Sự kết hợp hoàn hảo của Scrapy và Splash (Phần 2)
Bài đăng này đã không được cập nhật trong 5 năm

Lời nói đầu
Xin chào mọi người, nhìn vào tiêu đề thì các bạn cũng đã biết được ở bài viết này mình sẽ quay trở lại với series Crawl data đến tẩu hỏa nhập ma của mình  . Nếu các bạn chưa đọc qua series này thì hãy dành chút thời gian xem qua để hiểu hơn về cách mình trích xuất dữ liệu từ các trang web cũng như về Scrapy framework và thư viện Scrapy-splash nhé!
. Nếu các bạn chưa đọc qua series này thì hãy dành chút thời gian xem qua để hiểu hơn về cách mình trích xuất dữ liệu từ các trang web cũng như về Scrapy framework và thư viện Scrapy-splash nhé!
Bài toán đặt ra
Cụ thể là ở bài viết trước thì mình đã trích xuất một trang sản phẩm duy nhất của một cửa hàng Shopee. Vậy trong trường hợp một cửa hàng có hàng nghìn, hàng triệu sản phẩm được phân trang thành rất nhiều trang khác nhau thì chẳng nhẽ mình phải nhét URL của từng trang sản phẩm đó vào start_urls để con bot crawler tới từng trang đó mới crawl được dữ liệu về hay sao. Chắc là được vì ban đầu bạn nghĩ Shopee đã cho chúng ta biết một số thông tin như:
- Tổng số sản phẩm của một cửa hàng ở phần giới thiệu, vậy thì chỉ việc lấy tổng sản phẩm chia cho số sản phẩm trên 1 trang là ra số trang rồi làm một vòng
forlà easy. Nhưng ấu nầu, thực ra đó chỉ là những số liệu ảo mà thôi (không tin bạn cứ thử search vài shop mà xem, show là tổng có vài trăm sản phẩm nhưng thực ra có mỗi mấy chục :v). Chỉ còn cách bạn phải click lần lượt xem trang sản phẩm cuối cùng thực tế là trang bao nhiêu. - Shopee có một cái mini page controller dùng để next page và previous page, tại đây cũng show số trang hiện tại trên tổng số phân trang sản phẩm của shop đó, nhưng chỉ show max là 100 page, shop nào nhiều hơn 100 page thì lại bị miss. Khi mà bạn crawl hàng loạt các shop thì bạn lại phải thay đổi tương ứng với total page của shop đó. Crawl shop nào cũng phải làm như thế á, nghe thôi đã thấy mệt rồi

Vậy làm thế nào để giải quyết được vấn đề này??? Với scrapy-splash thì lại là quá dễ, việc click sang trang sản phẩm tiếp theo được thực hiện tự động hoàn toàn. Mỗi khi crawl xong một trang sản phẩm, con bot sẽ tự động click nhảy sang trang tiếp theo để crawl trang đó và lặp đi lặp lại cho tới khi không còn trang nào để next nữa thì thôi. Tức là ta đã crawl được toàn bộ sản phẩm của cửa hàng đó rồi =))
Lý thuyết thì là như vậy, giờ thì cùng mình thực hành nhé
Giải quyết bài toán
1. Chuẩn bị
Đương nhiên là đầu tiên các bạn phải tạo 1 project Scrapy và cài đặt scrapy-plash cho project đó. Những bước này mình đã trình bày rất chi tiết ở 2 bài viết trước trong series rồi nên mình sẽ không trình bày lại ở đây nữa nhé.
