Thu thập và lưu trữ dữ liệu với scrapy và mysql
Bài đăng này đã không được cập nhật trong 7 năm
Với sự phát triển mạnh mẽ của internet, chúng ta một ngày tạo ra một lượng dữ liệu số vô cùng lớn,..Những dữ liệu số này dường như trở thành một thứ giá trị nếu chúng ta biết khai thác hiệu quả. Bài viết này mình sẽ giới thiệu một cách đơn giản cho những bạn muốn thu thập dữ liệu và lưu trữ chúng bằng hệ quản trị cơ sở dữ liệu mysql

Trong bài lần này mình sẽ demo về việc crawl dữ liệu bài hát từ trang web: https://nhaccuatui.com
Cài đặt môi trường
Trước hết máy tính của các bạn cần cài đặt python
Hai gói chúng ta cần tiếp theo là scrapy và scrapy-mysql-pipeline Cài đặt chúng thông qua pip với câu lệnh
pip install scrapy-mysql-pipeline
pip install Scrapy
Ok vậy là chúng ta đã có đủ thứ cần thiết, giờ chỉ việc viết thêm vài dòng code là có một bộ sưu tập lời bài hát rồi
Crawl dữ liệu
Trước hết chúng ta thử nhìn qua đối tượng chúng ta sẽ lấy dữ liệu chúng trông như thế nào, với bài viết lần này mình sẽ crawl theo những category nhạc của trang nhaccuatui.com
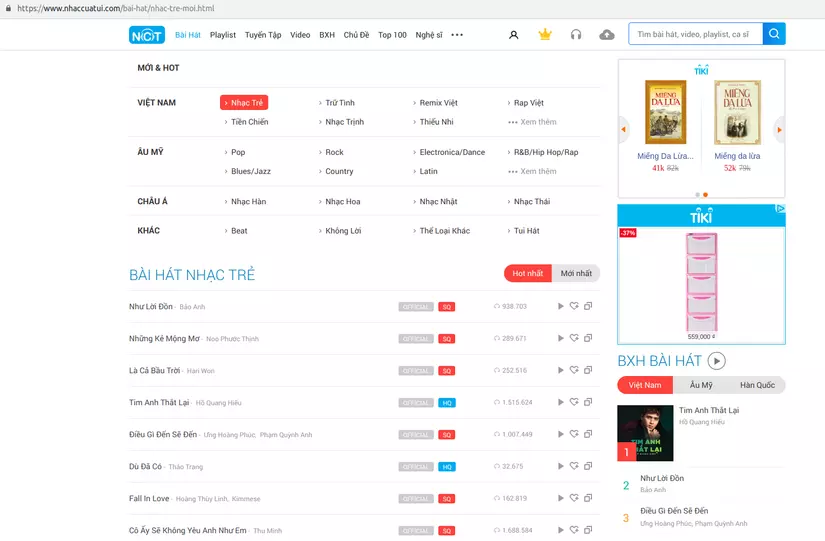
Mục tiêu của chúng ta là lấy hết lyric của các bài hát nhạc trẻ này mà chỉ với xuất phát điểm ban đầu là link duy nhất : https://www.nhaccuatui.com/bai-hat/nhac-tre-moi.html Trước hết cứ khởi tạo một project scrapy đã:
scrapy startproject nhaccuatui
Sau đó chúng ta sẽ có một project trông khá đầy đủ như thế này:
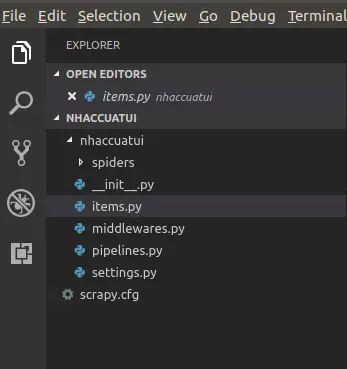
Các bạn có thể xem thêm chi tiết tại hướng dẫn này
Tiếp theo việc của chúng ta là tạo ra một con bọ spider để sai nó đi vơ vét lyric nhạc cho mình.Tạo trong folder một file lyrics_spider.py:
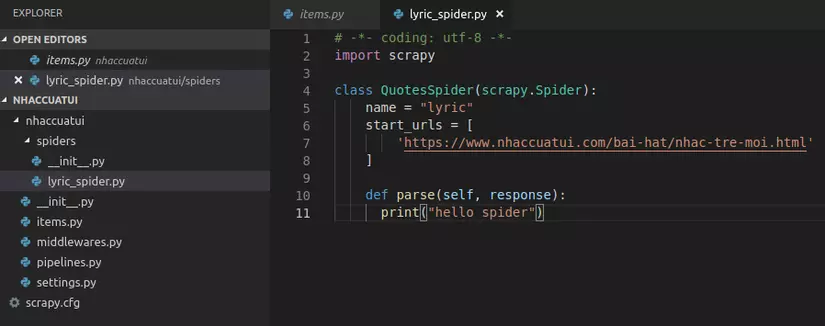
Mình sẽ giải thích đơn giản những thứ có trong file này :
name: Tên của con bọ, với mục đích khi run mình sẽ gọi tên để chỉ định con bọ(spider) nào sẽ đi crawl cho mình
start_urls: Có thể coi chính là địa chỉ bắt đầu cho spider, có thể là một list. Tại ví dụ này mình sẽ bắt đầu ở link các bài hát nhạc trẻ
parse(): Chính là nơi mình sẽ viết code để điều khiển spider làm việc cho mình (đi crawl link nhạc)
Hiện giờ chúng ta đang xuất phát từ link . Mục tiêu của chúng ta là lấy được tất cả các site của các bài hát trong link xuất phát và sẽ crawl dữ liệu của chúng
Giao diện của mỗi trang chi tiết của mỗi bài nhạc:
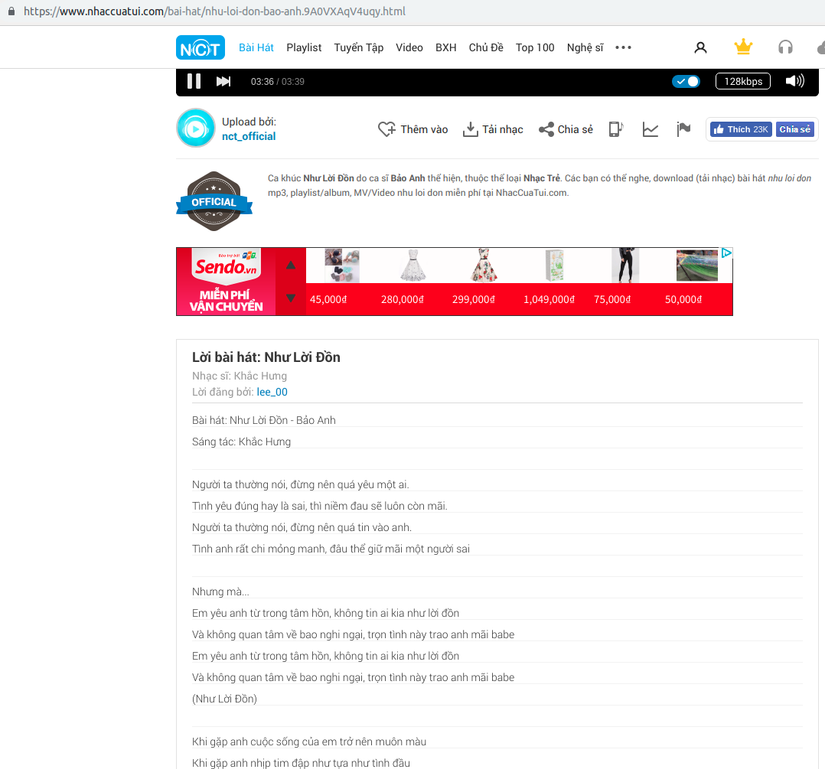
Như các bạn thấy thì chúng ta sẽ phải lấy được địa chỉ của từng bài nhạc, trước khi có thể động đến lyric của nó
