
Tổng quan về Triton Inference Server
Tổng quan
Triton Inference Server là một open source inference serving software, cho phép deploy các AI model từ nhiều deep-machine learning frameworks, bao gồm TensorRT, TensorFlow, PyTorch, ONNX, OpenVINO, Python, RAPIDS FIL, v.v. Triton hỗ trợ inference trên cloud, data center và thiết bị nhúng trên GPU NVIDIA, x86 và CPU ARM hoặc AWS Inferentia cũng như mang lại hiệu suất được tối ưu hóa cho nhiều loại truy vấn, bao gồm real-time, batched, ensembles và audio/video streaming. Ngoài ra, Triton còn có thể dễ dàng tích hợp với các công cụ khác như Kubernetes, Kserve, Prometheus hay Grafana. Tóm lại, đây là một nền tảng phần mềm giúp tăng tốc quy trình khoa học dữ liệu và tối đa hóa hiệu suất và hiệu quả của các ứng dụng AI.
Triton Architecture
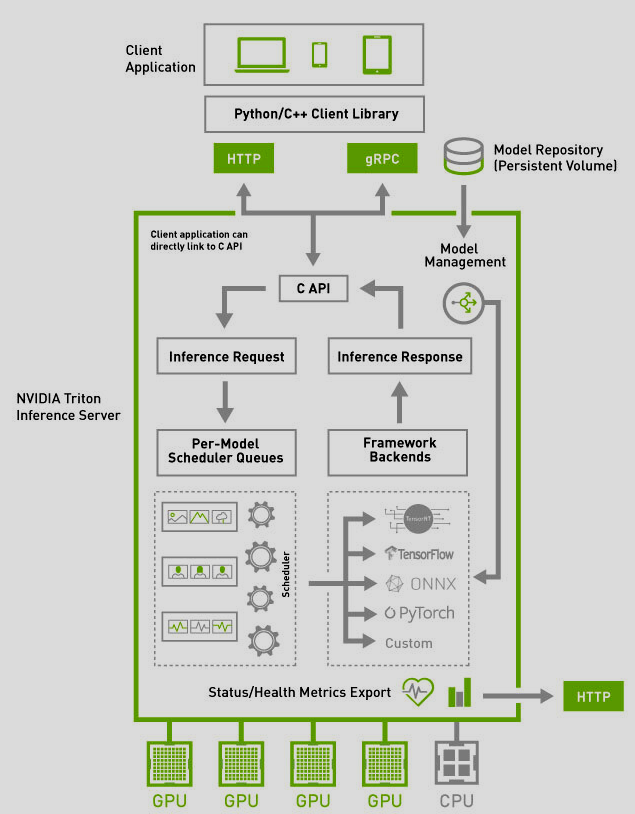
Trong đó:
- Model repository là kho lưu trữ dựa trên hệ thống file mô hình (file-system) mà Triton cung cấp cho hoạt động inference
- Inference request có thể được gửi tới triton server thông qua HTTP/gRPC hoặc C API
- Inference Request sau đó được chuyển đến bộ lập lịch (Per-model schedular) thích hợp cho mỗi mô hình
- Triton triển khai nhiều thuật toán để scheduling và batching để có thể cấu hình trên cơ sở từng mô hình mang lại hiệu suất tốt hơn
- Scheduler của mỗi model tùy chọn thực hiện batching các inference requests và chuyển tới Backend tương ứng với loại model
- Các model có thể được dynamically loaded từ bộ nhớ cloud hoặc local file systems mà không cần khởi động lại server
- Backend frameworks thực hiện inferencing bằng cách sử dụng các input từ batched requests để tạo các requested output
- Các output sau đó được gửi lại tới client
Các model được serve bởi Triton có thể được truy vấn và kiểm soát bằng model management API có sẵn bằng HTTP/REST hoặc gRPC protocol, C API. Các metrics về mức độ sử dụng, sẵn sàng, tình trạng hoạt động, thông lượng, độ trễ dễ dàng tích hợp Triton vào deployment framework như Kubernetes.
Features
Hỗ trợ nhiều deep-machine learning frameworks
Triton hỗ trợ nhiều kỹ thuật tối ưu hóa mô hình Deep Learning. Platform cung cấp hỗ trợ cho TensorRT, Runtime library và NVIDIA’s high-performance deep learning inference optimizer. Ngoài ra còn hỗ trợ ONNX Runtime - open-source performance-focused để chạy các ONNX models. ONNX Runtime cung cấp các tính năng giúp cải thiện hiệu suất các DL models: graph optimizations, kernel fusion, execution provider integration cho phép developers tận dụng các tính năng tối ưu bất kể Deep learning framework.
