
Tạo dữ liệu cho bài toán OCR Tiếng Việt trong 5 bước.
Bài đăng này đã không được cập nhật trong 5 năm
Bài toán OCR hay nhận dạng chữ Tiếng Việt đã không còn xa lạ và đã được ứng dụng vào rất nhiều cuộc sống như ứng dụng trích xuất thông tin văn bản, số hóa dữ liệu, ... đã thu được rất nhiều thành quả đáng kinh ngạc. Và bài toán OCR cũng là một chủ đề có độ khó vừa phải để những người mới bắt đầu cũng có thể học, nghiên cứu thu thập nhiều kiến thức mới. Tuy nhiên làm sao để chúng ta tạo được những mô hình OCR, điều đầu tiên chúng ta cần phải có là dữ liệu. Đúng chính xác rồi đó chính là dữ liệu. Dù là bài toán Object Detection, Segmentation, Classification thì điều cần phải có là dữ liệu. Ý dữ liệu mình nói ở đây là một dữ liệu "tốt" còn tốt như thế nào thì tùy vào các bài toán, kỳ vọng chúng ta sẽ có những cách đánh giá khác nhau.
Dữ liệu cho bài toán OCR, theo ý kiến cá nhân của mình có thể chia làm hai loại:
- Dữ liệu thật
- Dữ liệu nhân tạo
Dữ liệu thật đó là những dữ liệu có trong ngoài thực tế như ảnh một câu hoặc một từ mình cắt ra rồi chúng ta sẽ gán nhãn nội dung cho từng ảnh tương ứng.
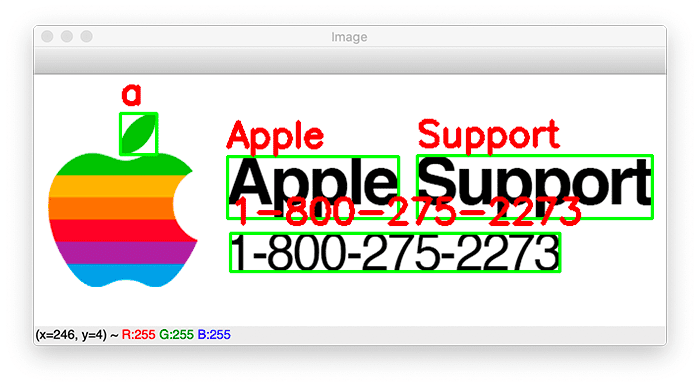 Ảnh minh họa. (Nguồn Internet)
Ảnh minh họa. (Nguồn Internet)
Dữ liệu nhân tạo theo mình định nghĩa ở đây là dữ liệu do con người tạo ra bằng các đoạn chương trình. Một số phương pháp mà các bạn cũng khá quen thuộc là augmentation giúp làm đa dạng dữ liệu của bạn bằng một số cách như làm nhiễu ảnh, làm mờ, xoay ngang, xoay dọc,..... Tuy nhiên cách này không giúp chúng ta đa dạng về nội dung ảnh ở đây là ý mình nói là chữ trong ảnh. Vì vậy hôm nay mình sẽ giới thiệu cho các bạn một phương pháp có thể dễ dàng tạo dữ liệu OCR để có thể ứng dụng vào trong học tập, nghiên cứu. Nào cùng mình tìm hiểu nhé
1. Tải mã nguồn
Ở đây mình có sử dụng một tool sinh dữ liệu của repo TextRecognitionDataGenerator. Tuy nhiên, để chuẩn bị sẵn các dữ liệu cần thiết để các bạn có thể thực hành sử dụng ngay thì các bạn có thể tải về repo mình nhé.
git clone https://github.com/buiquangmanhhp1999/ImageTextGenerator.git
2. Cài đặt môi trường
pip -r requirements.txt
3. Tìm hiểu một số cấu hình cần biết
Trong repo này tác giả cung cấp rất nhiều cấu hình khác nhau hỗ trợ việc sinh ảnh trong file run.py. Việc tìm hiểu hết tất cả các chức năng tốn nhiều thời gian. Mình sẽ cung cấp cho các bạn một số cấu hình mà sẽ được sử dụng nhiều trong thực tế.
Các tham số chính:
- -c hoặc --count: Số lượng ảnh cần tạo.
