
Tìm hiểu về giải pháp Digital Humans phần 4: Hallo: Hãy để một bức ảnh cất tiếng nói
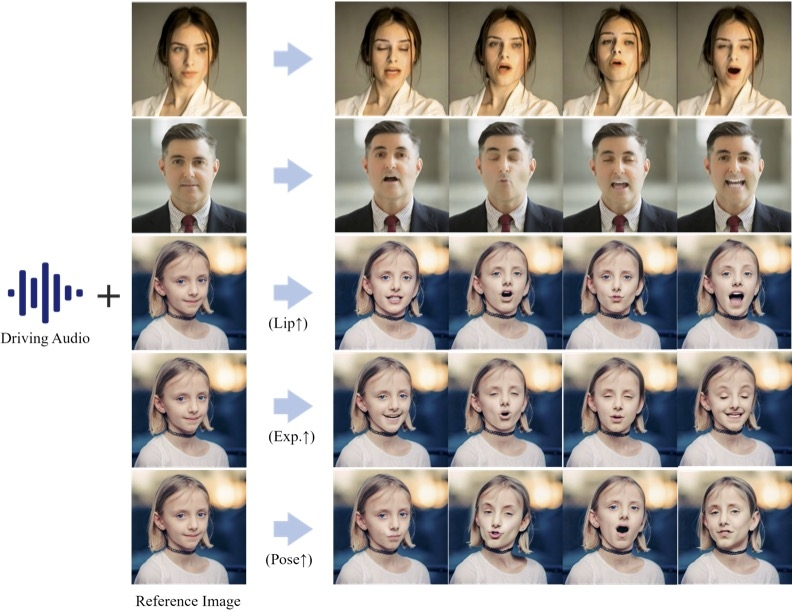
Hallo có thể làm gì?
Để những bức ảnh tĩnh “lên tiếng” luôn là mong đợi của con người đối với trí tuệ nhân tạo. Trong những năm gần đây, với sự phát triển của deep learning, công nghệ tạo chuyển động ảnh chân dung được điều khiển bằng âm thanh đã có những bước tiến vượt bậc. Nhiều mô hình khác nhau đã xuất hiện như SadTalker and DiffTalk,... nhưng làm thế nào để đạt được sự đồng bộ hóa môi chính xác, duy trì độ chân thực và mượt mà của video cũng như hỗ trợ nhiều ngôn ngữ và phong cách vẫn là những thách thức mà các nhà nghiên cứu phải đối mặt.
Một nhóm nghiên cứu từ Đại học Fudan, Baidu, ETH Zurich và Đại học Nam Kinh đã cùng nhau phát triển và cho ra mắt Hallo . Mô hình này đã đạt được những đột phá về nhiều mặt và cung cấp cách tạo ra những hình ảnh hoạt hình vô cùng chân thực. Quan trọng hơn Hallo có mã nguồn mở, không như mô hình V*** hay E** nào đó công bố nửa năm rồi vẫn chưa thấy mã nguồn 👉️👈️
Mọi người có thể tham khảo các demo của Hallo ở đây: https://fudan-generative-vision.github.io/hallo/#/
Một demo mình chạy Mr.Bean hát một đoạn Đừng làm trái tim anh đau của xếp Tùng 😆
Hallo làm điều đó như thế nào
Tổng quan
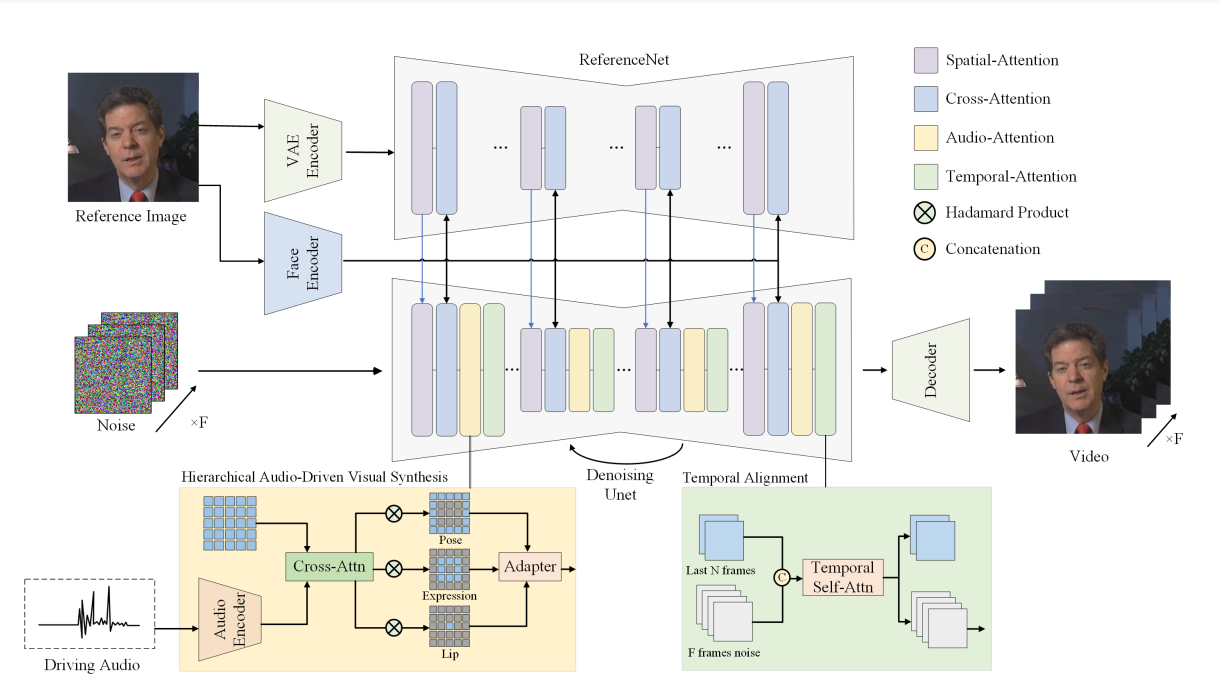
