Token AI là gì? Đơn vị dữ liệu và cửa sổ ngữ cảnh của AI
Mỗi khi bạn gõ một câu hỏi cho ChatGPT hay Claude, mô hình không đọc chữ cái hay từ ngữ theo cách con người vẫn đọc. Nó đọc token.
Token AI là đơn vị dữ liệu nhỏ nhất mà một mô hình ngôn ngữ đọc vào và viết ra — thường là một mảnh từ, đôi khi cả một từ ngắn, đôi khi chỉ là một dấu câu. Cửa sổ ngữ cảnh (context window) là giới hạn bộ nhớ đi kèm: tổng số token mà mô hình có thể giữ trong "đầu" cùng một lúc.
Nắm được hai đơn vị này là cách duy nhất để dự đoán chi phí, kiểm soát độ chính xác và hiểu vì sao AI đôi khi "quên" những gì bạn vừa nói.

Token trong AI là gì?
Token là "giao thức giao tiếp" duy nhất mà các mạng thần kinh nhân tạo thực sự xử lý. Thay vì đọc từng chữ cái hay cả câu, mô hình nhìn thế giới dữ liệu dưới dạng những mảnh đã mã hóa, mỗi mảnh mang một ID số. Từ chuỗi ID đó, nó học quy luật ngôn ngữ và dự đoán mảnh khả dĩ nhất tiếp theo.
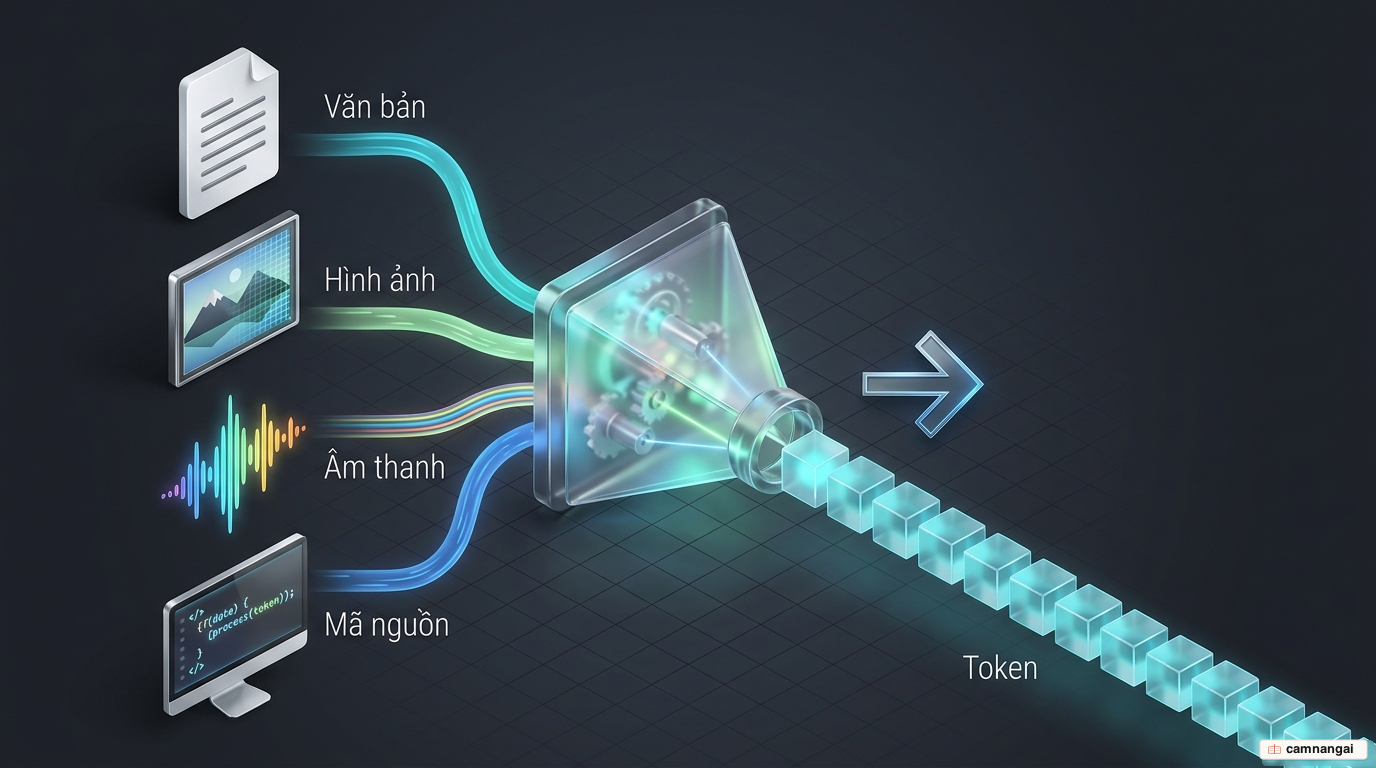
Một token thường là đơn vị cơ sở: một chữ cái, một từ, hoặc một cụm từ phổ biến. Các từ ngắn thông dụng thường gói gọn trong một token, còn từ phức tạp hoặc hiếm gặp sẽ bị chia nhỏ. Vài quy tắc ước lượng hữu ích cho tiếng Anh:
- 1 token ≈ 4 ký tự
- 1 token ≈ ¾ của một từ
- 100 token ≈ 75 từ
Nguyên lý này không giới hạn ở văn bản. Dữ liệu được chuyển thành token tùy theo hình thái: văn bản thành từ và cụm từ, hình ảnh thành pixel hoặc voxel, âm thanh thành phổ đồ (spectrogram), và mã nguồn thành các đoạn cú pháp. Về bản chất, suy luận trên mọi loại dữ liệu đều quy về một việc: dự đoán token tiếp theo trong chuỗi.
