Tìm hiểu về Convolutional Neural Network và làm một ví dụ nhỏ về phân loại ảnh
Bài đăng này đã không được cập nhật trong 5 năm
Trong mạng nơ-ron, mạng nơ-ron tích chập (ConvNets hay CNNs, Convolutional Neural Network) là một trong những phương pháp chính để thực hiện nhận dạng hình ảnh, phân loại hình ảnh. CNN được sử dụng rộng rãi trong một số lĩnh vực như phát hiện đối tượng, nhận dạng khuôn mặt, ..... Bài viết này trình bày một số kiến thức cơ bản đã tự tìm hiểu về mạng nơ-ron tích chập và các kiến thức liên quan cũng như trình bày một ví dụ nhỏ về phân biệt hình ảnh của chó và mèo bằng cách sử dụng phương pháp trên.
Tìm hiểu về CNN
Mô hình neural network
Mạng nơ-ron nhân tạo (Neural Network - NN) là một mô hình lập trình mô phỏng cách thức hoạt động của mạng nơ-ron thần kinh. Kết hợp với các kĩ thuật học sâu (Deep Learning - DL), mạng nơ-ron nhân tạo đang trở thành một công cụ rất mạnh mẽ mang lại hiệu quả tốt nhất cho nhiều bài toán khó như nhận dạng ảnh, giọng nói hay xử lý ngôn ngữ tự nhiên.
Lịch sử phát triển của mạng nơ-ron nhân tạo bắt đầu khi Warren McCulloch và Walter Pitts đã tạo ra một mô hình tính toán cho mạng nơ-ron dựa trên các thuật toán gọi là logic ngưỡng vào năm 1943. Tuy nhiên, để làm quen và hiểu được một số kiến thức cơ bản về mô hình mạng nơ-ron nhân tạp, chúng ta sẽ bàn đến hồi quy logictics - thứ có thể coi là mô hình neural network đơn giản nhất với chỉ input layer và output layer.
Giả sử chúng ta có bài toán dựa đoán khả năng nhận đơn giao hàng dựa trên khoảng cách và thời điểm cần giao trong ngày dựa trên dữ liệu đã cho trước. Từ đó ta có thể hiểu rằng với các bộ dữ liệu {x, y} cho sẵn với x có hai đặc trưng và lần lượt là khoảng cách và thời điểm cần giao trong ngày, chúng ta sẽ sử dụng các phương pháp để tìm được ước lượng sao cho sát với giá trị y nhất.
Thông thường, chúng ta thường sử dụng hàm để dễ tính toán, tuy nhiên đầu ra y là xác suất đơn hàng có được nhận hay không nên để đầu ra thỏa mãn được điều kiện có dạng tương tự xác suất tức là luôn có giá trị trong khoảng từ 0 đến 1 chúng ta thường sử dụng hàm logictics với thường được gọi là hàm sigmod làm hàm activation.
Khi đó, hàm lỗi của một cho mỗi điểm {} được định nghĩa là cross-entropy của và như sau:
Khi đó hàm này trên toàn bộ dữ liệu được tính bằng cách lấy tổng các giá trị trên. Bằng cách tối ưu hàm mất mát này, thường bằng phương pháp đạo hàm gradient, chúng ta có thể có thể thu được mô hình phù hợp nhất cho bài toán cũng như bộ dữ liệu đã cho. Tuy nhiên, dù cố gắng nhưng hầu như giá trị ước lượng từ hàm trên vẫn có một số chênh lệch với giá trị thực tế, bởi vậy để đảm bảo cho tính khách quan, người ta thường thêm một giá trị b hay vào để tính bằng cách sử dụng giá trị này là giá trị bias có thể hiểu là phần bù cho những chênh lệch khó/không thể cực tiểu từ bước trên.
Thông thường các bước tính toán của một mô hình mạng nơ-ron nhân tạo thường được thể hiện bằng một biểu đồ tính toán để có thể quan sát trực quan hơn. Dưới đây là một biểu đồ thể hiện cho bài toán phân loại dựa trên hồi quy logictics.
