Tìm hiểu Prometheus Grafana hiểu để ứng dụng

Với công việc dựng Monitor hệ thống thì có lẽ bộ đôi được ưu chuộng config nhanh đa dụng dễ triển khai là Prometheus, Grafana. Chúng ta sẽ cùng nhau tìm hiểu về bộ đôi này ngay sao đây.
Prometheus là hệ thống monitoring mã nguồn mở chuyên:
- Thu thập metric
- Lưu trữ dưới dạng time series
- Truy vấn bằng PromQL
- Định nghĩa và xử lý alerting
Grafana là công cụ dùng để:
-
Query đọc dữ liệu từ Prometheus
-
Hiển thị thông tin đọc hổ trợ xây dựng dashboard đẹp mắt
-
Tạo panel, biến (variables) và cũng hỗ trợ alerting
-
Prometheus = thu thập metric, lưu metric, tính toán metric, bắn alert
-
Grafana = lấy metric ra vẽ dashboard, panel và quan sát trực quan
Sự cần thiết của monitor system
- Server có đang quá tải không?
- API nào đang chậm?
- CPU, RAM, disk bắt đầu tăng từ lúc nào?
- Tỷ lệ lỗi 5xx hiện tại là bao nhiêu?
- Latency có vượt ngưỡng cần cảnh báo không?
Không phải ngồi yên đợi lỗi đến mà chủ động với hệ thống xử lí trước khi vấn đề xuất hiện từ đó có giải pháp với vấn đề.
Prometheus hoạt động như thế nào?
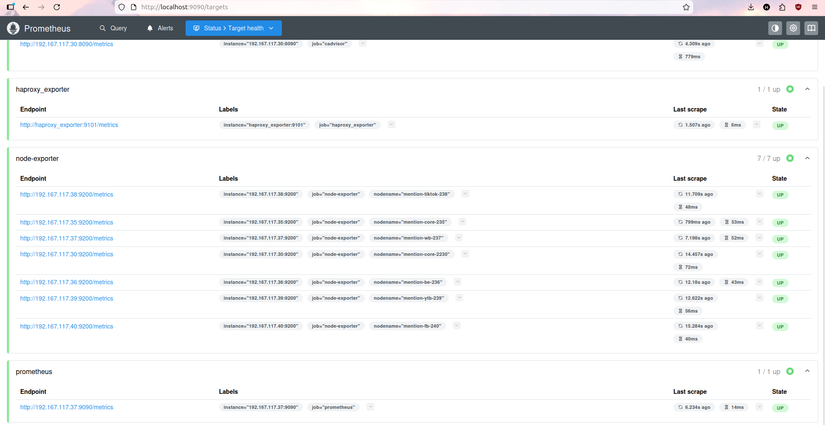 Mô hình cơ bản rất đơn giản:
Mô hình cơ bản rất đơn giản:
Application / Server / Exporter
↓ expose /metrics
Prometheus scrape định kỳ
↓
Lưu thành time series
↓
PromQL → Alert rules → Grafana
Prometheus dùng file config YAML để định nghĩa các scrape job.
Các khái niệm
-
Metric : Số liệu đo lường: CPU usage, số lượng request, số lỗi, thời gian xử lý…
-
Time series: Mỗi metric là chuỗi dữ liệu theo thời gian, được phân biệt bởi label.
-
Label :Cặp key-value giúp phân loại.
Ví dụ:
http_requests_total{method="GET", status="200", instance="app-1"} -
Scrape
Prometheus chủ động gọi endpoint/metricsđể kéo dữ liệu về (pull model). -
PromQL: Ngôn ngữ truy vấn của Prometheus.
Các loại Metric chính
-
Counter: Chỉ tăng dần.
Ví dụ: tổng số request, tổng số lỗi.
Thường dùng kèmrate()hoặcincrease(). -
Gauge: Tăng giảm tự do.
Ví dụ: lượng RAM đang dùng, số kết nối hiện tại, nhiệt độ CPU.Prometheus là công cụ mạnh mẽ trong việc thu thập, lưu trữ, truy vấn dữ liệu và thiết lập cảnh báo. Trong khi đó, Grafana nổi bật với khả năng trực quan hóa dữ liệu thông qua các dashboard linh hoạt và dễ sử dụng.
Sự kết hợp giữa Prometheus và Grafana tạo thành một hệ thống giám sát toàn diện, giúp việc theo dõi và phân tích trạng thái hệ thống trở nên trực quan và hiệu quả hơn.