Dynamic batching
Phía client sẽ gửi các request độc lập, nếu như xử lý tuần tự như vậy sẽ tốn rất nhiều thời gian. Với Dynamic batching, nhiều request sẽ được tổng hợp lại vào 1 batch lớn hơn, có thể được server xử lý đồng thời để có thể tận dụng tốt hơn tài nguyên, giảm độ trễ và cải thiện thông lượng. Vì vậy, việc sử dụng dynamic batching sẽ hữu dụng cho các ứng dụng như recommendation systems, phân tích real-time video.
Dynamic batching có thể được enabled và sử dụng với cài đặt mặc định bằng thêm phần: dynamic_batching { } trong file config.pbtxt của mỗi model (mình sẽ trình bày trong các phần sau). Ngoài ra, ta có thể sử dụng một tool khác của Triton là Model Analyzer để có thể tự động tìm ra cấu hình dynamic batching phù hợp nhất cho hệ thống.
Một số thuộc tính của dynamic batching
- Preferred Batch Sizes: Các kích thước batch mà dynamic batching cố gắng tạo. Tuy nhiên thì hầu hết các mô hình không nên sử dụng cái này. Ngoại trừ một vài trường hợp của mô hình TensorRT. Ví dụ:
dynamic_batching {
preferred_batch_size: [ 4, 8 ]
}
-
- Delayed Batching: là khoảng thời gian tối đa mà request có thể bị trì hoãn để cho phép các request khác tham gia. Sử dụng khi không thể tạo 1 batch có kích thước tối đa hoặc ưu tiên như ở trên. Tuy nhiên trong thực tế thì thường dẫn đến thời gian thực thi lâu hơn cho các batch lớn.
dynamic_batching {
max_queue_delay_microseconds: 100
}
- Preserve Ordering: thuộc tính sử dụng để buộc tất cả các responses phải được phản hồi cùng với thứ tự của requests tương ứng đã nhận
- Priority Levels: thuộc tính để xử lý các requests theo nhiều mức độ ưu tiên
- Queue Policy: được sử dụng khi priority_levels được định nghĩa, với mỗi priority levels sẽ có một ModelQueuePolicy khác nhau
- Custom Batching: tùy chỉnh batching rules ngoài các hành vi của dynamic batching
Tính năng này chủ yếu tập trung vào việc cung cấp giải pháp cho Stateless models (các model không duy trì trạng thái giữa lần thực thi, như model phát hiện vật thể, phân loại hình ảnh).
Concurrent model execution: Thực thi mô hình đồng thời
