Tìm hiểu về Hadoop
Bài đăng này đã không được cập nhật trong 6 năm
Trong thời đại công nghệ 4.0 ngày nay, có lẽ các bạn được nghe rất nhiều về AI, big data Machine Learning hay điện toán đám mây… Nhưng tất cả những công nghệ đó đều phải dựa vào tài nguyên của người dùng đó là Big data.
Vậy Big Data là gì? Big Data là một tập hợp dữ liệu rất lớn và rất phức tạp đến nỗi những công cụ, kỹ thuật xử lý dữ liệu truyền thống không thể nào đảm đương được. Hiện nay BIg data đang là một trong những ưu tiên hàng đầu của các công ty công nghệ trên toàn thế giới, vậy những kỹ thuật hiện đại nào sẽ giúp các công ty giải quyết được vấn đề của Big Data? Và hôm nay mình xin giới thiệu về Hadoop, một framework được dùng phổ biến nhất để giải quyết các bài toán về Big Data.
1. Hadoop là gì?
Hadoop là một Apache framework nguồn mở viết bằng Java cho phép phát triển các ứng dụng phân tán có cường độ dữ liệu lớn một cách miễn phí. Nó được thiết kế để mở rộng quy mô từ một máy chủ đơn sang hàng ngàn máy tính khác có tính toán và lưu trữ cục bộ (local computation and storage). Hadoop được phát triển dựa trên ý tưởng từ các công bố của Google về mô hình Map-Reduce và hệ thống file phân tán Google File System (GFS). Và có cung cấp cho chúng ta một môi trường song song để thực thi các tác vụ Map-Reduce.
Nhờ có cơ chế streaming mà Hadoop có thể phát triển trên các ứng dụng phân tán bằng cả java lẫn một số ngôn ngữ lập trình khác như C++, Pyhthon, Pearl,...
2. Kiến trúc của Hadoop
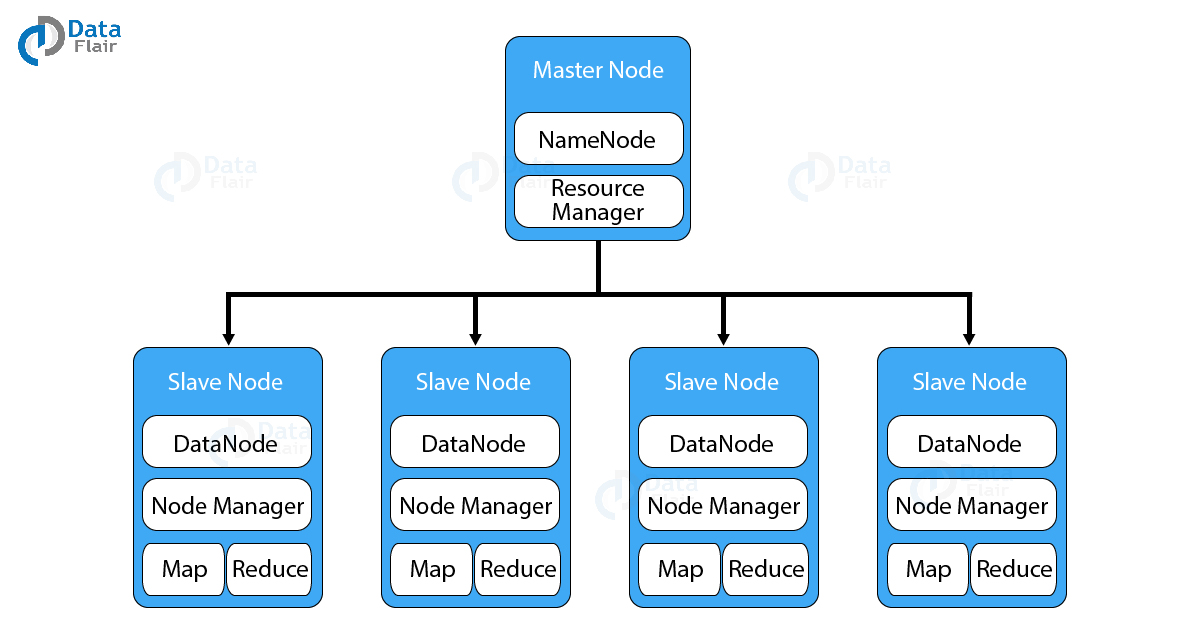
Hadoop có một cấu trúc liên kết master-slave. Trong cấu trúc này, chúng ta có một node master và nhiều node slave . Chức năng của node master là gán một tác vụ cho các node slave khác nhau và quản lý tài nguyên. Các node slave là máy tính thực tế có thể không mạnh lắm. Các node slave lưu trữ dữ liệu thực trong khi trên master chúng ta có metadata.
