Thiết kế phần mềm [P4] - Xử lý ngoại lệ
Bài đăng này đã không được cập nhật trong 5 năm
Trong Phần 3 của series Thiết kế phần mềm, chúng ta đã cùng tìm hiểu các kỹ thuật tạo chiều sâu cho mô-đun. Ở bài viết này, chúng ta sẽ tiếp tục đồng hành với John Ousterhout và cuốn sách Philosophy of Software Design để tìm hiểu các lý do ngoại lệ làm tăng sự phức tạp một cách đáng kể và kỹ thuật để việc xử lý ngoại lệ trở nên đơn giản hơn.
Vì sao ngoại lệ làm tăng thêm sự phức tạp?
Ngoại lệ (exception) nghĩa là các điều kiện đặc biệt mà làm thay đổi luồng xử lý thông thường trong một chương trình. Nhiều ngôn ngữ lập trình hỗ trợ cơ chế ngoại lệ chính thức, cho phép ngoại lệ được ném ra bởi code bậc thấp hơn và được giữ lại bởi code bao bọc (ví dụ, Python hỗ trợ raise Exception và try-except). Tuy nhiên, các ngoại lệ vẫn có thể xảy ra mà không cần cơ chế này, khi một phương thức trả về một giá trị đặc biệt biểu thị rằng nó không thể hoàn thành hành vi thông thường của mình. Tất cả các dạng ngoại lệ này đều làm gia tăng sự phức tạp.
Một đoạn code có thể gặp phải ngoại lệ trong nhiều trường hợp:
- Người gọi cung cấp tham số hoặc thông số thiết lập không đúng với yêu cầu.
- Một phương thức được gọi không thể hoàn thành. Ví dụ, thao tác nhập xuất xảy ra lỗi, tài nguyên được yêu cầu không sẵn sàng.
- Code có bug.
- Trong hệ thống phân tán, các gói tin mạng bị thất lạc hoặc đến trễ, các server không phản hồi kịp thời.
Các hệ thống lớn phải xử lý rất nhiều ngoại lệ, đặc biệt nếu chúng phân tán hoặc muốn đạt được tính chịu lỗi (fault-tolerant). Do đó, có một lượng đáng kể code xử lý ngoại lệ trong hệ thống.
Khi ngoại lệ phát sinh, lập trình viên có thể xử lý nó theo hai cách (và cả hai cách đều phức tạp). Cách tiếp cận đầu tiên là tiếp tục xử lý và hoàn thành nhiệm vụ. Ví dụ, nếu một gói tin bị mất, nó có thể được gửi lại; nếu dữ liệu bị hỏng, nó có thể được khôi phục. Cách tiếp cận thứ hai là hủy bỏ thao tác và thông báo ngoại lệ. Tuy nhiên, hủy bỏ cũng phức tạp bởi code xử lý ngoại lệ phải khôi phục về lại trạng thái nhất quán. Ví dụ, khi một giao dịch (transaction) trong database bị hủy bỏ vì vi phạm các ràng buộc (ví dụ, primary key bị trùng), database bằng cách nào đó phải hoàn tác các thay đổi đã thực hiện.
Hơn nữa, code xử lý ngoại lệ cũng tạo ra cơ hội cho ngoại lệ khác. Xét trường hợp gửi lại gói tin trong mạng bị thất lạc. Có thể gói tin không bị thất lạc mà chỉ đơn giản là bị trì hoãn. Trong trường hợp này, gửi lại gói tin sẽ dẫn đến trùng lặp dữ liệu, điều này tạo ra một điều kiện ngoại lệ mà bên nhận phải xử lý.
Các ngôn ngữ hỗ trợ ngoại lệ thường dài dòng, khiến code khó đọc. Chúng ta cùng xem đoạn code Java xử lý việc đọc các đối tượng từ file:
try (
FileInputStream fileStream = new FileInputStream(fileName);
BufferedInputStream bufferedStream = new BufferedInputStream(fileStream);
ObjectInputStream objectStream = new ObjectInputStream(bufferedStream);
) {
for (int i = 0; i < tweetsPerFile; i++) {
tweets.add((Tweet) objectStream.readObject());
}
}
catch (FileNotFoundException e) {
...