Model parallelism cho phép nhiều model hoặc nhiều instances của deep learning models thực thi đồng thời trên các GPU (hệ thống có thể có 0, 1 hoặc nhiều GPU) nhằm tận dụng và xử lý ứng dụng AI quy mô lớn hiệu quả, giúp giảm độ trễ, cải thiện thông lượng. Việc tận dụng tính năng này rất có lợi cho các mô hình phức tạp đòi hỏi tài nguyên tính toán như NLP, Computer Vision. Triton Inference Server có thể tạo ra nhiều phiên bản của cùng một mô hình, có thể xử lý các truy vấn song song. Ta có thể sử dụng tính năng thông qua instance groups trong model’s configuration
instance_group [
{
count: 2
kind: KIND_GPU
gpus: [ 0, 1 ]
}
]
Dưới đây là một hình ảnh minh họa việc sử dụng Dynamic Batching và Concurrent model execution
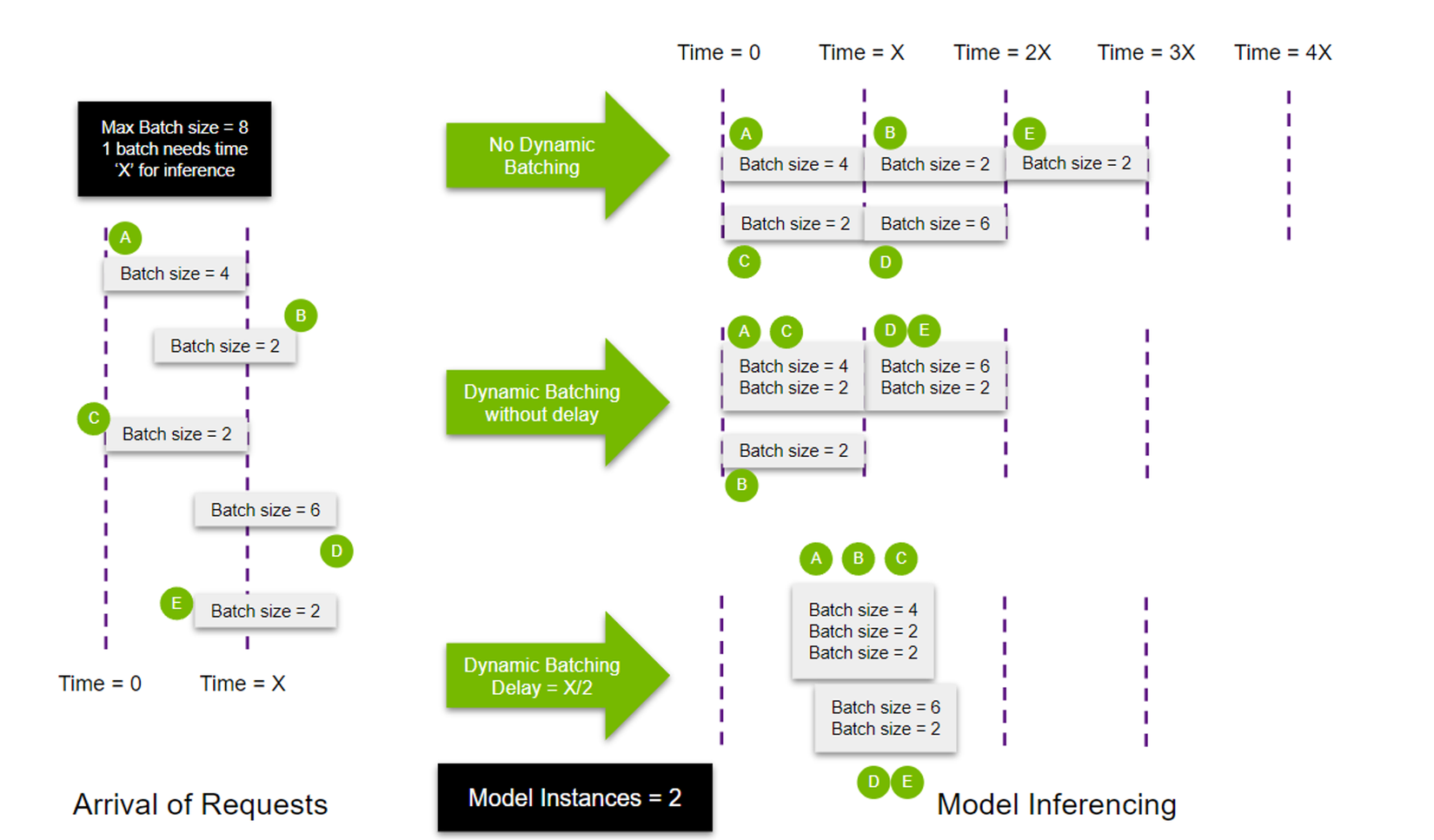
Trong hình trên, model instances được sử dụng là 2. Bởi vì cậy, thay vì một mô hình xử lý cả 5 queries, 2 models được tạo ra.
- Trong trường hợp No Dynamic Batching, vì có 2 mô hình được thực thi nên các truy vấn được phân bố đều. Trong đó, model thứ nhất xử lý request A và model xử lý request C do 2 request được gửi cùng thời điểm. Sau khi xử lý xong A và C, 2 model tiếp tục nhận request B và D theo thứ tự xuất hiện. Sau khi model 1 xử lý request B, model 1 tiếp tục nhận request E để xử lý.
- Xét trường hợp Dynamic Batching without delay, Max batch size được khởi tạo = 8. Vì vậy, model 1 sẽ thực thi cả 2 request cùng thời điểm gửi đến là A và C. Sau đó, request B đến với độ trễ nhất định có thể được thực thi bằng cách sử dụng model thứ hai.
- Với trường hợp có Delay , model 1 sẽ được lấp và khởi chạy theo thời gian T = X/2, các truy vấn D và E xếp chồng lên nhau để lấp đầy batch size tối đa (khởi tạo = 8), nên mô hình thứ hai có thể bắt đầu thực thi mà không có bất kỳ độ trễ nào.
Ta có thể thấy rằng Triton Inference Server cung cấp tính linh hoạt liên quan đến việc tạo batching hiệu quả hơn, do đó cho phép sử dụng tài nguyên tốt hơn, dẫn đến giảm độ trễ và tăng thông lượng.
Cung cấp Backend API cho phép thêm Triton Custom Backends
Models có thể chứa các phần non-ML-model (ví dụ: tokenizer, feature extractor BERT). Triton Backend API cho phép tích hợp extension như vậy vào Triton. API cũng cho phép users tích hợp triển khai một công cụ thực thi của riêng họ vào Triton dưới dạng custom backend. Từ đó, Developers có thể customize và mở rộng Triton Inference Server cho bất kỳ ứng dụng và quy trình suy luận nào bằng ngôn ngữ Python hoặc C++.
