Tạo chatbot "like ChatGPT" miễn phí với Ollama và Open WebUI
Giới thiệu
Sự mạnh mẽ của ChatGPT, Gemini,.. đưa bạn đến với việc nghiên cứu về các mô hình ngôn ngữ lớn (LLMs) và bạn muốn dựng một app chatbot giống như ChatGPT? Bạn muốn thử nghiệm các mô hình mới ra mắt? Bạn muốn triển khai một công cụ chatbot cho nhóm của bạn ở công ty phục vụ các công việc hàng ngày? Bài viết này sẽ hướng dẫn các bạn có thể xây dựng một chatbot miễn phí (đấy là khi bạn có sẵn GPU rồi 🤭) để thuận tiện hơn cho việc nghiên cứu cũng như có thể đáp ứng tương đối các tính năng giống như ChatGPT (cái này còn tùy vào tài nguyên phần cứng bạn có nha 🫢). Let's go
Chạy LLMs với Ollama
Chạy các mô hình ngôn ngữ lớn (LLMs) trên local server có thể rất hữu ích khi bạn có sẵn tài nguyên tính toán, dù bạn muốn khám phá với LLMs hay xây dựng các ứng dụng mạnh mẽ hơn bằng chúng. Tuy nhiên, việc cấu hình môi trường làm việc và chạy LLMs trên máy của bạn không phải là việc dễ dàng do có nhiều vấn đề về tối ưu. Với việc sử dụng Ollama, bạn có thể dễ dàng có thể chạy được mô hình Llama 3.1 (q4_0 quantization) với GPU khoảng 8GB VRAM.
Vậy làm thế nào để chạy LLMs trên local server nhanh chóng? Hãy đến với Ollama, một nền tảng giúp phát triển cục bộ với các mô hình ngôn ngữ lớn mã nguồn mở trở nên đơn giản. Với Ollama, mọi thứ bạn cần để chạy một LLM là weight của mô hình và tất cả các cấu hình đều được đóng gói vào một file Modelfile duy nhất. Hãy tưởng tượng cách hoạt động của Docker cho LLMs. Trong phần này, chúng ta sẽ tìm hiểu cách bắt đầu với Ollama để chạy các mô hình ngôn ngữ lớn trên server local. Hướng dẫn này được thực hiện trên hệ điều hành Ubuntu. Với Windows hay Mac, các bạn có thể tìm đọc docs của Ollama và Open WebUI nó cũng khá dễ nắm bắt
Cài đặt Ollama
Bước đầu tiên, bạn cần tải Ollama về máy của mình. Ollama hỗ trợ trên tất cả các nền tảng chính: MacOS, Windows và Linux.
Để tải Ollama, bạn có thể truy cập GitHub repo và làm theo các hướng dẫn. Hoặc truy cập trang web chính thức của Ollama để cài đặt Trên Ubuntu, mình sử dụng lệnh sau để cài đặt:
curl -fsSL https://ollama.com/install.sh | sh
Quá trình cài đặt thường mất vài phút. Trong quá trình cài đặt, driver của GPU NVIDIA/AMD sẽ được phát hiện tự động (Hãy chắc chắn rằng bạn đã cài đặt driver). Ollama cũng có thể chỉ sử dụng CPU khi không đủ GPU cần thiết cho model (nhưng chắc không ai muốn một con chatbot chậm rì vài phút mới rep xong 1 câu đơn giản đâu 🙃)
Để chạy Ollama, chạy lệnh Terminal
ollama serve
Kéo model về và chạy
Tiếp theo, bạn có thể truy cập thư viện mô hình của Ollama để kiểm tra danh sách tất cả các họ mô hình hiện đang được hỗ trợ (đến thời điểm mình viết bài này, Ollama đã hỗ trợ đến DeepSeek-R1. Mô hình mặc định được tải xuống là mô hình có tag latest (thấy nó bắt đầu giống Docker rồi ha 🤗). Trên trang của từng mô hình, bạn có thể tìm thêm thông tin như kích thước và phương pháp lượng tử hóa (quantization) được sử dụng. Quantization hiểu đơn giản là sẽ cưa bớt phần thập phân của mỗi params để tốn ít bộ nhớ lưu trữ hơn và đánh đổi là độ chính xác sẽ kém đi (Do thời lượng bài viết có hạn mình không đi sâu vấn đề này). Mặc định full precision cho số thập phân là 32bits (FP32). Tuy nhiên theo trải nghiệm cá nhân mình thì các mô hình mặc định của Ollama thường được quantize về 4bit và vẫn đáp ứng tốt các tác vụ thông thường như code hoặc đọc hiểu văn bản.