Về cơ bản Hallo sử dụng một kiến trúc dựa trên Stable Diffusion 1.5 nhưng thay vì sử dụng các đặc trưng của văn bản, nhóm tác giả sử dụng đặc trưng là âm thanh. Hình ảnh ban đầu sẽ được nén vào một không gian Latent. Sau đó, mô hình sẽ biến đổi và khôi phục lại hình ảnh từ không gian này.
Ngoài ra khi tạo ra các đoạn video, Hallo không chỉ đơn giản là ghép nối âm thanh với hình ảnh. Thay vào đó, họ sử dụng một cách tiếp cận khác (Hierarchical Audio-Visual Cross Attention) để phân tích và đồng bộ hóa từng phần của khuôn mặt (như môi, biểu cảm và tư thế đầu) với âm thanh tương ứng. Bằng cách này, khi bạn đưa vào một đoạn âm thanh, Hallo sẽ tạo ra chuyển động môi khớp với âm thanh, đồng thời thêm các biểu cảm và tư thế để làm cho nhân vật trong ảnh trở nên tự nhiên hơn.
Tóm lại, Hallo bao gồm một "bộ khung" là dựa trên Stable Diffusion 1.5 kết hợp với Modul Hierarchical Audio-Visual Cross Attention và một ReferenceNet - một mạng tham chiếu giúp đảm bảo rằng các video được sinh ra luôn có chất lượng đủ tốt và nhất quán. Bên cạnh đó, Hallo còn sử dụng kỹ thuật là Temporal Alignment để đảm bảo các đoạn video mượt mà và không bị giật lag.
Chi tiết hơn
Khái niệm cần biết
Latent Diffusion Models
Latent Diffusion Models đại diện cho một lớp các mô hình khuếch tán hoạt động trong không gian tiềm ẩn được mã hóa bởi một bộ mã hóa tự động (autoencoder), được biểu diễn dưới dạng .
