Tìm hiểu về Hadoop
Bài đăng này đã không được cập nhật trong 8 năm
Mở đầu
Có bao giờ bạn băn khoăn lượng dữ liệu của các công ty công nghệ lớn như Facebook, Amazon, Google, ... thu thập mỗi ngày và được xử lý như thế nào mà vẫn đảm bảo tốc độ truy cập một cách nhanh chóng và hiệu quả nhất.
Từ đấy chúng ta biết đến BIG DATA. Nó là thuật ngữ dùng để chỉ một tập hợp dữ liệu rất lớn và rất phức tạp đến nỗi những công cụ, ứng dụng xử lí dữ liệu truyền thống không thể nào đảm đương được. Tuy nhiên, Big Data lại chứa trong mình rất nhiều thông tin quý giá mà nếu trích xuất thành công, nó sẽ giúp rất nhiều cho việc kinh doanh, nghiên cứu khoa học, dự đoán các dịch bệnh sắp phát sinh và thậm chí là cả việc xác định điều kiện giao thông theo thời gian thực.
Hiện nay việc xử lý BIG DATA đang một trong những ưu tiên hàng đầu của các công ty công nghệ trên toàn thế giới. Nên những framwork giúp việc xử lý BIG DATA cũng đang ngày càng được chú ý và phát triển mạnh.
Bài viết này sẽ giới thiệu về Hadoop, một trong các công nghệ cốt lõi cho việc lưu trữ và truy cập số lượng lớn dữ liệu.
Hadoop là gì?
Hadoop là một framwork giúp lưu trữ và xử lý Big Data áp dụng MapReduce. Nói đơn giản cách khác nó sẽ giúp sắp xếp dữ liệu sao cho user có thể dễ dàng sử dụng nhất.
MapReduce được Google tạo ra ban đầu để xử lý đống dữ liệu lớn của công ty họ. Ta còn có thể gọi phương pháp này là Phân tán dữ liệu vì nó tách hết tập hợp các dữ liệu ban đầu thành các dữ liệu nhỏ và sắp xếp lại chúng để dễ dàng tìm kiếm và truy xuất hơn, đặc biệt là việc truy xuất các dữ liệu tương đồng. Ví dụ thường thấy nhất là các đề xuất mà ta hay thấy ở Google tìm kiếm
Như vậy mô hình lập trình Map Reduce là nền tảng ý tưởng của Hadoop. Bản thân Hadoop là một framework cho phép phát triển các ứng dụng phân tán phần cứng thông thường . Các phần cứng này thường có khả năng hỏng hóc cao. Khác với loại phần cứng chuyên dụng đắt tiền, khả năng xảy ra lỗi thấp như các supermicrocomputer chẳng hạn.
Hadoop viết bằng Java. Tuy nhiên, nhờ cơ chế streaming, Hadoop cho phép phát triển các ứng dụng phân tán bằng cả java lẫn một số ngôn ngữ lập trình khác như C++, Python, Pearl.
Kiến trúc Hadoop
Hadoop gồm 4 module:
- Hadoop Common: Đây là các thư viện và tiện ích cần thiết của Java để các module khác sử dụng. Những thư viện này cung cấp hệ thống file và lớp OS trừu tượng, đồng thời chứa các mã lệnh Java để khởi động Hadoop.
- Hadoop YARN: Đây là framework để quản lý tiến trình và tài nguyên của các cluster.
- Hadoop Distributed File System (HDFS): Đây là hệ thống file phân tán cung cấp truy cập thông lượng cao cho ứng dụng khai thác dữ liệu.
- Hadoop MapReduce: Đây là hệ thống dựa trên YARN dùng để xử lý song song các tập dữ liệu lớn.
Hiện nay Hadoop đang ngày càng được mở rộng cũng như được nhiều framwork khác hỗ trợ như Hive, Hbase, Pig. Tùy vào mục đích sử dụng mà ta sẽ áp dụng framework phù hợp để nâng cao hiệu quả xử lý dữ liệu của Hadoop.
Hadoop hoạt động như thế nào?
Giai đoạn 1:
Một user hay một ứng dụng có thể submit một job lên Hadoop (hadoop job client) với yêu cầu xử lý cùng các thông tin cơ bản:
- Truyền dữ liệu lên server(input) để bắt đầu phân tán dữ liệu và đưa ra kết quả (output).
- Các dữ liệu được chạy thông qua 2 hàm chính là map và reduce.
- Map: sẽ quét qua toàn bộ dữ liệu và phân tán chúng ra thành các dữ liệu con.
- Reduce: sẽ thu thập các dữ liệu con lại và sắp xếp lại chúng.
