Tổng quan về RASA Chatbot
Bài đăng này đã không được cập nhật trong 3 năm
Xin chào các bạn, bài viết hôm nay mình sẽ viết về RASA - một framework để xây dựng Chatbot hội thoại có những hỗ trợ rất mạnh mẽ cho các nhà phát triển. Có nhiều bài viết trước đây về RASA trên Viblo và có đóng góp rất tích cực đến cộng đồng (Bản thân mình nhiều lần tham khảo đến các bài viết này), các bài viết đều hướng dẫn mọi người có thể tiếp cận và thực hành trên RASA.
Vì vậy, trong bài này, mình sẽ tập trung phân tích kiến trúc pipeline của chatbot được xây dựng bằng RASA, nhằm giúp mọi người hiểu một cách tổng quan kiến trúc, các thành phần và vai trò của từng thành phần trong chatbot.
Các khái niệm chung
RASA là một framework để xây dựng chatbot hội thoại, có hỗ trợ rất nhiều công cụ để người dùng có thể xây dựng chatbot nhanh và hiệu quả ngay cả khi dữ liệu cung cấp ít. Vậy RASA hỗ trợ gì?
Các vấn đề khi xây dựng chatbot thông minh
Xét một luồng hội thoại như hình sau:
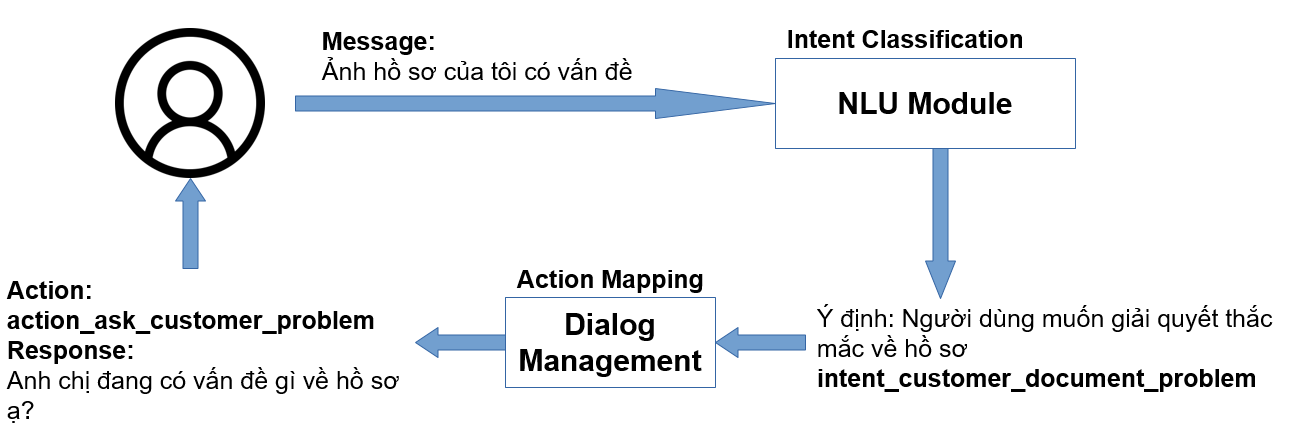 Từ ví dụ trong hình trên, chúng ta có các vấn đề quan trọng khi xây dựng bất kỳ chatbot hội thoại nào đều phải xử lý:
Từ ví dụ trong hình trên, chúng ta có các vấn đề quan trọng khi xây dựng bất kỳ chatbot hội thoại nào đều phải xử lý:
- Xác định ý định câu hội thoại người dùng (Intent Classification)
- Xác định các thực thể hội thoại (Entity Extraction, ở VD trên hình là entity "Hồ sơ")
- Xác định hành động cần thực hiện ứng với ý định câu hội thoại hiện tại của người dùng (Hay đơn giản là câu trả lời)
Như vậy, để xây dựng đầy đủ các chức năng trên, bao gồm thu thập dữ liệu, chuẩn bị dữ liệu, huấn luyện mô hình phân loại, mô hình trích xuất thực thể, module xử lý luồng hội thoại, ... , chúng ta sẽ phải bỏ ra rất nhiều công sức để chatbot có thể đạt được hiệu quả chấp nhận được. Nhưng không cần phải lo những điều này khi chúng ta đã có RASA.
Các thành phần của chatbot RASA
a. Thành phần cơ bản
Hai thành phần cơ bản của RASA bao gồm:
1. RASA NLU (Natural Language Understanding)
Đây là module đóng vai trò xử lý đầu vào câu hội thoại người dùng (tokenize, featurize), xác định ý định người dùng (Intent Classification) và trích chọn thực thể (Entity Extraction). Ngoài ra, RASA NLU còn có các tính năng khác như Regular Expression, Synonyms, Lookup Table.
