Tại sao tôi khuyên bạn nên ngừng sử dụng Docker để phát triển AI cục bộ trên Mac
Docker rất tuyệt vời. Nó có tính thực tiễn cao, là một kiệt tác của công nghệ phần mềm hiện đại, và hoàn toàn thống trị các môi trường sản xuất (production) cũng như các luồng CI/CD. Tuy nhiên, nếu hiện tại bạn đang sử dụng MacBook để xây dựng các ứng dụng AI cục bộ và hệ thống RAG, và vẫn đang dùng Docker Desktop để triển khai, bạn sẽ sớm nhận ra rằng nó chính là "kẻ hủy diệt" năng suất.

Khi phát triển AI cục bộ, ngay khoảnh khắc bạn gõ docker-compose up trong terminal, quạt tản nhiệt của MacBook bắt đầu quay cuồng, áp lực bộ nhớ trong Activity Monitor (Giám sát hoạt động) lập tức chuyển sang màu đỏ, và ngay sau đó bạn sẽ gặp phải tình trạng giật lag (micro-stutters) khi viết code trong VS Code.
Phát triển AI cục bộ, đặc biệt là khi chạy các Mô hình Ngôn ngữ Lớn (LLM) và cơ sở dữ liệu vector, đòi hỏi phải vắt kiệt từng giọt sức mạnh tính toán từ phần cứng của bạn. Kiến trúc dựa trên máy ảo của Docker trên macOS đang âm thầm vắt kiệt hiệu năng quý giá nhất của thiết bị.
Những cạm bẫy về hiệu suất của Docker trên macOS
Để hiểu nguyên nhân đằng sau sự sụt giảm hiệu suất này, chúng ta phải nhìn sâu vào kiến trúc cốt lõi. Những nút thắt kỹ thuật dưới đây là sự thật khách quan không thể tránh khỏi.
Trò chơi có tổng bằng 0 của việc cấp phát bộ nhớ (Memory Allocation)
Lợi thế công nghệ của Apple Silicon (chip dòng M) nằm ở kiến trúc "Bộ nhớ thống nhất" (Unified Memory). CPU và GPU chia sẻ chung một bộ nhớ băng thông cao, và việc chạy các mô hình như Llama 3 hoặc Mistral ở local phụ thuộc rất nhiều vào cơ chế này để đạt được tốc độ suy luận nhanh.

Docker không chạy trực tiếp (natively) trên macOS; thay vào đó, nó dựa vào một Máy ảo (VM) Linux ẩn. Hệ thống phải cấp phát trước một giới hạn bộ nhớ cố định cho VM này (ví dụ: cấp phát 16GB). Sự cách ly cứng nhắc này phá vỡ sự cân bằng động của Bộ nhớ thống nhất. Một LLM chạy trên máy chủ (host) không thể chạm vào phần bộ nhớ đã cấp phát cho Docker; ngược lại, nếu bạn thu hẹp hạn mức bộ nhớ của Docker để nhường chỗ cho LLM, các dịch vụ backend như PostgreSQL hoặc Python bên trong container sẽ thường xuyên gặp sự cố OOM (Out of Memory - Hết bộ nhớ).
Chi phí ảo hóa (Overhead) trong các lệnh gọi GPU
Để tăng tốc độ suy luận AI trên Mac, bạn phải thông qua framework Metal của Apple.
Mặc dù Docker Desktop đã có nhiều nỗ lực trong việc chuyển tiếp GPU (GPU passthrough) những năm gần đây, việc buộc một tiến trình chạy bên trong container Linux gọi API Metal của máy chủ một cách mượt mà chắc chắn sẽ tạo ra chi phí hiệu suất do quá trình dịch lệnh và lớp ảo hóa. Các thử nghiệm thực tế cho thấy các engine suy luận chạy trực tiếp (natively) trên macOS tạo ra token nhanh hơn nhiều so với các dịch vụ tương tự được đóng gói bên trong Docker container.
Nút thắt I/O trong việc đồng bộ hóa tệp
Việc phát triển ứng dụng RAG liên quan đến khối lượng xử lý tệp khổng lồ. Các lập trình viên thường xuyên phải đọc các bộ sưu tập PDF cục bộ, thư viện tài liệu Markdown hoặc kho lưu trữ code, chia nhỏ chúng và chuyển đổi chúng thành các vector (Embeddings).
