Thiết kế phần mềm [P3] - Kỹ thuật tạo chiều sâu cho mô-đun
Bài đăng này đã không được cập nhật trong 5 năm
Như đã cùng tìm hiểu ở Phần 2 của series Thiết kế phần mềm, chúng ta đã biết rằng khái niệm mô-đun sâu đóng vai trò quan trọng trong việc giảm sự ràng buộc nói riêng, hay sự phức tạp nói chung, trong hệ thống phần mềm. Ở bài viết này, chúng ta sẽ tiếp tục đồng hành với John Ousterhout và cuốn sách Philosophy of Software Design để tìm hiểu các kỹ thuật tạo chiều sâu cho mô-đun.
1. Đóng gói thông tin
Kỹ thuật quan trọng nhất để đạt được mô-đun sâu là đóng gói thông tin (information hiding), được mô tả đầu tiên bởi David Parnas. Ý tưởng cơ bản của kỹ thuật này là mỗi mô-đun nên đóng gói (encapsulate) một vài phần thông tin mà thể hiện các quyết định trong thiết kế (design decisions). Phần thông tin được đưa vào cài đặt của mô-đun nhưng không xuất hiện ở giao diện, vậy nên không được nhìn thấy bởi người dùng.
Thông tin được đóng gói trong một mô-đun thường bao gồm các chi tiết cài đặt (như cấu trúc dữ liệu, thuật toán,...) của một số cơ chế. Ví dụ:
- Cách lưu trữ giá trị trong B-tree và cách lấy giá trị hiệu quả.
- Cách cài đặt giao thức TCP.
- Cách phân giải (parse) dữ liệu dưới dạng JSON.
Thông tin được đóng gói đó cũng có thể chứa các chi tiết ở bậc thấp hơn (lower-level) như độ lớn của một trang (page), hay các khái niệm trừ tượng hơn ở bậc cao hơn (higher-level), như việc giả sử tất cả các file đều nhỏ.
Việc đóng gói thông tin giảm sự phức tạp theo hai cách:
- Thứ nhất, nó đơn giản hóa giao diện của một mô-đun, nghĩa là mô-đun sâu hơn.
Ví dụ: Người dùng mô-đun B-tree sẽ không cần quan tâm bằng cách nào cây luôn cân bằng. - Thứ hai, nó giúp việc thay đổi cài đặt của một mô-đun không làm ảnh hưởng đến các mô-đun khác, thế nên việc phát triển hệ thống trở nên dễ dàng hơn.
Ví dụ: Nếu giao thức TCP thay đổi, thì cài đặt của nó phải được chỉnh sửa tương ứng, nhưng code gọi đến mô-đun TCP để gửi và nhận dữ liệu không cần phải thay đổi.
Khi thiết kế một mô-đun mới, chúng ta nên cân nhắc một cách kỹ lưỡng thông tin nào có thể được đóng gói. Càng đóng gói nhiều thông tin, giao diện của mô-đun càng đơn giản, và mô-đun càng sâu hơn.
Lý tưởng là khi thông tin được đóng gói hoàn toàn, tuy nhiên đóng gói không hoàn toàn cũng vẫn đem lại giá trị. Ví dụ, nếu một tính năng cụ thể hay một phần thông tin chỉ có ích với một phần nhỏ người dùng và nó có thể được truy cập thông qua các phương thức riêng biệt, thì trong hầu hết trường hợp thường gặp, thông tin đó gần như được ẩn đi. Như vậy, ít ràng buộc sẽ được tạo ra hơn.
Rò rỉ thông tin
Ngược lại với đóng gói, là rò rỉ thông tin (information leakage). Rò rỉ xảy ra khi một quyết định trong thiết kế được thể hiện ở nhiều mô-đun khác nhau. Điều này tạo ra ràng buộc giữa các mô-đun đó: bất kì thay đổi nào đến quyết định thiết kế kia cũng yêu cầu thay đổi ở toàn bộ các mô-đun liên quan. Nếu một thông tin được thể hiện ở giao diện, thì theo định nghĩa, nó bị rò rỉ; thế nên, giao diện đơn giản tương quan với đóng gói thông tin. Tuy nhiên, thông tin cũng có thể bị rò rỉ kể cả khi nó không xuất hiện ở giao diện của mô-đun. Xét hai class đều có chung một thông tin về một định dạng file nhất định (có thể là một class để đọc file, class còn lại để ghi file). Kể cả khi hai class không thể hiện thông tin đó ở giao diện của chúng, thì chúng vẫn cùng bị phụ thuộc vào định dạng file: nếu định dạng thay đổi, cả hai class cũng đều phải được chỉnh sửa. Đây được gọi là rò rỉ cửa sau (back-door leakage), và nó nguy hiểm hơn rò rỉ qua giao diện, bởi nó không rõ ràng.
Khi gặp hiện tượng rò rỉ thông tin giữa các class, để tìm ra giải pháp giảm thiểu rò rỉ, hãy đặt ra câu hỏi: "Làm thế nào để tái tổ chức các class sao cho thông tin cụ thể kia chỉ tác động đến một class?". Nếu các class tương đối nhỏ và gắn bó mật thiết (closely tied) với thông tin bị rò rỉ, gộp chúng lại thành một class duy nhất có thể là một giải pháp hợp lý. Một cách tiếp cận khác là tách thông tin rò rỉ của tất cả class ra và đóng gói nó vào một class mới. Tuy nhiên, cách này chỉ hiệu quả nếu chúng ta có thể tìm ra một giao diện đơn giản và trừu tượng tốt, hoặc không chúng ta chỉ đơn giản là thay thế rò rỉ cửa sau với rò rỉ qua giao diện.
