Thu thập dữ liệu với Golang Colly
Bài đăng này đã không được cập nhật trong 5 năm
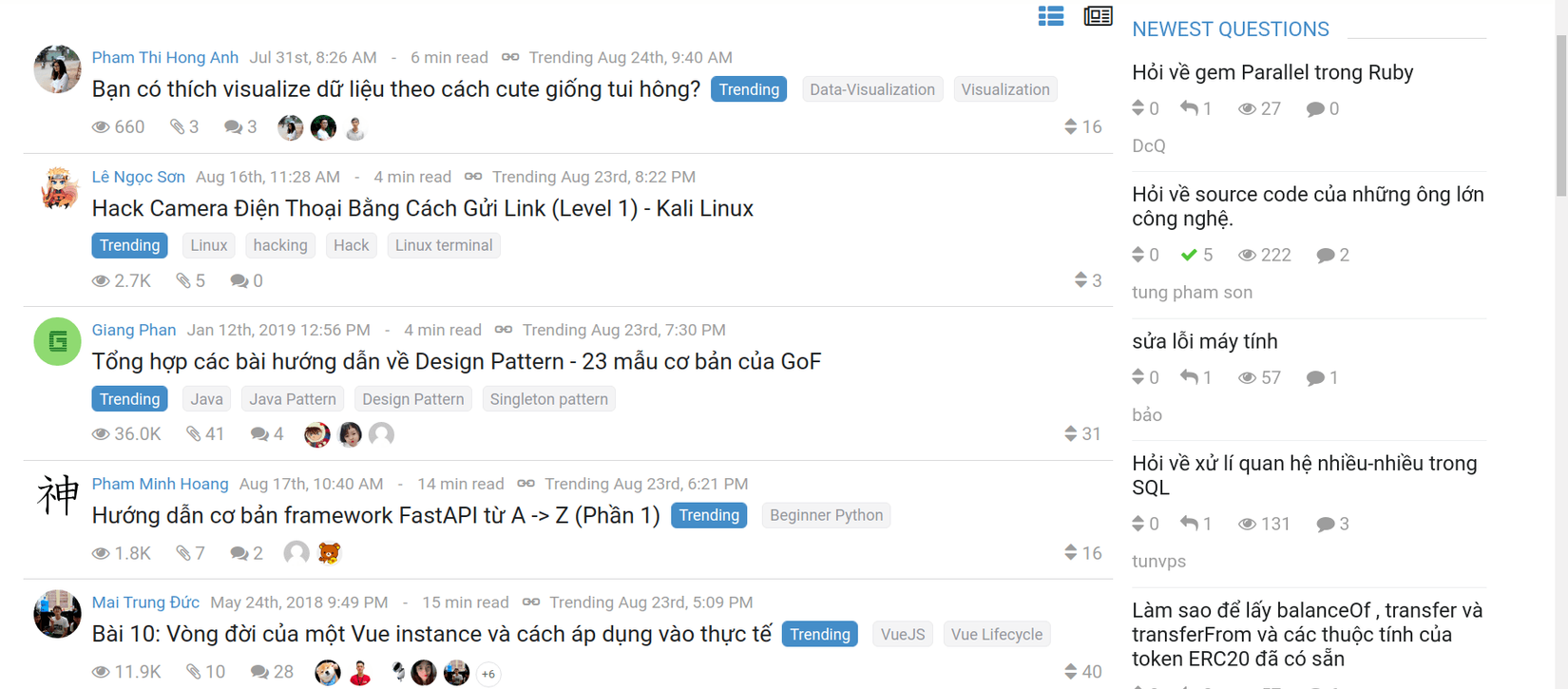
Nếu được yêu cầu viết một chương trình thu thập thông tin web, các công cụ phổ biến mà mọi người lựa chọn sẽ dựa trên Python: BeautifulSoup hoặc Scrapy. Tuy nhiên, hệ sinh thái để viết trình duyệt web và trình thu thập thông tin trong Golang khá mạnh mẽ. Đặc biệt, Colly và Goquery là những công cụ cực kỳ mạnh mẽ có khả năng biểu đạt và tính linh hoạt tương tự như các trình thu thập tương tự dựa trên Python.
Trong bài viết này, mình sẽ cùng mọi người khám phá một thư viện mạnh mẽ để thu thập dữ liệu trang web có tên là Colly được viết bằng Golang, nó nhẹ nhưng cung cấp rất nhiều chức năng như quét song song, chuyển đổi proxy,... Mục tiêu chính của chương trình quét này sẽ là lấy tất cả các bài đăng từ mục trending của trang viblo và ghi kết quả vào tệp csv.
Khởi tạo dự án
go mod init crawler
Tạo các tệp cần thiết
touch viblo.go
Cài đặt Colly mới nhất
go get -u github.com/gocolly/colly/v2/...
