
Tf-idf algorithm, Text retrieval and Search engines
Bài đăng này đã không được cập nhật trong 6 năm
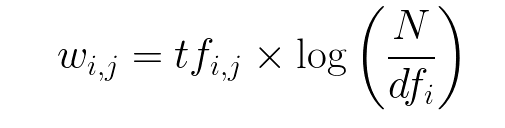
1.TF-IDF
Tf-idf là viết tắt của cụm từ: Term frequence -Inverse document frequency . Đây là một kĩ thuật rất nổi tiếng, được sử dụng trong nhiều bài toàn NLP và khai phá dữ liệu dạng văn bản với mục đích: tính weight (độ quan trọng) của word trong một văn bản cụ thể, văn bản đó nằm trong một tập nhiều văn bản khác nhau. Bản thân tên gọi này đã thể hiện được nội dung thuật toán
- Term frequence: tần xuất xuất hiện của từ w trong văn bản d
- Inverse document frequency: Nghịch đảo của '(số văn bản chứa từ w)/(tổng số văn bản)'.
Tư tưởng của thuật toán rất đơn giản: một từ xuất hiện nhiều trong 1 văn bản, nhưng lại ít xuất hiện trong cả dataset thì độ quan trọng của nó càng cao. Ngược lại, một từ xuất hiện ở hầu hết các văn bản thì có độ quan trọng càng thấp. Bằng thuật toán này, người ta có thể xác định ra các stop word (mang ít ngữ nghĩa như: a, an, the ...)
1.1.TF
Để hiểu rõ công thức, ta giả sử:
- Có 1 tập D gồm M văn bản.
- Văn bản d D có m từ, từ vựng w xuất hiện c(w,d) lần.
- từ vựng w xuất hiện trong f(w, D) văn bản
TF: Term frequence - tần xuất xuất hiện của w trong d. Một từ w xuất hiện trong văn bản d càng nhiều thì độ quan trọng của nó càng cao. Ta có:
- .
1.2.IDF
Tư tưởng của IDF: một từ xuất hiện trên càng nhiều văn bản, độ quan trọng từ đó càng giảm. VD các stop word như a, an, the, i .... xuất hiện trên hầu hết các văn bản, ngữ cảnh, độ quan trọng của những từ này thường rất thấp.
Người ta định nghĩa công thức IDF(w, D) = log
Như vậy tf-idf của từ w trong văn bản d trên tập D là:
- TF-IDF(w, d, D) = *
2.Thuật toán text search
2.1 Document vectorization
Bước đầu tiêu của thuật toán search, ta cần phải vectorize các document (vector hoá). Tức cần phải chuyển đổi dạng văn bản dạng string thành vector. Phương pháp đơn giản nhất là bag of word .
2.1.1 Bag of word
Giả sử ta có 1 dataset gồm 5 câu:
- “There used to be Stone Age”
- “There used to be bronze age”
- “There used to be Iron Age”
- “There was age of revolution”
- “Now it is Digital Age”
Toàn bộ dataset có 15 từ vựng --> mỗi văn bản là 1 vector có độ dài 15. Với 1 văn bản, từ vựng nào xuất hiện thì giá trị tại đó bằng 1, từ nào không xuất hiện thì giá trị bằng 0. Sau khi "bag of word", ta có thu được kết quả:
- There used to be bronze age = [1,0,1,1,1,0,1,0,0,0,1,0,0,0,0]
- There used to be iron age = [1,0,1,1,1,0,0,1,0,0,1,0,0,0,0]
- There was age of revolution = [1,1,0,0,0,0,0,0,1,0,1,1,0,0,0]
- Now its digital Age = [0,0,0,0,0,0,0,0,0,1,1,0,1,1,1]
2.1.2 Tf-Idf vectorization
Ngoài bag_of_word, ta có thể sử dụng tf-idf vectorization, phương pháp này giúp cải thiện kết quả đầu ra rất nhiều. Phương pháp này rất dễ hiểu, với 1 document d, thay vì gán giá trị 1 cho các từ vựng xuất hiện trong d, ta gán giá trị tf-idf tương ứng của từ đó trong d. VD sau khi tính toán, ta được:
- "There used to be bronze age" = [0.23 , 0 ,0.22 , 0.13, 1.2 ,0, 1.4 , 0,0,0, 0.99 , 0, 0, 0, 0]
(giá trị do mình tự bịa ra thôi :p )
2.2 Similarity
Gọi những đoạn truy vấn người dùng nhập vào là query. Các document được vector hoá và lưu vào database. Ta cũng vector hoá tương tự với query. Về mặt lý thuyết, query và document (văn bản người dùng muốn tìm) sẽ cùng chứa những từ khoá giống nhau. VD khi người dùng lên shopee nhập query="áo len mùa đông", thì các sản phẩm nào có chưa "áo", "áo_len", "mùa_đông", sẽ hiện ra trước tiên. Như vậy, để tìm kiếm document với 1 query, ta cần tính độ tương đồng (similarity) giữa query_vector với vector của từng document. Document nào cho similarity càng lớn, chứng tỏ kết quả càng sát với những gì user muốn.