Hãy tạo một spider bằng câu lệnh sau:
scrapy genspider shopee_crawl https://shopee.vn
2. Xác định dữ liệu mục tiêu muốn crawl
Tiếp theo là hãy chọn mục tiêu mà bạn muốn crawl, mục tiêu này sẽ bao gồm cả cửa hàng mà bạn muốn crawl sản phẩm, và những thông tin của sản phẩm đó mà bạn muốn lấy. Sau một hồi săn sale Shopee, à nhầm =)), sau một hồi săn lùng trên Shopee và lựa chọn xem shop nào nhiều sản phẩm để thực hành thì mình đã tìm được shop VINCERO:

Các bạn có thể thấy thực ra Shopee chỉ show là 1k sản phẩm mà không hề biết 1k là bao nhiêu từ 1000 tới 1999. Bạn scroll trang web xuống dưới 1 chút sẽ thấy mini page controller như này:

Mỗi trang có 30 sản phẩm mà tổng chỉ có 20 trang tức là shop này cùng lắm cũng chỉ có khoảng dưới 600 sản phẩm. Thế mà giới thiệu tận 1k sản phẩm... Lừa thế :v. Lúc này mới thấy bài toán đặt ra đúng rồi đấy =))
Oke, sau khi đã tìm được shop mục tiêu thì mình sẽ xác định những thông tin sản phẩm mà mình muốn lấy. Tại trang này thì mình cũng chỉ lấy được vài thông tin cơ bản như tên sản phẩm, giá khuyến mãi, giá gốc, số sản phẩm đã bán được. Giờ thì hãy tạo 1 class ProductItem ở trong file items.py để define những dữ liệu mà mình muốn lấy về như sau:
class ProductItem(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
price_sale = scrapy.Field()
sold = scrapy.Field()
3. Bắt tay vào code
Bạn đã xác định cần lấy những dữ liệu gì về rồi đúng không, okay, hãy bật inspect và tiến hành phân tích cấu trúc trang web để có thể select những element tương ứng trên DOM thật chính xác nhé.
Quay trở lại với spider mà chúng ta đã tạo lúc nãy, có một vài điểm khác biệt so với con bot spider mà mình đã tạo ở bài viết trước. Con bot lần này sẽ xử lý được vấn đề phân trang sản phẩm đã được nêu ra. Mình sẽ show code rồi giải thích ở phía dưới nhé:
import scrapy
from scrapy_splash import SplashRequest
from demo_scrapy.items import ProductItem
class ShopeeCrawlSpider(scrapy.Spider):
name = 'shopee_crawl'
allowed_domains = ['https://shopee.vn']
start_urls = ["https://shopee.vn/sp.btw2"]
render_script = '''
function main(splash)
assert(splash:go(splash.args.url))
assert(splash:wait(2))
local num_scrolls = 10
local scroll_delay = 1
local scroll_to = splash:jsfunc("window.scrollTo")
local get_body_height = splash:jsfunc(
"function() {return document.body.scrollHeight;}"
)
for _ = 1, num_scrolls do
local height = get_body_height()
for i = 1, 10 do
scroll_to(0, height * i/10)
splash:wait(scroll_delay/10)
end
end
assert(splash:wait(2))
