Tối ưu hoá hiệu năng Ruby
Bài đăng này đã không được cập nhật trong 6 năm
Chúng ta đều biết, Ruby là một trong những ngôn ngữ rất được yêu thích bởi vì giúp đơn giản hoá quá trình phát triển phần mềm, tuy nhiên, Ruby lại hay bị gắn liền với khái niệm chậm trong quá trình thực thi.
Đúng là bản Ruby 1.8 được phát hành năm 2003 thực sự chậm. Nhưng kể từ đấy, các nhà phát triển Ruby đã tích cực cải thiện hiệu năng của ngôn ngữ. Ruby 1.9 đã bổ sung máy ảo giúp thực thi code nhanh hơn. Ruby 2.0 đã tối ưu trình quản lý bộ nhớ giúp phát triển ứng dụng web lớn một cách nhanh chóng. Và cuối cùng, nhờ có sự cố gắng hết mình của Koichi Sasada, Ruby đã có sự cải tiến vượt bậc với bộ thu dọn rác trong phiên bản 2.1 và 2.2. Những nỗ lực này vẫn đang tiếp tục và hiệu năng trở thành một trong những mục tiêu đầu tiên cho từng phiên bản mới.
Seri bài viết này sẽ dựa theo cuốn sách Ruby Performance Optimization giúp cho chúng ta có cái nhìn tổng quan hơn về vấn đề hiệu năng trong Ruby, tại sao Ruby lại chậm và cách để tối ưu khi sử dụng Ruby cho việc phát triển phần mềm.
Điều gì làm cho Ruby nhanh
Khi xây dựng 1 ứng dụng mà thời gian tải quá lâu, hay khách hàng phản hồi hiệu năng chậm, thì chúng ta bắt đầu vào quá trình tối ưu hoá. Và khi đấy, chúng ta sẽ tự hỏi cần làm những gì để code chạy nhanh hơn?
Là một lập trình viên Ruby, khi được hỏi, thì tôi chắc chắn là đa số các lập trình viên sẽ trả lời là Tôi không biết? khi được hỏi như thế. Bởi vì, đơn thuần chúng ta đều nghĩ là chúng ta đã viết code hiệu quả rồi, và những gì làm sau đó là bỏ qua quá trình tối ưu hoá, đẩy hết vào cache và scale. Bởi vì chúng ta không biết cải thiện như thế nào, tại sao lại như thế, trong suy nghĩ luôn nghĩ tới việc tối ưu hoá rất vất vả. Nhưng, trong hầu hết trường hợp, chỉ cần một vài công cụ hỗ trợ hay sửa vài dòng code, thì code chúng ta đã chạy nhanh hơn rất nhiều.
Thêm nữa, không thể sử dụng mãi cache và scale để cải thiện hiệu năng được. Cache và scale cũng sẽ có giới hạn. Giả sử, khi ta muốn tăng tốc độ hệ thống, ta sẽ thực hiện scale, chia nhỏ nhiều service ra thành nhiều server, sử dụng load balance, cung cấp nhiều server cho 1 app. Tuy nhiên, khi hệ thống mở rộng, hay thêm tính năng mới, ta lại tiếp tục thêm server, nếu vậy thì chi phí sẽ càng ngày tăng thêm. Server cache thì cũng có giới hạn. Nếu như bất cứ cái gì cũng đẩy vào cache thì tới một lúc nào đấy server cache cũng đầy. Từ đây, chúng ta cần tiếp cận cách giải quyết vấn đề performance theo hướng khác.
Cái gì làm cho code Ruby chậm
Để có thể tìm ra cách làm cho code Ruby nhanh, thì trước hết, chúng ta cần làm rõ cái gì làm cho code Ruby chậm
Thông thường, suy nghĩ đầu tiên là code sử dụng quá thuật toán phức tạp: extra nested loop, tính toán, sắp xếp. Và những gì bạn cần làm để sửa vấn đề này? chỉ cần đánh giá, tìm ra chỗ gây chậm, và sử dụng thuật toán tối ưu hơn. Cứ lặp đi lặp lại quá trình này tới khi chạy nhanh. Điều này thông thường có vẻ đúng, tuy nhiên lại không hoạt động tốt cho code Ruby. Thuật toán phức tạp có thể gây ra một phần vấn đề của hiệu năng. Nhưng với Ruby, có nguyên nhân khác lớn hơn.
