[Tản mạn] Nếu máy nhìn người, điều nó thấy là ...
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu
Ngày nay, với sự phát triển thần kì của học máy, người ta không khỏi băn khoăn "Liệu rằng máy có thể thông minh hơn người?". Trong quá trình học hỏi về lĩnh vực này, mình nhận thấy được các sự tương đồng -về mặt chức năng, cách thức vận hành- giữa thuật toán và hành vi của con người trong quá trình đưa ra quyết định (cách thức quyết định, cách thức học hỏi để củng cố khả năng đưa ra quyết định, ...)
Ở bài viết này, mình chia sẻ góc nhìn của mình về cách con người đưa ra quyết định theo góc nhìn mô tả thuật toán học máy. Mình không cố đơn giản hóa tâm trí con người, cũng không thần kì hóa sức mạnh của AI, mình đưa ra một cách nhìn, với mình nó khá thú vị, khi mô tả giữa máy tính và con người.
Bài viết được trình bày như sau:
- Đầu tiên mình sẽ mô tả ở mức trừu tượng về thuật toán máy học, mức trừu tượng này sẽ không đi quá so với mô tả toán học của nó, đồng thời, vừa đủ để mình có thể liên hệ với sự so sánh với hành vi con người.
- Tiếp đến, mình chia sẻ góc nhìn của bản thân thông qua việc nêu ra những so sánh.
- Sau cùng, mình muốn kết thúc bằng việc tổng kết các ý đã đề cập.
Mô tả thuật toán học máy
Mình bắt đầu bằng việc lấy ví dụ về thuật toán Linear Regression. Ở thuật toán này, việc dự đoán sẽ được tuân theo công thức sau đây:
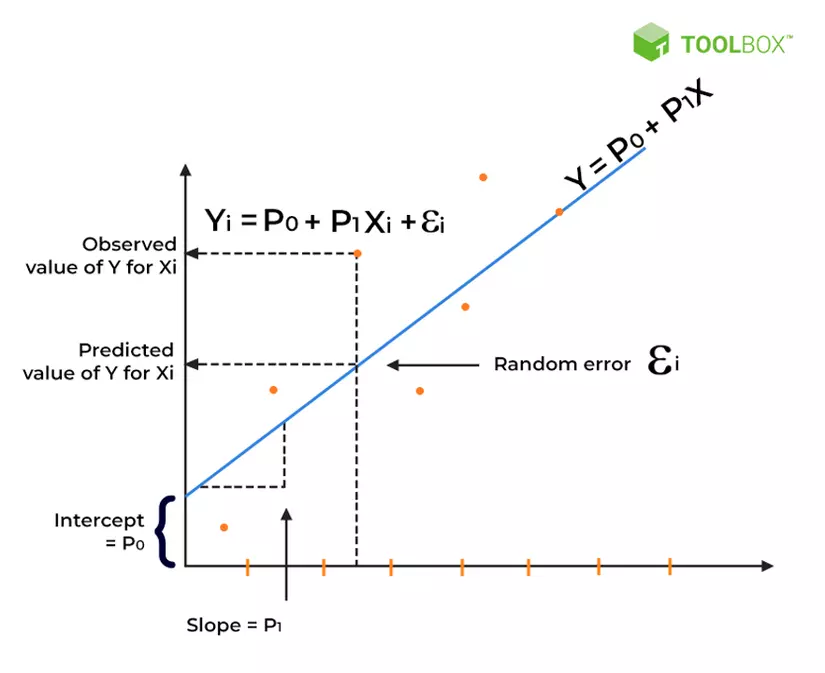
Trong quá trình học, bộ trọng số (theo hình sẽ là cặp P_0, P_1) sẽ được cập nhật sao cho những dự đoán của thuật toán sẽ gần nhất với dữ liệu thực. (Để cập nhật bộ trọng số này, sẽ có các hàm tối ưu hỗ trợ điều đó, mình sẽ bàn về nó chi tiết ở bài viết khác). Khi này, thuật toán sẽ gồm những thứ sau đây: Bộ dữ liệu, Hàm giả thuyết (dùng để đưa ra dự đoán) và bộ trọng số (các đặc điểm riêng của mô hình, được điều chỉnh thông qua huần luyện để cải thiện độ chính xác). Tính hiệu quả của thuật toán được đánh giá dựa trên dự thích nghi của nó với bộ dữ liệu (điều này có thể gợi ý rằng, với càng nhiều dữ liệu, độ phổ quát mà máy hiểu được sẽ càng lớn). Hầu hết, các thuật toán đều được giải quyết với luồng như sau:
- Đưa ra dự đoán.