Việc gắn (mounting) hệ thống tệp macOS vào một Docker container—ngay cả khi đã bật các tính năng tăng tốc thử nghiệm như VirtioFS—vẫn dẫn đến sự sụt giảm nghiêm trọng về băng thông I/O khi xử lý việc đọc đồng thời hàng chục ngàn tệp nhỏ. Một tập lệnh tải tài liệu chỉ mất vài trăm mili-giây để hoàn thành trong môi trường Python gốc cục bộ thường bị kẹt trong vài giây bên trong container.
Mạng lưới và Ánh xạ cổng (Port Mapping) cồng kềnh
Khi xây dựng một hệ thống AI Agent hoàn chỉnh, kiến trúc microservices là tiêu chuẩn. Lập trình viên thường phải duy trì một cơ sở dữ liệu vector chạy trên cổng 5432, một framework frontend trên cổng 3000, một API backend lắng nghe trên cổng 8000, đồng thời giao tiếp với giao diện LLM cục bộ trên cổng 11434.

Việc liên tục cấu hình ánh xạ cổng giữa mạng cầu nối (bridged network) của Docker và localhost của máy chủ, xử lý việc chặn Chia sẻ tài nguyên đa nguồn gốc (CORS), và cấp chứng chỉ SSL cho việc gỡ lỗi HTTPS cục bộ là những tác vụ vận hành tẻ nhạt, làm gián đoạn nghiêm trọng tiến độ phát triển logic nghiệp vụ.
Sự thay đổi mô hình: Trở lại với Kiến trúc gốc (Native) thuần túy
Cách duy nhất để vượt qua những nút thắt này là thay đổi kiến trúc cơ sở hạ tầng. Thay vì liên tục tìm kiếm các bản vá tối ưu hóa bên trong một hộp cát (sandbox) Linux cồng kềnh, tốt hơn là nên quay lại trực tiếp với phần cứng vật lý của macOS.
Các thành phần cốt lõi của các stack phát triển hiện đại—bao gồm Python, Node.js, PostgreSQL và các thư viện suy luận AI khác nhau—đều cung cấp các tệp nhị phân macOS gốc được tối ưu hóa cho kiến trúc ARM64. Loại bỏ lớp ảo hóa và để code chạy trực tiếp trên máy vật lý đã trở thành sự đồng thuận mới cho việc phát triển AI cục bộ.
Tái cấu trúc Môi trường Phát triển Gốc
Để loại bỏ hoàn toàn "thuế hiệu suất" do ảo hóa mang lại, môi trường phát triển cục bộ cần được tái cấu trúc toàn diện. ServBay là một cơ sở hạ tầng phát triển gốc trên macOS nổi bật lên để đáp ứng chính xác nhu cầu này. Nó từ bỏ phương pháp container hóa và trực tiếp cung cấp hiệu suất gốc ở cấp độ máy vật lý.
Hiệu suất Gốc 100% của Máy Vật lý
Không có máy ảo Linux nào bên trong ServBay. Nó sử dụng một môi trường nền tảng được biên dịch gốc hoàn toàn, nơi các tiến trình dịch vụ được lập lịch trực tiếp bởi nhân macOS và tương tác trực tiếp với Apple Silicon. Bằng cách loại bỏ cơ chế dự trữ tài nguyên, Bộ nhớ thống nhất của hệ thống có thể được LLM và các dịch vụ backend cấp phát động theo nhu cầu, giải quyết triệt để các vấn đề quạt kêu to và hệ thống bị lag.
Triển khai Cơ sở Hạ tầng AI chỉ với Một Cú Nhấp Chuột (Kèm Hướng dẫn Cài đặt)
Thoát khỏi các tệp docker-compose.yml dài và phức tạp. Phát triển RAG phụ thuộc rất nhiều vào các cơ sở dữ liệu hỗ trợ truy xuất vector, và ServBay cung cấp một môi trường gốc sẵn sàng sử dụng (out-of-the-box) cho việc này.
Các bước Cài đặt và Cấu hình:
- Truy cập trang web chính thức của ServBay để tải xuống gói cài đặt macOS mới nhất (tệp .dmg), và kéo ứng dụng vào thư mục Applications (Ứng dụng) để hoàn tất cài đặt cơ bản.

- Mở bảng điều khiển ServBay, điều hướng đến tab "Packages" (Gói), và tìm PostgreSQL. Hệ thống cung cấp nhiều phiên bản chính từ 11 đến 16. Nhấp vào nút màu xanh lá cây để cài đặt, và nó sẽ tự động tải xuống và cấu hình một cơ sở dữ liệu được biên dịch gốc cho ARM64.