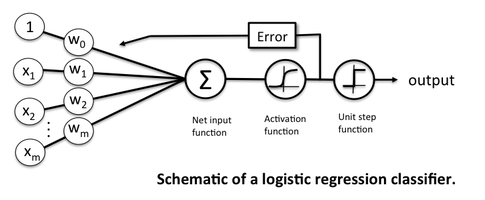
Hình ảnh từ trang web https://sebastianraschka.com/faq/docs/logisticregr-neuralnet.html
Convolutional Neural Network
Như trình bày ở trên, Convolutional Neural Network là một trong những phương pháp chính khi sử dụng dữ liệu về ảnh. Kiến trúc mạng này xuất hiện do các phương pháp xử lý dữ liệu ảnh thường sử dụng giá trị của từng pixel. Vậy nên với một ảnh có giá trị kích thước 100x100 sử dụng kênh RGB ta có tổng cộng ta có 100 * 100 * 3 bằng 30000 nút ở lớp đầu vào. Điều đó kéo theo việc có một số lượng lớn weight và bias dẫn đến mạng nơ-ron trở nên quá đồ sộ, gây khó khăn cho việc tính toán. Hơn nữa, chúng ta có thể thấy rằng thông tin của các pixel thường chỉ chịu tác động bởi các pixel ngay gần nó, vậy nên việc bỏ qua một số nút ở tầng đầu vào trong mỗi lần huấn luyện sẽ không làm giảm độ chính xác của mô hình. Vậy nên người ta sử dụng cửa số tích chập nhằm giải quyết vấn đề số lượng tham số lớn mà vẫn trích xuất được đặc trưng của ảnh.
Về mặt kỹ thuật, trong mô hình học sâu CNN, mô hình ảnh đầu vào sẽ chuyển nó qua một loạt các lớp tích chập với các bộ lọc, sau đó đến lớp Pooling, rồi tiếp theo là các lớp được kết nối đầy đủ (FC — fully connected layers) và cuối cùng áp dụng hàm softmax để phân loại một đối tượng dựa trên giá trị xác suất trong khoản từ 0 đến 1.
Convolution Layer
Convolution (lớp tích chập) là lớp đầu tiên trích xuất các đặc tính từ hình ảnh. Tham số lớp này bao gồm một tập hợp các bộ lọc có thể học được. Các bộ lọc đều nhỏ thường có kích cỡ hai chiều đầu tiên khoảng 3x3 hoặc 5x5, .... và có độ sâu bằng với độ sâu của đầu vào đầu vào. Bằng cách trượt dần bộ lọc theo chiều ngang và dọc trên ảnh, chúng thu được một Feature Map chứa các đặc trưng được trích xuất từ trên hình ảnh đầu vào.
Quá trình trượt các bộ lọc thường có các giá trị được quy định bao gồm:
padding: quy định bộ đệm của bộ lọc hay chính là phần màu xám được thêm vào ảnhstride: quy định bước nhảy trong quá trình thực hiện.
Hình minh họa sau sẽ giúp chúng ta dễ tưởng tượng hơn về quá trình trên:
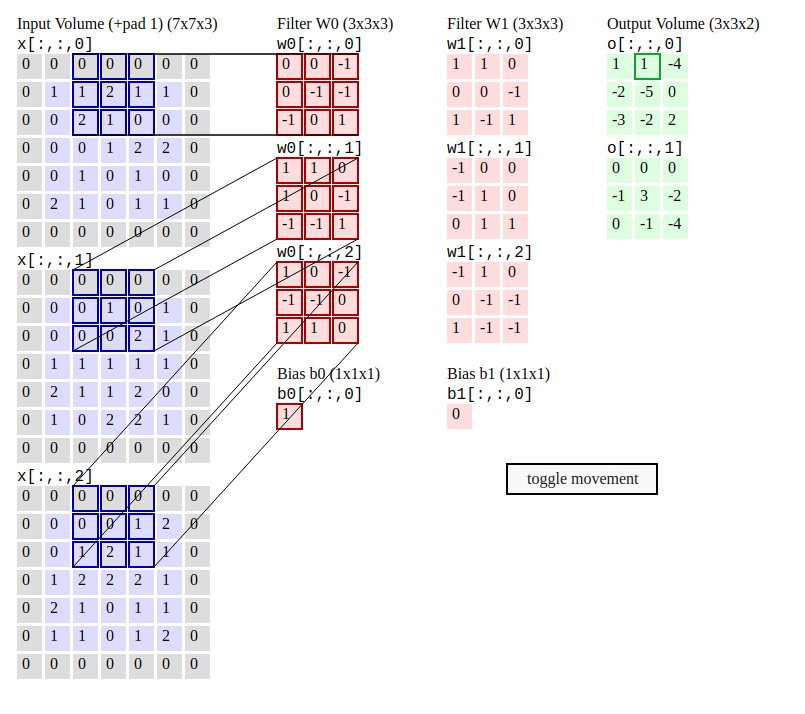
Hình ảnh chụp từ trang CS231n Convolutional Neural Networks for Visual Recognition, để nắm rõ hơn về Convolution Layer mọi người có thể đọc tiếp về phần giải thích ở trang này.
