Tối ưu hóa việc sử dụng ArrayMap và SparseArray trong ứng dụng Android
Bài đăng này đã không được cập nhật trong 4 năm
Trong nội dung bài viết này, tôi sẽ đưa ra tại sao và khi nào để sử dụng ArrayMap và SparseArray để tối ưu trong ứng dụng Android
Bất cứ khi nào bạn cần lưu trữ Key -> value pairs, cấu trúc dữ liệu mà chúng ta nghĩ đến đầu tiên thường là HashMap. Hashmap khá linh hoạt, vì vậy nó có thể được sử dụng ở mọi nơi mà không thực sự cần quan tâm đến các tác dụng phụ của nó.
Một ví dụ về việc sử dụng Hashmap ở mọi nơi trong việc phát triển ứng điển hình như trong Android Studio, nó sẽ đưa ra nhưng cảnh báo rằng bạn nên sử dụng ArrayMap để thay thế Hashmap
OK giờ chúng ta sẽ cùng khám phá khi nào bạn nên xem xét để sử dụng ArrayMap và tìm hiểu xem cách thức chúng hoạt động như thế nào
HashMap và ArrayMap
HashMap nằm trong gói java.utils.HashMap
ArrayMap nằm trong gói android.support.v4.util.ArrayMap. Nó nằm trong gói support.v4 để có thể cung cấp và hỗ trợ những phiên bản android version thấp hơn
Video này từ Android Developers Channel có nói rất chi tiết, bạn có thể tham khảo thêm ở đây.
ArrayMap là một collection generic key -> value để mapping dữ liệu được thiết kế nhằm tối ưu hóa bộ nhớ hơn là cách truyền thống HashMap
ArrayMap giữ ánh xạ của nó trọng một cấu trúc mảng dữ liệu - là 1 mảng số nguyên là mã băm của mỗi item, và một mảng đối tượng của key -> value. Điều này cho phép nó tránh việc cần thiết phải tạo ra thêm đối tượng mỗi khi thêm một entries vào map. Nó cũng kiếm soát kích thước của mảng tích cực hơn, vì việc phát triển chúng chỉ cần sao chép các entries trong mảng - không phải xây dựng lại bảng mã băm
Lưu ý, không dùng ArrayMap cho cấu trúc dữ liệu có số lượng lưu trữ lớn. Nó thường chậm hơn so vs HashMap truyền thống, từ việc nó dùng thuật toán tìm kiếm nhị phân để tra cứu. Thêm và xóa yêu cầu phải chèn và xóa các mảng entries Đối với tập lưu trữ lên đến hằng trăm phần tử thì sự khác biệt về hiệu suất là < 50%, theo tôi thì đó là con số không đáng kể
HashMap
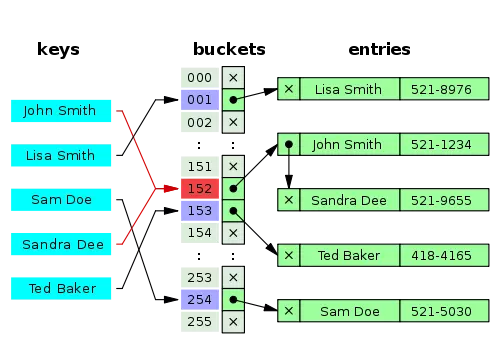
HashMap là một mảng cơ bản của đối tượng HashMap.Entry Tại high level, thể hiện của lớp Entry là:
- key không phải là dữ liệu nguyên thủy
- value không phải là dữ liệu nguyên thủy
- có chứa mã băm của đối tượng
- có con trỏ đến Entry tiếp theo
Điều gì sẽ xảy ra khi key -> value khi được chèn thêm vào trong HashMap
- Mã băm (hashcode) của các key được tính toán và giá trị được gán cho biến hashcode trong class Entry đó
- Sau đó, sử dụng hashcode, chúng ta lấy ra chỉ sổ của vùng chứa nơi chúng được lưu trữ