Chỉnh sửa tệp viblo.go
Đây là khung cơ bản của chương trình. Nó khởi tạo Colly Collector, là đối tượng sẽ kiểm soát tất cả các phương thức gọi lại khác sẽ sử dụng.
package main
import "github.com/gocolly/colly"
func main() {
c := colly.NewCollector()
}
Hãy thêm một cấu trúc, để lưu trữ từng mục mà mình truy xuất bao gồm tiêu đề (title) và liên kết (link) của bài viết:
type Data struct {
Title string
Link string
}
Mã hiện tại trở thành:
package main
import "github.com/gocolly/colly"
type Data struct {
Title string
Link string
}
func main() {
c := colly.NewCollector()
}
Sử dụng lệnh gọi lại Visit để trình thu thập truy cập URL đó
func main() {
c := colly.NewCollector()
c.Visit("https://viblo.asia/trending")
}
Tuy nhiên, rõ ràng sẽ không có gì xảy ra nếu bạn chạy go run viblo.go
Nếu bạn muốn thực sự thấy điều gì đó đang xảy ra, bạn có thể cho Colly biết phải làm gì với OnRequest. Lưu ý rằng nếu bạn in, bạn sẽ cần thêm "fmt" vào các import của mình
func main() {
c := colly.NewCollector()
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
c.Visit("https://viblo.asia/trending")
}
Nếu chúng ta truy cập trang trong trình duyệt của mình và mở bảng điều khiển trên các công cụ dành cho nhà phát triển, ta nhận thấy rằng tất cả những gì cần để truy xuất dữ liệu của mình là lấy các lớp .link nằm dưới lớp .post-feed đó.

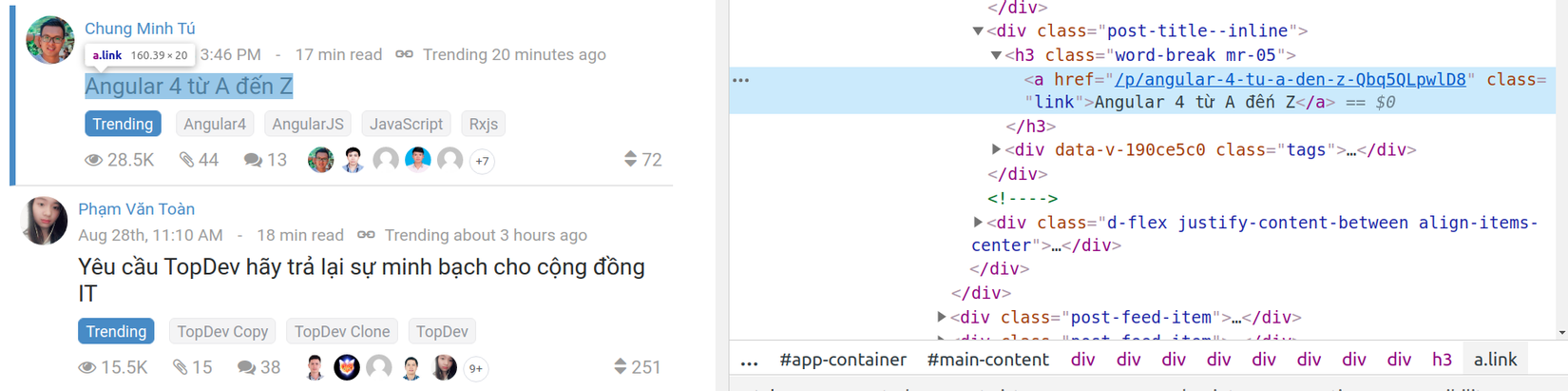
Trong mã Go, mình sẽ sử dụng lệnh gọi lại OnHTML, lệnh này sẽ hoạt động trên từng phần tử mà nó tìm thấy theo mẫu đã chỉ định ( Data là cấu trúc mà mình đã khởi tạo trước )
c.OnHTML(".post-feed .link", func(e *colly.HTMLElement) {
data := Data{}
data.Title = e.Text
data.Link = "https://viblo.asia" + e.Attr("href")
})
Điều này có nghĩa là khi tiếp nhận HTML, nó sẽ lấy các phần tử phù hợp với mẫu ".post-feed .link" và sau đó đối với mỗi phần tử đó, thực hiện như hàm cho biết.
Hiện tại, mình chỉ lấy trang đầu tiên của mục trending. Thật tuyệt vời nếu lấy được toàn bộ trang phải không? Nhận thấy rằng phân trang có thể được thay đổi qua URL:
https://viblo.asia/trending?page=2
Mình cũng nhận thấy rằng viblo trending không cho phép xem qua trang 5. Với thông tin đó, mình có thể xác định rằng tất cả các trang có thể được truy cập bằng cách sửa đổi c.Visit (url) trong mã hiện tại của mình. Nhờ vòng lặp for, mình hiện đang gửi yêu cầu đến tất cả các trang từ 1 đến 4. Điều này cho phép mình có thêm thông tin về bài viết.