Quay lại trang xuất phát và inspect lên chúng ta sẽ nhận thấy những link này đã có sẵn trong các thẻ li của html:
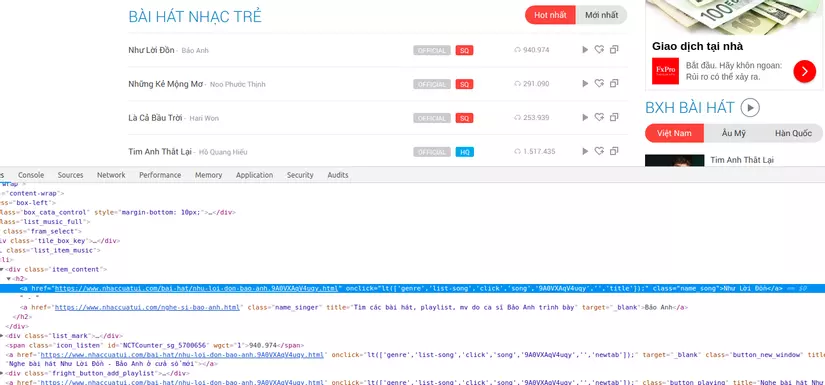
Và bây giờ ta sẽ phải lấy hết các link này. Khó khăn tiếp theo của chúng ta là những link chi tiết của bài nhạc không nằm hoàn toàn trên một trang, chúng giới hạn số lượng mỗi bài hiển thị:
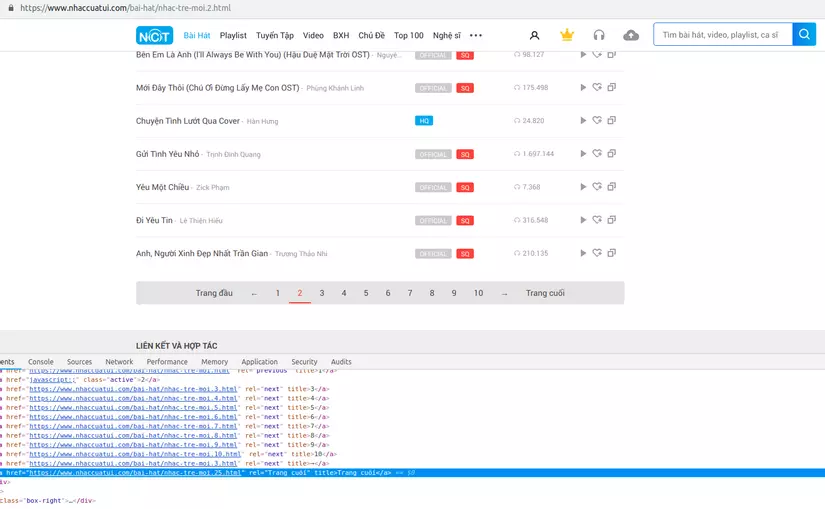
Như vậy để collect được hết link của từng bài nhạc, chúng ta phải trải qua một bước nữa là phải có được link của tất cả các trang tab chứa các list bài hát cùng category
Nếu chú ý thì bạn có thể để ý rằng là các trang tab này thay đổi tịnh tiếng địa chỉ url, ví dụ với ảnh phía trên chúng ta đang ở tab thứ 2 thì url sẽ có dạng là : https://www.nhaccuatui.com/bai-hat/nhac-tre-moi.2.html. Do đó mình nảy ra một ý định là sẽ tìm tổng số tab và dùng một vòng for để tạo ra list các tab chứa những bài nhạc mình sẽ crawl
Cũng tại ảnh trên khi inspect các bạn sẽ thấy ở element Trang cuối sẽ là đường dẫn https://www.nhaccuatui.com/bai-hat/nhac-tre-moi.25.html, như vậy tổng số tab của mục nhạc trẻ này là 25 tab
Giờ công việc của chúng ta sẽ là :
Từ trang đích -> các trang tab
Từ các trang tab -> trang chi tiết của bài nhạc