- Nếu vùng chứa chứa element tồn tại trước đó, thì những element mới sẽ được chèn vào cuối và được trỏ đến bởi element trước nó, về cơ bản nó tạo ra một danh sách liên kết giữa các vùng lưu trữ
Khi truy vấn trong HashMap để lấy value cho key tương ứng sẽ có độ phức tạp O(1) Nhưng điều quan trọng nhất đó là nó mang lại sự tối ưu cho bộ nhớ Nhược điểm:
- Autoboxing : đối tượng phụ được tạo mỗi khi chèn dữ liệu vào.Gây ảnh hưởng đến việc sử dụng bộ nhớ và vấn đề thu gom rác *Các đối tương HashMap.Entry bản thân chúng lại có thêm 1 lớp các đối tượng được tạo ra và được thu gom bở bộ dọn rác
- Vùng lưu trữ được sắp xếp lại mỗi lần HashMap thu hẹp hay mở rộng ra. Điều đó gây khá tốn giảm hiệu suất nhất là với số lượng lưu trữ lớn
Trong Android, vấn đề về bộ nhớ được nói đến rất nhiều khi ở những ứng dụng liên quan đến responsive . Phân bổ liên tục và tái phân bổ bộ nhớ cũng với bộ dón rác sẽ dẫn đến việc chậm trong ứng dụng của bạn Ghi nhớ - bộ thu gôm rác sẽ khiến bạn phải trả giá về hiệu suất ứng dụng. Khi bộ dọn rác chạy thì ứng dụng của bạn không thể chạy, thay vào đó ứng dụng sẽ bị giật, chậm...
ArrayMap
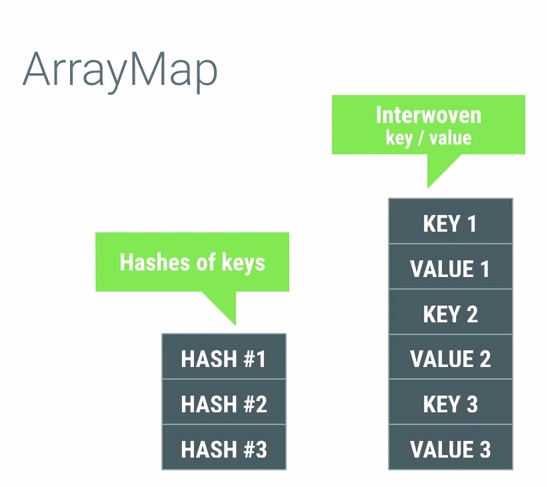
ArrayMap sử dụng 2 mảng. Nó sử dụng mảng Object[ ] mArray để lưu trữ các đối tượng còn int[ ] mHashesđể lưu trữ các hashcode. Khi key -> value được chèn vào thì:
- key -> value được autoboxed
- key của đối tượng được chèn vào vị trí khá dụng kế tiếp trong mArray[ ]
- value được chèn vào ngay sau vị trí key của nó trong mang mArray[ ]
- Hashcode của key được tính toán và lưu ở mảng mHashes[ ] tại ví trí khá dụng kế tiếp
Khi bạn lấy giá trị theo key thì:
- Hashcode của key sẽ được tính toán
- Tìm kiếm nhị phân để tìm mã hashcode có độ phức tạp O(logN)
- Khi mà có đc chỉ số của hashcode là index chúng ta sẽ suy ra ngay vị trị của key là 2*index trong mArray và vị trí của value là 2 * index +1
- Độ phức tạp tăng từ O(1) to O(logN) nhưng bộ nhớ được sử dụng hiệu quả. Bất cứ khi nào làm việc với tầm 100 bản ghi thì ứng dụng hầu như là không giật. Bằng cách này bạn đang sử dụng bộ nhớ hiệu quả hơn rồi đó.
Những cầu trúc dữ liệu khuyên dùng
- ArrayMap<K,V> in place of HashMap<K,V>
- ArraySet<K,V> in place of HashSet<K,V>
- SparseArray<V> in place of HashMap<Integer,V>
- SparseBooleanArray in place of HashMap<Integer,Boolean>
- SparseIntArray in place of HashMap<Integer,Integer>
- SparseLongArray in place of HashMap<Integer,Long>
- LongSparseArray<V> in place of HashMap<Long,V>
Mong rằng qua bài viết này mọi người có được sự lựa chọn hơp lí trong việc sử dụng HashMap, ArrayMap cũng như các collection khác sao cho tối ưu và hiệu quả nhất có thế
Nguồn Blog Mindorks
All rights reserved