- So sánh dự đoán với thực tế, đưa ra đánh giá.
- Dựa trên đánh giá, thay đổi trọng số.
- Lặp lại đến khi thuật toán đạt được độ chính xác vừa ý.
Đưa ra sự so sánh Theo cách hiểu biết của mình, với mọi thuật toán, dù ở cách học nào, luôn tồn tại những thứ sau đây, trọng số, bộ dữ liệu và các thức học. Tùy vào cách thức học mà đề tài hướng đến, bộ dữ liệu và cách thức học luôn được cài đặt sao cho, sau quá trình học, thuật toán luôn có 1 cách để tham chiếu sự thay đổi của mình dựa trên bộ dữ liệu ấy, ví dụ:
- Ở cách học giám sát, sự tham chiếu mà mình đề cập nằm ở việc so sánh giữa kết quả do máy học được và giá trị thực.
- Ở cách học không giám sát, sự tham chiếu là tính tương đồng hoặc độ xa lạ giữa các điểm dữ liệu với nhau.
Khi này, chính sự quy chiếu trong cách thức triển khai mô hình mang đến sự tương đồng giữa người và máy. Đôi khi, mình nghĩ rằng, vì con người cố gắng tạo ra cỗ máy giống người, nên họ đã mang những gì của mình vào trong thiết kế của họ. Dẫn đến 1 điều rằng, các thuật toán học máy có dáng vấp về sự mô phỏng lại của hình con người.Với sự phát triển của khoa học hiện đại, đến một ngày nào đó trong tương, thuật toán sẽ mô phỏng lại được cách ta vận hành ở mức độ chi tiết nhất.
 Một ví dụ điển hình là về các ta lựa chọn. Hãy nghĩ đến một điều sau đây, nếu mình hỏi bạn rằng "Chỉ cho mình một lối đi đến cửa nhà của bạn". Mình nghĩ rằng, bạn sẽ chỉ mình một con đường đơn giản đến mức mà bạn có thể tự hỏi bản thân rằng "Thằng này bị gì mà không mò ra được cửa ra vào vậy, nó ở ngay dưới nhà kia mà". Nếu ngẫm kĩ hơn 1 tí, mình không đề cập đến cụm "ngắn nhất" hay là "ít tốn thời gian nhất", tức là, bạn có thể chỉ mình với một lộ trình tựa như: trèo ra khỏi cửa sổ, đi qua nhà hàng xóm rồi đi ngược lại vào cửa sổ rồi xuống cầu thang là tới, đấy có thể là 1 điều vô lý, nhưng nó vẫn có thể là 1 câu trả lời khả dĩ. Mình nghĩ, vì lẽ rằng, trong mọi hành động ta làm, hành động đó sẽ có 1 hệ tham chiếu -trong trường hợp vừa nêu có thể là thời gian hoặc là quãng đường-, ta được "huấn luyện" sao cho bản thân có thể đạt được kết quả tốt nhất so với hệ quy chiếu đó - "đường đi ngắn nhất" hoặc "ít tốn thời gian nhất" -, đồng thời, để điều đó xảy ra, ta cần "một gì đó" để "cập nhật" bản thân mình. Nếu mô tả bài toán, mình sẽ mô tả như sau "lựa chọn hành động sao cho ít tốn thời gian nhất", khi này, tập hành động của ta có thể được tự tìm tòi, hoặc quan sát các hành động bên ngoài với cùng mục đích, sau đấy đo lường thời gian của các hoạt động rồi lựa ra các hành động tối ưu nhất (bên ngoài việc quy chiếu tới thời gian, ta có thể xét thêm các yếu tố khác như giảm năng lượng cơ thể nhiều nhất có thể).