Từ trang chi tiết bài nhạc -> crawl lyric tương ứng
Mình sẽ lấy link của các trang tab ngay trên cây DOM của trang đích. Các bạn có thể xem chi tiết các loại selector có thể sử dụng tại đường dẫn
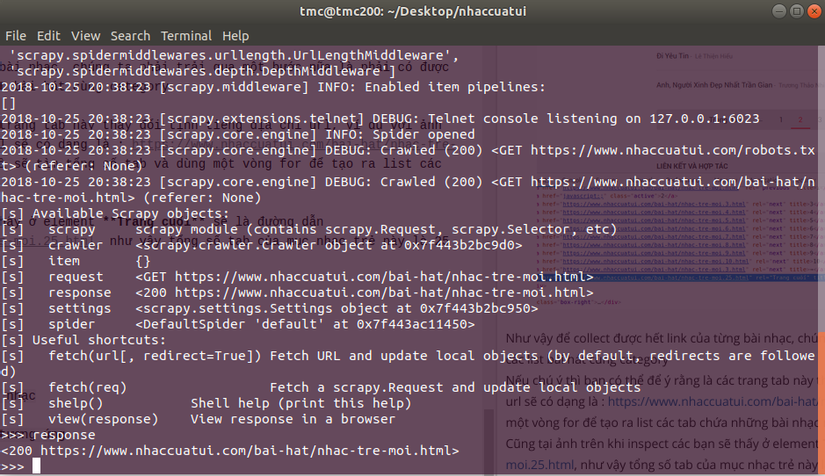
Ở ví dụ lần này mình sẽ xử dụng XPaths. Có một tip khá hay là sử dụng srapy shell để test trức tiếp các selector của các trang bạn muốn crawl:
Mở terminal và gõ :
scrapy shell https://www.nhaccuatui.com/bai-hat/nhac-tre-moi.html
 https://images.viblo.asia/7bd27576-af9e-4f42-a225-e922921ed063.png
https://images.viblo.asia/7bd27576-af9e-4f42-a225-e922921ed063.png
Vậy là chúng ta có thể thoải mái nghịch thử cây DOM của link này rồi
Đầu tiên sẽ là lấy số lượng các trang tab từ trang đích, hay chính là con số 25 kia:
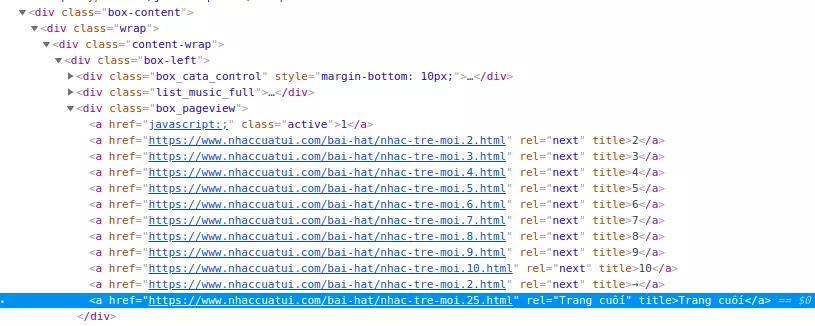
Chúng ta có thể thấy để đến được cái link cần lấy thì trải qua khá nhiều thẻ div, như vậy câu lệnh của chúng ta sẽ có dạng
response.xpath('//div[@class="box-content"]/div[@class="wrap"]/div[@class="content-wrap"]/div[@class="box-left"]/div[@class="box_pageview"]/a/@href')[-1].extract()
Kết quả trả về sẽ là :
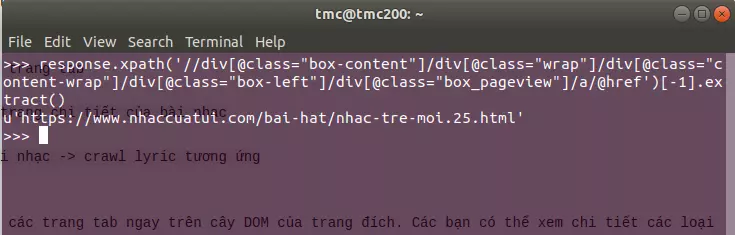
Và giờ công việc là là lấy số 25 là ta đã có thể biết được tổng số tab của thể loại nhạc trẻ rồi.
