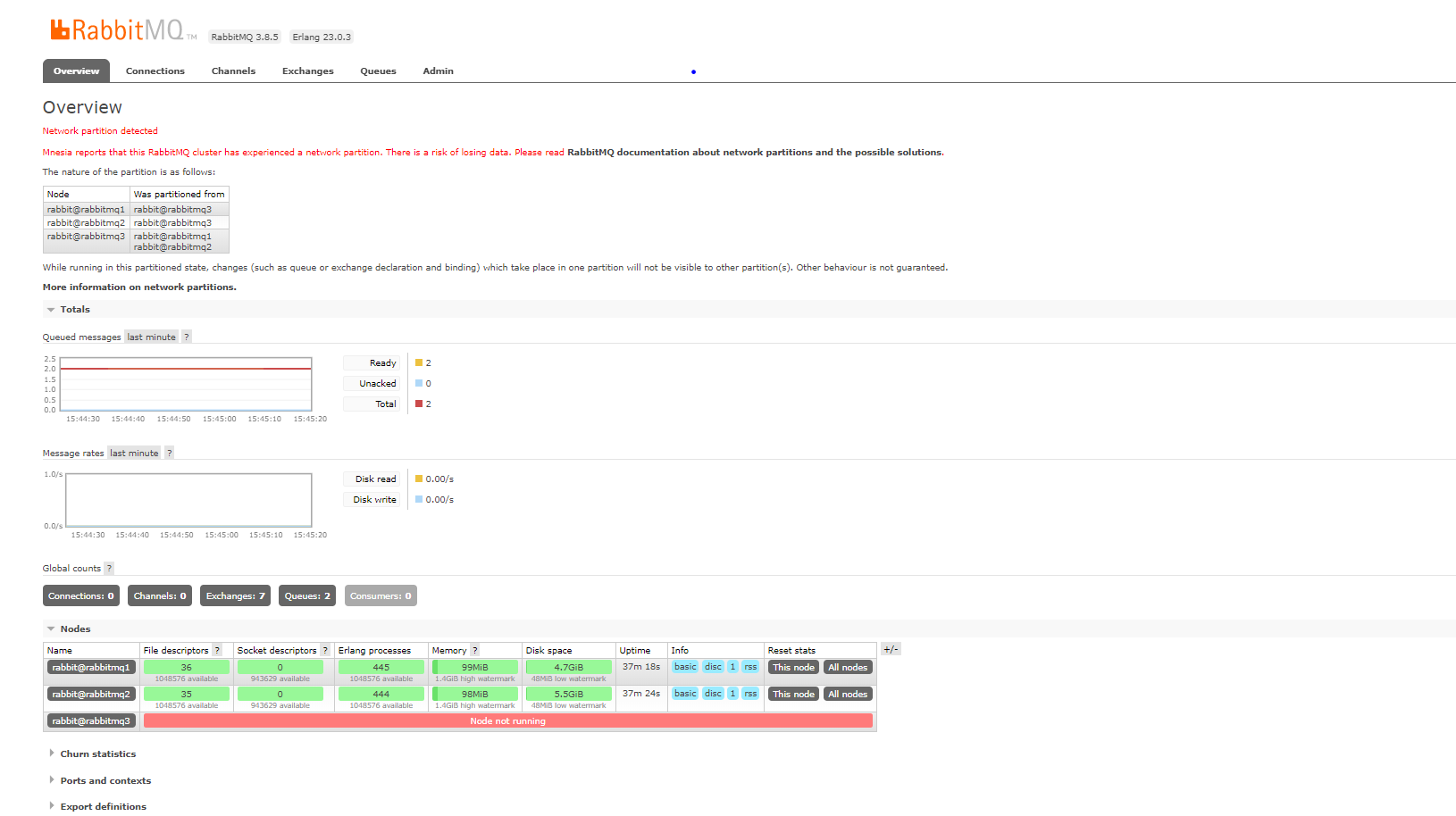
-
Ảnh chụp webadmin của node3
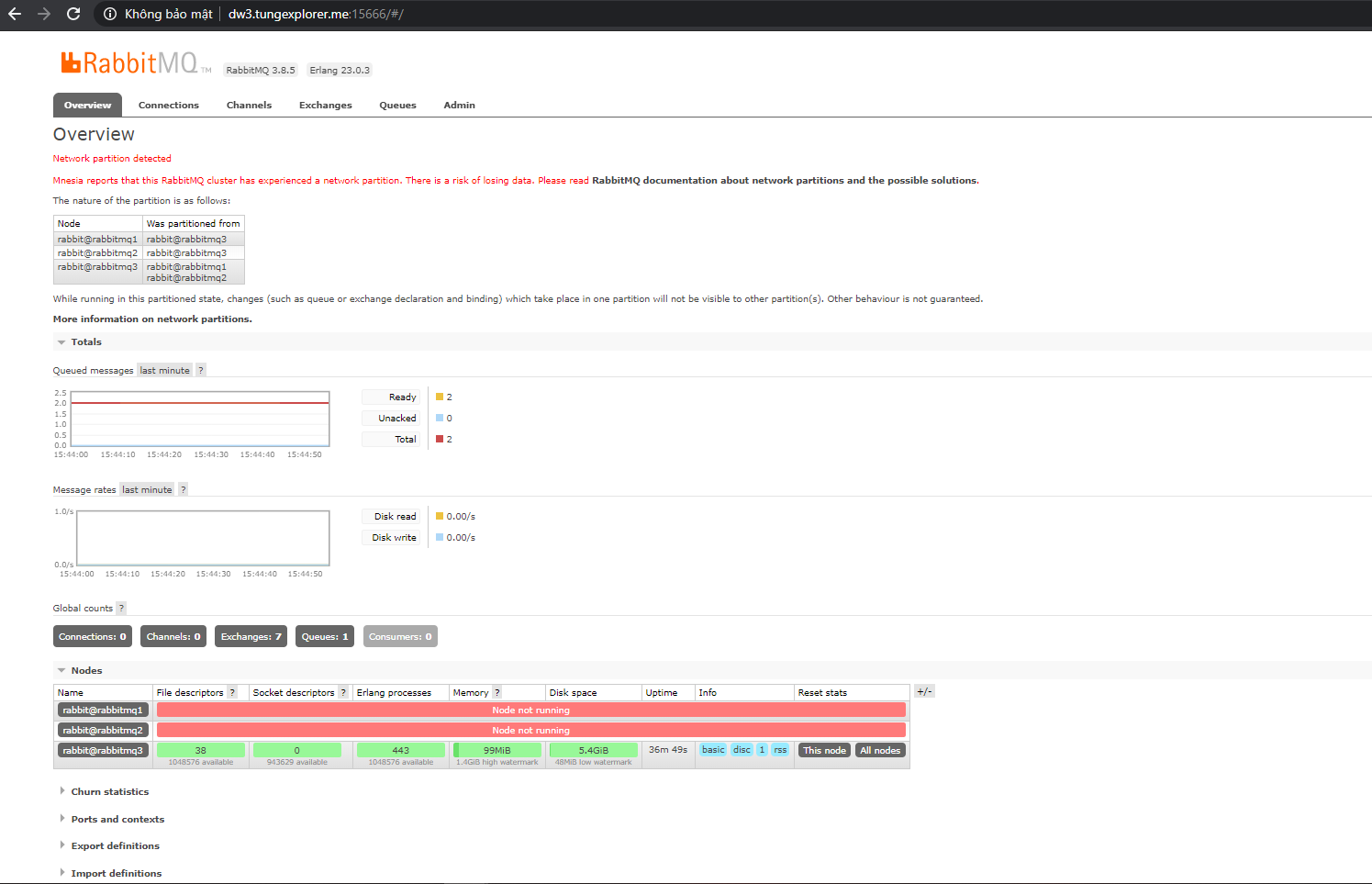
-
Hướng xử lýtrong tình huống này là gì?. Bạn phải chọn 1 bên làm chuẩn. Sau đó restart lại rabbitmq bên còn lại, để rabbbitmq bên còn lại rejoin lại cluster. Và đồng bộ lại message từ bên chuẩn sang. Và chấp nhận việc mất data. Reference https://www.rabbitmq.com/partitions.html#recovering
-
-
(2) Nếu trong file
rabbitmq-qq.confmình CÓ cấu hìnhcluster_partition_handling = pause_minoritythì kịch bản sau sẽ diễn ra:- node3 thấy nó chỉ có mình nó. Cả cluster khai báo 3 node. Vì 1 bé hơn 2. Nên rabbitmq trên node3 cho down luôn. Còn cụm node1+node2 vẫn chạy bình thường. (lưu ý là rabbitmq bị shutdown, chứ container vẫn chạy bình thường. Có thể kiểm tra bằng cách sử dụng
rabbitmqctl) - Lúc này việc route từ client sẽ được chuyển về cụm node1+node2. (Để việc route này diễn ra đọc tiếp phần 4)
- node3 thấy nó chỉ có mình nó. Cả cluster khai báo 3 node. Vì 1 bé hơn 2. Nên rabbitmq trên node3 cho down luôn. Còn cụm node1+node2 vẫn chạy bình thường. (lưu ý là rabbitmq bị shutdown, chứ container vẫn chạy bình thường. Có thể kiểm tra bằng cách sử dụng
4. Setup Nginx
- Khi mình sử dụng java springboot cấu hình rabbitmq client. Mình chỉ cần khai báo danh sách các broker các rabbitmq1, rabbitmq2, rabbitmq3 là được. Và thư viện tự động route cho mình tới broker đang "available".
