TML-Interaction-Small là gì? Thinking Machines Lab tái định nghĩa AI giọng nói với Interaction Model
Ra mắt như research preview ngày 13/5/2026, model đạt độ trễ chuyển lượt 0,40 giây và dẫn trước GPT-Realtime-2 tới 30 điểm trên benchmark đo tính tương tác, dù vẫn thua trên một số benchmark về trí tuệ thuần túy.
Tóm tắt các điểm chính
- Thinking Machines Lab gọi loại mô hình này là "Interaction Model": tính tương tác được huấn luyện trực tiếp vào mô hình, không phải lắp ghép từ bên ngoài
- TML-Interaction-Small có 276B tham số tổng cộng, 12B tham số hoạt động, kiến trúc Mixture-of-Experts, xử lý audio, video và text trong chu kỳ 200ms
- Độ trễ chuyển lượt 0,40 giây, nhanh nhất trong số các mô hình được so sánh (GPT-Realtime-2 ở mức tối thiểu: 1,18 giây)
- Trên FD-bench v1.5 đo tính tương tác, TML-Interaction-Small đạt 77,8 so với 46,8 của GPT-Realtime-2, khoảng cách 30 điểm
- Hiện chỉ trong limited research preview, chưa có giá công khai; Thinking Machines dự kiến mở rộng truy cập cuối 2026
Interaction Model là gì và tại sao nó khác với AI giọng nói thông thường?
Thinking Machines Lab định nghĩa Interaction Model là hệ thống mà tính tương tác là thuộc tính bên trong của mô hình, không phải lớp bổ sung bên ngoài. Nguyên tắc cốt lõi là: khả năng phản hồi và trí tuệ phải được huấn luyện cùng nhau từ đầu trên luồng audio và video liên tục, thay vì được ghép vào một mô hình văn bản sau khi đã xây dựng xong.
Phần lớn hệ thống AI giọng nói thời gian thực hiện nay ghép nối nhiều thành phần riêng biệt: bộ phát hiện hoạt động giọng nói, bộ mã hóa âm thanh độc lập và lớp quản lý hội thoại để giả lập sự phản hồi tự nhiên. Thinking Machines Lab lập luận rằng cách tiếp cận này sẽ luôn tụt hậu so với mô hình xử lý tương tác theo cách bản địa, vì ranh giới lượt thoại nhân tạo giới hạn những gì mô hình có thể làm.
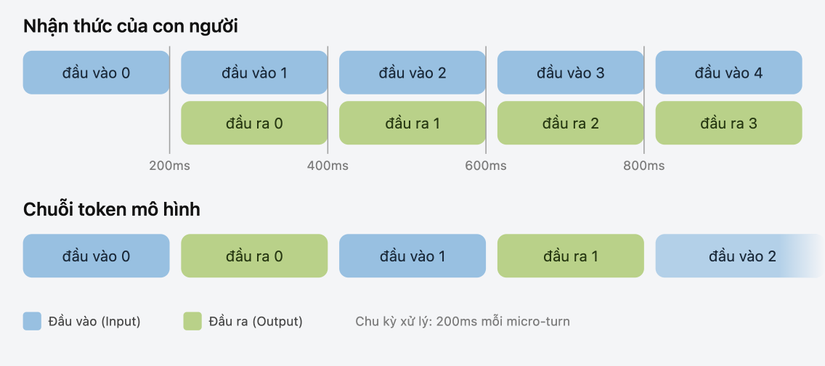
Thay vì tiêu thụ toàn bộ đầu vào rồi mới tạo ra phản hồi hoàn chỉnh, Interaction Model xử lý đầu vào và đầu ra như hai luồng song song, đan xen nhau trong mỗi chu kỳ 200 mili giây. Mô hình vừa nhận vừa phản hồi cùng một lúc, không chờ người nói kết thúc câu. Điều này mở ra ba khả năng mà mô hình luân phiên với lớp bổ sung bên ngoài không thể tái tạo: nói trong khi vẫn đang nghe, phản ứng với tín hiệu hình ảnh mà không cần được yêu cầu, và theo dõi thời gian đã trôi qua trực tiếp.