}
catch (ClassNotFoundException e) {
...
}
catch (EOFException e) {
// Not a problem: not all tweet files have full
// set of tweets.
}
catch (IOException e) {
...
}
catch (ClassCastException e) {
...
}
Từ đoạn code ví dụ trên, ta thấy rằng chỉ mình mẫu try-catch thôi đã dài hơn đoạn code xử lý trường hợp thông thường. Việc liên hệ giữa code xử lý ngoại lệ với code xử lý thông thường cũng khó khăn: ví dụ, không rõ ngoại lệ được sinh ra từ đâu. Ngoài ra, cũng khó có thể đảm bảo rằng code xử lý ngoại lệ thực sự hoạt động. Một vài ngoại lệ, như lỗi nhập xuất, không dễ dàng được tạo ra trong môi trường test, nên cũng khó test được đoạn code xử lý chúng. Vì ngoại lệ không thường xuyên xảy ra, nên code xử lý cũng hiếm khi được thực thi. Một nghiên cứu gần đây đã chỉ ra rằng 90% lỗi nghiêm trọng trong các hệ thống phân tán chuyên sâu về dữ liệu (data-intensive) là do xử lý ngoại lệ không chuẩn xác.
Quá nhiều ngoại lệ
Lập trình viên khiến vấn đề liên quan tới xử lý ngoại lệ trở nên trầm trọng hơn bằng cách tạo ra nhiều ngoại lệ không cần thiết. Hầu hết chúng ta đều được dạy rằng việc phát hiện và báo cáo lỗi là quan trọng; chúng ta cũng thường hiểu theo nghĩa "càng nhiều lỗi được phát hiện thì càng tốt". Điều này dẫn đến phong cách đề phòng quá mức: bất cứ thứ gì trông có vẻ khả nghi đều sẽ trả ra ngoại lệ, dẫn đến một loại các ngoại lệ thừa thãi, làm tăng sự phức tạp của hệ thống.
Bản thân tác giả John Outsterhout cũng thừa nhận rằng bản thân đã thực hiện lỗi nghiêm trọng nhất trong sự nghiệp của mình khi thiết kế ngôn ngữ Tcl. Trong Tcl, lệnh unset được sử dụng để loại bỏ một biến. Ông thiết kế unset sao cho một ngoại lệ được trả về nếu biến không tồn tại. Ở thời điểm đó, John cho rằng nếu ai đó cố gắng xóa một biến không tồn tại, thì hẳn đây là một bug và Tcl nên thông báo nó. Tuy nhiên, một trong những công dụng thường gặp nhất của unset là dọn dữ liệu tạm (được tạo ra từ một vài hành động trước). Việc dự đoán chính xác dữ liệu nào đã được tạo thường gặp khó khăn, đặc biệt nếu các hành động được hủy bỏ giữa chừng. Thế nên, việc đơn giản nhất là xóa mọi biến có khả năng đã được tạo. Định nghĩa của unset khiến việc này không đẹp mắt: các lập trình viên phải bao bọc đoạn code sử dụng unset trong các câu lệnh catch để bắt lỗi, nhưng lại lờ đi các lỗi trả về bởi unset.
Lập trình viên thường lợi dụng ngoại lệ để tránh phải xử lý các trường hợp phức tạp: thay vì tìm ra một cách hay hơn để xử lý nó, chỉ cần ném ra một ngoại lệ và để người gọi (caller - hoặc có thể hiểu là code gọi tới) tự xử lý vấn đề. Một số tranh cãi rằng cách tiếp cận này giúp người gọi có thêm quyền quản lý, vì nó cho phép người gọi xử lý ngoại lệ bằng cách riêng. Tuy nhiên, nếu chúng ta khó xác định được lỗi và việc phải làm trong tình huống đó, thì khả năng cao là người gọi cũng không biết phải làm gì. Tạo ra một ngoại lệ trong tình huống thế này là trái với kỹ thuật Kéo sự phức tạp xuống dưới được giới thiệu ở phần trước.