Lợi ích:
- Thực hiện mã nguồn dưới dạng shared library sử dụng C API backwards compatible.
- Tận dụng tất cả các tính năng của Triton (tương tự như existing framework): Bao gồm Dynamic batcher, sequence batcher, concurrent execution, multi-GPU.
- Cung cấp tính linh hoạt trong triển khai, Triton cung cấp giao thức giao tiếp tiêu chuẩn và nhất quán giữa các mô hình và các thành phần tùy chỉnh.
Ensembling models
Pipeline được xây dựng từ nhiều model có thể được kết nối input và output tensors giữa các models và chia sẻ GPU để tối ưu hóa hiệu suất. Ensemble models có mục đích đóng gói một quy trình liên quan đến nhiều mô hình như data preprocessing → inference → data postprocessing. Việc sử dụng ensemble models có thể tránh chi phí chuyển giao các tensor trung gian và giảm thiểu số lượng request phải gửi tới Triton.
 Trong hình trên, hình ảnh gốc sẽ được gửi từ phía Client sang bên Triton. Thay vì gửi request tới các mô hình độc lập, ta có thể gửi request tới ensemble model: Raw Image -> Text Detection -> Image Cropping -> Text Recognition. Sau đó, dữ liệu đã qua xử lý sẽ được gửi trả về Client. Ví dụ về mô hình ensemble cho phân loại và phân đoạn hình ảnh có model configuration như sau:
Trong hình trên, hình ảnh gốc sẽ được gửi từ phía Client sang bên Triton. Thay vì gửi request tới các mô hình độc lập, ta có thể gửi request tới ensemble model: Raw Image -> Text Detection -> Image Cropping -> Text Recognition. Sau đó, dữ liệu đã qua xử lý sẽ được gửi trả về Client. Ví dụ về mô hình ensemble cho phân loại và phân đoạn hình ảnh có model configuration như sau:
name: "ensemble_model"
platform: "ensemble"
max_batch_size: 1
input [
{
name: "IMAGE"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
output [
{
name: "CLASSIFICATION"
data_type: TYPE_FP32
dims: [ 1000 ]
},
{
name: "SEGMENTATION"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
ensemble_scheduling {
step [
{
model_name: "image_preprocess_model"
model_version: -1 #lastest version
input_map {
key: "RAW_IMAGE"
value: "IMAGE"
}
output_map {
key: "PREPROCESSED_OUTPUT"
value: "preprocessed_image"
}
},
{
model_name: "classification_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "CLASSIFICATION_OUTPUT"
value: "CLASSIFICATION"
}
},
{
model_name: "segmentation_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "SEGMENTATION_OUTPUT"
value: "SEGMENTATION"
}
}
]
}
Trong file trên, ensemble scheduling được sử dụng và ensemble model bao gồm 3 model khác nhau. Mỗi phần tử hay mỗi mô hình trong step chỉ định model được sử dụng và cách ánh xạ đầu vào và đầu ra của model. Để xác định xem model nào chạy trước hay các tensor chuyển đổi thế nào giữa mỗi model thì ta sẽ sử dụng input_map và output_map. Trong input_map và output_map thì sẽ có key và value. Trong đó, key : là tên của các layer mà các model yêu cầu, value : định nghĩa luồng của các tensor. Như ví dụ ở trên thì output của image_preprocess_model làm đầu vào của cả classification_model và segmentation_model thì value của output của image_preprocess_model phải trùng với value của 2 mô hình trên.