Độ do similarity giữa 2 vector thường được dùng là cosin:
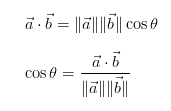
Thực hành.
Dataset
Để dễ hiểu, chúng ta sẽ tiến hành code thuật toán này với tập dataset do mình crawl từ shopee. Các sản phẩm rất đa dạng từ quần áo, giày dép, đồng hồ, kính mắt. Dataset được chia thành 97 file json. Mỗi file json là 1 mảng các object với các trường thông tin về sản phẩm như: tên gọi, kích thước, chủng loại, nhà sản xuất, mô tả chi tiết ... Code và dataset bạn có thể dễ dàng tải về tại https://github.com/trungthanhnguyen0502
Code
Import các thư viện cần thiết. Trong các thư viện này, đặc biệt nhất có underthesea có hàm word_tokenize rất hay dùng để phân đoạn lại từ đơn, từ ghép (VD: tôi ăn uống và mặc quần áo ---> tôi ăn_uống và mặc quần_áo)
import numpy as np
import sklearn
import underthesea
import json
import os
from tqdm.autonotebook import tqdm
from glob import glob
from pprint import pprint
import nltk
from underthesea import word_tokenize
from sklearn.decomposition import TruncatedSVD
import math
import sklearn
Load dataset
json_fns = glob("./dataset/*.json")
items = []
for fn in json_fns:
with open(fn, "r") as f:
items += json.load(f)
print(items[0])
### result
{'Danh Mục': 'danh mục thời trang nữ phụ kiện may mặc',
'Gửi từ': 'gửi từ quận hai bà trưng hà nội',
'Kho hàng': 'kho hàng 33933',
'Thương hiệu': 'thương hiệu no brand',
'desc_2': 'vải voan lươi mêm loại 1 khổ vải rộng 17m chiều dài khách đặt số '
'lượng bao nhiêu cắt khổ vải dài bấy nhiêu ví dụ khách ấn màu đỏ '
'đặt mua số lượng 10 thì em sẽ cắt 1 tấm vái dài 10m rộng 17m chất '
'liệu mềm mịn độ phồng cao có nhiều màu sắc phong phú cho khách lựa '
'phôngnền',
'price': '15000',
'title': 'vải voan lưới mềm loại 1 15k 1m '}
Các hàm xử lí và chuẩn hoá lại text
def word_tokenizer_item(item):
'''
Word tokenize for all field in a item
'''
for key in item.keys():
item[key] = word_tokenize(item[key], format='text')
return item
Đếm số lần xuất hiện mỗi từ trong một văn bản
def count_unigram(text):
'''
Count appearance number for each vocabulary
'''
counter = {}
words = text.split()
vocabs = set(words)
for vocab in vocabs:
if not vocab.isdigit():
counter[vocab] = words.count(vocab)
return counter
Các sản phẩm có rất nhiều các trường thông tin khác nhau. Để đơn giản hoá tính toán, mỗi sản phẩm ta gộp các trường thông tin đó thành hai trường name và desc.