Một ví dụ điển hình là về các ta lựa chọn. Hãy nghĩ đến một điều sau đây, nếu mình hỏi bạn rằng "Chỉ cho mình một lối đi đến cửa nhà của bạn". Mình nghĩ rằng, bạn sẽ chỉ mình một con đường đơn giản đến mức mà bạn có thể tự hỏi bản thân rằng "Thằng này bị gì mà không mò ra được cửa ra vào vậy, nó ở ngay dưới nhà kia mà". Nếu ngẫm kĩ hơn 1 tí, mình không đề cập đến cụm "ngắn nhất" hay là "ít tốn thời gian nhất", tức là, bạn có thể chỉ mình với một lộ trình tựa như: trèo ra khỏi cửa sổ, đi qua nhà hàng xóm rồi đi ngược lại vào cửa sổ rồi xuống cầu thang là tới, đấy có thể là 1 điều vô lý, nhưng nó vẫn có thể là 1 câu trả lời khả dĩ. Mình nghĩ, vì lẽ rằng, trong mọi hành động ta làm, hành động đó sẽ có 1 hệ tham chiếu -trong trường hợp vừa nêu có thể là thời gian hoặc là quãng đường-, ta được "huấn luyện" sao cho bản thân có thể đạt được kết quả tốt nhất so với hệ quy chiếu đó - "đường đi ngắn nhất" hoặc "ít tốn thời gian nhất" -, đồng thời, để điều đó xảy ra, ta cần "một gì đó" để "cập nhật" bản thân mình. Nếu mô tả bài toán, mình sẽ mô tả như sau "lựa chọn hành động sao cho ít tốn thời gian nhất", khi này, tập hành động của ta có thể được tự tìm tòi, hoặc quan sát các hành động bên ngoài với cùng mục đích, sau đấy đo lường thời gian của các hoạt động rồi lựa ra các hành động tối ưu nhất (bên ngoài việc quy chiếu tới thời gian, ta có thể xét thêm các yếu tố khác như giảm năng lượng cơ thể nhiều nhất có thể).
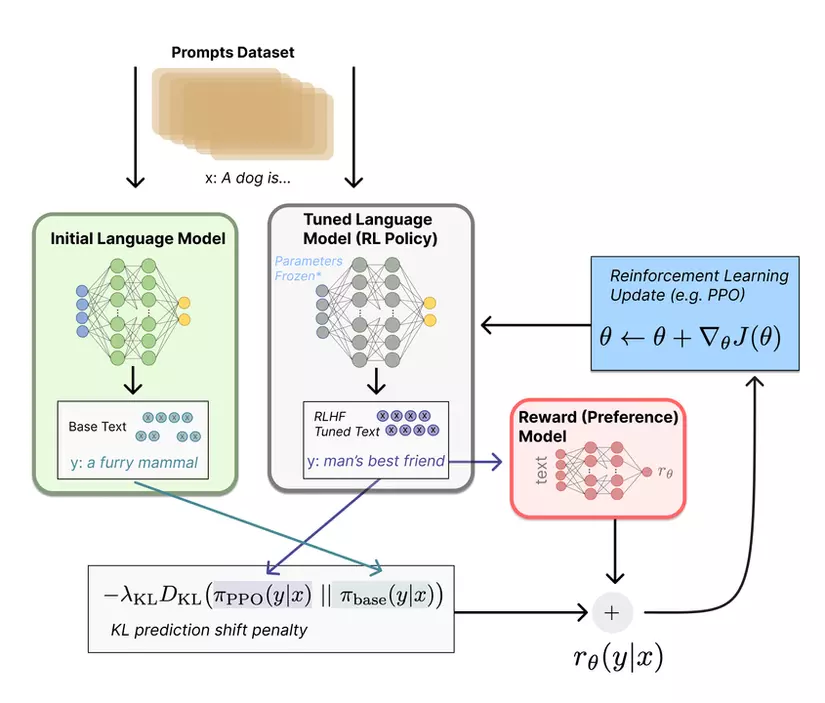
Ngoài ra, nếu xét đến cách học củng cố, cụ thể hơn, framework của RLHF (Reinforcement Learning from Human Feedback) được công bố gần đây. Mình có thể nói rằng, máy được thay đổi một cách liên tục dựa vào các phản hồi của con người, giống như việc ta thay đổi theo lời của ba mẹ hoặc thầy cô trong trường. Nếu framework này có thể phát triển đến mức độ rằng nó có thể tạo ra một local agent (vừa có khả năng học hỏi từ môi trường, đồng thời, ứng biến để đưa ra phản hồi theo người sử dụng), mình nói rằng nó khá giống ta trong việc: ta vừa học hỏi từ môi trường bên ngoài, nhưng ta cũng vừa điều chỉnh ta sao cho những điều ấy phù hợp với chính ta, trong bối cảnh vừa nêu, một local agent có thể tương đương với người sử dụng (trên tác vụ nào đó).
Kết luận
Máy và người, mặc dù sự khác biệt là rõ rằng và nếu quan sát kĩ lưỡng thì độ toàn diện của con người vượt xa máy, mình không thể phủ nhận rằng độ chính xác hay khối lượng thông tin mà nó giải quyết được vượt trội hơn con người gấp nhiều lần. Với công nghệ hiện nay, không khỏi để ngạc nhiên rằng sự yếu thế ấy có thể được khắc phục. Có thể nói rằng, các thuật toán học máy, phần lớn trong số ấy nếu không muốn nói là tất cả, mang dáng vấp của con người trong việc tiếp thu, ghi nhận và cải thiện.
All rights reserved