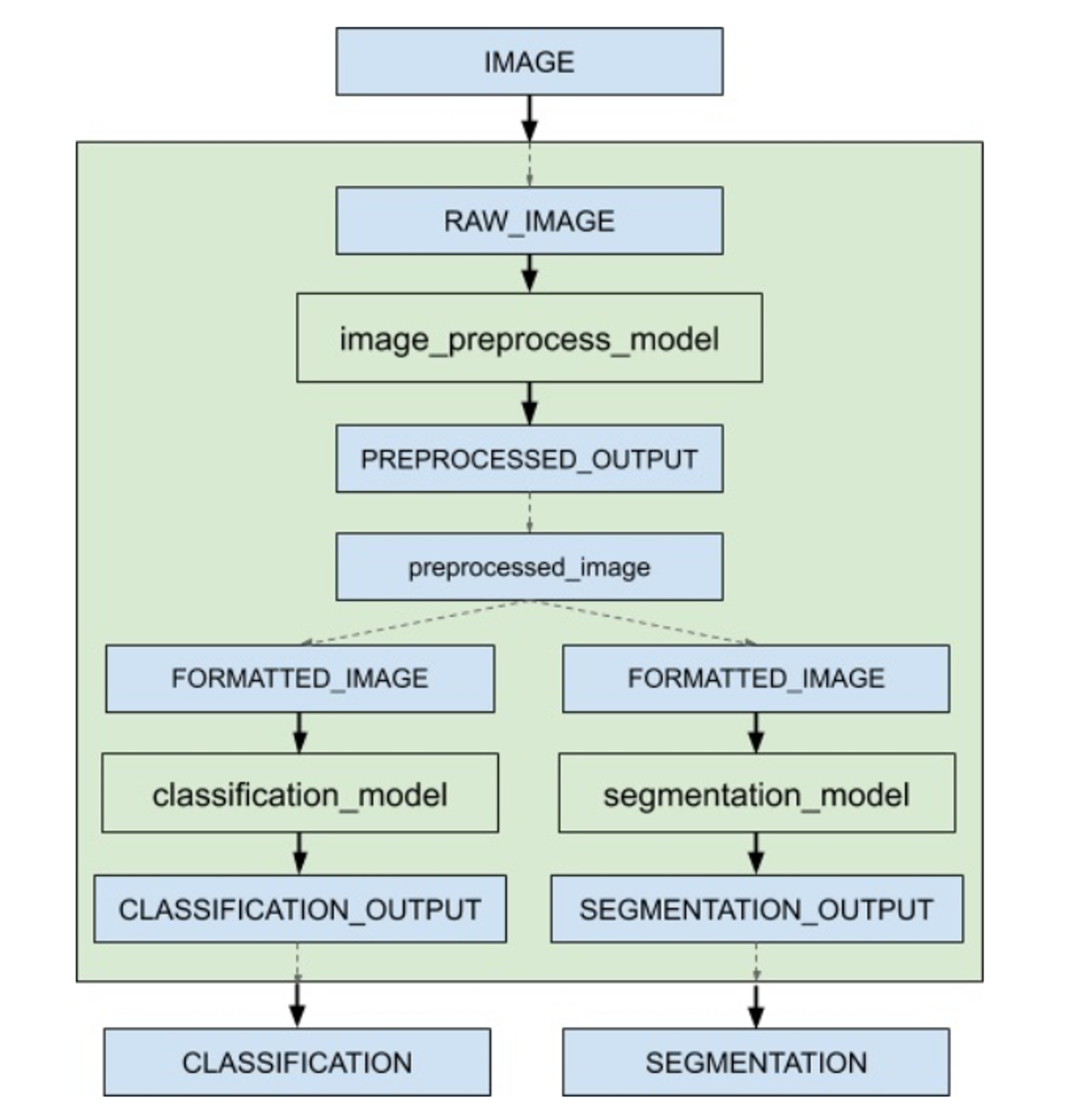
Khi nhận được inference request cho ensemble model thì ensemble scheduler sẽ:
- Nhận thấy IMAGE tensor ở request sẽ ánh xạ tới key là RAW_IMAGE trong input_map ở image preprocess model
- Kiểm tra các model bên trong ensemble và gửi internal request tới image preprocess model
- Thu thập tensor đầu ra “preprocessed image”
- Ánh xạ tensor vừa mới thu được tới input của các model trong trong ensemble.
- Kiểm tra và gửi interal request khi mỗi mô hình tải và tính toán xong
- Lặp lại bước 3 -5 cho đến khi ko còn internal request được gửi nữa và phản hổi lại inference request đã gửi ở đầu với các tensor được ánh xạ tới đầu ra của ensemble
HTTP/REST và GRPC inference protocols
Clients có thể giao tiếp Triton bằng cách sử dụng giao thức HTTP/REST, GRPC hoặc bởi in-process C API. Giao thức HTTP/REST và GRPC cung cấp endpoints kiểm tra tình trạng, dữ liệu và số liệu thống kê của server và model.
Metrics
Triton cung cấp Prometheus metrics cho biết số liệu thống kê về GPU và request. Ngoài ra, Triton cũng cung cấp các metrics cho Inference Request, GPU, CPU, v.v. VD: mức sử dụng GPU, server throughput, server latency, memory, ...
Triton Basics
Model repository
Model repository hay Cấu trúc của repo được lưu trữ ở local hoặc từ đường dẫn tới Google Cloud Storage, Amazon S3, hoặc Azure Storage. Dưới đây là ví dụ của model repository:
<model-repository>/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
...