- Regular Expression: Trích chọn thực thể bằng Regex
VD: ngày tháng, từ khóa cụ thể - Synonym: Từ đồng nghĩa
VD: "ub", "ubnd" và "Ủy ban nhân dân", khi gặp các từ "ub", "ubnd", hệ thống tự chuyển thành "Ủy ban nhân dân" - Lookup Table: Định nghĩa một tập giá trị cho một biến (RASA gọi là slot)
VD: Slot Province, ta định nghĩa Lookup Table gồm 64 tên tỉnh thành: "Hà Nội", "Hải Phòng", "Hà Nam",... . Khi hệ thống phát hiện từ "Hải Phòng" trong câu hội thoại người dùng, hệ thống sẽ tự gán giá trị "Hải Phòng" cho biến Province trong bộ nhớ, điều này giúp chatbot có thể nhận ra một số giá trị bổ trợ cho ngữ cảnh
2. RASA Core
RASA Core có vai trò kiểm soát luồng hội thoại, quyết định hành động nào được thực hiện để đáp lại câu hội thoại người dùng.
RASA Core bao gồm các chính sách (Policy) để xử lý luồng hội thoại, gồm:
- RulePolicy: Sử dụng các luật (Rule) để xác định hành động tiếp theo
- MemoizationPolicy: Sử dụng các Story để xác định hành động tiếp theo
- TEDPolicy: Sử dụng học sâu để xác định hành động tiếp theo
Các Policy này cùng nhau hợp lại thành Dialog Policies.
Cụ thể hơn, chúng ta sẽ xem xét ở phần sau.
b. Các thành phần hệ thống chatbot RASA
Bên cạnh hai thành phần cốt lõi trên, hệ thống chatbot RASA cần thêm các thành phần để xử lý bộ nhớ, kết nối các thành phần lại với nhau để hoạt động hiệu quả
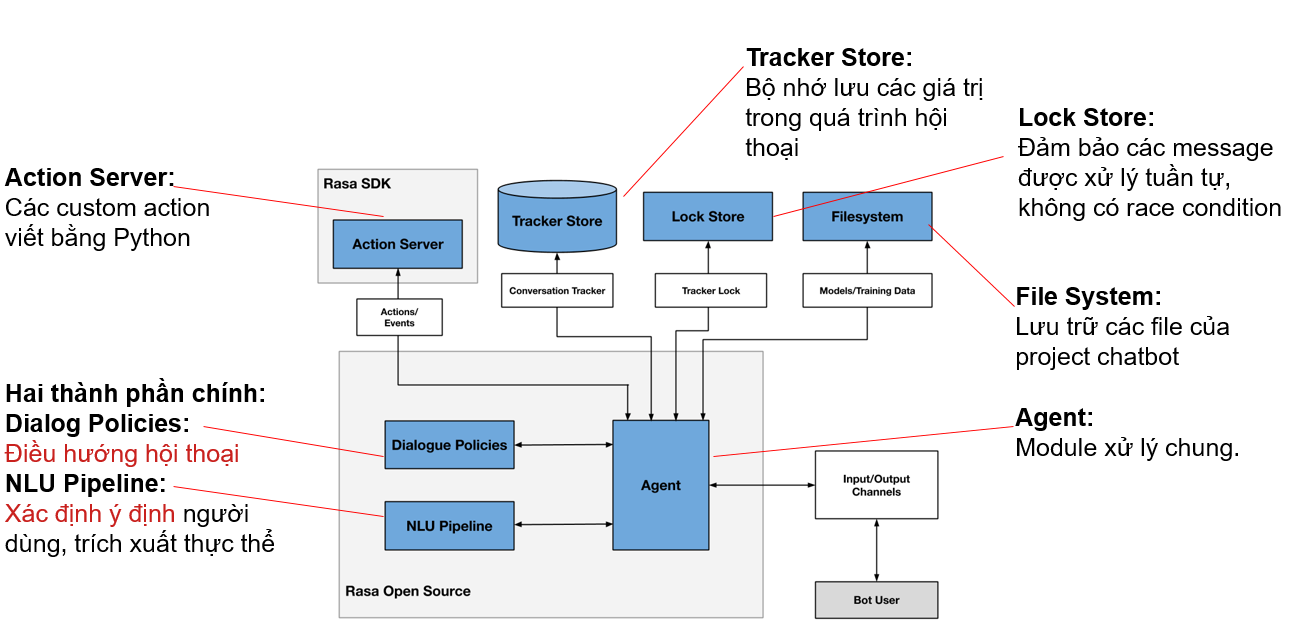 NLU Pipeline: Các module RASA NLU
NLU Pipeline: Các module RASA NLU
Dialog Policies: Các policy của RASA Core
Action Server: Các action đáp lại người dùng được viết bằng python (action mặc định là action dạng text)
Tracker Store: Module lưu trữ các slot, entity, câu hội thoại (Đây chính là module bộ nhớ lưu trữ của chatbot)
Lock Store: Module đảm bảo các câu hội thoại gửi đến chatbot được xử lý tuần tự, không bị race condition
Filesystem: Module lưu trữ và quản lý các tệp của chatbot
Agent: Module xử lý chung và kết nối các thành phần khác
Trong các thành phần trên, chúng ta chủ yếu làm việc với NLU Pipeline, Dialog Policies, Action Server và sử dụng Tracker để xử lý dữ liệu trong Action Server.