Token cũng được phân loại theo chức năng. Token đầu vào và token đầu ra là các đơn vị truyền tải dữ liệu thông thường — lời nhắc của bạn đi vào, phản hồi của mô hình đi ra. Bên cạnh đó có token suy luận (reasoning token), xuất hiện trong các mô hình "tư duy lâu" (long thinking). Những mô hình này tạo ra một chuỗi suy nghĩ trung gian trước khi trả lời, và phần ẩn đó tiêu tốn rất nhiều tài nguyên — có thể cao gấp hơn 100 lần một lượt suy luận thông thường.
Vì sao điều này đáng quan tâm? Vì số lượng token không chỉ đo độ dài văn bản, nó đo khối lượng công việc mà bộ xử lý đồ họa (GPU) phải gánh để cho ra kết quả. Đếm được token là dự đoán được cả độ phức tạp lẫn chi phí của một tác vụ.
Quá trình chia nhỏ văn bản (tokenization) hoạt động thế nào?
Tokenization là bước tiền xử lý bắt buộc, biến ngôn ngữ phi cấu trúc thành định dạng số học mà mạng thần kinh có thể "tiêu hóa". Nó diễn ra trước khi mô hình tính toán bất cứ điều gì.

Bộ mã hóa quét văn bản và cắt theo dấu cách, dấu câu. Phương pháp phổ biến nhất là Byte Pair Encoding (BPE), được ưa chuộng vì cân bằng tốt giữa tính linh hoạt và hiệu suất: từ hiếm được tách thành các từ con thông dụng, còn từ phổ biến vẫn giữ nguyên một khối. Ví dụ, "darkness" được tách thành "dark" + "ness". Nhờ vậy mô hình nhận ra "darkness" và "brightness" cùng chung hậu tố "ness", và tự suy ra ý nghĩa của những từ chưa từng gặp dựa trên cấu trúc thành phần — không cần ai "dạy" rằng "ness" nghĩa là trạng thái.
Sau khi mỗi token nhận một ID số riêng, mô hình chuyển chúng thành các vectơ nhúng (embedding). Những vectơ này biểu diễn quan hệ ngữ nghĩa trong một không gian nhiều chiều, cho phép mô hình tính "khoảng cách" giữa các khái niệm thay vì thao tác trên ký tự thô. Token đầu vào được nén thành vectơ để xử lý, rồi token đầu ra được giải nén ngược lại thành ngôn ngữ tự nhiên mà bạn đọc được.
Tại sao token lại quan trọng với chi phí và hiệu suất?
Trong các "nhà máy AI" hiện đại, token vừa là đơn vị kỹ thuật vừa là đơn vị tiền tệ. Các nhà cung cấp như OpenAI hay Anthropic thương mại hóa mô hình dựa trên số token tiêu thụ, nên tối ưu token chính là trung tâm của bài toán quản trị tài nguyên.
Đòn bẩy ở đây rất lớn. Việc tối ưu phần mềm cộng với phần cứng thế hệ mới có thể kéo chi phí mỗi token xuống tới 20 lần, và một số trường hợp thực tế ghi nhận doanh thu tăng gấp 25 lần chỉ trong bốn tuần nhờ cải thiện tốc độ xử lý token. Hai chỉ số thường dùng để đo trải nghiệm là thời gian đến token đầu tiên (Time to First Token) — độ trễ trước khi AI bắt đầu phản hồi — và độ trễ giữa các token (inter-token latency) — tốc độ bung ra những token tiếp theo.
Luôn có sự đánh đổi giữa chất lượng và tốc độ. Mô hình suy luận sâu tạo ra token "thông minh" hơn nhưng độ trễ cao hơn và đắt hơn nhiều. Công việc của người dùng — và của kỹ sư — là cân bằng giữa chi phí xử lý và giá trị thực mà mỗi token mang lại.
Cửa sổ ngữ cảnh là gì và hoạt động ra sao?
Cửa sổ ngữ cảnh (context window) là "bộ nhớ làm việc" của mô hình: số token tối đa — gồm cả lời nhắc hiện tại lẫn lịch sử trò chuyện — mà nó có thể xét đến cùng một lúc để tạo ra phản hồi mạch lạc.