Trong đó, model-name là tên của mô hình. File cấu hình của model tương ứng được viết dưới dạng config.pbtxt, thông thường file sẽ được tạo tự động. version của model được đặt tên bằng số và bắt đầu từ 1. Mặc định thì Triton sẽ sử dụng phiên bản mới nhất tuy nhiên việc này có thể được tùy chỉnh trong model configuration. Cuối cùng, model-definition-file, như cái tên, nó xác định mô hình và backend hỗ trợ. Ví dụ đối với tensorRT thì là model.plan, Onnx thì là model.onnx còn TorchScript sẽ là model.pt. Ví dụ về model repository chi tiết như sau:
# Expected folder layout
model_repository/
├── segmentation
│ ├── 1
│ │ └── model.pt
│ └── config.pbtxt
└── recognition
├── 1
│ └── model.onnx ## model definition file
└── config.pbtxt
Model configuration
Mỗi model trong repo phải có 1 model configuration, các yêu cầu và tùy chọn của model sẽ được viết bên trong file config.pbtxt. Trong model configuratioon, bắt buộc phải có các thông tin sau:
- Platform hay Backend: Framework sử dụng (TensorRT, ONNX, Pytorch)
- Max_batch_size: Kích thước tối đa mà model hỗ trợ, nếu model có hỗ trợ batching thì triton sẽ sử dụng dynamic batcher hoặc sequence batcher để tự động chia batch
- Input và Output của model: phải chỉ định tên, datatype, shape. Hầu hết, ta có thể bỏ phần input và output, Triton sẽ trích xuất các thông tin này từ model files.
Một ví dụ nhỏ dưới đây, ở đây ta sẽ có 2 input, 1 output với kiểu dữ liệu là float32. Dims là dimensions - số chiều của vector đầu vào và đầu ra của mô hình. Trong một vài trường hợp thì Triton sẽ tạo tự động các phần bắt buộc này.
platform: "tensorrt_plan"
max_batch_size: 8
input [
{
name: "input0"
data_type: TYPE_FP32
dims: [ 16 ]
},
{
name: "input1"
data_type: TYPE_FP32
dims: [ 16 ]
}
]
output [
{
name: "output0"
data_type: TYPE_FP32
dims: [ 16 ]
}
]
Model management
Triton cung cấp các API quản lý mô hình là một phần của giao thức HTTP/REST và gRPC, và là 1 phần của C API . Triton hoạt động ở 1 trong 3 model control modes: NONE, EXPLICIT hoặc POLL. Model control mode xác định cách Triton xử lý các thay đổi tới kho lưu trữ mô hình và những giao thức hoặc API nào có sẵn.
Model Control Modes:
- NONE: Triton cố gắng tải tất cả các mô hình trong kho lưu trữ mô hình khi khởi động. Models nào không thể tải sẽ bị gán là UNAVAILABLE và sẽ không có sẵn khi inferencing. Mọi thay đổi tới model repository khi server đang chạy sẽ bị bỏ qua. Các requests model load và unload sử dụng giao thức model control sẽ không có hiệu lực và trả về phản hồi lỗi. Khi khởi động Triton, ta cần chỉ định
--model-control-mode=none(default). - EXPLICIT: Khi khởi động, Triton chỉ load những models được chỉ định rõ ràng qua command-line
--load-model. Sau khởi động, Tất cả model load hay unload phải khởi tạo rõ ràng sử dụng giao thức điều khiển mô hình (model control protocol). Ta xác định-model-control-mode=explicit. - POLL: Triton cố gắng tải tất cả các mô hình trong kho lưu trữ mô hình khi khởi động. Thay đổi tới model repository sẽ được phát hiện và Triton sẽ cố gắng load và unload models khi cần thiết dựa trên thay đổi đó. Model load và unload requests sử dụng model control protocol sẽ không có hiệu lực và sẽ trả về phản hồi lỗi. Ta cần xác định
-model-control-mode=poll.
Triton Tool
Triton Performance Analyzer
Triton Performance Analyzer là CLI tool có thể giúp tối ưu hóa hiệu suất inference của các mô hình chạy trên Triton Inference Server bằng cách đo lường những thay đổi về hiệu suất khi thử nghiệm các chiến lược tối ưu hóa khác nhau. Analyzer cung cấp một số tính năng:
- Chế độ Inference Load:
- Concurrency Mode: duy trì sự đồng thời cụ thể của requests gửi đi tới server
- Request Rate Mode: gửi các yêu cầu liên tiếp ở một tốc độ cụ thể đến server.
- Custom Interval Mode: gửi các yêu cầu liên tiếp theo các khoảng thời gian cụ thể đến server.