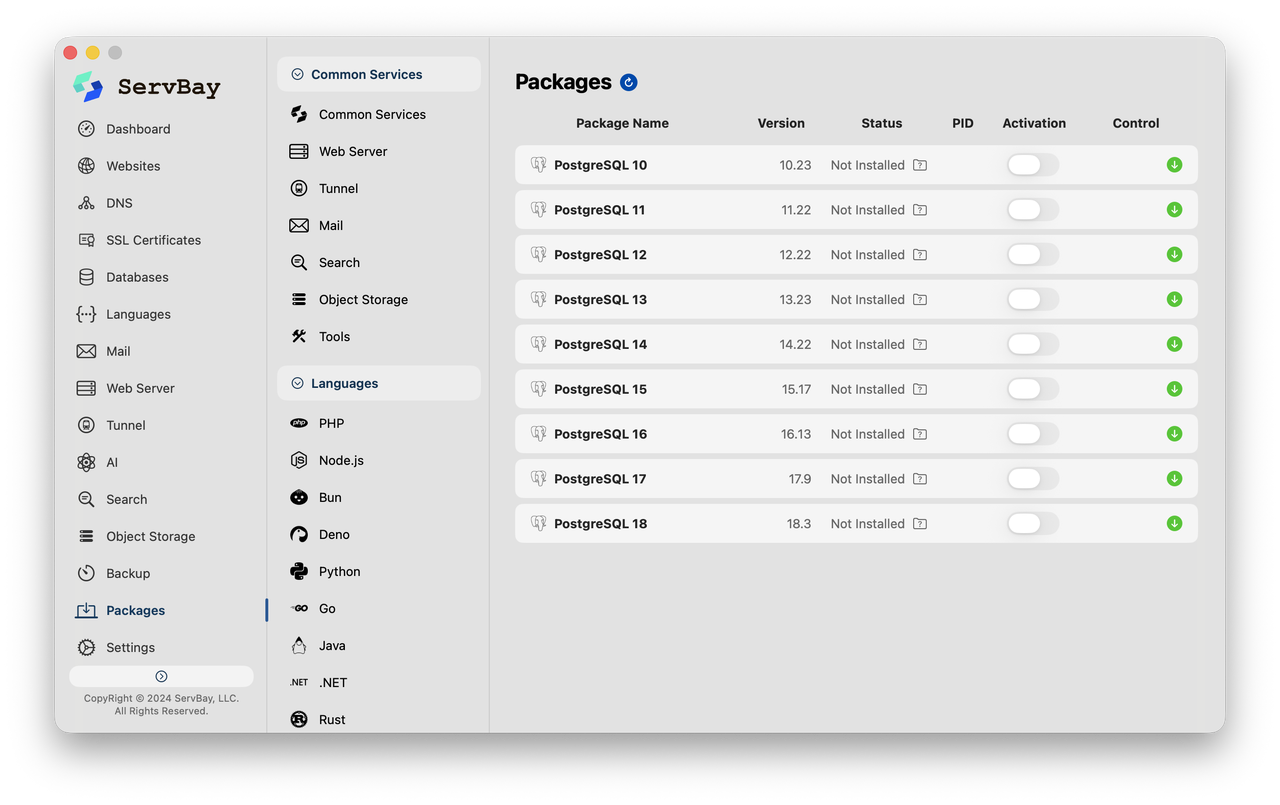
-
Bật plugin pgvector. ServBay đã tích hợp sẵn gói mở rộng pgvector được biên dịch trước. Sau khi kết nối với cơ sở dữ liệu cục bộ bằng một SQL client, lập trình viên chỉ cần thực thi
CREATE EXTENSION vector;để bật khả năng truy xuất vector, loại bỏ các bước xử lý phụ thuộc biên dịch ngôn ngữ C tẻ nhạt. -
ServBay cung cấp hỗ trợ nền tảng cho các môi trường đa ngôn ngữ như Node.js và Python, tự động xử lý ánh xạ đường dẫn toàn cục để tránh xung đột phiên bản với các môi trường đi kèm với hệ thống macOS.
Mạng lưới tối giản và Gỡ lỗi SSL
Khi phát triển với kiến trúc tách biệt frontend và backend và gỡ lỗi các AI API, môi trường HTTPS là điều không thể thiếu. ServBay có sẵn tính năng định tuyến DNS cục bộ và cơ chế chứng chỉ SSL tự động tin cậy. Lập trình viên có thể truy cập trực tiếp vào ứng dụng của họ bằng các tên miền cục bộ tùy chỉnh (ví dụ: my-ai-app.test), tạm biệt hoàn toàn các cảnh báo chứng chỉ của trình duyệt và lỗi CORS cục bộ.