Với mục tiêu của monitoring là chủ động giám sát và kiểm soát các biến động về “sức khỏe” của hệ thống, bộ đôi này cho phép người vận hành nắm bắt tình trạng từ đầu đến cuối, phát hiện sớm vấn đề và đưa ra phản ứng kịp thời, đảm bảo hệ thống luôn hoạt động ổn định và tối ưu.
- Histogram: Đo phân bố giá trị, rất tốt cho latency (có buckets).
Hay dùng để tính p50, p95, p99.
PromQL
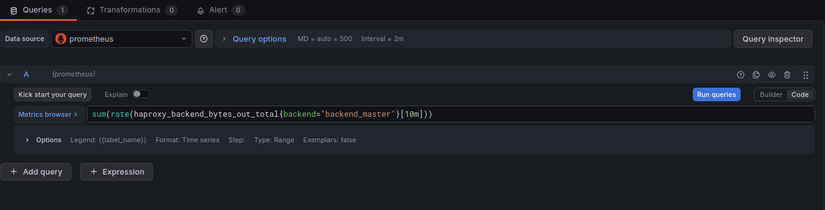
Một số query cơ bản thường dùng:
-
Kiểm tra target đang sống:
up -
Lọc theo job:
up{job="node"} -
Tốc độ request mỗi giây:
rate(http_requests_total[5m]) -
Tổng request theo method:
sum(rate(http_requests_total[5m])) by (method) -
Tính tỷ lệ lỗi 5xx:
sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m]))
Alerting trong Prometheus
Prometheus tách alerting thành 2 phần:
- Alerting rules: định nghĩa điều kiện alert ngay trong Prometheus.
- Alertmanager: gom nhóm, silence, route và gửi thông báo (Slack, email, PagerDuty…).
Ví dụ rule đơn giản:
- alert: HighCPUUsage
expr: avg(rate(process_cpu_seconds_total[5m])) > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "CPU usage cao kéo dài"
Grafana Dashboard
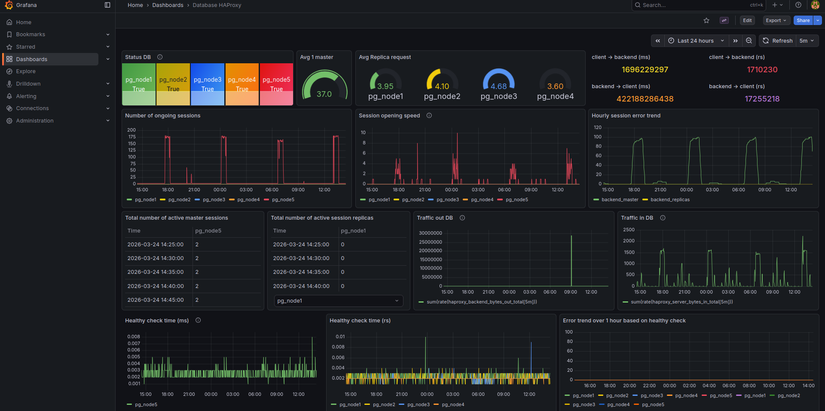
Grafana là lớp trình bày:
- Kết nối Prometheus qua Data Source
- Tạo Panel (Time series, Stat, Gauge, Table, Heatmap…)
- Ghép nhiều panel thành Dashboard
- Sử dụng Variables để lọc dashboard theo environment, instance, namespace…
Dashboard thường gặp:
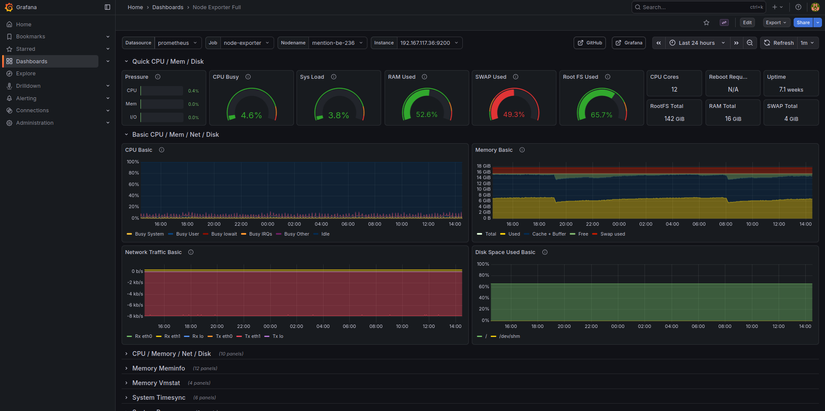
Exporter → Prometheus → PromQL → Grafana
- Dashboard Linux server: CPU, RAM, Disk, Network, Load average
- Dashboard Web App: Request rate, Error rate, P95 latency, số instance đang chạy
- Dashboard Database: Connections, Query rate, Slow queries, Replication lag
Cấu hình Prometheus Grafana đơn giản với Docker
version: "3.9"
services:
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro
- ./prometheus/alert_rules.yml:/etc/prometheus/alert_rules.yml:ro
ports:
- "9090:9090"
networks:
- esnet-p-sys
grafana:
image: grafana/grafana:latest
env_file:
- /home/mention/prometheus_manager/.env
ports:
- "3000:3000"
volumes:
- /home/mention/prometheus_manager/grafana/provisioning:/etc/grafana/provisioning
networks:
- esnet-p-sys
depends_on:
- prometheus
haproxy_exporter:
image: prom/haproxy-exporter
command:
- --haproxy.scrape-uri=http://admin:yourpassword@192.167.117.35:7700/stats;csv
ports:
- "9101:9101"
networks:
- esnet-p-sys
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
ports:
- "8090:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
- /var/run/docker.sock:/var/run/docker.sock:ro
- /etc/machine-id:/etc/machine-id:ro
- /var/lib/dbus/machine-id:/var/lib/dbus/machine-id:ro