VD với một chương trình đơn giản sinh dữ liệu cho file CSV
require "benchmark"
num_rows = 100000
num_cols = 10
data = Array.new(num_rows) { Array.new(num_cols) { "x"*1000 } }
time = Benchmark.realtime do
csv = data.map { |row| row.join(",") }.join("\n")
end
puts time.round(2)
Chúng ta sẽ tạm thời chạy với các phiên bản Ruby 1.8.7, 1.9.3, 2.0, 2.1, và 2.2, mỗi phiên bản sẽ có các đặc điểm hiệu năng khác nhau. Ruby 1.8 được coi là chậm nhất và lâu đời nhất, với kiến trúc thông dịch và thực thi khác nhau. Ruby 1.9.3 và 2.0 có cùng dòng thời gian phát hành với hiệu năng tương đương nhau. Ruby 2.1 và 2.2 là các version được phát triển hướng tới cải thiện performance.
Chúng ta có kết quả sau:

Ta thấy Ruby 2.1 và 2.2 đã được cải thiện khá nhiều, nhưng thực tế vẫn chậm. 10000 bản ghi mà mất tới hơn 2 giây.
Hãy cùng tìm hiểu, trước tiên là về thuật toán. Bài toán chúng ta sử dụng là dùng thuật toán O(n m), không có vấn đề gì. Vậy chúng ta có thể tối ưu cái gì? Thử tắt chức năng garbage collection bằng cách thêm lệnh GC.disable
require "benchmark"
num_rows = 100000
num_cols = 10
data = Array.new(num_rows) { Array.new(num_cols) { "x"*1000 } }
GC.disable
time = Benchmark.realtime do
csv = data.map { |row| row.join(",") }.join("\n") end
puts time.round(2)
Kết quả đạt được thật bất ngờ:
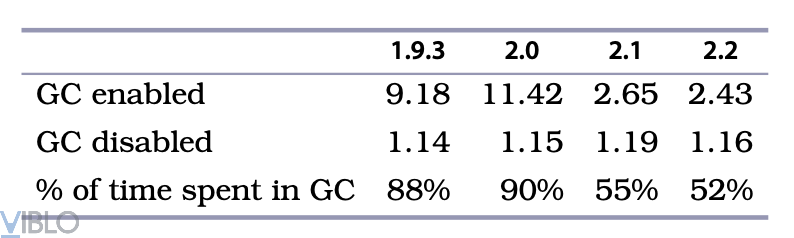
Chúng ta có thể thấy rõ, thời gian chủ yếu là chạy GC(garbage collection), trong khi thực thi code ở các phiên bản khác nhau là gần tương đương. Mặc dù phiên bản Ruby 2.1 đã được cải thiện thời gian GC, nhưng việc chiếm hơn 50% thời gian thực thi thì vẫn là quá lớn.
Vậy điều gì xảy ra với Ruby GC, có phải do code sử dụng quá nhiều bộ nhớ? hay chính Ruby GC quá chậm? câu trả lời là cả 2 điều đó. Việc sử dụng quá nhiều bộ nhớ là bản chất của Ruby. Bởi vì đó là ngôn ngữ thiết kế của Ruby. Mọi thứ đều là một đối tượng, nghĩa là chương trình cần một bộ nhớ đủ lớn để biểu diễn toàn bộ dữ liệu như là các đối tượng Ruby. Ngoài ra, GC chạy chậm cũng là một vấn đề có từ lâu của Ruby. Nó sử dụng thuật toán được đánh giá là chậm nhất trong các thuật toán thu dọn rác, nó dùng tư tưởng mark-and-sweep, stop-the-world ( nghĩa là đánh dấu và dọn dẹp, cùng với dừng mọi thứ lại ). Thêm nữa là khi GC chạy thì ứng dụng cũng phải dừng lại. Điều đó dẫn tới tại sao ứng dụng lại mất nhiều thời gian bị đóng băng trong quá trình chạy.
Phiên bản Ruby 2.1 và 2.2 được cải thiện hơn so với các phiên bản trước chủ yếu là do bộ GC đã được cải thiện lại.