TML-Interaction-Small là gì?
TML-Interaction-Small là mô hình đầu tiên Thinking Machines Lab công bố ra công chúng và cũng là triển khai đầu tiên của kiến trúc Interaction Model. Model có 276B tham số tổng cộng với 12B tham số hoạt động, được huấn luyện từ đầu trên luồng audio và video liên tục theo thiết kế multi-stream micro-turn, trong đó đầu vào và đầu ra được xử lý theo từng khối 200 mili giây.
Bốn tính năng cốt lõi của TML-Interaction-Small
Nói và nghe đồng thời
TML-Interaction-Small có thể tạo ra lời nói trong khi người dùng vẫn đang nói. Điều này làm cho dịch thuật đồng thời trở nên khả thi: bạn nói bằng một ngôn ngữ và mô hình bắt đầu dịch trước khi bạn kết thúc câu. Nó cũng có thể ngắt lời giữa câu khi phát hiện lỗi, hoặc đưa ra tín hiệu xác nhận bằng lời ("được rồi," "tiếp đi") trong khi bạn vẫn đang giải thích. Một ví dụ trong release notes cho thấy mô hình tự động chuyển đổi số tiền EUR sang USD và thông báo ngay mỗi khi người dùng đề cập đến một khoản thanh toán, không cần được yêu cầu.
Nhận diện và phản ứng với video mà không cần được hỏi
TML-Interaction-Small xử lý video song song với audio và có thể tự khởi đầu lời nói dựa trên những gì nó nhìn thấy, không cần bất kỳ lệnh nào bằng giọng nói. Nếu bạn đang chống đẩy trước camera, nó có thể đếm số lần thực hiện thành tiếng ngay khi chúng xảy ra. Nếu một đối tượng liên quan xuất hiện trong luồng video, nó có thể gọi tên ngay tại thời điểm đó. Tuy nhiên, đây là tính năng vẫn còn cần cải thiện: điểm RepCount-A nội bộ cho thấy chỉ một phần ba số trường hợp (33,4%) có kết quả đếm sai không quá một lần. Đây là khả năng hoàn toàn không tồn tại trong GPT-Realtime-2 hay Gemini Live hiện nay, vì cả hai đều chỉ xử lý audio.
Xử lý tự nhiên khi người dùng ngắt lời hoặc tự sửa mình
Nếu bạn bắt đầu một câu, đổi ý và tự sửa giữa chừng, TML-Interaction-Small theo dõi sự điều chỉnh đó và phản hồi theo ý định thực sự của bạn. Mô hình xử lý được backchanneling (bạn nói "ừ" hay "đúng rồi" trong khi nó đang nói) và phân biệt được giữa người đang nói chuyện với nó so với người đang nói chuyện với người khác trong phòng. Đây là những tình huống khiến mô hình luân phiên thường xuyên hỏng: chúng hoặc dừng lại khi không nên, hoặc phản hồi nhầm phần của câu nói.