Ngoại lệ được trả về bởi một class cũng là một phần trong giao diện của nó; các class với nhiều ngoại lệ có giao diện phức tạp, và chúng nông hơn là những class có ít ngoại lệ. Ngoại lệ là phần đặc biệt phức tạp trong một giao diện. Nó có thể lan truyền qua vài tầng stack trước khi được bắt và xử lý, nên nó không chỉ ảnh hưởng đến người gọi phương thức, mà (có thể) còn những người gọi ở bậc cao hơn.
Ném ngoại lệ thì dễ, nhưng xử lý chúng thì khó. Vậy nên, sự phức tạp của ngoại lệ đến từ code xử lý nó. Cách tốt nhất để giảm sự phức tạp này là giảm số lượng vị trí mà ngoại lệ phải được xử lý.
Loại bỏ ngoại lệ
Cách tốt nhất để loại bỏ sự phức tạp của việc xử lý ngoại lệ là thiết kế API sao cho không có ngoại lệ nào phải được xử lý. Điều này có vẻ thật khó chấp nhận được, nhưng lại rất hữu dụng trong thực tế. Xem lại ví dụ về lệnh unset bên trên. Thay vì ném ra một lỗi khi unset xóa một biến không tồn tại, nó nên đơn giản là thoát ra mà không cần làm gì. John nên thay đổi định nghĩa của unset một chút: thay vì xóa một biến, unset nên đảm bảo rằng biến đó sẽ không tồn tại nữa. Với định nghĩa ban đầu, unset không thể thực hiện công việc của nó khi biến không tồn tại, nên tạo ra ngoại lệ là hợp lý. Với định nghĩa thứ hai, unset được thực thi với biến không tồn tại là hoàn toàn bình thường. Trong trường hợp này, công việc của nó được hoàn thành, nên nó chỉ cần thoát ra, không có trường hợp lỗi nào để thông báo.
Ví dụ: phương thức substring trong Java
Cho hai index trong một string (xâu), phương thức substring trả về xâu con bắt đầu từ kí tự với index đầu tiên và kết thúc với kí tự ngay trước index thứ hai. Tuy nhiên, nếu một trong hai index không nằm trong string, thì phương thức sẽ ném ra ngoại lệ IndexOutOfBoundsException. Ngoại lệ này là không cần thiết và làm phức tạp phương thức. John thường xuyên rơi vào tình huống mà một hoặc hai index vượt quá khoảng của string, và ông muốn lấy ra toàn bộ kí tự trong khoảng đã cho. Tuy nhiên, phương thức substring yêu cầu ông phải kiểm tra mỗi index và làm tròn lên 0 hoặc xuống kết thúc của string; một phương thức, một dòng code bây giờ trở thành 5 đến 10 dòng code.
Phương thức substring sẽ dễ sử dụng hơn nếu nó cài đặt API như sau: "trả về các kí tự của string (nếu có) với index lớn hơn hoặc bằng beginIndex và nhỏ hơn endIndex". API này đơn giản và cũng loại bỏ được ngoại lệ IndexOutOfBoundsException. Hành vi của phương thức lúc này cũng không gặp vấn đề gì nếu một hoặc hai index đều âm, hoặc beginIndex lớn hơn endIndex. Cách tiếp cận này làm đơn giản API, đồng thời tăng tính năng của phương thức, vậy nên làm cho phương thức trở nên sâu hơn. Rất nhiều ngôn ngữ đã chọn cách tiếp cận này, chẳng hạn như Python.
Ẩn ngoại lệ
Kỹ thuật thứ hai để giảm số lượng vị trí mà ngoại lệ phải được xử lý là ẩn ngoại lệ (exception masking). Với cách tiếp cận này, điều kiện ngoại lệ được phát hiện và xử lý ở bậc thấp trong hệ thống, vậy nên các bậc cao không cần biết tới điều kiện này. Ẩn ngoại lệ đặc biệt phổ biến trong các hệ thống phân tán. Ví dụ, trong giao thức vận chuyển của mạng như TCP, các gói tin có thể bị thất lạc hoặc hư hỏng. TCP ẩn việc mất mát gói tin bằng cách cài đặt cơ chế gửi lại, thế nên dữ liệu cuối cùng cũng sẽ đến và người dùng không hề biết về các gói tin bị mất.