Vậy từ trên chúng ta có thắc mắc, tại sao GC lại tốn quá nhiều thời gian. Cụ thể là GC đã làm những gì? Chúng ta biết là càng tiêu thụ nhiều bộ nhớ, thì GC chạy càng lâu để hoàn thành quá trình dọn rac. Vậy có phải chăng là do đã phải cần khởi tạo quá nhiều bộ nhớ, chúng ta có thể biết được điều này bằng các hiển thị kích thước bộ nhớ trước và khi chạy benchmark. Bằng cách in ra RSS của tiến trình, nó sẽ hiển thị bộ nhớ của tiến trình trong RAM.
require "benchmark"
num_rows = 100000
num_cols = 10
data = Array.new(num_rows) { Array.new(num_cols) { "x"*1000 } }
puts "%d MB" % (`ps -o rss= -p #{Process.pid}`.to_i/1024)
GC.disable
time = Benchmark.realtime do
csv = data.map { |row| row.join(",") }.join("\n") end
puts "%d MB" % (`ps -o rss= -p #{Process.pid}`.to_i/1024) puts time.round(2)
Ta được kết quả:
$ ruby example_measure_memory.rb
1040 MB
2958 MB
Ta có thể thấy được, dữ liệu ban đầu là 1GB, nhưng lại tiêu tốn mất hơn 2 GB bộ nhớ cho việc xử lý 1 GB dữ liệu. Điều này thật kỳ lạ, tại sao chương trình cần 2 GB thay vì 1 GB bộ nhớ? Làm thế nào để khắc phục điều này? Có cách nào để cho chương trình sử dụng ít bộ nhớ hơn? Những câu hỏi này sẽ được giải đáp trong phần tới.
Tổng kết
- Bộ nhớ sử dụng và GC (trình dọn dẹp rác) là các nguyên nhân chính làm cho Ruby bị chậm.
- Ruby tiêu tốn bộ nhớ đáng kể.
- GC trong Ruby 2.1 và về sau đã nhanh hơn gấp 5 lần so với các phiên bản trước.
- Hiệu năng của tất cả các phiên bản trình biên dịch Ruby là giống nhau.
Tối ưu bộ nhớ
Sử dụng bộ nhớ lớn là điều làm cho Ruby chậm. Do đó, để tối ưu hoá, chúng ta cần giảm bớt dung lượng bộ nhớ. Trong phần này, chúng ta sẽ tìm hiểu cách để giảm bớt thời gian cho bộ xử lý dọn rác.
Đầu tiên, ta có thắc mắc, tại sao không dừng luôn GC, tại sao phải sử dụng nó. Đó thực sự là giải pháp hay, bởi vì thời gian tiêu tốn chủ yếu là do GC chạy. Tuy nhiên, xoá GC sẽ làm tăng dung lượng bộ nhớ tiêu thụ lên tới đỉnh. Khi đó, hệ điều hành sẽ bị tràn bộ nhớ hay cần bắt đầu dọn dẹp lại. Cả 2 kết quả đều làm cho hiệu năng chậm hơn rất nhiều so với để cho bộ GC của Ruby hoạt động.
Ta quay lại với VD trên, ta biết là chúng ta cần 2 GB bộ nhớ để xử lý 1 GB dữ liệu. Vì vậy, chúng ta chỉ ra bộ nhớ được sử dụng nhiều cho việc gì.
require "benchmark"
num_rows = 100000
num_cols = 10
data = Array.new(num_rows) { Array.new(num_cols) { "x"*1000 } }
time = Benchmark.realtime do csv = data.map do |row|
row.join(",") end.join("\n")
end
puts time.round(2)
CSV row mà chúng ta tạo ra trong block ngay lập tức kết quả được lưu vào bộ nhớ tới khi chúng ta thực hiện join chúng với kí tự dòng mới. Đó thực sự là nới mà sử dụng thêm 1 GB bộ nhớ.
Vậy, ta có thể viết lại theo cách khác mà không cần lưu trữ ngay kết quả. Ta có thể lặp qua các row và tiếp tục lặp qua các cột và lưu kết quả vào biến csv.
require "benchmark"
num_rows = 100000
num_cols = 10
data = Array.new(num_rows) { Array.new(num_cols) { "x"*1000 } }
time = Benchmark.realtime do csv = ''
num_rows.times do |i| num_cols.times do |j|
csv << data[i][j]
csv << "," unless j == num_cols - 1 end
csv << "\n" unless i == num_rows - 1 end
end
puts time.round(2)
Mặc dù code khá xấu, nhưng kết quả mang lại thực sự đáng kể:
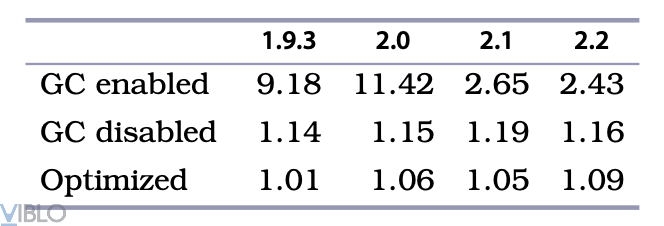
Chỉ cần một vài thay đổi đơn giản, chúng ta đã khắc phục được khuyết điểm của GC. Chương trình được tối ưu thậm chí nhanh hơn chương trình ban đầu mà không có GC. Và nếu bạn chạy phiên bản tối ưu mà đã disabled GC, bạn sẽ thấy thời gian cho GC chỉ chiếm 10% tổng số thời gian thực thi.