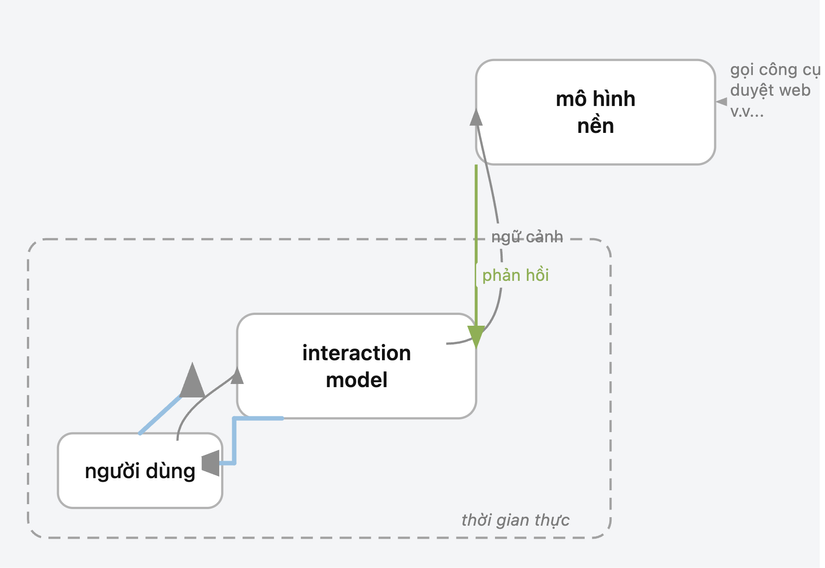
Chạy tác vụ phức tạp ở nền trong khi vẫn duy trì hội thoại
Mô hình nền là yếu tố làm cho Interaction Model không chỉ nhanh mà còn thông minh. Bạn có thể tiếp tục đặt câu hỏi theo dõi hoặc chuyển chủ đề trong khi tác vụ nền vẫn đang chạy. Khi kết quả sẵn sàng, mô hình đưa chúng vào hội thoại ở thời điểm tự nhiên thay vì ngắt quãng bằng một chuyển đổi ngữ cảnh đột ngột. Điều này có nghĩa bạn nhận được cả phản hồi hội thoại nhanh lẫn khả năng xử lý tác vụ nhiều bước mà thông thường đòi hỏi mô hình phải im lặng trong vài giây.
TML-Interaction-Small đạt kết quả benchmark như thế nào?
Thinking Machines công bố kết quả trên hai nhóm: benchmark streaming đo tính tương tác và benchmark turn-based đo trí tuệ. Kết quả mạnh nhất của mô hình nằm ở nhóm streaming, nơi các lựa chọn kiến trúc được kiểm tra trực tiếp nhất.
Tính tương tác: FD-bench v1.5
FD-bench v1.5 đưa ra audio được ghi sẵn và đo hành vi của mô hình trên bốn tình huống: người dùng ngắt lời, backchanneling, nói chuyện với người khác, và giọng nói nền. TML-Interaction-Small đạt 77,8, so với 54,3 của Gemini-3.1-flash-live-preview ở cài đặt tối thiểu và 46,8 của GPT-Realtime-2.0 ở cài đặt tối thiểu. Ngay cả GPT-Realtime-2.0 ở mức reasoning cao nhất (xhigh) cũng chỉ đạt 47,8.
Đây là benchmark đo trực tiếp nhất những gì Thinking Machines đang hướng đến. Khoảng cách 30 điểm so với đối thủ gần nhất không phải sự khác biệt nhỏ. Câu hỏi là liệu FD-bench v1.5 có nắm bắt được toàn bộ phạm vi tính tương tác quan trọng trong thực tế không, điều mà chính Thinking Machines thừa nhận vẫn còn là câu hỏi nghiên cứu mở.
Độ trễ chuyển lượt
TML-Interaction-Small đạt độ trễ chuyển lượt 0,40 giây trên FD-bench v1, nhanh nhất trong số các mô hình được so sánh. Gemini-3.1-flash-live-preview đứng gần nhất với 0,57 giây. Ngay cả ở cài đặt tối thiểu, GPT-Realtime-2.0 cần khoảng 1,18 giây, tức gấp ba lần. Ở mức reasoning cao nhất (xhigh), GPT-Realtime-2.0 đạt 1,63 giây.
Độ trễ quan trọng với tương tác giọng nói theo cách mà nó không quan trọng với văn bản. Khoảng cách 1,2 giây giữa lúc người dùng kết thúc câu và lúc mô hình bắt đầu phản hồi không chỉ cảm nhận được mà còn gây gián đoạn. Kết quả 0,40 giây đưa TML-Interaction-Small gần hơn với thời gian phản hồi hội thoại của con người.