for i := 1; i < 5; i++ {
fullURL := fmt.Sprintf("https://viblo.asia/trending?page=%d", i)
c.Visit(fullURL)
}
Ghi kết quả vào tệp csv
Sau khi lấy bài viết từ viblo trending thì mình cần triển khai một cách để lưu trữ nó. Trong phần này, mình sẽ chỉ cho bạn cách ghi dữ liệu vào tệp CSV. Tất nhiên, nếu bạn muốn lưu trữ dữ liệu theo cách khác, hãy thoải mái làm điều đó. Hãy bắt đầu bằng cách sửa đổi phần đầu của hàm chính. Đầu tiên, mình tạo một tệp có tên viblo_trending.csv. Sau đó, tạo một trình viết sẽ được sử dụng để lưu dữ liệu trong tệp của mình, viết mục nhập đầu tiên của tệp CSV, xác định tiêu đề của cột.
fileName := "viblo_trending.csv"
file, err := os.Create(fileName)
if err != nil {
log.Fatalf("Could not create %s", fileName)
}
defer file.Close()
writer := csv.NewWriter(file)
defer writer.Flush()
writer.Write([]string{"Title", "Link"})
Sau đó, trong hàm gọi lại OnHTML, thay vì ghi kết quả nhận được, mình sẽ ghi chúng vào tệp csv. Như thế này:
//fmt.Printf("Title: %s \nLink: %s \n", res.Title, res.Link)
writer.Write([]string{data.Title, data.Link})
Mã chương trình cuối cùng trông như thế này:
package main
import (
"encoding/csv"
"fmt"
"github.com/gocolly/colly"
"log"
"os"
)
type Data struct {
Title string
Link string
}
func main() {
fileName := "viblo_trending.csv"
file, err := os.Create(fileName)
if err != nil {
log.Fatalf("Could not create %s", fileName)
}
defer file.Close()
writer := csv.NewWriter(file)
defer writer.Flush()
writer.Write([]string{"Title", "Link"})
c := colly.NewCollector()
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
c.OnHTML(".post-feed .link", func(e *colly.HTMLElement) {
data := Data{}
data.Title = e.Text
data.Link = "https://viblo.asia" +e.Attr("href")
if data.Title == "" || data.Link == "https://viblo.asia" {
return
}
//fmt.Printf("Title: %s \nLink: %s \n", res.Title, res.Link)
writer.Write([]string{data.Title, data.Link})
})
for i := 1; i < 5; i++ {
fullURL := fmt.Sprintf("https://viblo.asia/trending?page=%d", i)
c.Visit(fullURL)
}
}
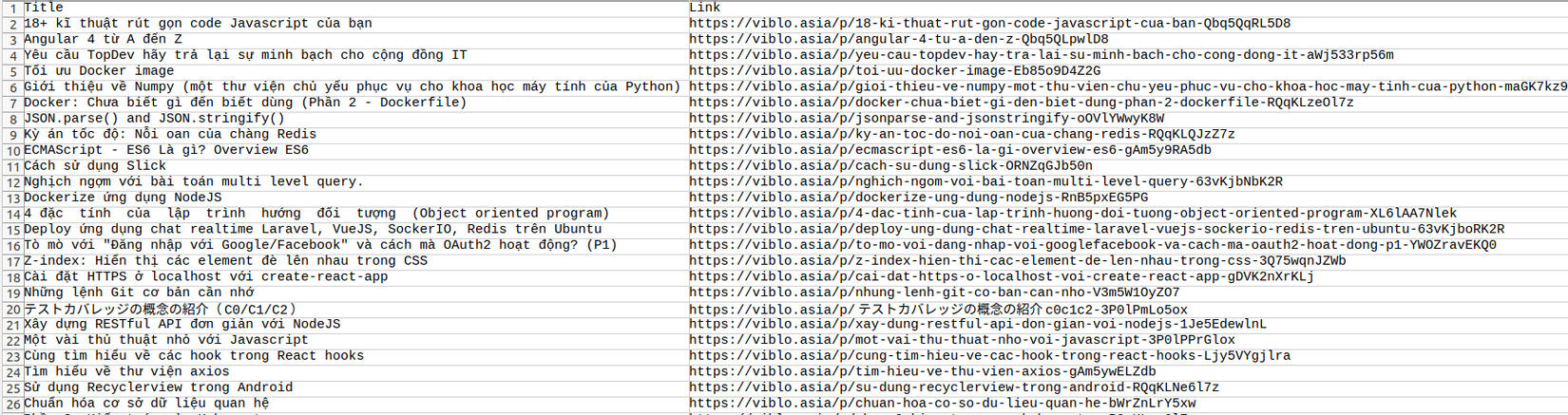
Đây là kết quả mình nhận được khi chạy chương trình, sẽ có một tệp mới trong thư mục làm việc. Nếu bạn mở nó bằng Excel (hoặc một chương trình tương tự), thì nó sẽ trông như thế này:
Mã nguồn
Tài liệu tham khảo
All rights reserved