assert(splash:runjs("document.querySelector('button.shopee-icon-button.shopee-icon-button--right').click()"))
assert(splash:wait(2))
return {
html = splash:html(),
url = splash:url(),
}
end
'''
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
endpoint="render.html",
args={
'wait': 5,
},
callback=self.parse,
dont_filter=True
)
def parse(self, response):
item = ProductItem()
for data in response.css("div.shop-search-result-view__item"):
item["name"] = data.css("div._36CEnF ::text").extract_first()
sale = data.css("div.WTFwws._3f05Zc._3_-SiN")
if sale:
item["price"] = data.css("div.WTFwws._3f05Zc._3_-SiN ::text").extract_first().lstrip('₫')
item["price_sale"] = data.css("div.WTFwws._1lK1eK._5W0f35 span:last-child ::text").extract_first()
else:
item["price"] = data.css(
"div.WTFwws._1lK1eK._5W0f35 > span._29R_un:last-child ::text").extract_first()
item["price_sale"] = 'No discount'
sold = data.css("div.go5yPW ::text").extract_first()
item["sold"] = sold.split()[2] if sold else 0
yield item
current_page = response.css('span.shopee-mini-page-controller__current ::text').extract_first()
total_page = response.css('span.shopee-mini-page-controller__total ::text').extract_first()
print('Page:', current_page, '/', total_page)
if current_page != total_page:
yield SplashRequest(
url=response.url,
callback=self.parse,
meta={
"splash": {
"endpoint": "execute",
"args": {
'wait': 5,
'url': response.url,
"lua_source": self.render_script,
},
}
},
dont_filter=True
)
Nhìn thì có vẻ dài nhưng thực ra khá đơn giản thôi , mình sẽ giải thích chi tiết từng bước:
- Hãy nhớ import
scrapycũng nhưscrapy_splashđể có thể sử dụng SplashRequest và importProductItemtừitemsđể link đúngitem pipelinescủa project nhé. - Về
name,domainvàstart_urlsmình đã giải thích ở các bài viết trước rồi nên ở đây mình sẽ không nhắc lại nữa. Mình đang cho crawl duy nhất một url tới shop mục tiêu mà mình đã define từ ban đầu. - Vì Shopee dùng js render nên tại function
start_requests, mình sẽ dùng SplashRequest để gửi request đến url của shop rồi chờ 5s để trả về html của trang web tương ứng, sau khi đã có html được render đầy đủ thì tiến hành gọi đến functionparseđể extract dữ liệu. Và mình có thêm optiondont_filter=Trueđể tránh lỗi[scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to <domain>. - Function
parsesẽ có nhiệm vụ extract chính xác dữ liệu dựa vào việc bạn select tới đúng element đó trên DOM. Bạn có thể dùng CSS Selector cũng như Xpath để thực hiện điều này, ở đây mình dùng CSS Selector. Lúc extract thì mình có xử lý chuỗi 1 chút để dữ liệu được lấy về được clean hơn. - Cũng tại function