Với mỗi kernel khác nhau ta sẽ học được những đặc trưng khác nhau của ảnh, nên trong mỗi convolutional layer ta sẽ dùng nhiều kernel để học được nhiều thuộc tính của ảnh. Vì mỗi kernel cho ra output là 1 matrix nên k kernel sẽ cho ra k output matrix. Ta kết hợp k output matrix này lại thành 1 tensor 3 chiều có chiều sâu k. Output của convolutional layer sẽ qua hàm activation function trước khi trở thành input của convolutional layer tiếp theo.
Pooling layer
Pooling layer thường được dùng giữa các convolutional layer, để giảm kích thước dữ liệu nhưng vẫn giữ được các thuộc tính quan trọng. Kích thước dữ liệu giảm giúp giảm việc tính toán trong model. Trong quá trình này, quy tắc về stride và padding áp dụng như phép tính convolution trên ảnh.

Hình ảnh từ trang https://www.geeksforgeeks.org/cnn-introduction-to-pooling-layer/
Fully connected layer
Sau khi ảnh được truyền qua nhiều convolutional layer và pooling layer thì model đã học được tương đối các đặc điểm của ảnh thì tensor của output của layer cuối cùng sẽ được là phẳng thành vector và đưa vào một lớp được kết nối như một mạng nơ-ron. Với FC layer được kết hợp với các tính năng lại với nhau để tạo ra một mô hình. Cuối cùng sử dụng softmax hoặc sigmoid để phân loại đầu ra.
Phân loại ảnh
Bài toán phân loại ảnh chó và mèo nghe có vẻ đơn giản, nhưng nó chỉ được giải quyết hiệu quả trong vài năm qua bằng cách sử dụng mạng nơ-ron tích hợp học sâu. Bằng các thực hiện ví dụ này, chúng ta sẽ hiểu thêm được về Convolutional Neural Network bên cạnh những lý thuyết đã trình bày trên.
Dữ liệu
Dữ liệu được sử dụng là tập dữ liệu Dogs vs. Cats trên Kaggle. Tập dữ liệu này bao gồm gần 25000 tập ảnh chó và mèo đã được gán nhãn sẵn trong một tệp csv đi kèm. Phần dữ liệu này sẽ được sử dụng trong ví dụ này.