Phân tách theo thời gian
Một nguyên nhân phổ biến gây ra rò rỉ thông tin được John Ousterhout gọi là phân tách theo thời gian (temporal decomposition). Trong cách thiết kế này, cấu trúc của hệ thống liên quan đến thứ tự thời gian mà hoạt động diễn ra. Xét một ứng dụng có thể đọc file với một định dạng nhất định, sửa nội dung của file và ghi file vào định dạng đó. Trong phân tách theo thời gian, ứng dụng có thể được chia nhỏ thành 3 class: một để đọc file, một cái khác để xử lý nội dung file, còn lại là ghi file. Cả hai bước đọc và ghi file đều sử dụng chung một thông tin về định dạng file, dẫn đến rò rỉ thông tin. Giải pháp ở đây là gộp hai cơ chế lõi của đọc và ghi file thành một class duy nhất. Class này sẽ được sử dụng cho cả hai bước đọc và ghi file trong ứng dụng. Khi thiết kế ứng dụng, hãy tập trung vào thông tin cần thiết để thực hiện mỗi tác vụ, thay vì thứ tự mà chúng được thực hiện.
Đóng gói thông tin bên trong class
Đóng gói thông tin có thể được áp dụng ở nhiều tầng khác nhau trong hệ thống, chẳng hạn như bên trong một class. Hãy cố gắng thiết kế các phương thức private bên trong class sao cho mỗi phương thức đóng gói một vài thông tin, và ẩn nó khỏi phần còn lại của class. Thêm vào đó, hãy giảm tối đa số lượng vị trí mà mỗi biến instance được sử dụng. Một số biến có thể cần được truy cập ở nhiều nơi trong class, nhưng số còn lại nên chỉ được dùng ở một vài nơi. Bằng cách này, chúng ta có thể loại bỏ ràng buộc bên trong class và giảm sự phức tạp của nó.
Đừng đi quá xa
Đóng gói thông tin chỉ phù hợp khi thông tin được đóng gói là không cần thiết ở bên ngoài mô-đun của nó. Nếu thông tin được yêu cầu từ bên ngoài mô-đun, thì chúng ta không được phép đóng gói. Giả dụ các thông số thiết lập được sử dụng nhiều cách khác nhau để tùy chỉnh hiệu suất, thì chúng nên được thể hiện ra ngoài giao diện của mô-đun.
2. Mô-đun đa năng
Một trong những vấn đề thường gặp nhất trong quá trình thiết kế mô-đun mới là quyết định cài đặt mô-đun đa năng (general-purpose) hay chuyên dụng (special-purpose). Khái niệm đa năng và chuyên dụng ở đây không liên quan tới nguyên tắc Đơn nhiệm (Single Responsibility principle).
Một số cho rằng nên chọn cách tiếp cận đa năng, trong đó chúng ta cài đặt cơ chế có thể giải quyết một mảng vấn đề rộng, chứ không chỉ giải quyết một vài vấn đề quan trọng trong hiện tại. Trong trường hợp này, cơ chế mới có thể lường trước được các công dụng cần thiết trong tương lai, vậy nên sẽ tiết kiệm thời gian cho sau này. Cách tiếp cận này cũng thống nhất với tư duy đâu tư cho thiết kế được thảo luận ở phần 1, nghĩa là chúng ta dành thêm thời gian từ ban đầu để tiết kiệm thời gian cho tương lai.
Mặt khác, chúng ta biết rằng dự đoán nhu cầu trong tương lai của một hệ thống phần mềm là không hề dễ dàng. Do đó, giải pháp đa năng có thể bao gồm các tính năng không bao giờ được dùng đến. Hơn nữa, nếu chúng ta xây dựng một thứ gì đó quá đa năng, nó có thể không xử lý tốt vấn đề trọng tâm của hiện tại. Hệ quả là, một số tranh luận cho rằng, tốt nhất hãy tập trung vào nhu cầu hiện tại, chỉ xây dựng và ưu tiên những gì chúng ta biết chắc là cần thiết. Nếu tuân theo cách tiếp cận chuyên dụng này và phát hiện thêm nhu cầu mới, chúng ta luôn có thể tái cấu trúc (refactor) hệ thống bất cứ lúc nào cần thiết. Do vậy, cách tiếp cận chuyên dụng có vẻ thống nhất với cách tiếp cận tăng tiến (incremetal approach) trong phát triển phần mềm.
Class có phần đa năng
"Make classes somewhat general-purpose." - John Ousterhout.
John Ousterhout đưa ra lời khuyên là hãy tạo class có phần đa năng. Cụm từ "có phần đa năng" nghĩa là tính năng của mô-đun chỉ phản ánh các nhu cầu hiện tại, còn giao diện thì phải đủ "rộng" (general) để hỗ trợ nhiều nhu cầu. Giao diện của mô-đun nên dễ sử dụng cho mục đích hiện tại nhưng không bị đặc biệt gắn liền với chúng. Cụm từ "có phần" ở đây rất quan trọng: đừng xây dựng thứ gì đó quá đa năng, dẫn đến việc sử dụng nó để giải quyết các nhu cầu hiện tại gặp khó khăn.
Lợi ích quan trọng nhất (và cũng có lẽ là bất ngờ) của cách tiếp cận đa năng là giao diện nhận được sẽ đơn giản hơn và sâu hơn so với cách tiếp cận chuyên dụng. Cách tiếp cận đa năng cũng có thể tiết kiệm thời gian của chúng ta trong tương lai, nếu mô-đun được tái sử dụng cho các mục đích khác. Tuy nhiên, kể cả khi mô-đun chỉ được sử dụng cho mục đích ban đầu, cách tiếp cận này vẫn tốt hơn nhờ vào sự đơn giản của nó.
Ví dụ: Trình soạn thảo văn bản
Chúng ta sẽ tham khảo một bài tập được John Ousterhout giao cho với các sinh viên của ông: xây dựng một giao diện đơn giản cho trình soạn thảo văn bản. Trình soạn thảo này phải hiển thị được file, cho phép người dùng trỏ, click và nhập để thay đổi file. Đồng thời, nó cũng phải hỗ trợ các tính năng hoàn tác (undo) và khôi phục (redo) khi chỉnh sửa file. Mỗi bài làm của các sinh viên đều chứa một class quản lý văn bản trong file, nó cung cấp các phương thức để tải file vào bộ nhớ, đọc và chỉnh sửa văn bản, cũng như ghi lại thay đổi vào file.