Giờ mình sẽ thêm tí code vào con spider để nó đi crawl lyric nhé:
# -*- coding: utf-8 -*-
import scrapy
class QuotesSpider(scrapy.Spider):
name = "lyric"
start_urls = [
'https://www.nhaccuatui.com/bai-hat/nhac-tre-moi.html'
]
def parse(self, response):
finalPage = response.xpath('//div[@class="box-content"]/div[@class="wrap"]/div[@class="content-wrap"]/div[@class="box-left"]/div[@class="box_pageview"]/a/@href')[-1].extract()
totalPage = int(finalPage.split(".")[-2])
for page in range(totalPage):
link = finalPage.replace(str(totalPage), str(page + 1))
yield scrapy.Request(link, callback=self.crawlLyric)
def crawlLyric(self, response):
for linkLyric in response.xpath('//div[@class="box-content"]/div[@class="wrap"]/div[@class="content-wrap"]/div[@class="box-left"]/div[@class="list_music_full"]/div[@class="fram_select"]/ul[@class="list_item_music"]/li/a[@class="button_new_window"]/@href').extract():
yield scrapy.Request(linkLyric, callback=self.saveFile)
def saveFile(self, response):
lyricRaw = response.xpath('//div[@class="box-content"]/div[@class="wrap"]/div[@class="content-wrap"]/div[@class="box-left"]/div[@class="lyric"]/p[@id="divLyric"]/text()').extract()
lyric = "\n".join(lyricRaw[1:])
print(lyric)
Mình sẽ giải thích các hàm mới được thêm vào:
yield scrapy.Request(link, callback=self.crawlLyric) Tạo request vơi 2 đối số là link là đường dẫn sẽ request tới và callback là hàm sẽ thực hiện khi request đến link được response