Kiến trúc Hadoop gồm có ba lớp chính đó là
- HDFS (Hadoop Distributed File System)
- Map-Reduce
- Yarn
2.1 HDFS (Hadoop Distributed File System)
- Là hệ thống file phân tán, cung cấp khả năng lưu trữ dữ liệu khổng lồ và tính năng tối ưu hoá việc sử dụng băng thông giữa các node. HDFS có thể được sử dụng để chạy trên một cluster lớn với hàng chục ngàn node.
- Cho phép truy xuất nhiều ổ đĩa như là 1 ổ đĩa. Nói cách khác, chúng ta có thể sử dụng một ổ đĩa mà gần như không bị giới hạn về dung lượng. Muốn tăng dung lượng chỉ cần thêm node (máy tính) vào hệ thống.
- Có kiến trúc Master-Slave
- NameNode chạy trên máy chủ Master, có tác vụ quản lý Namespace và điều chỉnh truy cập tệp của client
- DataNode chạy trên các nút Slave. có tác vụ lưu trữ business data thực tế
- Một tập tin với định dạng HDFS được chia thành nhiều block và những block này được lưu trữ trong một tập các DataNodes
- Kích thước 1 block thông thường là 64MB, kích thước này có thể thay đổi được bằng việc cấu hình
2.2 Map-Reduce
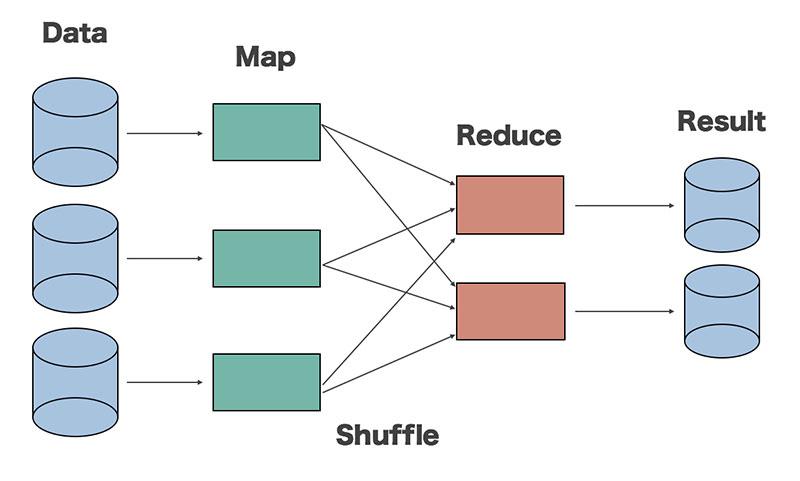
Map-Reduce là một framework dùng để viết các ứng dụng xử lý song song một lượng lớn dữ liệu có khả năng chịu lỗi cao xuyên suốt hàng ngàn cluster(cụm) máy tính
Map-Reduce thực hiện 2 chức năng chính đó là Map và Reduce
- Map: Sẽ thực hiện đầu tiên, có chức năng tải, phân tích dữ liệu đầu vào và được chuyển đổi thành tập dữ liệu theo cặp key/value
- Reduce: Sẽ nhận kết quả đầu ra từ tác vụ Map, kết hợp dữ liệu lại với nhau thành tập dữ liệu nhỏ hơn
Để dễ hiểu hơn, chúng ta hãy cùng xem ví dụ WordCount sau đây. WordCount là bài toán đếm tần suất xuất hiện của các từ trong đoạn văn bản. Và chúng ta sẽ mô tả quá trình xử lý bài toán này bằng Map-Redue
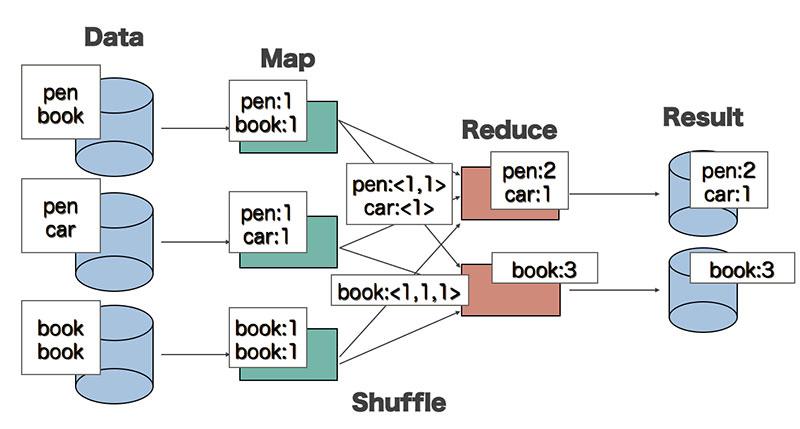
Đối với hàm Map:
- Input là 1 đoạn văn bản
- Output là các cặp <word, 1>
Hàm Map được thực hiện song song để xử lý các tập dữ liệu khác nhau.