Kỹ thuật ẩn ngoại lệ không áp dụng được trong mọi trường hợp, nhưng sẽ rất mạnh mẽ trong những tình huống phù hợp. Nó dẫn đến các class sâu hơn, bởi giao diện được giảm (ít ngoại lệ hơn) và tính năng được thêm vào dưới dạng code ẩn ngoại lệ. Đây cũng là một ví dụ của kỹ thuật Kéo sự phức tạp xuống dưới.
Tập hợp ngoại lệ
Kỹ thuật thứ ba giúp giảm sự phức tạp liên quan tới ngoại lệ là tập hợp ngoại lệ (exception aggregation). Ý tưởng của kỹ thuật này là xử lý nhiều ngoại lệ trong một đoạn code; thay vì viết nhiều code xử lý (handler) khác nhau cho các ngoại lệ, hãy xử lý tất cả chúng ở một nơi.
Xét ví dụ xử lý request truyền thiếu tham số khi gọi đến Web server. Khi server nhận được request đến, nó điều hướng (dispatch) tới một phương thức dịch vụ để xử lý URL đó và tạo ra response. URL chứa nhiều tham số khác nhau và response sẽ phụ thuộc vào các tham số này. Mỗi phương thức dịch vụ lại gọi tới phương thức ở bậc thấp hơn (gọi là getParameter) để trích xuất tham số từ URL. Nếu URL không chứa tham số mong muốn, getParameter sẽ ném ra ngoại lệ. Hình minh họa bên dưới cho thấy một cách xử lý ngoại lệ không tốt, trong đó một số code bắt lỗi đều làm một việc giống nhau (tạo response lỗi).
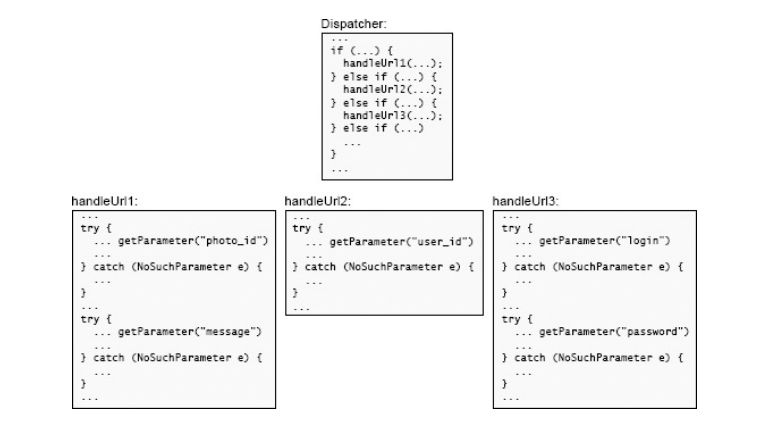
Cách tiếp cận khác tốt hơn là sử dụng kỹ thuật Tập hợp ngoại lệ. Thay vì xử lý ngoại lệ ở trong từng phương thức dịch vụ, hãy để chúng truyền (propagate) lên phương thức điều hướng của Web server (như hình bên dưới). Một đoạn code xử lý trong phương thức này có thể bắt tất cả các ngoại lệ và tạo ra response lỗi phù hợp với các tham số bị thiếu. Thông báo về lỗi có thể được tạo lúc ngoại lệ được ném ra và được đặt vào đối lượng ngoại lệ; ví dụ, getParameter sẽ tạo ra thông báo "tham số bắt buộc 'quanity' không được tìm thấy", code xử lý sẽ trích xuất thông báo này từ ngoại lệ và đưa vào response. Ngoài ra, cách tiếp cận này cũng có thể áp dụng rộng hơn trong Web server, như trong trường hợp tham số nhận được sai kiểu dữ liệu, người dùng không được cấp quyền truy cập, v.v.