parse, sau khi crawl xong response được trả về bởiSplashRequesttừ functionstart_requests, mình sẽ check phân trang, nếu chưa phải là phân trang cuối cùng thì tiếp tục tiến hành crawl trang sản phẩm tiếp theo. Bằng việc gửiSplashRequestcó meta: endpoint làexecutevà truyềnlua_sourceargs là đoạnrender_scriptđược viết bằng lua script phía trên. Hãy nhớ là phải đặt endpoint làexecuteđể thực thi được đoạn script chuyển trang trongrender_scriptthay vì set endpoint làrender.htmlthì nó chỉ trả về HTML đã được render mà thôi. - Đoạn
render_scriptcó tác dụng scroll page tới cuối để đợi cho trang được render hoàn toàn, sau đó thực hiện click vào button next trang, mỗi thao tác mình đợi 2s để chờ browser xử lý. Sau khi next được sang trang mới thì trả về HTML và url đã được render cho functionparsexử lý tiếp. Mình đã tham khảo splash documentation và javascript để viết đoạnrender_scripttrên, các bạn có thể tham khảo thêm. - Các bước được lăp đi lặp lại cho tới khi đã crawl được tất cả các trang sản phẩm. Tạm thời done rùi =))
4. Chạy crawl
Code xong xuôi rồi thì vẫn như thường lệ, mình sẽ lôi đống data trên webpage về bằng câu lệnh sau:
scrapy crawl shopee_crawl -o shopee_crawl.json
Đây là đoạn log sau khi đã chạy crawl thành công:
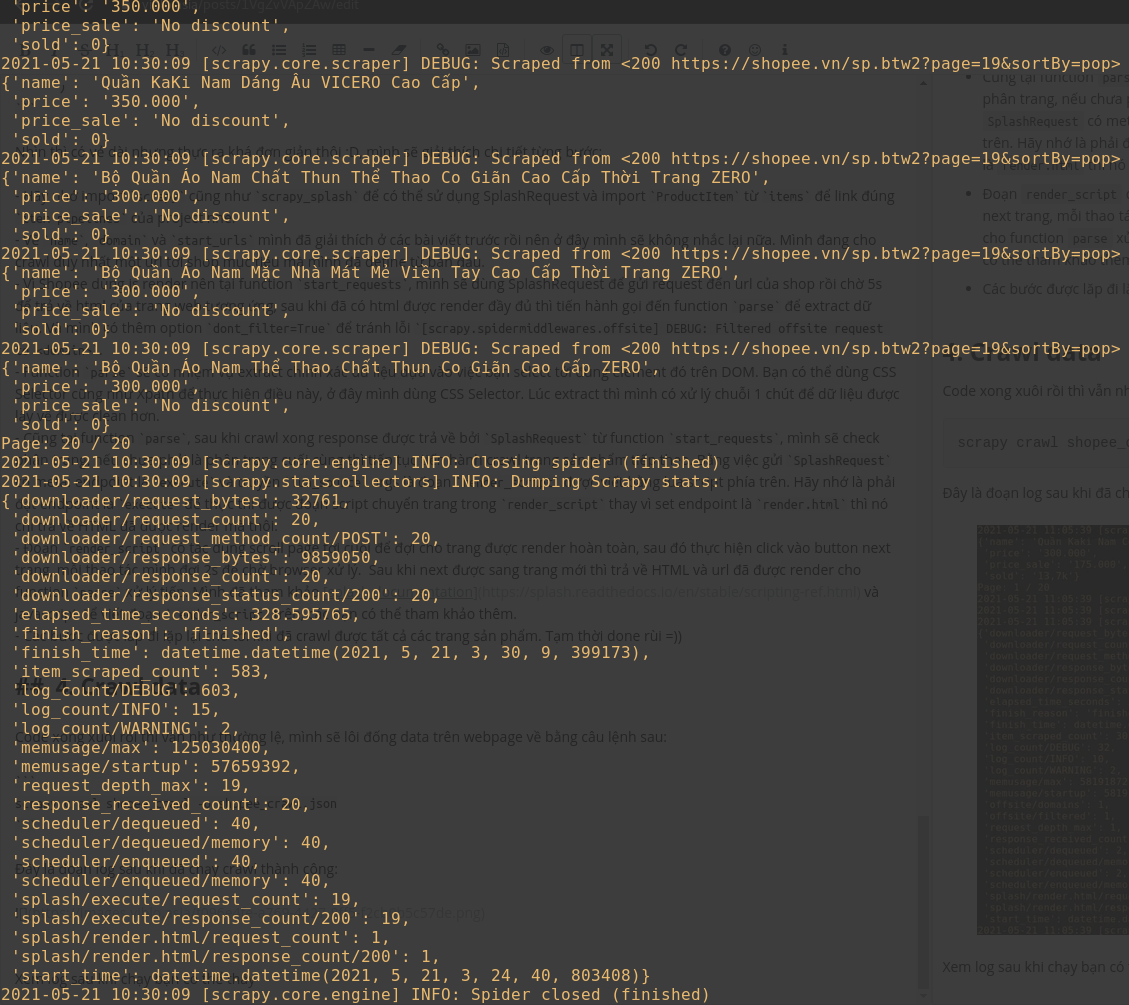
Xem log sau khi chạy bạn có thể thấy item_scraped_count: 583 tức là chúng ta đã crawl được tổng cộng 583 sản phẩm từ shop đó sau khi crawl lần lượt 20 page. Check lại các thông tin hoàn toàn trùng khớp =))
Trong trường hợp, các bạn muốn crawl nhiều shop hơn thì hãy tự tạo cho mình một con spider có nhiệm vụ crawl url của shop đó rồi lưu vào DB hay file json. Tiếp theo là truyền tất cả url các shop vào starts_url của con spider mình vừa tạo thì các bạn đã có thể crawl được hết sản phẩm của tất cả các shop rồi, easy chưa =))
Kết luận
Rất có thể bài viết của mình có thể chỉ crawl được trong thời điểm mình viết bài, các bạn cần theo dõi cập nhập giao diện từ shopee xem họ có thay đổi HTML hay không để chỉnh lại selector cho phù hợp, tránh trường hợp HTML bị thay đổi dẫn tới sai selector không crawl được chính xác data.
Cảm ơn các bạn đã giành thời gian theo dõi bài viết này cũng như series về crawl data của mình (đừng ngại ngần để lại 1 upvote, clip và follow cho mình nhaa ), nếu có gì còn thiếu sót, góp ý, các bạn có thể để lại bình luận bên dưới bài viết để cùng nghiên cứu và cải thiện. (bow)
All rights reserved