Các bước tiến hành
Đầu tiên chúng ta import các thư viện bằng đoạn mã sau:
import os, cv2, itertools
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
!pip install np_utils
from keras.utils.np_utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Dropout
from sklearn.utils import shuffle
!pip install sklearn
import sklearn
from sklearn.model_selection import train_test_split
Tiếp đó là định nghĩa một số hằng số để dễ dàng sử dungj:
TRAIN_DIR = './train/'
TEST_DIR = './test1/'
ROWS = 64
COLS = 64
CHANNELS = 3
Từ đó chúng ta lấy đường dẫn dữ liệu bằng đoạn mã sau:
train_images = [TRAIN_DIR+i for i in os.listdir(TRAIN_DIR)]
test_images = [TEST_DIR+i for i in os.listdir(TEST_DIR)]
Dữ liệu là tập các ảnh nên cần tiền xử lý để thu được kết quả tốt hơn, vậy nên chúng ta sẽ thực hiện như sau:
def read_image(file_path):
#print(file_path)
img = cv2.imread(file_path, cv2.IMREAD_COLOR)
#print(img)
return cv2.resize(img, (ROWS, COLS), interpolation=cv2.INTER_CUBIC)
def prep_data(images):
m = len(images)
n_x = ROWS*COLS*CHANNELS
X = np.ndarray((m,ROWS,COLS,CHANNELS), dtype=np.uint8)
y = np.zeros((m,1))
print("X.shape is {}".format(X.shape))
for i,image_file in enumerate(images) :
image = read_image(image_file)
X[i,:] = np.squeeze(image.reshape((ROWS, COLS, CHANNELS)))
if 'dog' in image_file.lower() :
y[i,0] = 1
elif 'cat' in image_file.lower() :
y[i,0] = 0
else : # for test data
y[i,0] = image_file.split('/')[-1].split('.')[0]
if i%5000 == 0 :
print("Proceed {} of {}".format(i, m))
return X,y
X_train, y_train = prep_data(train_images)
X_test, test_idx = prep_data(test_images)
Sau khi nhận được giá trị đã xử lý, chúng ta tiến hành chia thành hai tập train và validate và tạo one-hot vector
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=1)
y_train_one_hot = to_categorical(y_train)
num_classes = y_train_one_hot.shape[1]
y_val_one_hot = to_categorical(y_val)\
X_train_norm = X_train / 255
# X_val_norm = X_val / 255
Tiếp đến là định nghĩa mạng CNN được sử dụng bao gồm 4 Convolutional layers theo sau là 1 Fully Connected Layer và sử dụng đầu ra là Sigmoid.
model = Sequential()
model.add(Conv2D(32, (3,3), input_shape=(ROWS, COLS, CHANNELS), activation='relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Dropout(0.4))
model.add(Conv2D(128, (3,3), activation='relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Dropout(0.4))
model.add(Conv2D(256, (3,3), activation='relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Dropout(0.4))
model.add(Conv2D(512, (1,1), activation='relu'))
#model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Flatten())
model.add(Dropout(0.4))
model.add(Dense(units=120, activation='relu'))
model.add(Dense(units=2, activation='sigmoid'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
Tiếp theo là huấn luyện mô hình bằng cách sử dụng hàm fit có sawnx:
model.fit(X_train_norm, y_train_one_hot, validation_data=(X_val_norm, y_val_one_hot), epochs=50, batch_size = 64)
Sau khi huấn luyện xong, chúng ta có thể thử predict bằng mô hình vừa huấn luyện bằng đoạn mã sau:
image = X_train[0]
test_pred = model.predict_classes(image.reshape(1, 64, 64, 3))
plt.figure(figsize=(4,2))
plt.imshow(image)
plt.show()
print("Our Model Prediction: {}".format(test_pred))
Bên cạnh đó bằng cách sử dụng tập test và hàm evaluate chúng ta cũng có thể tính toán điểm số của mô hình. Sau khi tính thì kết quả thu được khá cao ~ 90.89%.
Kết luận
Bài viết này trình bày một số kiến thức cơ bản đã tự tìm hiểu về mạng nơ-ron tích chập và các kiến thức liên quan cũng như trình bày một ví dụ nhỏ về phân biệt hình ảnh của chó và mèo bằng cách sử dụng phương pháp trên. Có thể thấy rằng các framework Machine learning đã hỗ trợ rất tốt trong việc sử dụng các mô hình dựa trên các mạng nơ-ron nhân tạo để người dùng có thể không cần hiểu rõ về các mạng nơ-ron cũng có thể sử dụng. Tuy nhiên để có khả năng tự đánh giá và cải tiến các phương pháp của bản thân, người dùng vẫn cần tìm hiểu kĩ về bản chất và cách hoạt động của các phương pháp này. Bài viết đến đây là kết thúc cảm ơn mọi người đã giành thời gian đọc.
Tài liệu tham khảo
- https://dominhhai.github.io/vi/2017/12/ml-logistic-regression/
- https://www.geeksforgeeks.org/cnn-introduction-to-pooling-layer/
- https://machinelearningmastery.com/pooling-layers-for-convolutional-neural-networks/
- https://nttuan8.com/bai-3-neural-network/
- https://machinelearningcoban.com/2017/01/27/logisticregression/
- https://cs231n.github.io/convolutional-networks/
All rights reserved