Tích hợp Liền mạch với Môi trường LLM Cục bộ
Lợi thế lớn nhất của một môi trường gốc nằm ở giao tiếp độ trễ thấp giữa các tiến trình. Khi kết hợp với các công cụ chạy LLM cục bộ, toàn bộ quy trình sẽ trở nên cực kỳ mượt mà.
Ví dụ Cài đặt và Tích hợp Gốc Ollama:
ServBay đã tích hợp sâu Ollama vào phần mềm của mình. Lập trình viên không cần chuyển sang terminal để thực thi các dòng lệnh. Chỉ cần tìm Ollama trong phần "Packages" (Gói) của ServBay và nhấp vào cài đặt ollama bằng một cú nhấp chuột; hệ thống sẽ tự động cấu hình và khởi chạy tiến trình gốc.
Khi dịch vụ đã sẵn sàng, nó mặc định lắng nghe trên cổng cục bộ 11434. Tại thời điểm này, các network request được khởi tạo trực tiếp từ code Python backend do ServBay lưu trữ không cần phải xuyên qua bất kỳ lớp mạng ảo hóa nào, giảm độ trễ xuống mức tối thiểu tuyệt đối.
import requests
response = requests.post('http://127.0.0.1:11434/api/generate', json={
"model": "llama3",
"prompt": "Phân tích tóm tắt của tài liệu này",
"stream": False
})
print(response.json()['response'])
Đo lường Hiệu suất (Benchmarks): So sánh Dữ liệu
Đo lường khách quan là cách trực tiếp nhất để phản ánh khoảng cách hiệu suất do sự khác biệt về kiến trúc tạo ra. Dưới đây là hiệu suất của một môi trường phát triển RAG tiêu chuẩn (PostgreSQL + Python Backend + Node Frontend) dưới cả hai kiến trúc.
So sánh việc Sử dụng Bộ nhớ
| Kiến trúc Môi trường | Bộ nhớ thường trú khi rảnh | Chiến lược Cấp phát Bộ nhớ Đỉnh |
|---|---|---|
| Docker Desktop | 3.5 GB - 4.2 GB | Cấp phát cứng nhắc, dễ dẫn đến Swap hệ thống |
| ServBay (Gốc) | < 150 MB | Gọi động, theo nhu cầu từ Bộ nhớ thống nhất |
Thời gian Khởi động & Sẵn sàng
| Kiến trúc Môi trường | Thời gian Khởi động Nguội | Thời gian Tác vụ Tốn I/O (Tải 1000 file PDF) |
|---|---|---|
| Docker Compose | 12 - 18 giây (Cần khởi động VM và các container) | 14.5 giây (Bị giới hạn bởi hệ thống tệp ảo) |
| ServBay (Gốc) | < 2 giây (Khởi chạy tiến trình cấp hệ thống) | 3.2 giây (Đọc tốc độ cao APFS gốc) |
Hãy để Điện toán Đám mây ở trên Đám mây, và Cục bộ ở lại Cục bộ
Việc lựa chọn stack công nghệ nên phục vụ cho các kịch bản cụ thể. Docker vẫn là tiêu chuẩn tuyệt đối để xây dựng các ứng dụng cloud-native tiêu chuẩn, thực thi các luồng CI/CD và triển khai máy chủ. Tuy nhiên, trong giai đoạn viết code và gỡ lỗi cục bộ—đặc biệt là trong kỷ nguyên AI khi mà từng giọt sức mạnh tính toán cần được vắt kiệt cho việc suy luận LLM—việc bám víu vào mô hình phát triển cục bộ dựa trên máy ảo không còn phù hợp nữa.
Một môi trường gốc nhẹ, cực nhanh và không suy hao là con đường bắt buộc để nâng cao trải nghiệm của lập trình viên. Đừng để sức mạnh tính toán đắt đỏ của chip dòng M bị lãng phí chỉ để duy trì hoạt động của một máy ảo. Hãy đón nhận các công cụ phát triển gốc như ServBay, tái cấu trúc lại luồng công việc phát triển AI cục bộ của bạn và giải phóng toàn bộ hiệu năng thực sự của phần cứng.
All rights reserved