Nhiều sinh viên của ông đã cài đặt các API chuyên dụng cho class nói trên. Họ cho rằng class sẽ được sử dụng trong một trình soạn thảo văn bản có thể tương tác (interactive), nên đã đưa vào các tính năng chuyên dụng, ví dụ như xóa một kí tự bên trái con trỏ khi người dùng ấn phím Backspace, hay xóa một kí tự bên phải con trỏ khi ấn phím Delete.
void backspace(Cursor cursor);
void delete(Cursor cursor);
Mỗi phương thức trên đều nhận tham số là vị trí của con trỏ, được thể hiện bởi class Cursor. Trình soạn thảo cũng phải hỗ trợ xóa một đoạn văn bản được chọn. Các sinh viên đã xử lí việc này bằng cách tạo thêm class Selection và truyền đối tượng của nó vào phương thức sau:
void deleteSelection(Selection selection);
Các sinh viên trên chắc hẳn đã nghĩ rằng việc cài đặt giao diện người dùng sẽ dế hơn nhiều, nếu các phương thức của class văn bản nói trên tương ứng với các tính năng được hiển thị cho người dùng. Tuy nhiên, trong thực tế, việc chuyên dụng hóa này mang lại ít lợi ích cho code giao diện, và nó tạo ra thêm khối lượng kiến thức lớn (high cognitive load) cho lập trình viên khi làm việc với giao diện người dùng hoặc class văn bản. Class văn bản lúc này bao gồm nhiều phương thức nông, mỗi phương thức chỉ phù hợp cho một thao tác giao diện người dùng. Hệ quả là, lập trình viên làm việc với giao diện phải biết một số lượng lớn các phương thức của class văn bản.
API đa năng hơn
Một cách tiếp cận tốt hơn cho ví dụ trình biên soạn kể trên là làm cho class văn bản "chung" (generic) hơn. API nên được xác định dựa theo các tính năng cơ bản của trình soạn thảo văn bản, mà không thể hiện thao tác bậc cao (các thao tác sẽ được cài đặt bởi API này). Ví dụ, chỉ cần hai phương thức sau để xử lí việc chỉnh sửa văn bản:
void insert(Position position, String newText);
void delete(Position start, Position end);
Phương thức đầu tiên chèn một chuỗi kí tự vào một vị trí bất kì trong văn bản. Phương thức thứ hai xóa mọi kí tự từ vị trí start cho tới trước vị trí end. API này cũng sử dụng Position ("chung" hơn) thay vì Cursor (thể hiện trực tiếp giao diện người dùng). Class cũng nên cung cấp phương thức đa năng để quản lý vị trí trong văn bản, ví dụ như:
Position changePosition(Position position, int numChars);
Phương thức này trả về một vị trí mới từ vị trí position, với khoảng cách là numChars. Nếu numChars là số dương, thì vị trí mới sẽ ở sau vị trí position, và ngược lại. Phương thức cũng tự động bỏ qua dòng phía trước hoặc sau nếu cần thiết (chẳng hạn như dòng trống). Như vậy, phương thức delete ở phần trước có thể được cài đặt như sau:
text.delete(cursor, text.changePosition(cursor, 1));
Tương tự, phương thức backspace:
text.delete(text.changePosition(cursor, -1), cursor);
Với API đa năng trên, code cài đặt các hàm giao diện người dùng như delete và backspace dài hơn một chút so với cách tiếp cận (chuyên dụng) ban đầu. Tuy nhiên, code mới lại rành mạch hơn code cũ. Khi một lập trình viên muốn xóa kí tự bằng backspace: với code mới, việc này rất rõ ràng, còn với code cũ, anh ta có thể phải tìm class văn bản, đọc tài liệu (documentation) hay thậm chí đọc code của phương thức backspace để xác nhận hành vi của nó. Hơn nữa, nhìn chung, cách tiếp cận đa năng cần ít code hơn cách tiếp cận chuyên dụng, bởi nó thay thể một lượng lớn các phương thức chuyên dụng trong class văn bản bằng một số ít phương thức đa năng.
Class văn bản được cài đặt với giao diện đa năng cũng có thể được sử dụng cho các mục đích khác ngoài trình soạn thảo văn bản. Ví dụ: khi xây dựng ứng dụng thay đổi toàn bộ xuất hiện của một xâu kí tự bên trong file bằng một xâu kí tự khác, các phương thức chuyên dụng như delete hay backspace sẽ mang lại ít giá trị. Tuy nhiên, class văn bản đa năng đã có sẵn hầu hết tính năng cần thiết, tất cả những gì còn thiếu chỉ là một phương thức tìm kiếm vị trí xuất hiện kế tiếp của xâu kí tự cho trước:
Position findNext(Position start, String string);
Sự đa năng giúp đóng gói thông tin tốt hơn
Cách tiếp cận đa năng tạo ra sự phân tách rõ ràng hơn giữa class văn bản và class giao diện người dùng, điều này dẫn đến đóng gói thông tin tốt hơn. Class văn bản không cần biết các thông tin cụ thể của giao diện người dùng, như phím backspace được xử lí thế nào; những chi tiết này được đóng gói ở trong class giao diện người dùng. Một tính năng mới ở giao diện cũng có thể được thêm vào mà không cần các hàm hỗ trợ từ class văn bản. Giao diện đa năng đồng thời cũng giảm khối lượng kiến thức: lập trình viên làm việc với giao diện người dùng chỉ cần tìm hiểu một vài phương thức cơ bản trong class văn bản và sử dụng chúng cho nhiều mục đích khác nhau.
Phương thức backspace trong phiên bản đầu tiên của class văn bản đã không được trừu tượng đúng cách. Ý tưởng của nó là làm ẩn đi thông tin về kí tự bị xóa, nhưng mô-đun giao diện người dùng lại thực sự cần được biết thông tin này; lập trình viên phát triển giao diện người dùng (có khả năng) sẽ phải đọc code của phương thức backspace để kiểm chứng hành vi của nó. Việc đặt phương thức này vào trong class văn bản chỉ làm cho lập trình viên khó lấy được thông tin mà họ cần, tạo ra sự mờ mịt. Một trong những điều quan trọng nhất của thiết kế phần mềm là xác định được ai cần biết gì, và khi nào.