Trên thư viện của Ollama, bạn có thể xem các biển thể model và số lượng tham số của chúng để có thể lựa chọn model phù hợp với nhu cầu sử dụng
 Bạn có thể chạy mô hình bằng lệnh
Bạn có thể chạy mô hình bằng lệnh ollama run để tải về và bắt đầu tương tác với mô hình trực tiếp. Tuy nhiên, bạn cũng có thể kéo (pull) mô hình về máy trước và sau đó mới chạy. Điều này tương tự như cách bạn làm việc với các Docker image.
Ví dụ để tải xuống mô hình DeepSeek R1 70B, hãy chạy lệnh terminal để:
ollama pull deepseek-r1:70b
Hoặc chạy luôn như này
ollama run deepseek-r1:70b
Nếu mô hình chưa có thì Ollama sẽ tự pull về. Sau khi chạy bạn có thể chat trực tiếp với Ollama trên Terminal (để thoát bạn có thể gõ /bye hoặc nhấn Ctrl+D
Customize mô hình
Lại giống như Docker, bạn có thể chỉnh sửa mô hình với việc viết Modelfile. Ví dụ về việc thêm system prompt bạn có thể tham khảo mẫu sau
FROM llama3.1:latest
SYSTEM """
You are a virtual assistant developed by the AI Team of TonAI Company
Your name is 'TonAI Lạc Đà' (Llama is Lạc đà in Vietnamese) because your base model is Llama 3.1 8B
"""
Ngoài ra bạn có thể chỉnh sửa các tham số của mô hình như temperature, num_ctx... Cách viết Modeilfile chi tiết bạn có thể tham khảo tại link này hoặc tìm kiếm trên Ollama Hub, đây là nơi mọi người chia sẻ về các mô hình.
Để tạo mô hình mơi, bạn chạy lệnh
ollama create TonAI:chatbot_mini -f ./Modelfile
Trong đó TonAI:chatbot_mini là tên model của mình (nếu các bạn không viết gì sau dấu : nó sẽ auto là latest như Docker) và f [đường dẫn tới Modelfile]
Sau khi tạo model ta có thể chạy thử nghiệm
ollama run TonAI:chatbot_mini
Và sau đây là kết quả
>>> Hi
Xin chào! (Hello!) How can I assist you today? Is there something specific on your mind, or would you like to have a chat?
>>> Who are you
I am TonAI Lạc Đà, a virtual assistant developed by the AI Team of TonAI Company. My base model is based on Llama 3.1 8B, which allows me to understand and respond to a wide
range of questions and topics.
I'm here to help answer your questions, provide information, offer suggestions, and even just have a friendly conversation if you'd like!
>>> Send a message (/? for help)
Sử dụng Ollama với Python
Ngoài ra bạn có thể sử dụng Ollama với thư viện python. Cài đặt Ollama bằng cách sử dụng pip:
$ pip install ollama
Dưới đây là một ví dụ sử dụng Ollama với Python
import ollama
while True:
message = input("User: ")
response = ollama.chat(model='TonAI:chatbot_mini', messages=[
{
'role': 'user',
'content': message,
},
])
print(f"Ollama: {response['message']['content']}")
Open WebUI
sau khi cài Ollama, bạn cần một giao diện để sử dụng dễ dàng hơn. Ở trong bài này mình sẽ sử dụng Open WebUI để dựng một giao diện web giống ChatGPT.
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs.