Đối Với hàm Reduce:
- Input có dạng <word, [list]>, trong đó list là tập hợp các giá trị đếm được của mỗi từ
- Output: <word, tổng số lần xuất hiện của từ>
Hàm Reduce cũng được chạy song song để xử lý các tập từ khoá khác nhau.
Giữa hàm Map và Reduce có một giai đoạn xử lý trung gian gọi là hàm Shuffle. Hàm này có nhiệm vụ sắp xếp các từ và tổng hợp dữ liệu đầu vào cho Reduce từ các kết quả đầu ra của hàm Map.
2.3 Yarn
YARN (Yet-Another-Resource-Negotiator) là một framework hỗ trợ phát triển ứng dụng phân tán YARN cung cấp daemons và APIs cần thiết cho việc phát triển ứng dụng phân tán, đồng thời xử lý và lập lịch sử dụng tài nguyên tính toán (CPU hay memory) cũng như giám sát quá trình thực thi các ứng dụng đó.
Bên trong YARN, chúng ta có hai trình quản lý ResourceManager và NodeManage
- ResourceManager: Quản lý toàn bộ tài nguyên tính toán của cluster.
- NodeManger: Giám sát việc sử dụng tài nguyên của container và báo cáo với ResourceManger. Các tài nguyên ở đây là CPU, memory, disk, network,...
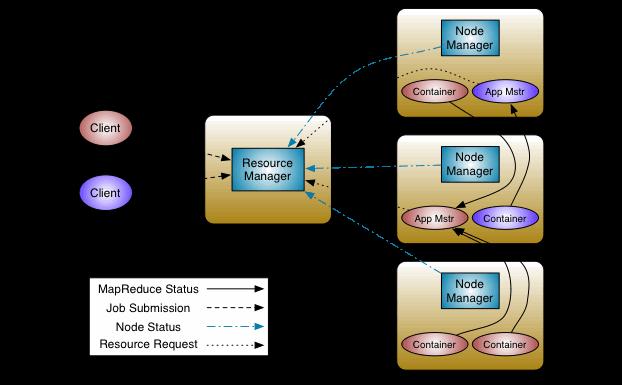
Quá trình 1 ứng dụng chạy trên YARN được mô tả bằng sơ đồ trên qua các bước sau:
- Client giao 1 task cho Resource Manager
- Resource Manager tính toán tài nguyên cần thiết theo yêu cầu của ứng dụng và tạo 1 App Master (App Mstr). Application Master được chuyển đến chạy 1 một node tính toán. Application Master sẽ liên lạc với các NodeManager ở các node khác để ra yêu cầu công việc cho node này.
- Node Manager nhận yêu cầu và chạy các task trên container
- Các thông tin trạng thái thay vì được gửi đến JobTracker sẽ được gửi đến App Master.
ResourceManger có hai thành phần quan trọng đó là Scheduler và ApplicationManager
Scheduler có trách nhiệm phân bổ tài nguyên cho các ứng dụng khác nhau. Đây là Scheduler thuần túy vì nó không thực hiện theo dõi trạng thái cho ứng dụng. Nó cũng không sắp xếp lại các tác vụ bị lỗi do lỗi phần cứng hoặc phần mềm. Bộ lập lịch phân bổ các tài nguyên dựa trên các yêu cầu của ứng dụng
ApplicationManager có chức năng sau:
- Chấp nhận nộp công việc.
- Đàm phán container đầu tiên để thực thi ApplicationMaster. Một nơi chứa kết hợp các yếu tố như CPU, bộ nhớ, đĩa và mạng.
- Khởi động lại container ApplicationMaster khi không thành công.
Chúng ta có thể mở rộng YARN ngoài một vài nghìn node thông qua tính năng YARN Federation. Tính năng này cho phép chúng ta buộc nhiều cụm YARN thành một cụm lớn. Điều này cho phép sử dụng các cụm độc lập, ghép lại với nhau cho một job rất lớn
Tham khảo
http://hadoop.apache.org/docs/current/index.html
All rights reserved