Luồng hoạt động chi tiết
Để có thể xây dựng chatbot RASA hiệu quả, điều đầu tiên chúng ta phải hiểu rõ kiến trúc của RASA, trong đó hiểu rõ với một câu hội thoại đầu vào, dữ liệu sẽ được RASA xử lý như thế nào. Trong phần này chúng ta sẽ đi làm rõ về luồng hoạt động câu hội thoại từ khi chatbot tiếp nhận, xử lý và sau đó trả lời người dùng.
Xem xét sơ đồ sau:
 Tin nhắn (Message) đi vào RASA NLU, được xử lý đầu vào, trích chọn véc-tơ đặc trưng, áp dụng các bộ trích chọn thực thể (nếu có), xác định ý định của người dùng.
Tin nhắn (Message) đi vào RASA NLU, được xử lý đầu vào, trích chọn véc-tơ đặc trưng, áp dụng các bộ trích chọn thực thể (nếu có), xác định ý định của người dùng.
Sau khi xác định được ý định, trích chọn được các thực thể trong tin nhắn, dữ liệu được đẩy sang RASA Core (Từ giờ đến cuối bài mình sẽ gọi là Dialog Policies), dữ liệu các ý định và thực thể từ các tin nhắn của bước hội thoại trước cũng được đưa vào mô hình để xử lý và tính toán hành động tiếp theo để đáp lại người dùng.
Hãy cùng đi sâu từng thành phần để chúng ta có thể hiểu chi tiết hơn bằng sơ đồ ví dụ trong hình trên.
RASA NLU Pipeline
RASA NLU Pipeline bao gồm nhiều module để có thể xử lý đầu vào câu văn bản của người dùng: tokenizer, trích chọn đặc trưng (featurizer), trích xuất thực thể (regex entity extractor, ...), bộ phân loại (classifier). Trong sơ đồ trên, câu văn bản được đưa vào theo thứ tự:
- Tokenizer
- CountVectorFeaturizer 1
- CountVectorFeaturizer 2
- DIETClassifier
- RegexEntityExtractor
Trên thực tế, không nhất thiết phải tuân theo thứ tự này, cũng như phải có đầy đủ các thành phần này (Bạn sẽ thấy cấu hình module này trong tệp config.yml), bạn có thể thêm hoặc bớt, hoặc trích chọn thực thể trước với RegexEntityExtractor rồi mới tiến hành trích chọn đặc trưng và phân loại ý định người dùng.
 Tuy nhiên trong bài này, mình sẽ lấy ví dụ đi qua lần lượt các module này.
Giả sử câu hội thoại người dùng nói là "Ảnh hồ sơ tôi mờ lắm"
Tuy nhiên trong bài này, mình sẽ lấy ví dụ đi qua lần lượt các module này.
Giả sử câu hội thoại người dùng nói là "Ảnh hồ sơ tôi mờ lắm"
- Tokenizer: Trước khi thực hiện trích chọn véc-tơ đặc trưng, câu văn bản đầu vào cần phải được tokenize
"Ảnh hồ sơ tôi mờ lắm" --> ["Ảnh", "hồ_sơ", "tôi", "mờ", "lắm"]
- CountVectorFeaturizer 1: Tính toán sparse feature véc-tơ (mình sẽ không đi sâu giải thích vì sẽ khá dài, các bạn hãy tìm hiểu thêm).