def combine_metadata(item):
newItem = {}
newItem['name'] = item['title']
newItem['desc'] = ""
for key in item.keys():
newItem["desc"] += f" . {item[key]}"
return newItem
def count_word_in_dataset(items):
'''
Thống kê số lần xuất hiện từng từ trên toàn bộ dataset
'''
nameCounter = {}
descCounter = {}
for item in items:
for word in item['unigram_name'].keys():
if word in nameCounter.keys():
nameCounter[word] += 1
else:
nameCounter[word] = 1
for word in item['unigram_desc'].keys():
if word in descCounter.keys():
descCounter[word] += 1
else:
descCounter[word] = 1
return nameCounter, descCounter
Thống kê số lần xuất hiện của mỗi từ trong từng sản phẩm (mỗi sản phẩm được coi là 1 document)
newItems = []
for item in tqdm(items):
newItem = word_tokenizer_item(item)
newItem = combine_metadata(newItem)
newItem['unigram_name'] = count_unigram(newItem['name'])
newItem['unigram_desc'] = count_unigram(newItem['desc'])
newItems.append(newItem)
Công thức tính tf-idf cho 1 document, doc_counter là 1 biến lưu số lần suất hiện từng từ trong 1 document, corpus_counter là biến lưu số lần xuất hiện từng từ trong toàn bộ dataset. Kết quả trả về là 1 vector cho document.
def tfidf(doc_len, corpus_len, doc_counter, corpus_counter, k=2):
vector_len = len(corpus_counter)
tfidf_vector = np.zeros((vector_len,))
for i, key in enumerate(corpus_counter.keys()):
if key in doc_counter.keys():
tf = (k+1)*doc_counter[key]/(k+doc_counter[key])
idf = math.log((corpus_len+1)/(corpus_counter[key]))
tfidf_vector[i] = tf*idf
return tfidf_vector
Tính vector cho description_document cho từng sản phẩm
nameCounter, descCounter = count_word_in_dataset(newItems)
tfidf_vectors = []
corpus_len = len(newItems)
for item in tqdm(newItems):
doc_len = len(item['desc'])
tfidf_vectors.append(
tfidf(doc_len, corpus_len, item['unigram_desc'], descCounter)
)
Giảm chiều dữ liệu với SVD, thay vì sử dụng những vector có số chiều rất lớn (dimension~10000), ta giảm chiều vector xuống còn 256. Bạn có thể tham khảo thêm về thuật toán SVD tại machinelearningcoban .
svd = TruncatedSVD(n_components=256)
svd.fit(tfidf_vectors)
svd_tfidf_vector = svd.transform(tfidf_vectors)
Để tiết kiệm thơi gian, mình lấy luôn 1 vector đầu tiên trong list làm vector query (bạn có thể vector hoá 1 chuỗi query bất kì). Tính độ tương đồng giữa query_vector và tất cả các vector còn lại, sắp xếp theo giá trị giảm dần.
query_vector = tfidf_vectors[0]
query_vector = np.reshape(query_vector, (1,-1))
# search
sim_maxtrix = sklearn.metrics.pairwise.cosine_similarity(query_vector, tfidf_vectors)
sim_maxtrix = np.reshape(sim_maxtrix, (-1,))
idx = (-sim_maxtrix).argsort()[:20]
for _id in idx:
print(_id, sim_maxtrix[_id])
print(newItems[_id]['name'].upper())
print(newItems[_id]['desc'], "\n\n")
Sản phẩm đầu tiên chính là sản phẩm được lấy làm query_vector nên là sản phẩm đúng nhất. Ta có thể thấy, trong hàng ngàn sản phẩm đủ mọi mặt hàng nhưng các kết quả trả về đều liên quan tới sản phẩm đầu tiên. Kết qủa trông rất khả quan, đều liên quan tới mặt hàng "váy lưới chấm bi Hàn Quốc" 

Như vậy là mình đã hướng dẫn xong các bạn thuật toán lõi. Trong thực tế thì bài toán khó hơn 1 chút bởi tình trạng "những keyword user vào thường không hoàn toàn giống những gì user nghĩ đến". Nếu có thời gian, mình sẽ viết thêm những thuật toán cải thiện tình trạng này.
All rights reserved