parse(): Từ link đích mình sẽ collect link của các tab chứa các bài hát. ý tưởng ở đây là lấy số lượng tổng các tab sau đó dùng một vòng for để tạo ra các đường link tiếp theo mà spider sẽ thăm đến.
crawlLyric(): Collect tất cả các trang nhạc chi tiết và chuyển spider đến link và function tiếp theo
saveFile(): Link response ở đây đã là link chi tiết của bài nhạc và chứa lyric mà chúng ta cần crawl
Giờ thử ra lệnh cho spider hoạt động bằng câu lệnh:
scrapy crawl lyric
Kết quả sẽ có dạng như vậy:
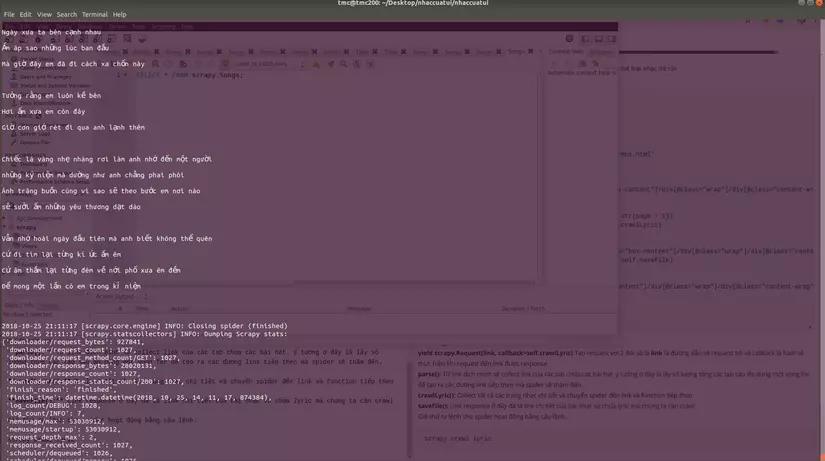
Và công việc tiếp theo của chúng ta là lưu chúng vào cơ sở dữ liệu
Lưu trữ dữ liệu
Đầu tiên chúng ta sẽ tạo một database để lưu trữ dữ liệu, để cho tiện mình sẽ sử dụng workbench. Tại đây mình sẽ tạo một database là scrapy và table là Songs như hình dưới nhé:
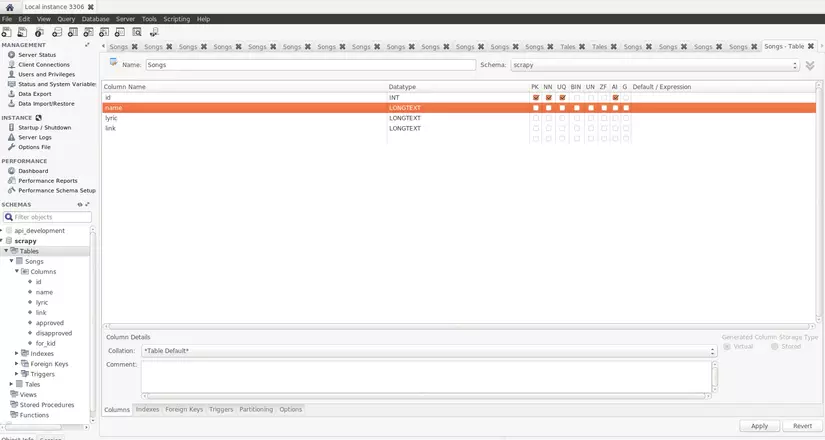
Đã xong cơ sở dữ liệu, tiếp theo chúng ta sẽ thêm một vài dòng code vào project scrapy 2 file cần custom lại sẽ là items.py và settings.py:
Ở file settings.py chúng ta sẽ cấu hình để scrapy sử dụng scrapy-mysql-pipeline và database vừa khởi tạo:
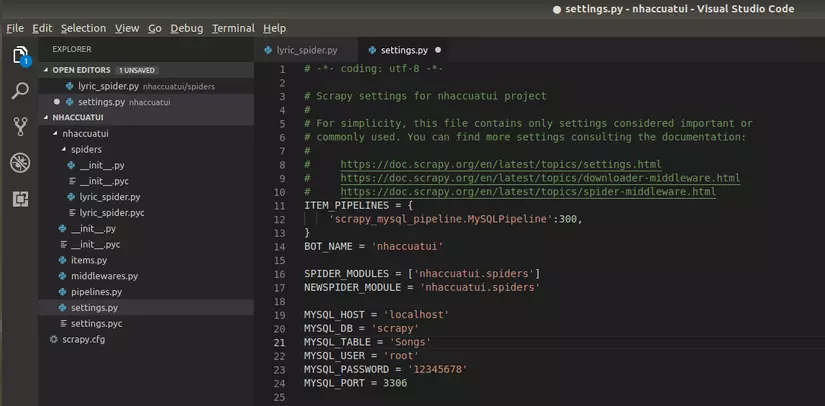
File items.py các bạn có thể hình dung như một ORM tương ứng với table lưu trữ:
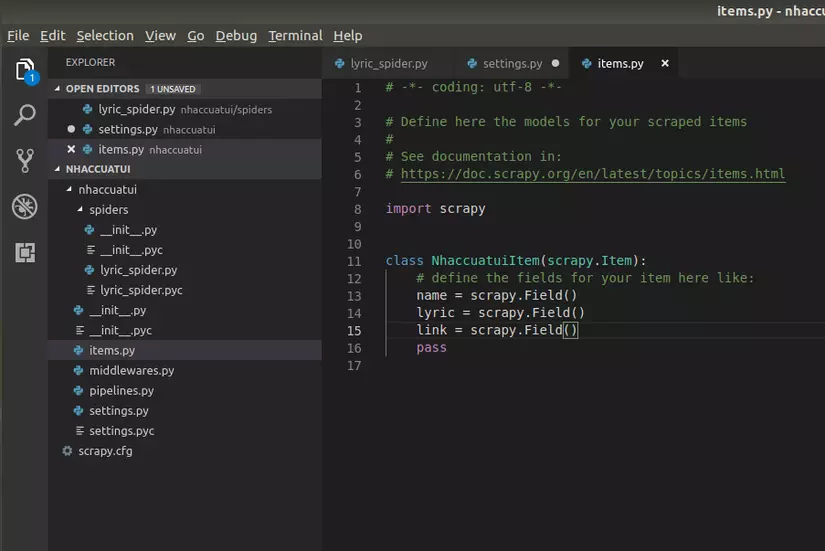
Cuối cùng là viết thêm tí code cho spider:
# -*- coding: utf-8 -*-
import scrapy
from nhaccuatui.items import NhaccuatuiItem
class QuotesSpider(scrapy.Spider):
name = "lyric"
start_urls = [
'https://www.nhaccuatui.com/bai-hat/nhac-tre-moi.html'