Trí tuệ và tuân theo hướng dẫn
Audio MultiChallenge đo trí tuệ và khả năng tuân theo hướng dẫn trong audio. TML-Interaction-Small đạt 43,4%, cao hơn GPT-Realtime-1.5 (34,7%) và Gemini-3.1-flash-live-preview (26,8%), nhưng thấp hơn GPT-Realtime-2.0 ở xhigh (48.5%). Đây là benchmark nơi đánh đổi giữa tính tương tác và trí tuệ hiện rõ nhất.
Khoảng cách 5,1 điểm giữa TML-Interaction-Small và GPT-Realtime-2.0 xhigh là đáng kể nhưng không quá lớn, và nó đi kèm với chi phí độ trễ đáng kể ở phía GPT-Realtime-2.0 (1,63 giây so với 0,40 giây). Đánh đổi đó có đáng hay không phụ thuộc vào ứng dụng cụ thể.
Chất lượng phản hồi và gọi công cụ
FD-bench v3 đo chất lượng phản hồi và độ chính xác gọi công cụ trong tình huống audio kết hợp tools. TML-Interaction-Small đạt 82,8% chất lượng phản hồi và 68,0% pass@1 khi bật background agent, so với 80,0% / 52,0% của GPT-Realtime-2.0 ở cài đặt tối thiểu và 81,0% / 58,0% ở xhigh. Khoảng cách pass@1 (68,0% so với 58,0%) là con số có ý nghĩa nhất ở đây, vì nó đo lường liệu mô hình có thực sự hoàn thành đúng tác vụ phụ thuộc vào công cụ hay không. Kiến trúc kép tách biệt gọi công cụ khỏi tương tác người dùng có vẻ mang lại hiệu quả thực sự.
Các benchmark mới: TimeSpeak, CueSpeak và visual proactivity
Thinking Machines tạo ra hai benchmark nội bộ và điều chỉnh ba benchmark ít được dùng hơn để đo trực tiếp các khả năng tương tác. Đây là những benchmark cần xem xét cẩn thận vì không có mô hình cạnh tranh nào đạt kết quả có ý nghĩa trên bất kỳ cái nào trong số đó.
TimeSpeak (bắt đầu nói đúng thời điểm): TML-Interaction-Small đạt 64,7% macro-accuracy. CueSpeak (nói khi nhận tín hiệu lời): đạt 81,7% macro-accuracy. RepCount-A (đếm hành động qua hình ảnh): đạt 33,4% off-by-one accuracy. ProactiveVideoQA (nói khi nhận tín hiệu hình ảnh): đạt 31,5 PAUC, trong khi ngưỡng baseline không phản hồi là 25,0%. Charades temporal localization (định vị thời điểm hành động): đạt 30,4 mIoU.
Trên hầu hết các benchmark mới này, GPT-Realtime-2.0 hoàn toàn thất bại với điểm gần bằng không, hoặc bằng không trên Charades (yêu cầu mô hình nói "bắt đầu" và "kết thúc" đúng thời điểm trong video). Các benchmark này còn mới và chưa được xác nhận độc lập, nhưng nhìn chung phù hợp với bức tranh tổng thể về sự khác biệt kiến trúc.
Giá và cách truy cập TML-Interaction-Small
TML-Interaction-Small hiện đang trong limited research preview và chưa có thông tin giá. Thinking Machines dự kiến mở rộng truy cập vào cuối 2026. Nhà nghiên cứu và lập trình viên quan tâm có thể liên hệ qua interaction@thinkingmachines.ai để đăng ký quyền truy cập.