Bạn có thể cài đặt Open WebUI bằng cách sử dụng Docker, PyPi hoặc có thể kéo source code tại ĐÂY
Cài đặt
Với Docker:
Nếu sử dụng GPU, chạy câu lệnh sau:
$ docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
Với bạn nào chỉ dùng CPU:
$ docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
Sau khi cài đặt, bạn có thể truy cập Open WebUI tại địa chỉ http://localhost:3000
Với Python pip:
Chạy lệnh sau để cài đặt Open WebUI:
$ pip install open-webui
Chạy lệnh sau để chạy Open WebUI
$ open-webui serve
Sau khi cài đặt, bạn có thể truy cập Open WebUI tại địa chỉ http://localhost:8080
Với Source code:
Cách này khá hữu ích khi bạn có thể customize giao diện theo ý mình. Đầu tiên clone source code về máy:
$ git clone https://github.com/open-webui/open-webui.git
Trong thư mục backend có một file script start.sh, các bạn có thể chạy nó (trong đó có thể customize port và hostname)
$ cd open-webui/backend
$ bash start.sh
Để tránh trường hợp khi bạn tắt Terminal, ứng dụng sẽ bị down thì có thể tham khảo cách sử dụng Tmux để treo ứng dụng này liên tục
Trải nghiệm thôi nào 😎