networks:
- esnet-p-sys
node-exporter:
image: prom/node-exporter:latest
ports:
- "9200:9100"
network_mode: host
environment:
- NODE_ID=${NODE_ID:-local}
- NODE_HOSTNAME=${NODE_HOSTNAME:-localhost}
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro,rslave
command:
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --collector.filesystem.mount-points-exclude=^/(dev|proc|sys|var/lib/docker/.+|var/run/docker.sock)$$
alertmanager:
image: prom/alertmanager:latest
ports:
- "9093:9093"
volumes:
- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml:ro
- ./alertmanager/templates/alertsposts.tmpl:/etc/alertmanager/templates/alertsposts.tmpl:ro
- ./alertmanager/templates/email.tmpl:/etc/alertmanager/templates/email.tmpl:ro
command:
- --config.file=/etc/alertmanager/alertmanager.yml
- --web.external-url=http://monitor.rotoro.site
networks:
- esnet-p-sys
promtail_core:
image: grafana/promtail:2.9.0
volumes:
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- /var/log:/var/log:ro
- /home/mention/etl/log/consumer-update:/consumer_update:ro
- ./loki/config/promtail_config_core.yml:/etc/loki/promtail_config_core.yml:ro
command: -config.file=/etc/loki/promtail_config_core.yml
networks:
- esnet-p-sys
loki:
image: grafana/loki:2.9.8
ports:
- "3100:3100"
volumes:
- ./loki/config/loki_config.yml:/etc/loki/loki_config.yml:ro
command: -config.file=/etc/loki/loki_config.yml
networks:
- esnet-p-sys
networks:
esnet-p-sys:
external: true
name: esnet-p-sys
Một mẫu đơn giản về monitor có loki để đọc log từ hệ thống sinh ra, có alertmanager để chủ động email cho khách hàng cho admin khi sự cố theo rule, có node-exporter để giám sát hệ thống tổng thể(cpu, ram, disk,..), cadvisor để giám sát hiệu năng trên docker, haproxy_exporter custom metric gửi đến prometheus từ đây chúng ta thu thập metrics đổ về prometheus và dựng dashboard cho hệ thống theo custom riêng cho mỗi nghiệp vụ.
Tổng kết
Prometheus là công cụ mạnh trong việc thu thập, lưu trữ, truy vấn dữ liệu và thiết lập cảnh báo, trong khi Grafana cung cấp khả năng trực quan hóa dữ liệu thông qua các dashboard linh hoạt và dễ sử dụng. Sự kết hợp giữa hai công cụ này tạo nên một hệ thống giám sát toàn diện, giúp việc theo dõi và phân tích trạng thái hệ thống trở nên trực quan, rõ ràng và hiệu quả hơn.
Monitoring không chỉ dừng lại ở việc quan sát mà thực tế hướng tới việc chủ động kiểm soát toàn bộ trạng thái hệ thống. Thông qua Prometheus và Grafana, chúng ta nhứng system admin có thể theo dõi liên tục các biến động trên hệ thống, phát hiện sớm sự cố và phản ứng kịp thời, từ đó đảm bảo hệ thống vận hành ổn định, an toàn và tối ưu.
All rights reserved