- -f hoặc --format: Chiều cao của ảnh được tạo ra
- -t hoặc --thread_count: Số lượng luồng dùng trong quá trình sinh ảnh. Càng nhiều luồng thì tốc độ sinh ảnh càng nhanh
- -i hoặc --input_file: đường dẫn tới file text chứa text sẽ được chuyển thành ảnh.
- --output_dir: đường dẫn tới thư mục chứa ảnh sau khi tạo
- --font_dir: đường dẫn tới thư mục chứa font chữ.
- --image_dir: đường dẫn tới thư mục chứa ảnh nền.
- -b hoặc --background: Nhận một trong 4 giá trị: 0, 1, 2, 3, 4.
- -cs hoặc --character_spacing: khoảng cách giữa hai kí tự.
- -sw hoặc --space_width: khoảng cách giữa hai từ
Ngoài ra còn có một số tham số cấu hình khác như:
- -e hoặc --extension: định dạng file ảnh sẽ được sinh ra. Ví dụ: jpg, png, jpeg, ....
- -rk hoặc --random_skew: độ nghiêng tối đa của text trong ảnh. Chỉ nhận giá trị dương
- -bl hoặc --blur: mức làm mờ ảnh bằng nhiễu Gausian.
- -na hoặc --name_format: cách địng dạng tên ảnh sẽ được lưu. Tham số này nhận một trong ba giá trị 0, 1, 2. Trong đó: 0: TEXT_ID.EXT; 1: ID_TEXT.EXT; 2: ID.EXT + file labels.txt chứa tên nhãn và ảnh tương ứng. Mình thì hay dùng option 2 hơn vì có một số text chứa các ký tự đặc biệt như: //, /,... hay bị nhầm thành đường dẫn khi dùng các định dạng khác.
- -tc hoặc --text_color: mã hexa tương ứng với màu chữ trong ảnh cần sinh ra. Màu đen mình thường để mặc địn luôn là #000000.
4. Chuẩn bị dữ liệu
Có ba dữ liệu mình sẽ cần chuẩn bị đó là :
Ảnh nền (ảnh background): Tùy thuộc vào từng bài toán mình sẽ chuẩn bị những ảnh nền thích hợp nhé. Ví dụ bài toán của bạn là các văn bản thì phông các bạn cũng là ảnh trắng thôi.
Font tiếng Việt:Mình đã chuẩn bị sẵn font chữ tiếng Việt ở trong repo nếu các bạn sử dụng repo của mình để bên trên. Còn nếu không, cách dễ nhất là các bạn có thể tải các font tiếng Việt của google bằng cách click ở đây nhé. Tuy nhiên bạn nên kiểm tra kỹ lại từng font vì có mấy font thỉnh thoảng lúc tạo dữ liệu bị mất dấu tiếng Việt. Các bạn cẩn thận nhé 
Dữ liệu text:là một file .txt chứa các câu văn tiếng Việt. Mỗi câu là một dòng trong file txt. Tool sẽ lấy dữ liệu trên từng dòng ghép với một font, một ảnh nền khác để tạo ra file ảnh tương ứng. Mình có cung cấp sẵn khoảng 500 sample. Các bạn có thể xem tại file test_data.txt.

5. Sinh dữ liệu
Sau bước chuẩn bị dữ liệu, bạn có thể dễ dàng sinh ảnh như ý muốn của mình chỉ với một dòng lệnh. Đơn giản đúng không nào 
python3 run.py -c 500 -w 1 -f 32 -b 3 \
--blur 0 \
--input_file data/test_data.txt \
--output_dir $(pwd)/out/ \
--font_dir fonts/vi/ \
--image_dir images/ \
--thread_count 4 \
--character_spacing 1 \
Kết quả bạn sẽ thu về một số file ảnh và file labels.txt chứa nhãn chứa trong thư mục bạn đã chỉ định như sau:
![]()
![]()
![]()
![]()
Vậy là mình cùng nhau hoàn thành hết 5 bước để tạo ra dữ liệu cho bài tóan OCR rồi. Quá là đơn giản đúng không nào ? Các bạn có thể dễ dàng tạo ra hàng trăm hàng ngàn ảnh để tiến hàng việc huấn luyện phục vụ cho mục đích học tập cũng như làm sản phẩm OCR. Bài viết đến đây là hết rồi, cảm ơn các bạn đã theo dõi bài viết của mình. Và hơi PR một chút, Nếu các bạn thấy hay, thì đừng ngần ngại hãy upvote để mình có thể thêm động lực ra những bài tiếp theo nhé
All rights reserved