]
def parse(self, response):
finalPage = response.xpath('//div[@class="box-content"]/div[@class="wrap"]/div[@class="content-wrap"]/div[@class="box-left"]/div[@class="box_pageview"]/a/@href')[-1].extract()
totalPage = int(finalPage.split(".")[-2])
for page in range(totalPage):
link = finalPage.replace(str(totalPage), str(page + 1))
yield scrapy.Request(link, callback=self.crawlLyric)
def crawlLyric(self, response):
for linkLyric in response.xpath('//div[@class="box-content"]/div[@class="wrap"]/div[@class="content-wrap"]/div[@class="box-left"]/div[@class="list_music_full"]/div[@class="fram_select"]/ul[@class="list_item_music"]/li/a[@class="button_new_window"]/@href').extract():
yield scrapy.Request(linkLyric, callback=self.saveFile)
def saveFile(self, response):
lyricRaw = response.xpath('//div[@class="box-content"]/div[@class="wrap"]/div[@class="content-wrap"]/div[@class="box-left"]/div[@class="lyric"]/p[@id="divLyric"]/text()').extract()
lyric = "\n".join(lyricRaw[1:])
item = NhaccuatuiItem()
item['name'] = lyricRaw[0].encode("utf-8")
item['lyric'] = lyric.encode("utf-8")
item['link'] = response.url.encode("utf-8")
yield item
Chạy lại scrapy và chờ kết quả:
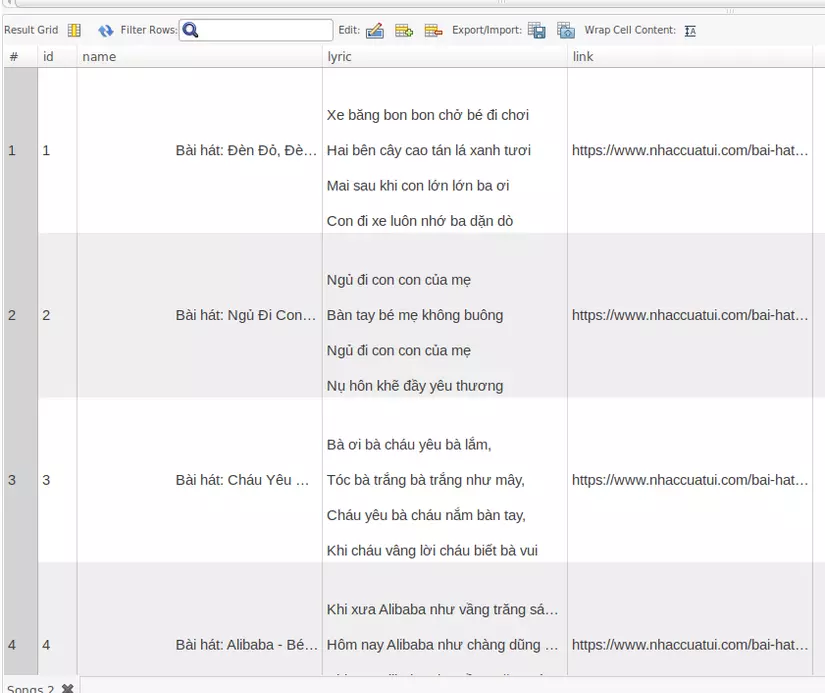
Tham khảo
https://doc.scrapy.org/en/latest/intro/tutorial.html
Kết luận
Như vậy mình đã giới thiệu cho các bạn về một cách để crawl dữ liệu và tích hợp việc store chúng.Mong bài viết của mình sẽ giúp ích cho các bạn.
All rights reserved