Các câu hỏi đặt ra khi thiết kế
Nhận ra một thiết kế class đa năng tốt (clean) dễ hơn là tạo ra nó. Dưới đây là một số câu hỏi chúng ta có thể đặt ra cho bản thân để giúp tìm ra thiết kế tốt, cân bằng giữa sự đa năng và chuyên dụng:
- Giao diện đơn giản nhất bao quát được toàn bộ nhu cầu hiện tại là gì?
- Phương thức này sẽ được sử dụng ở những trường hợp nào?
- API này có dễ dàng để sử dụng cho nhu cầu hiện tại không?
3. Lớp khác, trừu tượng khác
Hệ thống phần mềm bao gồm nhiều lớp (layers), lớp trên sử dụng hạ tầng được cung cấp bởi lớp dưới. Trong một hệ thống được thiết kế tốt, mỗi lớp có một trừu tượng khác với của lớp trên hoặc dưới của nó. Xét TCP - một giao thức tầng vận chuyển của mạng - như một ví dụ. Trong TCP, sự trừu tượng được cung cấp bởi lớp trên cùng là một chuỗi (stream) byte được vận chuyển từ máy tính này đến máy tính khác một cách tin cậy. Lớp này được xây dựng trên một lớp thấp hơn, ở đó các gói tin (packet) có độ lớn giới hạn được truyền giữa các máy tính một cách tốt nhất có thể (best-effort), nghĩa là các gói tin sẽ được chuyển đi thành công, nhưng một vài gói tin có thể bị mất hoặc truyền sai thứ tự.
Nếu trong một hệ thống chứa các lớp liên tiếp có sự trừu tượng tương tự nhau, điều này báo hiệu việc phân tách class đã có vấn đề.
Phương thức pass-through
Khi các lớp liên tiếp có sự trừu tượng giống nhau, vấn đề thường biểu lộ dưới dạng phương thức pass-through (pass-through method). Phương thức A gọi là phương thức pass-through nếu A không làm gì nhiều ngoài việc gọi đến phương thức B, trong đó kí hiệu (signature) của B lại tương tự hoặc giống hệt kí hiệu của A.
Quay trở lại với ví dụ trình soạn thảo văn bản, một nhóm sinh viên đã viết một class mà hầu như chỉ chứa toàn phương thức pass-through như sau:
public class TextDocument ... {
private TextArea textArea;
private TextDocumentListener listener;
...
public Character getLastTypedCharacter() {
return textArea.getLastTypedCharacter();
}
public int getCursorOffset() {
return textArea.getCursorOffset();
}
public void insertString(String textToInsert, int offset) {
textArea.insertString(textToInsert, offset);
}
public void willInsertString(String stringToInsert, int offset) {
if (listener != null) {
listener.willInsertString(this, stringToInsert, offset);
}
}
...
}
Các phương thức pass-through khiến cho class nông hơn; chúng chỉ khiến sự phức tạp tăng lên mà không thêm tính năng cho toàn bộ hệ thống. Các phương thức này cũng tạo ra ràng buộc giữa các class: nếu kí hiệu của phương thức insertString trong textArea thay đổi, thì phương thức insertString trong TextDocument cũng phải thay đổi tương ứng.
Các phương thức pass-through chỉ ra vấn đề trong việc phân chia nhiệm vụ giữa các class. Trong ví dụ trên, class TextDocument cung cấp phương thức insertString, nhưng tính năng chèn văn bản lại được cài đặt hoàn toàn ở TextArea. Đây luôn là một ý tưởng tồi: giao diện và cài đặt của một tính năng nên được đặt cùng một class.
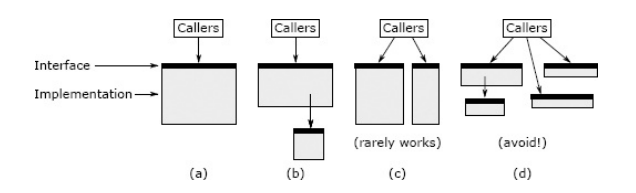
Giải pháp cho vấn đề này là cấu trúc lại các class, sao cho mỗi class có nhiệm vụ riêng biệt và rõ ràng. Hình bên dưới minh họa một vài cách để thực hiện:
Trong hình (b), class ở bậc thấp hơn được gọi trực tiếp, loại bỏ các tính năng ở class bậc cao. Một cách tiếp cận khác là phân chia lại tính năng giữa các class, điều này được thể hiện ở hình (c). Cuối cùng, nếu các cách trên không hiệu quả, thì cách tốt nhất có thể là hợp chúng lại với nhau như hình (d).
Khi nào thì giao diện có thể giống nhau?
Các phương thức có cùng kí hiệu không phải lúc nào cũng xấu. Điều quan trọng là mỗi phương thức mới nên đóng góp thêm một lượng tính năng đáng kể. Các phương thức pass-through không tốt, bởi chúng không thêm được bất kì tính năng mới nào.
Một ví dụ cho thấy việc gọi một phương thức khác có cùng kí hiệu mà vẫn hữu dụng là dispatcher (điều phối viên). Dispatcher là một phương thức sử dụng các tham số của nó để chọn ra một trong nhiều phương thức khác nhau và gọi đến. Kí hiệu của dispatcher thường giống với kí hiệu của các phương thức mà nó gọi. Dù vậy, dispatcher cung cấp một tính năng hữu dụng: nó chọn ra phương thức để tiếp tục thực hiện tác vụ. Cụ thể hơn, khi Web server nhận một HTTP request từ trình duyệt Web, nó gọi đến dispatcher để kiểm tra đường dẫn (URL) trong request và chọn ra một phương thức để xử lí request. Một vài đường dẫn có thể được xử lí bằng cách trả về một file tĩnh, số khác cần được xử lí bằng cách gọi đến các phương thức để thay đổi dữ liệu trong database. Quá trình điều phối khá phức tạp, thường được quy định bởi một tập các nguyên tắc dựa trên đường dẫn URL.