- Performance Measurement Modes
- Time Windows Mode: đo hiệu suất mô hình nhiều lần trong một khoảng thời gian cụ thể cho đến khi hiệu suất ổn định
- Count Windows Mode: đo hiệu suất mô hình theo 1 số request cụ thể cho đến khi ổn định
Triton Model Analyzer
Triton Model Analyzer là tool sử dụng Performance Analyzer để gửi yêu cầu đến mô hình trong khi đo bộ nhớ GPU và mức sử dụng điện toán. Sau khi có thông tin sử dụng bộ nhớ GPU này, ta có thể quyết định về cách kết hợp nhiều mô hình trên cùng một GPU trong khi vẫn duy trì trong dung lượng bộ nhớ của GPU. Nó tự động xác định các cấu hình mô hình tùy chọn trong Triton để tối đa hóa hiệu suất:
- Xác định ràng buộc về kết quả hiệu suất (độ trễ, lưu lượng, bộ nhớ GPU)
- Tự động quét đồng thời qua các cấu hình khác nhau (kích thước batch, số lượng mô hình, yêu cầu của client).
- Tìm ra cấu hình tốt nhất để đạt hiệu suất tối ưu dưới ràng buộc đã đặt ra.
- Hiển thị kết quả của bộ phân tích qua báo cáo và biểu đồ.
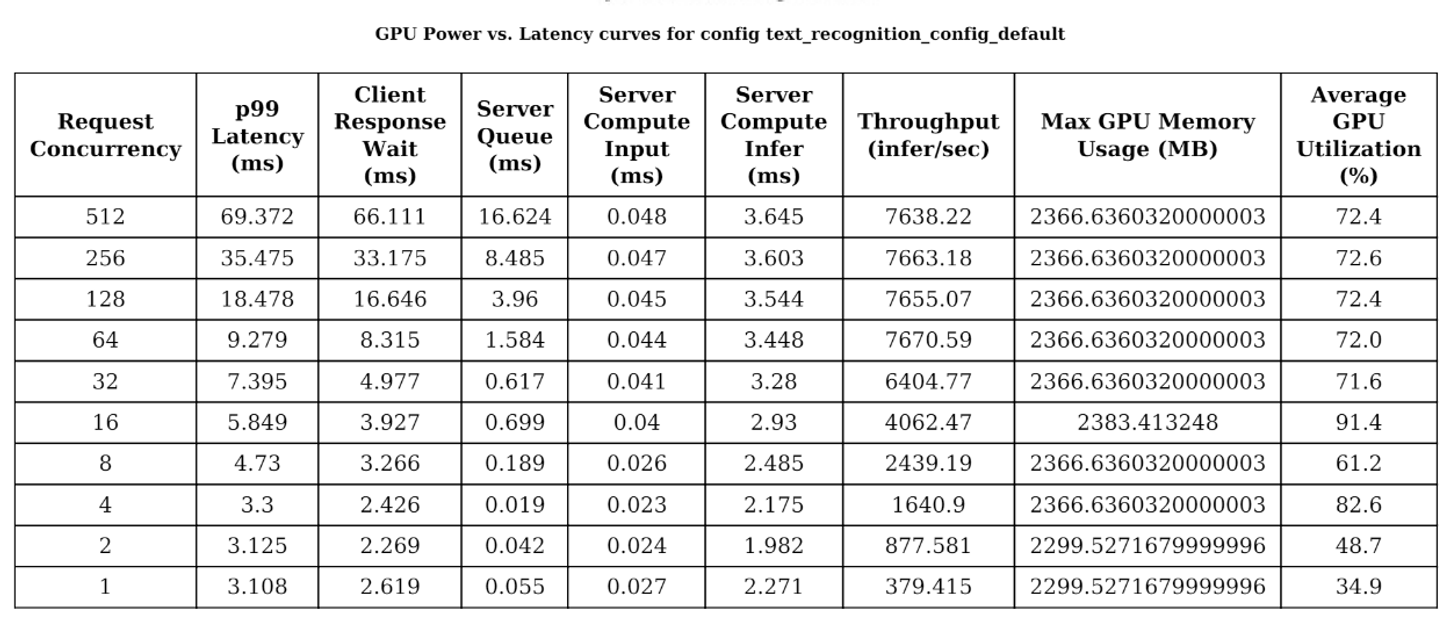
Đo lường dấu vết bộ nhớ GPU của một mô hình cho các kích thước batch và giá trị đồng thời yêu cầu khác nhau. Kết quả sau đó có thể được sử dụng để xác định cấu hình mô hình tối ưu, tối đa hóa hiệu suất trong khi đáp ứng yêu cầu sử dụng bộ nhớ.
- Tối ưu hóa việc sử dụng phần cứng: Xác định số lượng tối đa mô hình có thể được tải lên mỗi GPU, giảm thiểu nhu cầu về phần cứng hoặc cân nhắc sự cân đối với lưu lượng.