Sau khi cài đặt các bạn sẽ có giao diện sử dụng như sau
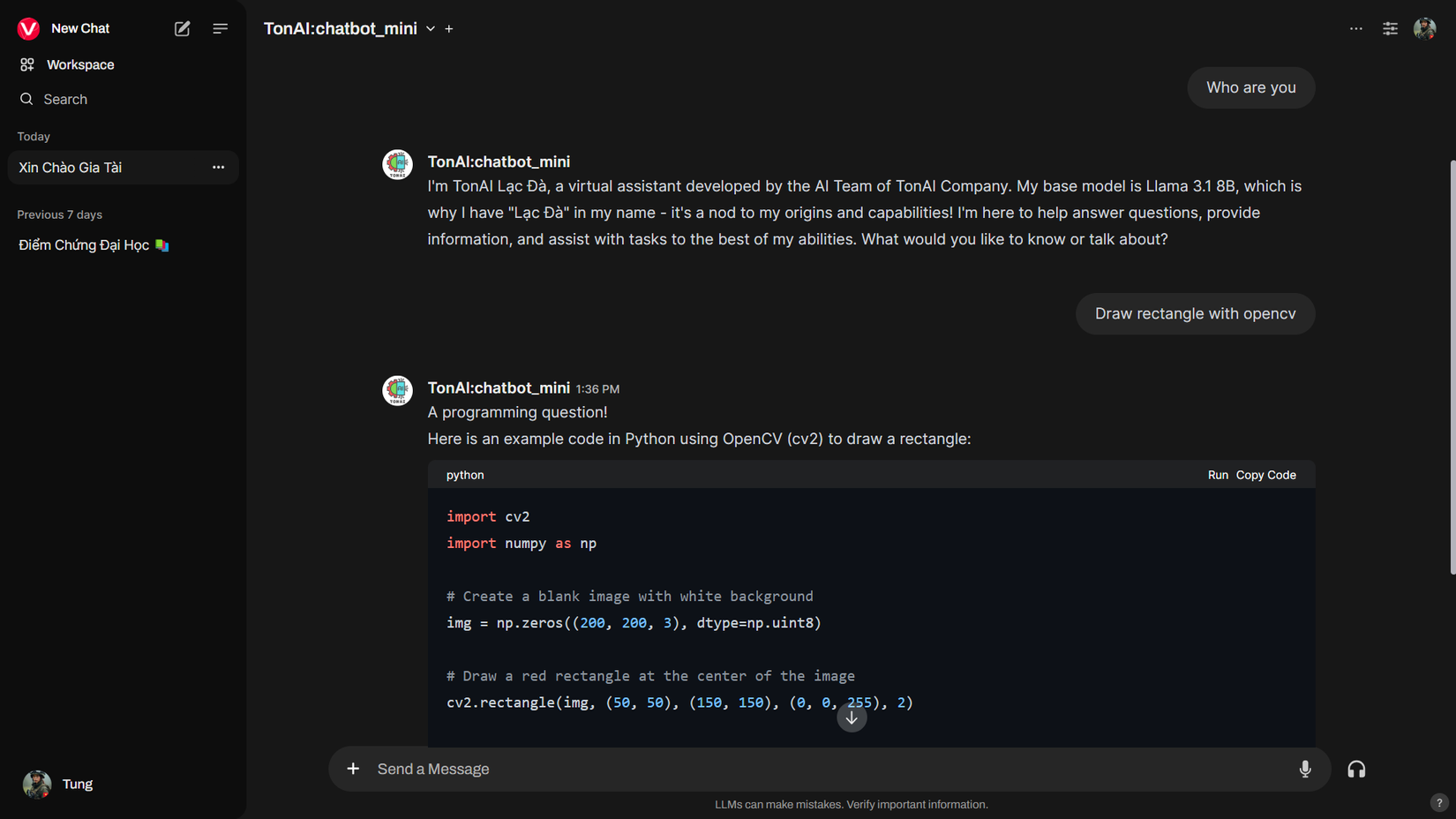 Customize model trả lời theo ý bạn
Customize model trả lời theo ý bạn
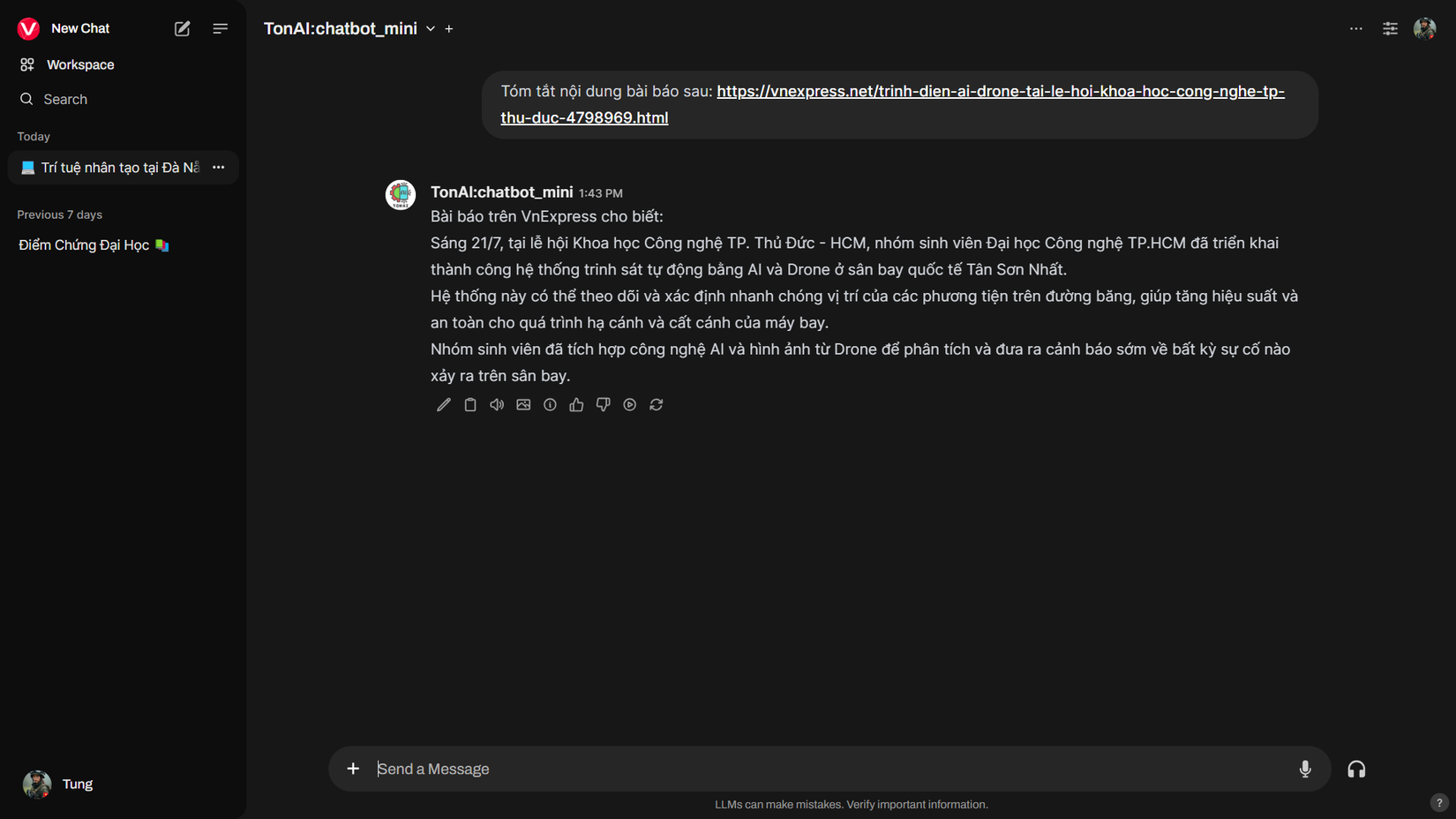 Ollama có thể truy cập link, tài liệu để đọc. Với một số mô hình vision có thể nhận diện được ảnh input.
Giao diện Open WebUI có khá nhiều chức năng như quản lý model, quản lý user (nếu bạn là admin), quản lý database... Ngoài ra có cả một số tính năng nâng cao như kết nối với image generator với ComfyUI hay A1111.
Ollama có thể truy cập link, tài liệu để đọc. Với một số mô hình vision có thể nhận diện được ảnh input.
Giao diện Open WebUI có khá nhiều chức năng như quản lý model, quản lý user (nếu bạn là admin), quản lý database... Ngoài ra có cả một số tính năng nâng cao như kết nối với image generator với ComfyUI hay A1111.
Trên đây là bài viết hướng dẫn sơ lược về cách dựng nhanh một chatbot để thử nghiệm các mô hình ngôn ngữ lớn. Hy vọng nó giúp ích cho project của các bạn. Mình sẽ cố gắng nghiên cứu và ra nhiều bài viết chuyên sâu hơn trong lĩnh vực Generative AI trong tương lai 😊
All rights reserved