Cứ để hệ thống sập
Kỹ thuật thứ tư (có thể bạn không ngờ tới) chính là cứ để cho hệ thống sập khi gặp lỗi. Trong hầu hết các ứng dụng, có một số lỗi nhất định không cần thiết phải xử lý. Thông thường, các lỗi này khó, hoặc không thể xử lý, hoặc rất ít khi xuất hiện. Trong trường hợp này, việc đơn giản nhất cần làm để phản hồi là in ra thông tin chẩn đoán (diagnostic) rồi dừng (abort) ứng dụng.
Một ví dụ là lỗi "hết bộ nhớ" (out of memory), xảy ra khi cấp phát bộ nhớ. Nếu sử dụng hàm malloc trong C, lỗi này xảy ra khi malloc trả về NULL, nghĩa là không thể cấp phát bộ nhớ như mong muốn. Đây là một hành vi không may mắn, bởi nó dẫn đến việc mỗi đoạn code gọi malloc sẽ phải kiểm tra giá trị trả về và xử lý nếu không còn bộ nhớ. Ứng dụng bao gồm rất nhiều đoạn code gọi malloc, như vậy việc kiểm tra kết quả sau mỗi lần gọi sẽ làm tăng độ phức tạp lên đáng kể. Nếu một lập trình viên quên kiểm tra (điều này có thể diễn ra thường xuyên), thì ứng dụng sẽ tham chiếu tới con trỏ NULL nếu không thể cấp phát, như vậy hệ thống sẽ sập.
Hơn nữa, một ứng dụng cũng không làm được gì nhiều khi nó phát hiện ra bộ nhớ đã cạn kiệt. Về cơ bản là ứng dụng có thể tìm các phần bộ nhớ không cần thiết để giải phóng, nhưng nếu có thì hẳn nó đã được giải phóng từ trước. Các hệ thống ngày nay có rất nhiều bộ nhớ, hay nói cách khác là bộ nhớ sẽ hầu như không bao giờ cạn kiệt; nếu như vậy, hẳn là có bug trong ứng dụng. Tóm lại, việc cố gắng xử lý lỗi hết bộ nhớ hiếm khi có ý nghĩa; điều này chỉ tạo thêm sự phức tạp để đổi lấy một chút lợi ích.
Trong các ngôn ngữ mới hơn như C++ và Java, toán tử new ném ra ngoại lệ nếu bộ nhớ đã cạn kiệt. Bắt các lỗi này thường không có ý nghĩa, bởi khả năng cao là code xử lý sẽ cố gắng cấp phát lại bộ nhớ, và điều này cũng sẽ thất bại. Tốt hơn hết là để hệ thống sập khi phát hiện ra lỗi.
Có nhiều ví dụ khác về lỗi, khi mà để hệ thống sập là hợp lý. Cho hầu hết các chương trình, nếu lỗi nhập xuất xuất hiện khi đọc hoặc ghi một file mở (chẳng hạn như lỗi ổ đĩa), hay nếu socket mạng không thể mở, ứng dụng hầu như không thể làm gì để khôi phục, vậy nên hủy bỏ với một thông báo lỗi rõ ràng là một cách tiếp cận hợp lý. Các lỗi này ít khi xảy ra, nên chúng sẽ không làm ảnh hưởng khả năng sử dụng chung của ứng dụng. Hủy bỏ với thông báo lỗi cũng phù hợp nếu ứng dụng gặp các lỗi bên trong (internal), ví dụ như một cấu trúc dữ liệu không nhất quán (điều này thường chỉ ra bug trong chương trình).
Để hệ thống sập hay không dựa trên một lỗi nhất định cũng còn phụ thuộc vào ứng dụng. Đối với hệ thống lưu trữ có sao lưu (replicated), việc hủy bỏ khi gặp lỗi nhập xuất là không hợp lý. Thay vào đó, hệ thống phải sử dụng dữ liệu đã sao lưu để khôi phục lại thông tin đã mất. Cơ chế khôi phục sẽ làm tăng thêm một lượng đáng kể sự phức tạp, nhưng khôi phục dữ liệu bị mất là một phần giá trị thiết yếu mà hệ thống này cung cấp cho người dùng.