- Đây là log của application khi có node bị down. Như bạn thấy thì nó ERROR báo shutdown, xong lập tức restart lại để kết nối tới broker khác
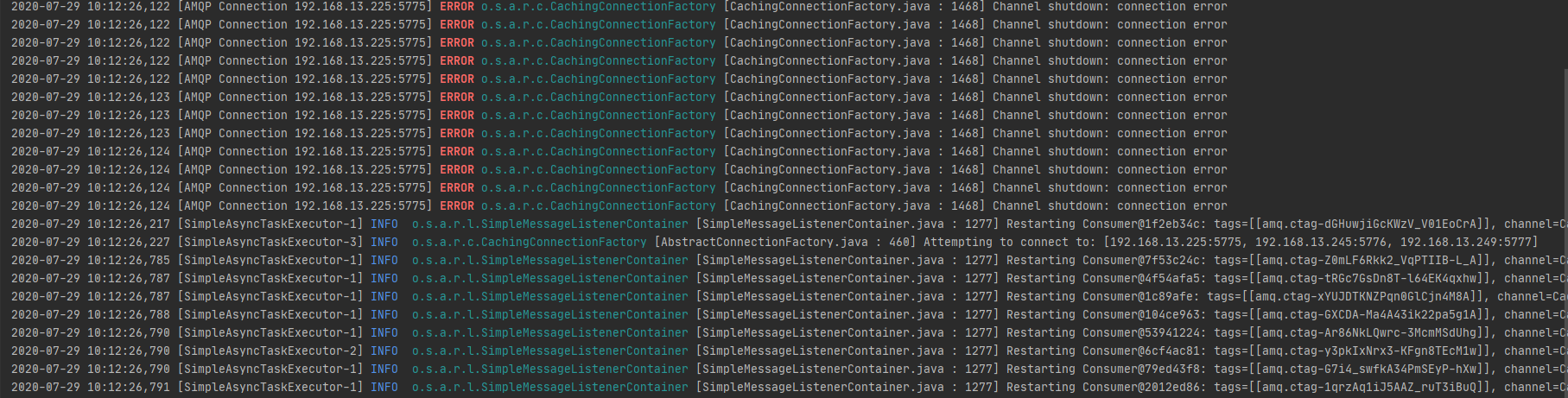
- Nếu sử dụng spring boot cấu hình rabbit, thì rất đơn giản
spring: rabbitmq: addresses: 192.168.1.225:5775,192.168.1.245:5776,192.168.1.249:5777 username: tungtv password: tungtv - Đây là log của application khi có node bị down. Như bạn thấy thì nó ERROR báo shutdown, xong lập tức restart lại để kết nối tới broker khác
- Trường hợp thư viện không hỗ trợ, chúng ta cần 1 endpoint đứng ngoài hứng. Và check trước khi route vào broker đang available.
- Có thể sử dụng nginx. Với cấu hình đơn giản sau
events { } stream { upstream myrabbit { server 172.31.11.205:5672; server 172.31.3.230:5677; server 172.31.1.3:5666; } server { listen 5000; proxy_pass myrabbit; } }
Bonus
(cái này mình chưa lab)
- Cân nhắc khi sử dụng Quorum Queue cho Fanout Exchange. (Vì bộ nhớ để chứa message được nhân lên rất nhiều => tốn resource)
- Mặc định message trên Quorum Queue lưu trên memory/disk mãi mãi. Cần setup giới hạn (và hệ thống 3rd giám sát) để khi tới ngưỡng, rabbitmq release tài nguyên
x-max-in-memory-lengthsets a limit as a number of messages. Must be a non-negative integer.x-max-in-memory-bytessets a limit as the total size of message bodies (payloads), in bytes. Must be a non-negative integer.
- Source code https://github.com/tungtv202/ops_rabbitmq_ha_qq
Implement rabbitmq to Springboot
- Import maven
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
- Tạo quorum queue
@Bean
public RabbitAdmin admin(ConnectionFactory connectionFactory) {
val ra = new RabbitAdmin(connectionFactory);
val queueNames = Arrays.asList(
backupQueueName.productManual,
backupQueueName.collectionManual
);
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-queue-type", "quorum");
for (String queueName : queueNames) {
ra.declareQueue(new Queue(queueName, true, false, false, arguments));
}
return ra;
}
Một số lỗi hay gặp
[SimpleMessageListenerContainer.java : 1004] Consumer failed to start in 60000 milliseconds; does the task executor have enough threads to support the container concurrency?=> Do poolsize của taskExecutor thấp hơn số concurrency của subsciber. Cần tăng pool size, hoặc giảm số concurrency xuống.node_health_check and its HTTP API counterpart are DEPRECATED=> do có client đang sử dụng api cũ để healcheck tới cluster. (có thể client này chỉ được sử dụng cho version rabbitmq 3.7 trở về trước).
All rights reserved