- Các thiết lập cụ thể liên quan đến job thông qua các thông số truyền vào.
Giai đoạn 2:
Hadoop job client submit job (file jar, file thực thi) và bắt đầu lập lịch làm việc(JobTracker) đưa job vào hàng đợi .
Sau khi tiếp nhận yêu cầu từ JobTracker, server cha(master) sẽ phân chia công việc cho các server con(slave). Các server con sẽ thực hiện các job được giao và trả kết quả cho server cha.
Giai đoạn 3:
TaskTrackers dùng để kiểm tra đảm bảo các MapReduce hoạt động bình thường và kiểm tra kết quả nhận được (quá trình output).
Khi “chạy Hadoop” có nghĩa là chạy một tập các trình nền - daemon, hoặc các chương trình thường trú, trên các máy chủ khác nhau trên mạng của bạn. Những trình nền có vai trò cụ thể, một số chỉ tồn tại trên một máy chủ, một số có thể tồn tại trên nhiều máy chủ.
Ưu điểm của Hadoop
- Hadoop framework cho phép người dùng nhanh chóng viết và kiểm tra các hệ thống phân tán. Đây là cách hiệu quả cho phép phân phối dữ liệu và công việc xuyên suốt các máy trạm nhờ vào cơ chế xử lý song song của các lõi CPU.
- Hadoop không dựa vào cơ chế chịu lỗi của phần cứng fault-tolerance and high availability (FTHA), thay vì vậy bản thân Hadoop có các thư viện được thiết kế để phát hiện và xử lý các lỗi ở lớp ứng dụng.
- Hadoop có thể phát triển lên nhiều server với cấu trúc master-slave để đảm bảo thực hiện các công việc linh hoạt và không bị ngắt quãng do chia nhỏ công việc cho các server slave được điều khiển bởi server master.
- Hadoop có thể tương thích trên mọi nền tảng như Window, Linux, MacOs do được tạo ra từ Java.
Cài đặt
Tải Hadoop về máy
wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/hadoop-2.4.1.tar.gz
Unzip tệp tải về
tar xzf hadoop-2.4.1.tar.gz
Đổi tên thư mục cho dễ nhìn =))
mv hadoop-2.4.1 to hadoop
Cài đặt môi trường cho Hadoop dùng vi ~/.bashrc và thêm những dòng sau rồi dùng lệnh source ~/.bashrc để thực thi thay đổi
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export
PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Truy cập thư mục hadoop/etc/hadoop và sửa các file sau:
hadoop-env.shthay thế đoạn JAVA_HOME thànhexport JAVA_HOME=/usr/local/jdk-...theo version java máy bạn cài đặt- core-site.xml thêm :
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
- yarn-site.xml thêm:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- copy
cp mapred-site.xml.template mapred-site.xmlrồi thêm:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- hdfs-site.xml thêm:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value >
</property>
Khởi động hadoop:
Khởi tạo namenode
hdfs namenode -format
Chạy server hadoop:
start-dfs.sh
start-yarn.sh
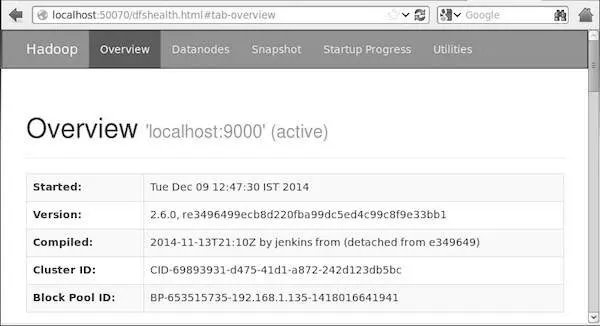
Truy cập localhost:50070: overview của hadoop
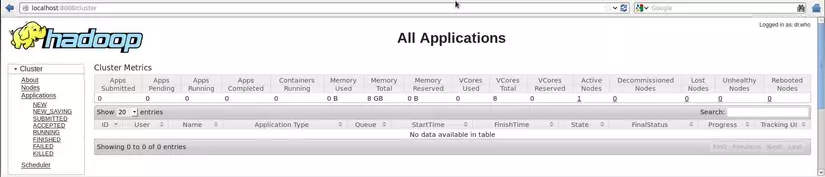
Truy cập localhost:8088: ta có thể xem các job mapreduce đang chạy ở đây
Các daemon khi khởi chạy Hadoop sẽ bao gồm:
- NameNode
- DataNode
- SecondaryNameNode
- JobTracker
- TaskTracker
Tham khảo thêm tại:
https://kipalog.com/posts/Co-ban-ve-Hadoop
https://www.tutorialspoint.com/hadoop/hadoop_enviornment_setup.htm
All rights reserved