Một ví dụ nổi bật hay được nhắc tới là Stable Diffusion, tích hợp một VQ-VAE autoencoder và một U-Net có điều kiện theo thời gian để ước tính nhiễu. Hơn nữa, Stable Diffusion sử dụng CLIP để chuyển đổi văn bản đầu vào thành một vector text embedding tương ứng, phục vụ như một điều kiện (condition) trong quá trình khuếch tán. Phương pháp này không chỉ đảm bảo độ trung thực của các hình ảnh được tạo ra mà còn đảm bảo chúng phù hợp về mặt ngữ cảnh với các điều kiện đầu vào bổ sung, thể hiện tính hiệu quả của việc tích hợp các điều kiện điều chỉnh trong các mô hình sinh tổng quát (generative models).
Cross Attention as Motion Guidance.
![]()
Cross attention là một thành phần quan trọng trong mô hình khuếch tán, giúp tăng cường quá trình tổng hợp hình ảnh bằng cách định hướng luồng và tập trung vào thông tin.
Trong các tác vụ sinh video, các điều kiện (conditions) có thể bao gồm lời nhắc bằng văn bản, khung xương (skeletons), bản đồ ngữ nghĩa (semantic maps), hoặc các luồng tham số 3D. Đối với các tác vụ sinh hoạt ảnh chân dung, âm thanh thường sẽ được sử dụng kèm với cross attention để tích hợp các điều kiện liên quan một cách hiệu quả.
Về mặt toán học, cross attention được thực hiện bằng cách sử dụng các lớp attention xử lý cả embedding của conditions, ký hiệu là , và các biến latent .
Các lớp này tính toán các điểm số attention để xác định mức độ tập trung của mô hình trên các khía cạnh đầu vào khác nhau. Các điểm số sau đó được sử dụng để tính trọng số cho từng thành phần, tạo ra một tổng trọng số làm đầu vào cho các lớp tiếp theo. Cơ chế cross attention có thể được biểu diễn như sau:
Ở đây, được tính như này:
Trong đó là các ma trận có thể học được.
Bằng cách tích hợp cross attention, mô hình khuếch tán có khả năng tự điều chỉnh sự tập trung của nó dựa trên trạng thái đang tiến triển của các biến tiềm ẩn và điều kiện chuyển động cụ thể.
Hierarchical Audio-Driven Visual Synthesis.
Vì nhiệm vụ chính là tạo ra một video với S khung hình, khi cho trước hình ảnh khuôn mặt và một đoạn âm thanh. Với mỗi khung hình s, chúng ta cần xác định vector latent tương ứng tại thời điểm khuếch tán là
Face Embedding
Mục tiêu của Face Embedding là tạo ra các đặc trưng nhận dạng khuôn mặt có độ phân giải cao. Khác với các phương pháp trước đây sử dụng CLIP để mã hóa đặc trưng hình ảnh bằng cách huấn luyện chung trên một tập dữ liệu lớn gồm hình ảnh và mô tả văn bản, nhóm tác giả sử dụng một bộ pre-trained face encoder khác để trích xuất các đặc trưng . Các đặc trưng này được đưa vào một mô-đun cross-attention của mạng khuếch tán, tức là để tạo ra các ảnh khuôn mặt trung thực với các đặc trưng đầu vào. Phương pháp này không chỉ đảm bảo tính tổng quát hóa trong việc trích xuất đặc trưng khuôn mặt mà còn tái tạo chính xác và bảo toàn các đặc điểm nhận dạng cá nhân như biểu cảm khuôn mặt, tuổi tác và giới tính.
Audio Embedding
Nhóm tác giả sử dụng wav2vec làm bộ mã hóa đặc trưng âm thanh. Cụ thể, họ ghép nối các audio embeddings từ 12 lớp cuối cùng của mạng wav2vec để nắm bắt thông tin giữa các lớp âm thanh khác nhau. Sử dụng ba lớp linear để chuyển đổi audio embeddings từ model đã huấn luyện trước thành trong đó . Tức là chuyển đổi thành vector số thực có chiều bằng và là audio embedding cho S khung hình.
Hierarchical Audio-Visual Cross Attention
 Như hình minh họa,cơ chế cross attention âm thanh-hình ảnh theo phân cấp để hỗ trợ mô hình học các mối quan hệ giữa các điều kiện âm thanh và các thành phần hình ảnh như môi, biểu cảm và tư thế đầu.