Decorators
Decorator là một mẫu thiết kế (design pattern) khuyến khích sự trùng lặp API giữa các lớp. Một đối tượng decorator lấy một đối tượng khác (gọi là A) làm cơ sở và mở rộng tính năng của A. Decorator cung cấp API tương tự hoặc giống hệt với đối tượng A, và phương thức của decorator lại gọi đến phương thức của A.
Trong ví dụ về Java I/O ở Phần 2 của series Thiết kế phần mềm, class BufferedInputStream chính là một decorator: với một đối tượng InputStream, BufferedInputStream cung cấp API giống hệt, chỉ có khác là thêm bộ đệm. Cụ thể, khi phương thức read được gọi để đọc một kí tự, nó gọi đến phương thức read của InputStream để đọc một đoạn (block) lớn hơn, sau đó lưu lại các kí tự không cần thiết cho lần đọc sau.
Mục đích của decorator là phân tách phần mở rộng chuyên dụng cho một class với phần lõi đa dụng. Tuy nhiên, các class decorator thường nông: chúng thêm vào một lượng lớn giao diện và chỉ một lượng nhỏ tính năng mới. Các class này cũng thường chứa nhiều phương thức pass-through. Chúng ta thường dễ dàng sử dụng decorator một cách dư thừa, dẫn đến việc bùng nổ các class nông, như ví dụ Java I/O.
Trước khi tạo ra một class decorator, hãy cân nhắc các lựa chọn thay thế dưới đây:
- Thêm tính năng mới trực tiếp vào class, thay vì tạo class decorator cho nó.
Lựa chọn này sẽ hợp lý nếu tính năng mới tương đối đa dụng, hoặc nó có liên kết logic với class cơ sở, hoặc hầu hết trường hợp sử dụng class cơ sở cũng sẽ sử dụng tính năng mới đó. Ví dụ: Hầu hết mọi người tạo một đối tượng InputStream trong Java cũng sẽ tạo thêm BufferedInputStream, và bộ đệm cũng rất thường xuyên được sử dụng trong nhập xuất, vậy nên hai class này nên được gộp thành một. - Nếu tính năng mới là chuyên dụng cho một trường hợp cụ thể, hãy cân nhắc gộp nó trực tiếp vào trường hợp sử dụng, thay vì tạo một class riêng.
- Gộp tính năng mới vào decorator có sẵn, thay vì tạo decorator mới.
- Tạo ra một class độc lập với các class có sẵn.
Biến pass-through
Một dạng khác của trùng lặp API giữa các lớp là biến pass-through (pass-through variable), nghĩa là một biến được truyền qua một chuỗi các phương thức.
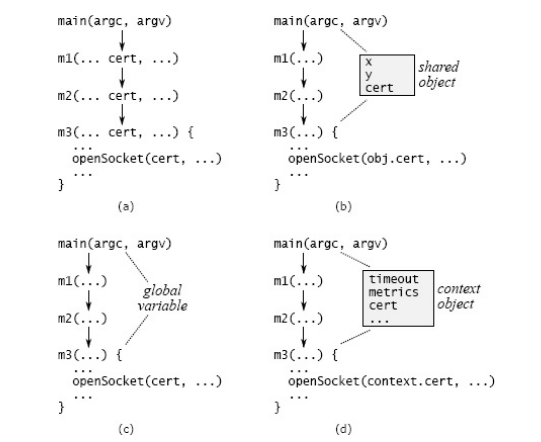
Hình (a) cho thấy một ví dụ từ một dịch vụ datacenter. Một tham số command-line mô tả các chứng chỉ (certificates) để sử dụng kết nối bảo mật. Thông tin này chỉ được sử dụng ở phương thức bậc thấp m3 (m3 gọi đến một thư viện để mở một socket), nhưng lại được truyền qua tất cả các phương thức ở giữa main và m3.
Các biến pass-through làm tăng sự phức tạp, bởi chúng buộc tất cả các phương thức trung gian phải biết đến sự tồn tại của chúng, ngay cả khi các phương thức không hề sử dụng các biến này. Hơn nữa, nếu một biến mới được thêm vào (ví dụ, ban đầu một hệ thống không hỗ trợ các chứng chỉ, nhưng được yêu cầu hỗ trợ sau đó), chúng ta sẽ phải chỉnh sửa rất nhiều giao diện và cài đặt để truyền biến này đến tới nơi cần thiết.
Việc loại bỏ các biến pass-through khá thách thức. Có ba cách tiếp cận được thể hiện ở hình trên:
- Hình (b): Sử dụng đối tượng được chia sẻ giữa phương thức ở đầu (topmost) và ở đáy (bottommost), trong ví dụ trên là main và m3.
- HÌnh (c): Sử dụng biến toàn cục.
- Hình (d): Sử dụng mẫu thiết kế context (John Ousterhout thường sử dụng cách tiếp cận này hơn).
4. Kéo sự phức tạp xuống dưới
Giả sử chúng ta đang phát triển một mô-đun mới và phát hiện ra một phần phức tạp không thể tránh khỏi. Lúc này, lựa chọn nào sẽ tốt hơn: Để cho người dùng của mô-đun tự xử lí sự phức tạp, hay tự mình xử lí sự phức tạp ở bên trong mô-đun? Nếu sự phức tạp đó có liên quan đến tính năng được cung cấp bởi mô-đun, thì câu trả lời đúng nằm ở vế sau. Hầu hết các mô-đun có lượng người dùng lớn hơn số lượng lập trình viên của mô-đun, vậy nên tốt hơn hết là để các lập trình viên này gánh chịu khó khăn thay cho người dùng. Với tư cách là một lập trình viên của mô-đun, chúng ta nên cố gắng khiến cho cuộc sống của người dùng dễ dàng nhất có thể, ngay cả khi điều đó có nghĩa là chúng ta phải làm nhiều việc hơn. Nói một cách khác, mô-đun có giao diện đơn giản quan trọng hơn là có cài đặt đơn giản.