Loại bỏ các trường hợp đặc biệt
Với lý do tương tự như việc loại bỏ ngoại lệ, việc loại bỏ các trường hợp đặc biệt cũng hợp lý. Các trường hợp đặc biệt có thể khiến code trở nên khó dò tìm với nhiều câu lệnh if, điều này khiến code khó hiểu hơn và dẫn đến bug. Như vậy, các trường hợp đặc biệt nên được loại bỏ bất cứ khi nào có thể. Cách tốt nhất để làm điều này là thiết kế các trường hợp thông thường sao cho nó tự động xử lý các trường hợp đặc biệt mà không cần viết thêm code.
Trong ví dụ về trình soạn thảo văn bản đã thảo luận ở phần trước, một nhóm các sinh viên của John đã cài đặt cơ chế chọn văn bản (bôi đen) và copy hay xóa đoạn đã chọn. Hầu hết các thiết kế đều sử dụng một biến khi cài đặt việc chọn văn bản để xác định xem đoạn văn bản đã được chọn hay không chọn đoạn nào. Các sinh viên đã chọn cách tiếp cận này, có lẽ bởi vì có những thời điểm không đoạn bôi đen nào hiển thị trên màn hình, nên cách tiếp cận trên biểu diễn hiện tượng này một cách tự nhiên khi cài đặt. Tuy nhiên, cách tiếp cận trên lại dẫn đến một loạt code kiểm tra điều kiện "không có đoạn nào được chọn" và xử lý chúng theo cách riêng.
Code xử lý việc chọn văn bản có thể được đơn giản hóa bằng cách loại bỏ trường hợp đặc biệt "không có đoạn nào được chọn". Khi không có đoạn bôi đen nào trên màn hình, nó có thể được biểu diễn với đoạn trống bôi đen, nghĩa là vị trí bắt đầu và kết thúc trùng nhau. Với cách tiếp cận này, code quản lý việc chọn văn bản không cần kiểm tra trường hợp đặc biệt trên. Khi copy một đoạn, nếu đoạn trống được chọn, 0 bytes sẽ được thêm vào vị trí mới (nếu cài đặt đúng, chúng ta cũng không cần kiểm tra 0 bytes như một trường hợp đặc biệt). Tương tự, việc xóa một đoạn trống cũng có thể được xử lý mà không cần kiểm tra trường hợp đặc biệt.
Đừng đi quá xa
Loại bỏ ngoại lệ, hay ẩn chúng bên trong một mô-đun, chỉ hợp lý nếu thông tin về ngoại lệ không cần thiết ở bên ngoài mô-đun. Điều này đúng với ví dụ về câu lệnh unset trong Tcl, hay phương thức substring trong Java.
Tuy nhiên, trong một mô-đun về giao tiếp trong mạng, một lập trình viên có thể ẩn tất cả các ngoại lệ: nếu lỗi xảy ra, mô-đun xử lý và loại bỏ nó, sau đó tiếp tục như không hề có vấn đề gì. Điều này nghĩa là các ứng dụng sử dụng mô-đun này không có cách nào để biết các tin nhắn bị mất hay server ngang hàng (peer) bị lỗi; khi không có thông tin này, chúng ta không thể xây dựng các ứng dụng mạnh mẽ. Trong trường hợp này, việc mô-đun hiển thị ngoại lệ là cần thiết, mặc dù chúng ta phải thêm sự phức tạp vào giao diện của mô-đun.
Tương tự như các lĩnh vực khác trong thiết kế phần mềm, bạn phải xác định điều gì là quan trọng và không quan trọng. Những gì không quan trọng thì nên được ẩn giấu đi, càng nhiều càng tốt. Nhưng khi điều gì đó là quan trọng, nó phải được thể hiện ra.
Tổng kết
Chìa khóa trong xử lý ngoại lệ là giảm số lượng vị trí mà ngoại lệ phải được xử lý; trong nhiều trường hợp, ý nghĩa của các hoạt động có thể được thay đổi sao cho hành vi thông thường xử lý được mọi trường hợp, không cần phải trả về ngoại lệ. Nếu không thể loại bỏ ngoại lệ, hãy thử kỹ thuật ẩn hoặc tập hợp chúng. Trong phần tiếp theo, chúng ta sẽ tiếp tục thảo luận về việc sử dụng comment.
All rights reserved