["Ảnh", "Hồ_sơ", "tôi", "mờ", "lắm"] --> [0, 1, 1, 0, ..., 1, 0]
- CountVectorFeaturizer 2: Tính toán dense feature véc-tơ (có thể sử dụng module của RASA hoặc customize lại theo ý của các bạn, PhoBERT chẳng hạn):
["Ảnh", "Hồ_sơ", "tôi", "mờ", "lắm"] --> [2.44, 1.32, ..., 0.13, 1.56]
Sau đó 2 véc-tơ sparse feature, dense feature này được nối lại để tạo thành véc-tơ duy nhất để đưa vào mô hình DIETClassifier.
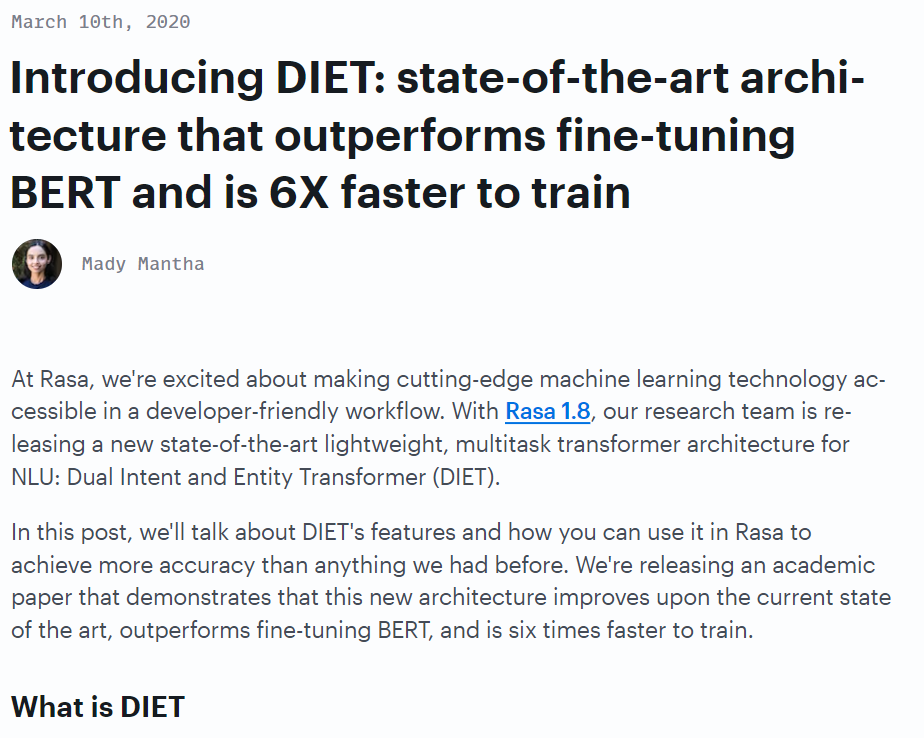
- DIETClassifier: DIET (Dual Intent and Entity Transformer) Classifier là mô hình đa tác vụ có thể phân loại ý định và trích xuất thực thể, đây là mô hình nhẹ, hiệu quả được nhóm nghiên cứu của RASA phát triển thử nghiệm cho kết quả vượt trội so với BERT và huấn luyện nhanh gấp 6 lần. Véc-tơ đặc trưng từ bước trước được đưa vào mô hình, đầu ra là ý định của tin nhắn hội thoại và các thực thể có trong tin nhắn.
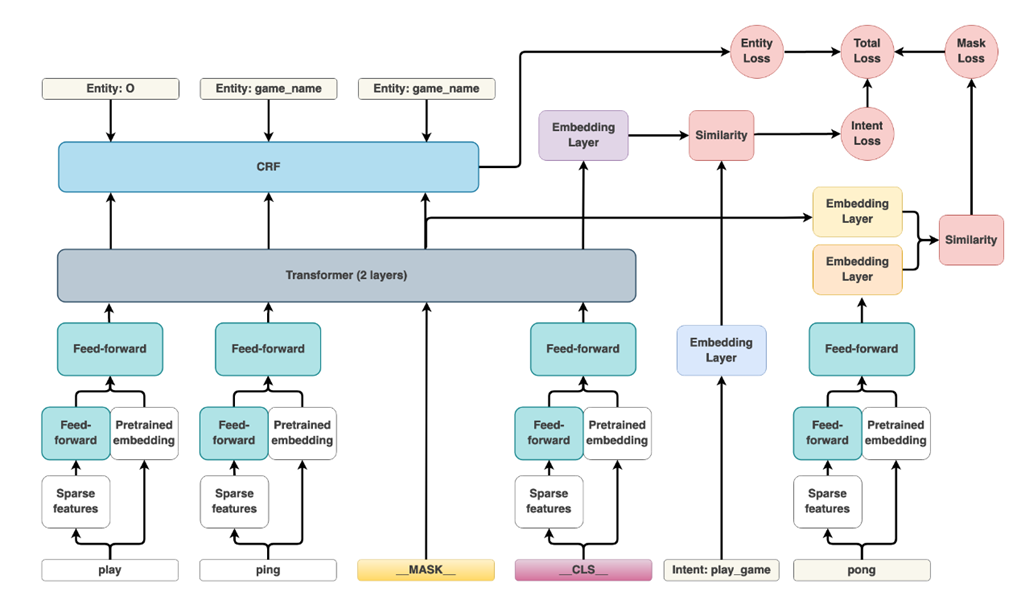
![image.png]() Quá trình huấn luyện, mô hình DIET thực hiện đồng thời ba tác vụ: dự đoán intent, trích chọn thực thể, và dự đoán masked token (Một token trong câu được mask ngẫu nhiên và quá trình huấn luyện mô hình phải cố gắng đoán được từ này, điều này giúp cho khoảng cách các từ gần nghĩa gần nhau hơn trên không gian số khi mô hình hội tụ). Dưới đây là sơ đồ trích từ bài báo:
Quá trình huấn luyện, mô hình DIET thực hiện đồng thời ba tác vụ: dự đoán intent, trích chọn thực thể, và dự đoán masked token (Một token trong câu được mask ngẫu nhiên và quá trình huấn luyện mô hình phải cố gắng đoán được từ này, điều này giúp cho khoảng cách các từ gần nghĩa gần nhau hơn trên không gian số khi mô hình hội tụ). Dưới đây là sơ đồ trích từ bài báo:
![image.png]() Có thể thấy trong câu "I play ping pong", từ "pong" đã được masked và quá trình huấn luyện, mô hình sẽ dự đoán từ được masked này. Dĩ nhiên, mất mát của mô hình sẽ bằng tổng ba hàm mất mát từ việc dự đoán ý định thực thể, trích xuất thực thể và dự đoán từ masked.
Có thể thấy trong câu "I play ping pong", từ "pong" đã được masked và quá trình huấn luyện, mô hình sẽ dự đoán từ được masked này. Dĩ nhiên, mất mát của mô hình sẽ bằng tổng ba hàm mất mát từ việc dự đoán ý định thực thể, trích xuất thực thể và dự đoán từ masked.
![image.png]() Trong đó, Li, Le, Lm lần lượt là hàm mất mát của việc xác định ý định, hàm mất mát của việc trích xuất thực thể, hàm mất mát của việc dự toán masked token
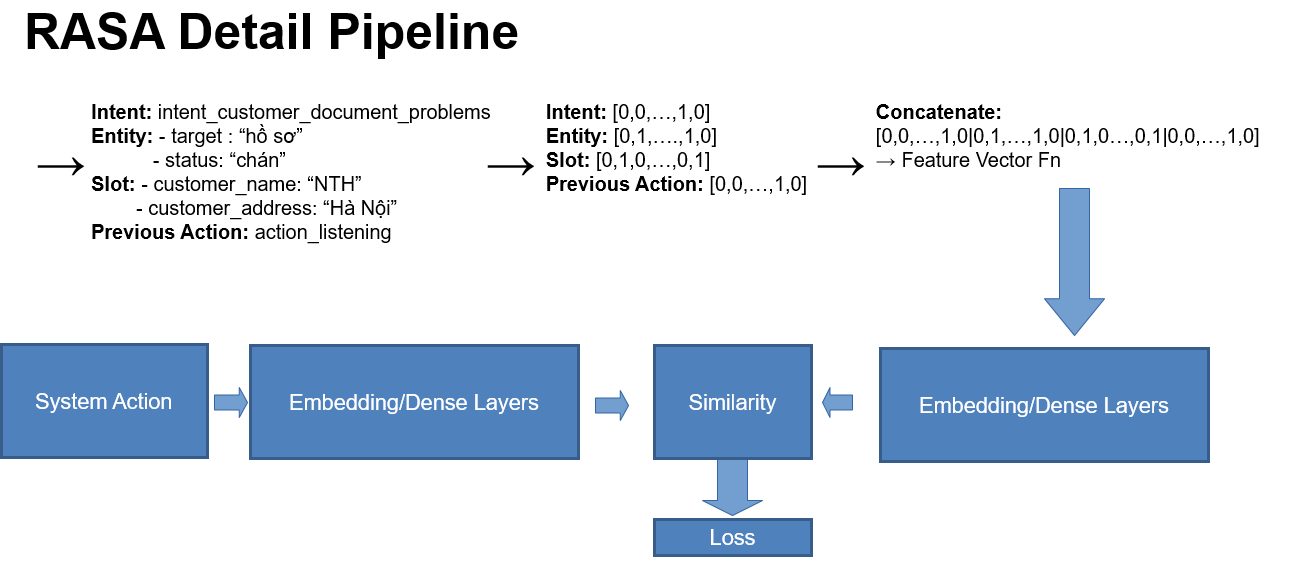
Trong đó, Li, Le, Lm lần lượt là hàm mất mát của việc xác định ý định, hàm mất mát của việc trích xuất thực thể, hàm mất mát của việc dự toán masked token - RegexEntityExtractor: Module này có thể thực hiện trước hoặc sau, giả sử ta cần lưu biến Status, Document Entity là trạng thái và thực thể trong hồ sơ được nhắc đến. Với ví dụ trên, ta thu được đầu ra lý tưởng với ý định là người dùng phản ánh hồ sơ có vấn đề (ta đặt là intent_document_problem) và các thực thể có giá trị là Document Entity: "Ảnh hồ sơ" và Status: "Mờ", các thực thể này được lưu trong các biến mà RASA gọi là Slot, và có thể truy cập lấy giá trị trong python bằng Tracker.