Bằng cách thay đổi đơn giản, chúng ta đã cải thiện hiệu năng từ 2.5 đến 10 lần. Vậy, chúng ta hãy xem kỹ code và suy nghĩ bao nhiêu bộ nhớ đã dùng cho mỗi dòng và hàm được gọi. Khi đó, ta sẽ biết được bộ nhớ bị khởi tạo quá nhiều ở đâu, hay sử dụng không hiệu quả ở chỗ nào để viết lại code cho phù hợp. Rất đơn giản, phải không?
Nhưng theo kinh nghiệm của tôi, không cần thiết phải tối ưu mọi thứ ngoài bộ nhớ. Theo nguyên tắc 80 - 20 của việc tối ưu hiệu năng trong Ruby là 80% của việc cải thiện hiệu năng đến từ việc tối ưu bộ nhớ, số còn lại 20% đến từ các thứ khác.
Hãy xem lại, suy nghĩ và viết lại. Có thể chúng nên nghĩ nhiều hơn. Nếu tối ưu bộ nhớ cần yêu cầu phải nghĩ lại code để làm gì, thì chúng ta cần thực sự nên nghĩ đến cái đó.
Tổng kết
- Luật 80 - 20 của việc tối ưu hiệu năng trong RUby: 80% của việc tối ưu hiệu năng đến từ tối ưu bộ nhớ, vì vậy cần tối ưu bộ nhớ đầu tiên.
- Một chương trình có bộ nhớ được tối ưu thì sẽ có hiệu năng tương đương với hầu hết các phiên bản Ruby mới.
Xây dựng Mind-set performance
Việc tối ưu hoá Ruby là cần phải nghĩ lại nhiều hơn về những code này là có mục đích gì hơn là tìm ra các điểm nghẽn với các công cụ đặc biệt. Kỹ năng chính cần học là cách nghĩ đúng về hiệu năng, hay còn gọi là Mind-set trong tối ưu hiệu năng Ruby.
Khi bạn viết code, cần luôn nghĩ đến số lượng bộ nhớ sử dụng và bộ dọn rác cần đến, bằng việc trả lời các câu hỏi:
- Ruby có phải là công cụ tốt nhất để giải quyết vấn đề
Ruby là ngôn ngữ lập trình cho các mục đích chung, nhưng không có nghĩa là có thể giải quyết được toàn bộ tất cả vấn đề. Có những thứ Ruby không tốt. VD, bài toán số nguyên tố cần xử lý một lượng dữ liệu cực lớn. Do đó cần bộ nhớ cũng rất lớn.
Hoặc task sẽ hoạt động hiệu quả trong database hay trong các tiến trình chạy nền được viết bởi các ngôn ngữ lập trình khác. VD, Twitter sử dụng Ruby on Rails để viết bên frontend và sử dụng Scala worker cho bên backend. Hoặc với các bài toán thống kê, tính toán, phân tích thì tốt hơn hết nên dùng ngôn ngữ R.
- Có bao nhiêu bộ nhớ mà code chúng ta sử dụng đến
Càng ít bộ nhớ phải dùng cho code bao nhiêu, thì GC sẽ càng ít việc phải làm bấy nhiêu. Có một vài thủ thuật để giảm bớt bộ nhớ tiêu thụ, có thể là xử lý dữ liệu theo từng dòng và tránh việc sử dụng qua các đối tượng. Chúng ta sẽ biết nhiều hơn thông qua các phần tiếp theo.
- Hiệu năng thực sự của code là gì
Ngay khi bạn chắc chắn là bộ nhớ đã được tối ưu, thì hãy bắt đầu tìm hiểu đến thuật toán mà code đang được dùng.
Với việc hỏi các câu hỏi này, bạn đã bắt đầu có được tư duy Mind-set hiệu năng khi code Ruby.
Trong phần tiếp theo, chúng ta sẽ đề cập đến các vấn đề hiệu năng hay gặp phải. Cảm ơn bạn đã theo dõi.
All rights reserved