Để so sánh, GPT-Realtime-2 hiện tính phí 32 USD per 1M audio input token và 64 USD per 1M audio output token. Giá của TML-Interaction-Small nhiều khả năng sẽ được công bố cùng lúc với bản phát hành rộng hơn. Hậu tố "-Small" trong tên model gợi ý rõ ràng rằng Thinking Machines sẽ tiếp tục với các model lớn hơn, dù các model đó hiện vẫn chưa đủ tốc độ để triển khai thực tế.
TML-Interaction-Small so với GPT-Realtime-2: model nào phù hợp hơn?
| Benchmark | TML-Interaction-Small | GPT-Realtime-2.0 (minimal) | GPT-Realtime-2.0 (xhigh) | Gemini-3.1-flash-live (minimal) |
|---|---|---|---|---|
| FD-bench v1 · độ trễ chuyển lượt (giây) | 0,40 | 1,18 | 1,63 | 0,57 |
| FD-bench v1.5 trung bình | 77,8 | 46,8 | 47,8 | 54,3 |
| FD-bench v3 · chất lượng phản hồi (%) | 82,8* | 80,0 | 81,0 | 68,5 |
| Audio MultiChallenge APR (%) | 43,4 | 37,6 | 48,5 | 26,8 |
| BigBench Audio (%) | 75,7 / 96,5* | 71,8 | 96,6 | 71,3 |
| IFEval VoiceBench (%) | 82,1 | 81,7 | 83,2 | 67,6 |
| IFEval text (%) | 89,7 | 89,6 | 95,2 | 85,8 |
Khi bật background agent.
Khoảng cách thú vị hơn giữa hai model nằm ở benchmark tính tương tác. Trên FD-bench v1.5, TML-Interaction-Small dẫn 30 điểm so với GPT-Realtime-2.0 ở mọi mức cài đặt. Đây là benchmark đo trực tiếp nhất những gì Thinking Machines đang tối ưu hóa.
Có đánh đổi về trí tuệ, nhưng khoảng cách ở đây nhỏ hơn nhiều so với khoảng cách tương tác. GPT-Realtime-2.0 ở xhigh đạt 48,5% trên Audio MultiChallenge so với 43,4% của TML-Interaction-Small. Trên BigBench Audio, GPT-Realtime-2.0 ở mức reasoning cao đạt 96,6% so với 75,7% của TML-Interaction-Small khi không bật background agent, nhưng TML-Interaction-Small đạt 96,5% khi background agent được bật.
Bức tranh tổng thể: TML-Interaction-Small dẫn về khả năng phản hồi và tính tương tác, trong khi GPT-Realtime-2.0 ở cài đặt reasoning cao dẫn về benchmark trí tuệ thuần túy.
Kết luận
TML-Interaction-Small có nhiều triển vọng. Nếu sống đúng với những tuyên bố trong release notes, model mới mang lại tính tương tác được cải thiện đáng kể với độ trễ ngắn mà không hy sinh chất lượng phản hồi hay sức mạnh reasoning. Khả năng nói, nghe và phản ứng với tín hiệu hình ảnh đồng thời là độc nhất hiện nay và mở ra nhiều khả năng ứng dụng thực tế.
Khoảng cách về trí tuệ so với GPT-Realtime-2 có thực nhưng hẹp hơn nhiều so với khoảng cách về tính tương tác. Với ứng dụng cần cuộc hội thoại cảm thấy tự nhiên, khoảng cách độ trễ 0,40 giây so với 1,18 giây quan trọng hơn khoảng cách 5 điểm trên Audio MultiChallenge. Với ứng dụng ưu tiên độ chính xác trên tác vụ reasoning khó, GPT-Realtime-2.0 ở mức reasoning cao vẫn đứng đầu.
Nguồn: Infinity News — trang tin tức và phân tích chuyên sâu về khoa học, công nghệ, đời sống và kinh tế, mang đến góc nhìn liên ngành để thấu hiểu xu hướng hiện đại.
All rights reserved