Tuy nhiên, một lập trình viên rất dễ phá bỏ nguyên tắc trên. Nếu một điều kiện xảy ra và anh ta không biết chắc phải xử lí nó như thế nào, việc dễ nhất là tạo ra một ngoại lệ (exception) rồi để người dùng xử lí nó. Nếu người lập trình viên không biết chắc phải cài đặt chính sách (policy) nào, hẳn là anh ta có thể tạo ra một vài thông số thiết lập (configuration parameters) để điều hành chính sách và bỏ lại cho người quản trị hệ thống tự tìm giá trị tốt nhất cho chúng.
Các cách tiếp cận này sẽ làm cuộc đời người lập trình viên dễ dàng hơn trong một thời gian ngắn, nhưng nhiều người sẽ phải đối phó với vấn đề (thay vì một người). Ví dụ: nếu một class trả về ngoại lệ, mọi chương trình gọi tới class sẽ phải xử lí chúng; nếu một class đưa ra các thông số thiết lập, mọi quản trị viên sẽ phải học cách để thiết lập chúng.
Ví dụ: Thiết lập thông số
Việc thiết lập các thông số là một ví dụ của việc đẩy sự phức tạp lên, thay vì kéo xuống. Một class có thể đưa ra một vài thông số để điều khiển hành vi của nó, ví dụ như độ lớn của bộ đệm, hoặc số lần thử lại nếu một request bị lỗi liên tục. Người dùng của class sẽ phải tìm các giá trị phù hợp cho các tham số. Điều này đã trở nên cực kì phổ biến trong các hệ thống ngày nay, một vài hệ thống có tới hàng trăm thông số.
Những người ủng hộ cho rằng các thông số thiết lập rất cần thiết, bởi chúng cho phép người dùng tùy chỉnh hệ thống tùy theo nhu cầu của họ. Ví dụ, người dùng có thể biết được tác vụ nào cần được thực hiện nhanh chóng, nên sẽ hợp lý nếu để họ thiết lập độ ưu tiên cho các tác vụ riêng biệt.
Tuy nhiên, các thông số thiết lập cũng là cái cớ để dễ dàng trốn tránh việc xử lí các vấn đề quan trọng và đẩy chúng cho người khác. Trong nhiều trường hợp, người dùng hay quản trị viên khó (hoặc không thể) xác định được giá trị phù hợp cho các tham số. Trong các trường hợp khác, giá trị phù hợp có thể được xác định tự động với một chút công sức bỏ ra để cài đặt thêm cho hệ thống. Xét một giao thức mạng phải xử lí các gói tin bị mất. Nếu một request được gửi nhưng không có phản hồi trong một khoảng thời gian nhất định, request cần được gửi lại. Một cách để xác định khoảng thời gian chờ trước khi gửi lại là tạo một thông số thiết lập. Tuy nhiên, giao thức vận chuyển có thể tự tính toán một giá trị phù hợp bằng cách theo dõi thời gian phản hồi thành công trước đó. Cách tiếp cận này kéo sự phức tạp xuống dưới và tiết kiệm công sức, thời gian cho người dùng. Ngoài ra, cách tiếp cận này còn có một ưu điểm khác là tính toán thời gian chờ linh động, nên giá trị của thời gian chờ sẽ tự động thay đổi nếu điều kiện vận hành thay đổi. Ngược lại, tham số thiết lập bởi người dùng lúc này có thể dễ dàng bị lỗi thời.
Lý tưởng là mỗi mô-đun giải quyết vấn đề một cách triệt để; các tham số thiết lập dẫn đến một giải pháp không hoàn chỉnh, điều này làm tăng lên sự phức tạp của hệ thống.
Đừng đi quá xa
Một cách tiếp cận cực đoan theo ý tưởng này là kéo tất cả tính năng của một ứng dụng vào một class duy nhất, điều này rõ ràng là không hợp lý. Kéo sự phức tạp xuống dưới chỉ phù hợp, nếu:
- Sự phức tạp được kéo xuống có liên quan chặt chẽ với các tính năng hiện có trong class.
- Nhiều phần trong ứng dụng được đơn giản hóa.
- Giao diện của class được đơn giản hóa.
Hãy cùng nhìn lại phương thức cài đặt tính năng backspace trong ví dụ trình soạn thảo. Thoạt đầu, nó trông có vẻ tốt, vì sự phức tạp được kéo xuống dưới. Tuy nhiên, việc thêm khối lượng thông tin của giao diện người dùng vào class văn bản không làm đơn giản code bậc cao hơn nhiều, và thông tin về giao diện cũng không liên quan tới tính năng lõi của class văn bản. Trong trường hợp này, việc kéo sự phức tạp xuống chỉ dẫn đến rò rỉ thông tin.
Tóm lại, nên ghi nhớ rằng, mục đích của chúng ta là làm giảm sự phức tạp chung của toàn hệ thống.
5. Gộp chung hay tách riêng?
Một trong những câu hỏi cơ bản nhất trong thiết kế phần mềm, đó là: với hai phần tính năng, nên cài đặt chúng ở cùng một nơi, hay phần cài đặt của chúng nên được tách riêng? Câu hỏi này được áp dụng ở mọi cấp bậc trong một hệ thống, như các hàm, phương thức, class, hay dịch vụ. Ví dụ, liệu bộ đệm có nên được bao gồm trong class xử lí file I/O? Việc phân giải (parsing) một HTTP request nên được cài đặt toàn bộ trong một phương thức, hay nên được chia thành nhiều phương thức khác nhau (hay thậm chí là nhiều class khác nhau)?