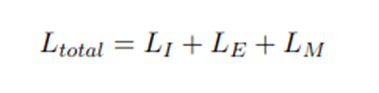
Như vậy, từ tin nhắn đầu vào, ta đã xác định được ý định và các thực thể có nhắc đến trong tin nhắn của người dùng. Giờ hãy xem RASA xử lý và lựa chọn đáp lại như thế nào?
RASA Core pipeline (Dialog Policies)
RASA Core xác định action nào được thực hiện để đáp lại câu hội thoại từ người dùng, action có thể là một câu thoại văn bản (Được định nghĩa cứng trong domain.yml) hoặc tính toán xử lý phức tạp hơn trước khi trả lời (VD: Yêu cầu tìm kiếm danh sách nhà hàng gần đây) (Action Server viết bằng python)
RASA Core chia luồng hội thoại dựa trên 3 chính sách đã nhắc đến ở phần trên: RulePolicy, MemoizationPolicy, TEDPolicy. Trong đó:
- RulePolicy: Sử dụng các rule để xác định hành động tiếp theo
- MemoizationPolicy: Sử dụng Story để xác định hành động tiếp theo
- TEDPolicy: Sử dụng kỹ thuật học sâu để xác định
Để sử dụng các Policy này, ta cấu hình trong tệp config.yml
 Vậy, có đến ba chính sách, RASA sẽ ưu tiên như thế nào?
RASA ưu tiên thực hiện chính sách để chọn hành động đáp lại người dùng theo thứ tự sau:
Vậy, có đến ba chính sách, RASA sẽ ưu tiên như thế nào?
RASA ưu tiên thực hiện chính sách để chọn hành động đáp lại người dùng theo thứ tự sau:
B1: Áp dụng RulePolicy nếu có Rule thỏa mãn ý định (Intent) vừa được xác định
B2: Nếu không có Rule thỏa mãn Intent vừa được xác định, áp dụng Story nếu có Story thỏa mãn ý định (Intent) đó.
B3: Nếu không có cả Rule và Story thỏa mãn ý định (Intent) vừa được xác định, sử dụng mô hình học sâu để lựa chọn hành động có khả năng nhất.
 Để hiểu hơn, hãy xem hình sau:
Để hiểu hơn, hãy xem hình sau:
 Cột bên phải là nội dung tệp
Cột bên phải là nội dung tệp rules.yml và tệp stories.yml của chatbot.
- Kịch bản đầu tiên(Từ trên xuống): , ý định được xác định là
intent_greet, hệ thống sẽ tìm trong rule (RulePolicy) có rule nào định nghĩa action thực hiện ngay khi tìm ra được ý địnhintent_greet, do trong rule không có rule nào thực thi khi cóintent_greetnên hệ thống chuyển sang tìm trongstories.ymlthì thấy có storysad user pathcó luồng trả lời ý địnhintent_greetvới action làutter_greet, vậy action được xác định làutter_greet, hệ thống sẽ lấy nội dungutter_greetvà trả lời người dùng. - Kịch bản thứ hai: ý định được xác định là
intent_identify_bot, hệ thống tìm trong rule (RulePolicy) và thấy có rulebot identificationcó định nghĩa actionutter_iamabotđể trả lời với ý địnhintent_identify_bot, vậy action được xác định làutter_iamabot, hệ thống sẽ lấy nội dungutter_iamabotvà trả lời người dùng. Tương tự với kịch bản thứ ba
Bây giờ hãy xét đến ví dụ khác:

- Kịch bản đầu tiên: tương tự như 3 kịch bản trên, kịch bản này thỏa mãn MemoizationPolicy
- Kịch bản thứ hai: Hệ thống xác định ý định
intent_not_ok, trong rules.yml và stories.yml (cột bên phải) không thấy nội dung nào định nghĩa action trả lời cho ý địnhintent_not_ok, hệ thống sẽ sử dụng TEDPolicy để xác định action tiếp theo, và hệ thống xác định actionutter_iamabot(Câu trả lời này cũng không hợp tý nào nên confident score là 0.24)
Vậy TEDPolicy là gì?
