Tăng tốc database phần 12 Index với LIKE
Bài đăng này đã không được cập nhật trong 4 năm
Các bạn có thể xem đầy đủ các phần tại đây nhé
Nếu các bạn chưa đọc bài trước có thể đọc tại link Tăng tốc database phần 11 Tìm kiếm theo Khoảng, Lớn Hơn, Nhỏ Hơn, và BETWEEN
Truy vấn với Like nhiều lúc rất hiệu quả, nhiều lúc lại rất chậm. Có thể một số từ khóa được đánh index tốt, một số thì không. Nhiều lúc vị trí của wild card có thể cho kết quả rất khác nhau. VÍ dụ dùng % wild card ở giữa từ khóa
SELECT first_name, last_name, date_of_birth
FROM employees
WHERE UPPER(last_name) LIKE 'WIN%D'
Dưới đây là execution plan Oracle
---------------------------------------------------------------
|Id | Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 4 |
|*2 | INDEX RANGE SCAN | EMP_UP_NAME | 1 | 2 |
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access(UPPER("LAST_NAME") LIKE 'WIN%D')
filter(UPPER("LAST_NAME") LIKE 'WIN%D')
Mysql
+----+-----------+-------+----------+---------+------+-------------+
| id | table | type | key | key_len | rows | Extra |
+----+-----------+-------+----------+---------+------+-------------+
| 1 | employees | range | emp_name | 767 | 2 | Using where |
+----+-----------+-------+----------+---------+------+-------------+
Trong việc tìm kiếm theo LIKE, chỉ có những ký tự đứng trước wild card đầu tiên có thể được dùng trong index. còn lại sẽ không được sử dụng trong ví dụ trên việc tìm kiếm theo WIN sẽ được tìm theo index còn D thì không. Trong ví dụ trên thì phần WIN sẽ dùng trong phần access trong predicate còn phần D thì ở trong phần filter ( access là chọn điểm đầu và điểm cuối trên leaf node còn filter là việc duyệt trên leaf node). Tại sao chỉ phần trước theo được index mà phần sau lại không được? bạn có thể xem hình sau:
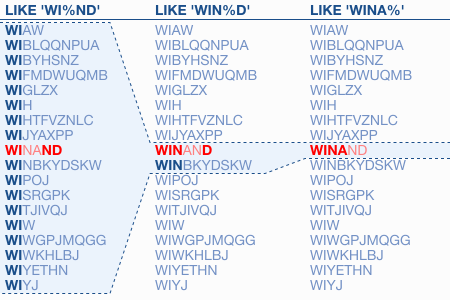
Trên hình có thể thấy bản chất của chữ cái nếu bạn tìm theo WI thì sẽ đọc theo từ điển được, còn tìm theo chữ D thì không thể tìm được, nếu cho bạn tra từ điển thì cũng có thể tìm được theo các chữ đầu chứ không tìm theo chữ giữa chữ cuối được. Nhìn trên hình trên các bạn còn thấy nếu như phần phía trước càng chứa nhiều ký tự, thì khoảng tìm kiếm càng ngắn lại. Dẫn tới hiệu năng sẽ tốt hơn. ( tìm kiếm theo WINA sẽ nhanh hơn WIN và WI). Cái đầu tiên sẽ phải đọc nhiều, cái thứ hai chỉ cần đọc thêm 1 bản ghi còn cái cuối cùng thì có thể lấy dữ liệu ra ngay lập tức.
Điều gì sẽ xảy ra nếu như bạn để dấu % ở đầu tiên. Nếu để như vậy nếu không có điều kiện nào bổ xung thì bạn sẽ phải duyệt toàn bộ bảng để trả về kết quả, vì vậy kết quả của WINA% sẽ rất khác biệt %WINA các bạn nên tránh trường hợp để wildcard ở đầu. Về lý thuyết vị trí của wild card sẽ ảnh hưởng tới hiệu năng khi tìm kiếm theo LIKE. Trong thực tế trình tối ưu còn dựa vào bind parameters để đoán xem có toán tử like ở đầu không (trường hợp này duyệt toàn bộ)
Tóm lại trong bài này các bạn nên nhớ LiKE chỉ có thể index được nếu % không đứng đầu, và càng ở sau thì càng có hiệu quả, trong trường hợp Like với % ở đầu tiên các bạn nên có các điều kiện khác để hạn chế số lượng bản ghi lại nếu không sẽ quét toàn bộ bảng. Trong trường hợp không tránh được các bạn nên sử dụng Fulltext Index.
All rights reserved