Khi quyết định nên gộp chung hay tách riêng, mục tiêu của chúng ta là giảm sự phức tạp của toàn bộ hệ thống và tăng tính mô-đun. Cách tốt nhất để đạt được mục đích này có vẻ là chia hệ thống thành nhiều thành phần nhỏ: các thành phần càng nhỏ, thì mỗi thành phần (có vẻ) càng đơn giản hơn. Tuy nhiên, việc chia nhỏ cũng làm tăng sự phức tạp so với trước khi chia:
- Số lượng thành phần lớn làm tăng sự phức tạp: càng nhiều thành phần thì càng khó để theo dõi chúng, lại càng khó để tìm ra thành phần mong muốn. Việc chia nhỏ thường xuyên tạo ra nhiều giao diện hơn, và mỗi giao diện lại làm tăng thêm sự phức tạp.
- Việc phân tách cũng cần nhiều code hơn để quản lý các thành phần. Ví dụ, một đoạn code sử dụng một đối tượng trước khi chia nhỏ, giờ có thể phải quản lý nhiều đối tượng khác nhau.
- Việc chia nhỏ tạo ra sự chia cách: các thành phần được phân tách sẽ trở nên xa nhau hơn, so với trước khi chúng được tách ra. Ví dụ, các phương cùng thuộc một class, sau khi được phân tách thì có thể nằm ở các class ở những file khác nhau. Sự chia cách này khiến lập trình viên khó quan sát được các thành phần cùng một lúc, hoặc biết đến sự tồn tại của chúng. Nếu các thành phần hoàn toàn độc lập, thì sự chia cách là tốt: lúc này, lập trình viên có thể tập trung vào một thành phần duy nhất tại một thời điểm, không bị phân tâm bởi phần còn lại. Ngược lại, nếu các thành phần có ràng buộc, thì chia tách là ý tưởng tồi: lập trình viên phải di chuyển qua lại giữa các thành phần. Hoặc tệ hơn, họ có thể không hề biết đến các sự ràng buộc, điều này rất có thể dẫn đến bug.
- Việc phân tách có thể dẫn đến trùng lặp: code trong một thành phần trước khi được chia nhỏ, giờ có thể phải xuất hiện ở mỗi thành phần sau khi được chia nhỏ.
Gộp chung các đoạn code sẽ mang lại lợi ích nếu chúng có liên quan chặt chẽ với nhau. Nếu chúng không có sự liên quan, thì có lẽ nên được phân tách riêng. Sau đây là một số chỉ dẫn cho thấy hai đoạn code có liên quan với nhau:
- Chúng chia sẻ cùng một thông tin. Ví dụ, hai class chia sẻ cùng một thông tin về định dạng file như đã thảo luận ở phần Rò rỉ thông tin.
- Chúng được sử dụng cùng nhau: một người dùng sử dụng đoạn code này, thì cũng có nhiều khả năng sẽ sử dụng đoạn code kia. Dạng quan hệ này chỉ đáng lưu ý nếu chúng là từ hai phía. Ví dụ, hầu hết cơ chế disk block cache sử dụng cấu trúc dữ liệu hash table, nhưng hash table cũng có thể sử dụng ở nhiều trường hợp khác không liên quan tới block cache; vậy nên các mô-đun này nên được phân tách.
- Cả hai đoạn code cùng thuộc một khái niệm bậc cao. Ví dụ, tìm kiếm xâu con (substring) và chuyển đổi viết hoa/ thường (case conversion) đều thuộc nhóm xử lí xâu (string manipulation).
- Một đoạn code trở nên khó hiểu khi chỉ đọc nó mà không chú ý tới đoạn code khác.
Gộp chung nếu cùng chia sẻ một thông tin
Trong một bài tập về cài đặt HTTP server của John Outserhout, một nhóm sinh viên đã cài đặt bằng cách tạo hai class để đọc và phân giải HTTP request. Class thứ nhất có phương thức đọc, dùng để đọc nội dung văn bản trong request và đặt nó vào một xâu kí tự. Class thứ hai cung cấp phương thức phân giải và lấy ra các thành phần khác nhau của request. Trong cách tiếp cận này, cả hai phương thức đều chia sẻ một lượng lớn thông tin về định dạng (format) của HTTP request. Phương thức đầu tiên chỉ đọc request, không phân giải nó, nhưng không thể xác định kết thúc của request mà không thực hiện vài công việc phân giải (ví dụ, phải phân giải được header để xác định trường Content-Length, tức là độ dài nội dung của request), việc này dẫn đến code xử lí phân giải bị trùng lặp ở cả hai class. Bởi vì thông tin được chia sẻ này, tốt nhất nên gộp hai class thành một, như vậy code sẽ ngắn và đơn giản hơn.
Gộp chung nếu có thể làm đơn giản giao diện
Khi hai hay nhiều mô-đun được gộp thành một, giao diện của mô-đun mới có thể đơn giản và dễ dùng hơn các giao diện ban đầu, đặc biệt khi các mô-đun ban đầu chỉ cài đặt một phần giải pháp của vấn đề. Trong ví dụ về Java I/O, nếu FileInputStream và BufferedInputStream được gộp thành một và bộ đệm được sử dụng mặc định, thì đa số người dùng sẽ chẳng cần biết tới sự tồn tại của bộ đệm. Class được gộp lại mới có thể cung cấp các phương thức để tắt sử dụng hoặc thay thế bộ đệm, nhưng phần lớn người dùng không cần nghiên cứu về chúng.
Gộp chung để loại bỏ trùng lặp
Nếu tìm thấy những đoạn code giống nhau và lặp đi lặp lại, hãy thử tổ chức lại code để loại bỏ sự trùng lặp. Một cách tiếp cận là tách và thay thế các đoạn code bị lặp bằng một phương thức riêng. Cách này sẽ hiệu quả nhất nếu đoạn code bị lặp dài, và phương thức thay thế có kí hiệu đơn giản. Nếu đoạn code lặp chỉ dài một hay hai dòng, việc thay thế sẽ không mang lại nhiều giá trị. Nếu đoạn code tương tác với môi trường của nó một cách phức tạp (ví dụ, truy cập nhiều biến cục bộ), thì phương thức thay thế có thể cần một kí hiệu phức tạp (ví dụ, nhiều tham số truyền bằng địa chỉ), điều này lại càng làm giảm lợi ích.