Khi tổng token (cả đầu vào và đầu ra) vượt quá giới hạn, hệ thống áp dụng nguyên tắc FIFO (vào trước, ra trước): các token cũ nhất bị đẩy ra ngoài để nhường chỗ. Đây chính là lý do AI có vẻ "quên" những chỉ dẫn ở đầu cuộc hội thoại — chúng đã bị đẩy khỏi cửa sổ trước khi mô hình đọc tin nhắn mới nhất của bạn.
Kích thước cửa sổ thay đổi rất nhiều giữa các kiến trúc. Vài con số minh họa kinh điển:
| Mô hình | Kích thước cửa sổ ngữ cảnh (token) |
|---|---|
| BERT | 512 |
| GPT-3.5 | 4.000 (4K) |
| GPT-4 | 8.000 – 32.000 (8K–32K) |
| Claude | 100.000 (100K) |
Các con số trên phản ánh một thế hệ mô hình trước; những bản mới nhất đã đẩy giới hạn lên hàng trăm nghìn, thậm chí hàng triệu token. Nhưng quy luật vẫn không đổi: cửa sổ càng rộng, AI càng tóm tắt được tài liệu khổng lồ hay xử lý tác vụ nghiên cứu phức tạp — đổi lại độ nhiễu tăng theo, đòi hỏi quản lý bộ nhớ thông minh hơn để mô hình không bị phân tán.
Làm thế nào để dùng token hiệu quả?
Tối ưu token không chỉ để tiết kiệm tiền. Nó còn nâng độ chính xác bằng cách dọn bớt "rác" ngôn ngữ trước khi mô hình phải bận tâm đến.
- Viết lời nhắc cô đọng. Tập trung vào từ khóa mang giá trị, cắt các cụm thừa thãi và sự lặp lại để dành tối đa không gian cho những token quan trọng.
- Chia nhỏ tài liệu (chunking). Tách văn bản dài thành các đoạn có liên kết ngữ cảnh, xử lý từng phần thay vì nhồi tất cả vào một lần gọi làm tràn bộ nhớ làm việc.
- Quản lý ưu tiên. Lọc bỏ phần lịch sử hội thoại không còn cần thiết, chỉ giữ lại thông tin then chốt cho logic của phản hồi kế tiếp.
Bản chất của việc này là cải thiện tỷ lệ tín hiệu trên nhiễu (signal-to-noise ratio). Càng ít token rác được nạp vào, mô hình càng ít bị phân tán sự chú ý (attention drift), và câu trả lời càng chính xác, đi thẳng vào vấn đề.
Những hạn chế và thách thức hiện nay là gì?
Tokenization là một phép xấp xỉ toán học về ngôn ngữ, không phải sự thấu hiểu thật sự — và vì thế nó mang sẵn vài lỗi cố hữu.
- Mơ hồ ngữ nghĩa. Những từ đa nghĩa như "lie" (nằm / nói dối) hay "play" (chơi / vở kịch) có thể bị gán sai vectơ khi ngữ cảnh quá hẹp, dẫn đến lỗi logic trong phản hồi.
- Ngôn ngữ không có dấu cách. Với tiếng Trung hay tiếng Nhật, việc xác định ranh giới token cực kỳ khó. Từ "hot dog" (热狗) nếu bị tách nhầm thành "nóng" (热) và "chó" (狗) sẽ mất sạch ý nghĩa gốc.
- Các trường hợp đặc biệt. URL, email, mã nguồn hay số điện thoại thường bị băm thành những mảnh vô nghĩa, vừa tốn token một cách lãng phí vừa kéo độ chính xác đi xuống.
Cần nhớ rằng AI không hiểu "từ ngữ" — nó thao tác trên các mẫu xác suất số học. Mọi sai sót trong khâu tokenization đều có thể dẫn đến "ảo giác" (hallucination) hoặc lỗi suy luận mà người dùng khó nhận ra.
Điểm chính
- Token là đơn vị cơ bản như một phân đoạn từ — không nhất thiết tương đương một từ nguyên vẹn, và cũng dùng cho ảnh, âm thanh, mã nguồn.
- Cửa sổ ngữ cảnh quyết định dung lượng bộ nhớ làm việc và khả năng duy trì mạch hội thoại của AI; vượt giới hạn là AI bắt đầu quên.
- Tối ưu token giúp giảm chi phí đáng kể và cải thiện tỷ lệ tín hiệu trên nhiễu, nên câu trả lời chính xác và đi thẳng vào vấn đề hơn.
- Các mô hình suy luận sâu có thể tiêu tốn gấp 100 lần tài nguyên tính toán cho mỗi câu lệnh so với một lượt suy luận thông thường.
Tài liệu tham khảo
- What Are AI Tokens? The Language and Currency Powering Modern AI — NVIDIA Blog
- What are AI Tokens? — Microsoft Copilot
- Tokens in AI — Understand how AI thinks — nLighten
Bài viết được đăng lần đầu trên camnangai.com.
All rights reserved