TEDPolicy là chính sách dựa trên kỹ thuật học sâu để xác định action tiếp theo. Mô hình học sâu ở đây có tên gọi Dialog Transformers được nhóm nghiên cứu của RASA thực hiện, mô hình tính toán véc-tơ đặc trưng của tin nhắn đầu vào kèm theo các tin nhắn từ các đoạn hội thoại trước và các thực thể được trích xuất trong tin nhắn đầu vào, sau đó tính toán véc-tơ đặc trưng cho từng action trong tập action định nghĩa từ trước. Cuối cùng, mô hình tính giá trị tương đồng bằng giá trị Cosine Similarity.
Ở đây mình sẽ lấy ví dụ trên sơ đồ mình tự vẽ, mình sẽ không giải thích sâu vì bài sẽ dài, nếu các bạn có nhu cầu mình sẽ đính kèm tài liệu tham khảo để nghiên cứu thêm.
 Như hình trên, sau khi trích chọn được véc-tơ từ các ý định, thực thể, slot, véc-tơ được đưa vào mô hình để trích chọn véc-tơ đặc trưng và tính toán độ tương đồng với véc-tơ đặc trưng của từng action trong tập action của chatbot
Như hình trên, sau khi trích chọn được véc-tơ từ các ý định, thực thể, slot, véc-tơ được đưa vào mô hình để trích chọn véc-tơ đặc trưng và tính toán độ tương đồng với véc-tơ đặc trưng của từng action trong tập action của chatbot
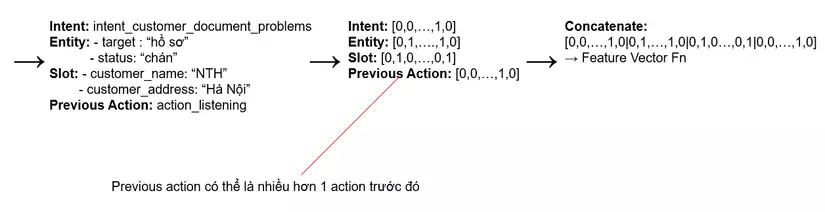
 Số lượng action của các bước hội thoại trước được đưa vào mô hình tùy thuộc vào giá trị của
Số lượng action của các bước hội thoại trước được đưa vào mô hình tùy thuộc vào giá trị của max_history khi cấu hình TEDPolicy trong config.yml
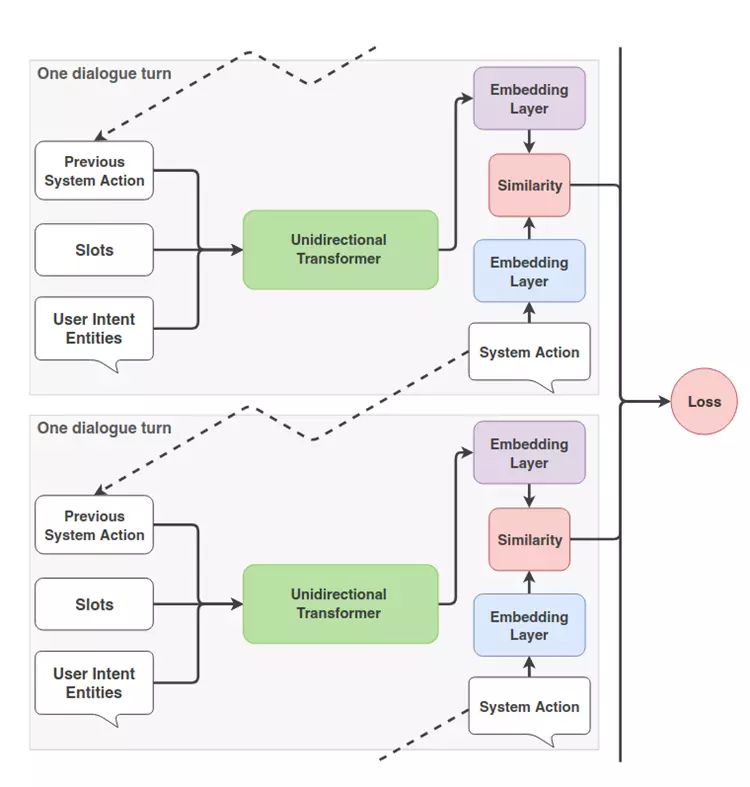
 Sơ đồ của nhóm tác giả trong bài báo Dialog Transformer:
Sơ đồ của nhóm tác giả trong bài báo Dialog Transformer:
 Rất hay phải không các bạn? Nhưng điều hay hơn của RASA, đấy là các bạn có thể customize lại được tất cả các module này, Tokenizer, Featurizer, Classifier, EntityExtractor và ... thậm chí cả Policy luôn. Các module này của RASA được xây dựng và lưu trữ theo cấu trúc rõ ràng, bạn cần tuân thủ theo cú pháp của RASA khi xây dựng các module này.