Phân tách code đa năng và code chuyên dụng
Nếu mô-đun chứa một cơ chế được sử dụng cho nhiều mục đích, thì nó chỉ nên cung cấp một mình cơ chế đa năng đó. Mô-đun không nên chứa cả code chuyên dụng cho một mục đích sử dụng nhất định, lẫn cả code đa năng. Code chuyên dụng nên được đặt ở một mô-đun khác. Trong ví dụ trình soạn văn bản, thiết kế tốt nhất là class văn bản được cài đặt đa năng, trong khi các thao tác cụ thể với giao diện người dùng được cài đặt ở mô-đun giao diện. Cách tiếp cận này loại bỏ rò rỉ thông tin và giảm số lượng giao diện so với thiết kế ban đầu.
Nói chung, trong một hệ thống, các lớp ở bậc thấp hơn (lower layers) có xu hướng đa năng, còn các lớp ở bậc cao hơn (upper layers) xử lí tính năng cụ thể của ứng dụng.
Áp dụng với phương thức
Những phương thức dài thường khó hiểu hơn những phương thức ngắn, vậy nên nhiều người tranh luận rằng có thể chỉ cần sử dụng độ dài để đánh giá việc chia nhỏ một phương thức. Chúng ta thường thấy các lời khuyên chắc nịch như "hãy chia nhỏ bất kì phương thức nào dài quá 20 dòng!".
Tuy nhiên, một mình độ dài hiếm khi là một lý do tốt để chia nhỏ một phương thức. Nhìn chung, các lập trình viên có xu hướng phân tách phương thức quá nhiều. Việc chia tách tạo ra thêm nhiều giao diện, nghĩa là tăng sự phức tạp. Đồng thời, chia tách một phương thức làm code trở nên khó đọc hơn nếu các đoạn code được tách khỏi nhau lại thực chất có liên quan với nhau. Chúng ta không cần chia nhỏ một phương thức, trừ khi hệ thống nói chung sẽ đơn giản hơn.
Phương thức dài không phải lúc nào cũng tệ. Ví dụ, giả sử một phương thức bao gồm 5 đoạn (block), mỗi đoạn dài 20 dòng, và các đoạn được thực thi theo thứ tự. Nếu các đoạn tương đối độc lập, phương thức có thể được đọc hiểu theo từng đoạn một; việc chia các đoạn thành các phương thức riêng biệt không mang lại nhiều lợi ích. Nếu các đoạn tương tác với nhau một cách phức tạp, thì việc giữ chúng cùng nhau lại càng quan trọng; bởi nếu chia nhỏ, người đọc sẽ phải đổi qua lại giữa các phương thức để hiểu cách chúng làm việc với nhau. Các phương thức gồm hàng trăm dòng code được coi là ổn, nếu chúng dễ đọc hiểu và có giao diện đơn giản. Điều này là tốt bởi các phương thức đều sâu (nhiều tính năng, giao diện đơn giản). Hãy xem đoạn phương thức sau: TransportDispatcher.cc. Có thể thấy rằng các đoạn code trong phương thức trên tương đối độc lập với nhau, vậy nên mặc dù dài hơn 500 dòng nhưng phương thức không cần thiết phải được chia nhỏ.
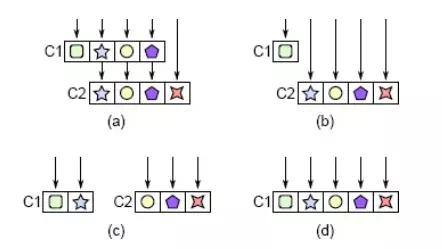
Dưới đây trình bày một số cách để phân tách một phương thức lớn (như hình (a)) thành nhiều phương thức nhỏ hơn:
- Hình (b): Cách tiếp cận này có ý nghĩa nếu tác vụ con (được xử lí trong phương thức con) được phân tách rõ ràng khỏi phần còn lại của phương thức ban đầu, nghĩa là người dùng khi đọc phương thức con sẽ không cần biết về phương thức cha, và khi đọc phương thức cha cũng không cần hiểu cách cài đặt của phương thức con. Thông thường, điều này cũng có nghĩa là phương thức con tương đối đa năng. Nếu sau khi chia tách, người dùng phải di chuyển qua lại giữa các phương thức để hiểu cách chúng làm việc cùng nhau, thì đây hẳn là một ý tưởng tồi.
- HÌnh (c): Cách tiếp cận này chỉ phù hợp nếu giao diện của phương thức ban đầu quá phức tạp, vì nó cố gắng làm nhiều thứ không liên quan một lúc. Trong trường hợp này, việc chia tính năng của phương thức vào nhiều phương thức nhỏ hơn có thể khả thi, dẫn đến các giao diện đơn giản hơn. Nếu các phương thức mới đa năng hơn phương thức ban đầu, thì đây là dấu hiệu tốt.
- Hình (d): Việc chia tách như hình (c) thường không hợp lý bởi người dùng sẽ phải gọi đến nhiều phương thức thay vì một, và truyền nhiều dữ liệu qua lại giữa chúng. Khi chia nhỏ như hình (c), hãy cân nhắc, liệu cách tiếp cận có giúp người dùng làm việc đơn giản hơn.
Tóm lại, khi thiết kế các phương thức, mục tiêu quan trọng nhất là cung cấp trừu tượng tốt và đơn giản. Mỗi phương thức chỉ nên thực hiện một nhiệm vụ và thực hiện một cách triệt để. Phương thức nên có giao diện đơn giản, như vậy người dùng không phải giữ quá nhiều thông tin trong đầu để sử dụng nó chính xác. Đồng thời, phương thức cũng nên có chiều sâu. Nếu một phương thức thỏa mãn tất cả tính chất trên, thì việc nó dài hay ngắn không quan trọng.
Tổng kết
Ở bài viết này, chúng ta đã tìm hiểu các kỹ thuật tạo chiều sâu cho mô-đun. Xử lí ngoại lệ (exception handling) sẽ là chủ đề chính được thảo luận ở phần tiếp theo.
All rights reserved