- Định kích thước phần cứng tốt hơn: Xác định số lượng chính xác của phần cứng cần thiết để chạy các mô hình của bạn, bằng cách sử dụng yêu cầu về bộ nhớ.
Có 2 loại report có thể được tạo ra:
-
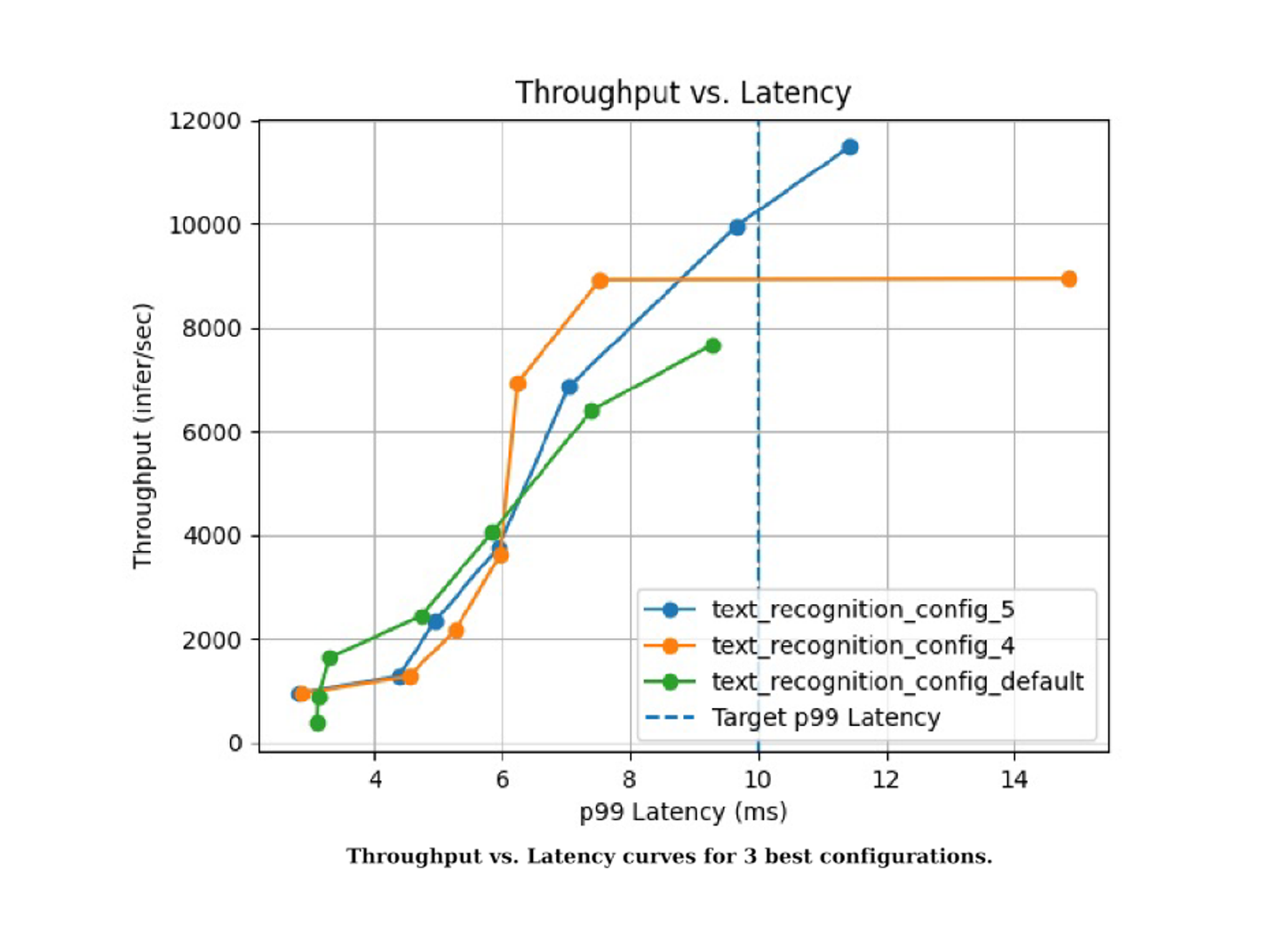
Summaries: chứa kết quả tổng thể của các cấu hình. Ví dụ:
![]()
-
Detailed Reports:
![]()
Tổng kết
Vậy là ta đã đi qua một số khái niệm cơ bản cũng như hiểu rõ hơn các tính năng của Triton Inference Server. Trong bài viết tiếp theo, mình sẽ đi chi tiết phần installation, các ví dụ cụ thể sử dụng Triton Inference Server và Triton Tool nhé.
Tài liệu tham khảo
All rights reserved