Rất hay phải không các bạn? Nhưng điều hay hơn của RASA, đấy là các bạn có thể customize lại được tất cả các module này, Tokenizer, Featurizer, Classifier, EntityExtractor và ... thậm chí cả Policy luôn. Các module này của RASA được xây dựng và lưu trữ theo cấu trúc rõ ràng, bạn cần tuân thủ theo cú pháp của RASA khi xây dựng các module này.
VD: Bạn tạo một Class thừa kế lớp rasa.core.policies, tuân theo quy tắc đặt tên và các phương thức của một lớp xây dựng nên một Policy và sau cùng là thêm chúng vào config.yml
Hoặc bạn muốn tạo một Tokenizer cho tiếng Việt, VietnameseTokenizer thay cho WhitespaceTokenizer không phù hợp với tiếng Việt,... đều khả thi với RASA.
(Mình sẽ không viết chi tiết ở đây do tập trung vào vấn đề phân tích cấu trúc)
Tương lai nào cho RASA?
Giữa sự phát triển vũ bão của AI, sự ra đời của ChatGPT cùng với rất nhiều các chatbot thông minh khác dựa trên mô hình ngôn ngữ lớn (LLM), kiến trúc và cách phát triển của RASA liệu có còn phù hợp? Bản thân đội ngũ RASA cũng đã thích ứng rất nhanh, tận dụng khả năng open source và có thể customize mạnh mẽ của mình, nhóm nghiên cứu của RASA đang phát triển các mô hình Generative AI và phương pháp để tận dụng chúng trong RASA Framework, hứa hẹn một tương lại chúng ta có thể biến một mô hình chatbot mạnh mẽ như ChatGPT thành mô hình phục vụ cho các tác vụ cụ thể của bản thân, cơ quan và tổ chức doanh nghiệp. Nhưng trước hết, chúng ta phải hiểu thật rõ mô hình đang được xây dựng để có thể tiếp nhận những sự đổi mới mạnh mẽ hơn và áp dụng chúng hiệu quả hơn.
Tổng kết
RASA là framework rất mạnh mẽ cho phát triển chatbot, ngay cả với người mới chưa từng có kinh nghiệm qua lĩnh vực Conversational AI hoặc lập trình, có thể hoạt động tốt với lượng dữ liệu ít. Tuy nhiên, để chatbot RASA thực hiện được những bài toán khó, đòi hỏi chúng ta phải nắm rõ, hiểu rõ từng thành phần để xây dựng hoặc điều chỉnh lại theo mục đích sử dụng riêng.
Tài liệu tham khảo
DIET Classifier:
https://medium.com/the-research-nest/using-the-diet-classifier-for-intent-classification-in-dialogue-489c76e62804
Introduction to DIET: SOTA Architecture outperform fine-tuning BERT.
https://rasa.com/blog/introducing-dual-intent-and-entity-transformer-diet-state-of-the-art-performance-on-a-lightweight-architecture/
DIET Classifier Explained:
https://blog.marvik.ai/2022/06/23/nlp-transformer-diet-explained/
NLU Pipeline:
https://rasa.com/blog/intents-entities-understanding-the-rasa-nlu-pipeline/
ARXIV DIET Classifier Paper:
https://arxiv.org/pdf/2004.09936.pdf
NLU Pipeline RASA 3.0:
https://rasa.com/blog/bending-the-ml-pipeline-in-rasa-3-0/
Dialog Policy:
https://rasa.com/blog/dialogue-policies-rasa-2/
ARXIV RASA Dialog Transformers:
https://arxiv.org/pdf/1910.00486.pdf
ResponseSelector in RASA:
https://rasa.com/blog/response-retrieval-models/
All rights reserved