Như hình minh họa,cơ chế cross attention âm thanh-hình ảnh theo phân cấp để hỗ trợ mô hình học các mối quan hệ giữa các điều kiện âm thanh và các thành phần hình ảnh như môi, biểu cảm và tư thế đầu.
Trước tiên, nhóm tác giả xử lý hình ảnh đầu vào để thu được các lớp mặt nạ đại diện cho môi, biểu cảm và tư thế đầu tương ứng.
Ở đây MediaPipe được sử dụng để dự đoán các tọa độ của nhiều điểm đặc trưng cho môi và biểu cảm. Các bounding box được xác định bằng:
trong đó và BoundingBox(r) biểu diễn bounding box của tất cả các điểm đặc trưng cho r. được tính như sau:
Trong đó ⊙ là phép nhân Hadamard.
Tiếp theo, áp dụng cơ chế cross attention giữa các latent và audio embeddings:
Sau đó áp dụng lớp mặt nạ và thu được các latent có tỷ lệ khác nhau:
Cuối cùng, để hợp nhất các đầu ra này, một mô-đun tích hợp được thêm để xử lý. Cụ thể, đầu ra được thu nhận bằng lớp tích chập:
Network Architecture
Diffusion Backbone
Stable Diffusion 1.5 được sử dụng, và bao gồm ba thành phần chính:
- Vector Quantised Variational AutoEncoder (VQ-VAE)
- Unet-based denoising model
- Conditioning module.
Trong các ứng dụng chuyển văn bản thành hình ảnh (text-to-image) hiện nay, các đầu vào hình ảnh ban đầu được khởi tạo ngẫu nhiên và được xử lý bởi mô hình khuếch tán kết hợp với mô-đun điều kiện hóa (Conditioning module) để tạo ra các đầu ra hình ảnh mới. Tuy nhiên trong nghiên cứu này, các đặc trưng văn bản bị loại bỏ, thay vào đó các tín hiệu âm thanh được sử dụng như là yếu tố chính để dẫn dắt chuyển động.
ReferenceNet
ReferenceNet được thiết kế để dẫn dắt quá trình sinh bằng cách tham chiếu các hình ảnh hiện có nhằm nâng cao chất lượng của video được tạo ra, bao gồm thông tin về kết cấu hình ảnh (visual texture) của các ảnh chân dung và nền.
Temporal Alignment
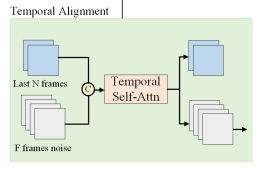
Trong các tác vụ sinh video dựa trên các mô hình khuếch tán, sự căn chỉnh theo thời gian đóng vai trò quan trọng trong việc đảm bảo tính gắn kết và nhất quán của chuỗi video được tạo ra theo thời gian. Cụ thể hơn, một tập hợp các khung hình (2 khung trong quá trình triển khai) từ bước suy diễn trước đó được chỉ định làm khung chuyển động, các khung này sau đó được ghép nối với các vector latent dọc theo các trục thời gian. Sự căn chỉnh theo thời gian này được tạo điều kiện thuận lợi thông qua các khối tự chú ý (self-attention blocks), có khả năng xử lý một cách chính xác các yếu tố thời gian của các khung hình video.
Như vậy, kiến trúc mạng sử dụng một mô hình sinh hình ảnh chuẩn dựa trên Stable Diffusion, kết hợp với ReferenceNet để dẫn dắt quá trình sinh video bằng cách sử dụng các hình ảnh tham chiếu có sẵn. Modul Temporal alignment giúp tăng cường sự gắn kết và tính nhất quán trong chuỗi video được tạo theo thời gian, kèm với hierarchical audio-driven visual synthesis module giúp thiết lập các ánh xạ tinh chỉnh giữa âm thanh và môi, biểu cảm và tư thế như đã mô tả trước đó.
Cài đặt Hallo
Mọi người cài đặt theo các bước như trong repo chính của Hallo tại đây, hoặc lẹ hơn có thể cài đặt bằng docker theo link này. Cài đặt xong là có thể trải nghiệm dễ dàng vì code đã được thiết kế sẵn giao diện bằng gradio.
Nguồn tham khảo
All rights reserved
