Sự kết hợp hoàn hảo của Scrapy và Splash - Giải pháp tối ưu với trang web sử dụng Javascript?
Bài đăng này đã không được cập nhật trong 5 năm

1. Lời mở đầu
Ở bài viết trước về Scrapy, mình đã cùng tìm hiểu cơ bản về Scrapy và làm 1 demo nho nhỏ để crawl dữ liệu từ trang web thegioididong. Có thể các bạn sẽ thấy với Scrapy thì chúng ta muốn crawl trang web nào cũng được, mình cũng đã từng nghĩ vậy và đã thử với các trang web thương mại điện tử nổi tiếng như Shopee, Lazada,... nhưng dữ liệu trả về chả có gì cả. Như vậy, giới hạn của Scrapy là những trang web sử dụng javascript để render, mà cái thời nay thì nhà nhà dùng JS, người người dùng JS thì biết phải làm saoo.
Giờ thì hãy cùng mình tiếp tục tìm cách giải quyết xem sao nhé =))
2. Kiểm tra trang web sử dụng javascript để render
Như mình đã nói ở trên, nhược điểm của Scrapy là không thể crawl được những trang web dùng js render. Vậy nên, mỗi khi trong đầu le lói ý muốn crawl 1 trang web nào với Scrapy thì hãy kiểm tra ngay điều này trước khi cắm mặt vào code rồi công sức đổ sông đổ bể.
Để biết rằng trang này có render bằng js ra nội dung không, bạn chỉ cần Ctrl+U rồi xem có nội dung html như hiển thị không, hay chỉ là một thẻ body rồi js chèn vào sau. Hoặc sử dụng Chrome Extension Quick Javascript Switcher, công cụ này cho phép bật hoặc vô hiệu hóa Javascript của trang web rất đơn giản bằng 1 cú click chuột.
Sau một hồi tìm hiểu thì mình thấy Scrapy có thể sử dụng kèm với headless browser như Splash để chờ trang web render ra nội dung và cookie, rồi gửi lại đống HTML đã generated về crawler để bóc tách như bình thường, việc này làm tốn thêm một ít thời gian chờ nhưng vẫn nhanh hơn các lựa chọn khác Scrapy.
Dưới đây là một số chức năng mà Splash mang lại cho chúng ta:
process multiple webpages in parallel;
get HTML results and/or take screenshots;
turn OFF images or use Adblock Plus rules to make rendering faster;
execute custom JavaScript in page context;
write Lua browsing scripts;
develop Splash Lua scripts in Splash-Jupyter Notebooks.
get detailed rendering info in HAR format.
Không những thế, còn có hẳn một lib scrapy-splash dành riêng cho Scrapy nữa. Vậy là có đao có kiếm trong tay rồi, cầm đi chinh phạt mấy web dùng JS thôi nào =)))
3. Thực hành
3.1. Tạo project và spider
Mình sẽ sử dụng luôn project lần trước để thực hiện demo này, nếu các bạn còn chưa biết cách tạo thì có thể follow theo bài viết đó để tạo project nhé 
Lần này Shopee sẽ là mục tiêu chinh phạt của mình, dùng Quick Javascript Switcher thì thấy đúng là nó dùng JS thật rồi, ngứa tay ngứa chân quá, mình tạo ngay 1 Spider crawl_shopee để crawl tất cả sản phẩm của 1 shop bất kì trên Shopee, vì demo đơn giản nên ở đây mình chọn tạm shop Apple Flagship Store vì chỉ có 1 page sản phẩm, tạo spider bằng câu lệnh sau:
scrapy genspider shopee_crawl https://shopee.vn/shop/88201679/search
Mới chỉ bước đến cửa shop thôi, chưa vào trong được, lúc này mới nhớ ra là quên đao kiếm ở nhà, vội vàng về lấy thôi :v
3.2. Cài đặt Splash và scrapy-splash
Muốn cài đặt được Splash thì đầu tiên bạn phải có Docker cái đã. Sau khi có Docker, bạn chỉ cần chạy 2 câu lệnh sau:
$ sudo docker pull scrapinghub/splash
$ sudo docker run -p 8050:8050 scrapinghub/splash
Hiện tại mới chỉ có đao thôi, muốn xài kiếm nữa thì tiếp tục sử dụng câu lệnh sau để cài đặt scrapy-splash:
$ pip install scrapy scrapy-splash
Thêm một chút config trong file settings.py như sau:
# ...
SPLASH_URL = 'http://localhost:8050'
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
COOKIES_ENABLED = True # Nếu cần dùng Cookie
SPLASH_COOKIES_DEBUG = False
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 400,
}
DOWNLOAD_DELAY = 10
# ...
Okayyy, vậy là đã cài đặt đầy đủ Splash và scrapy-splash rồi, tay đã đủ đao kiếm, đi thôi =)))
3.3. Xác định dữ liệu mục tiêu muốn crawl
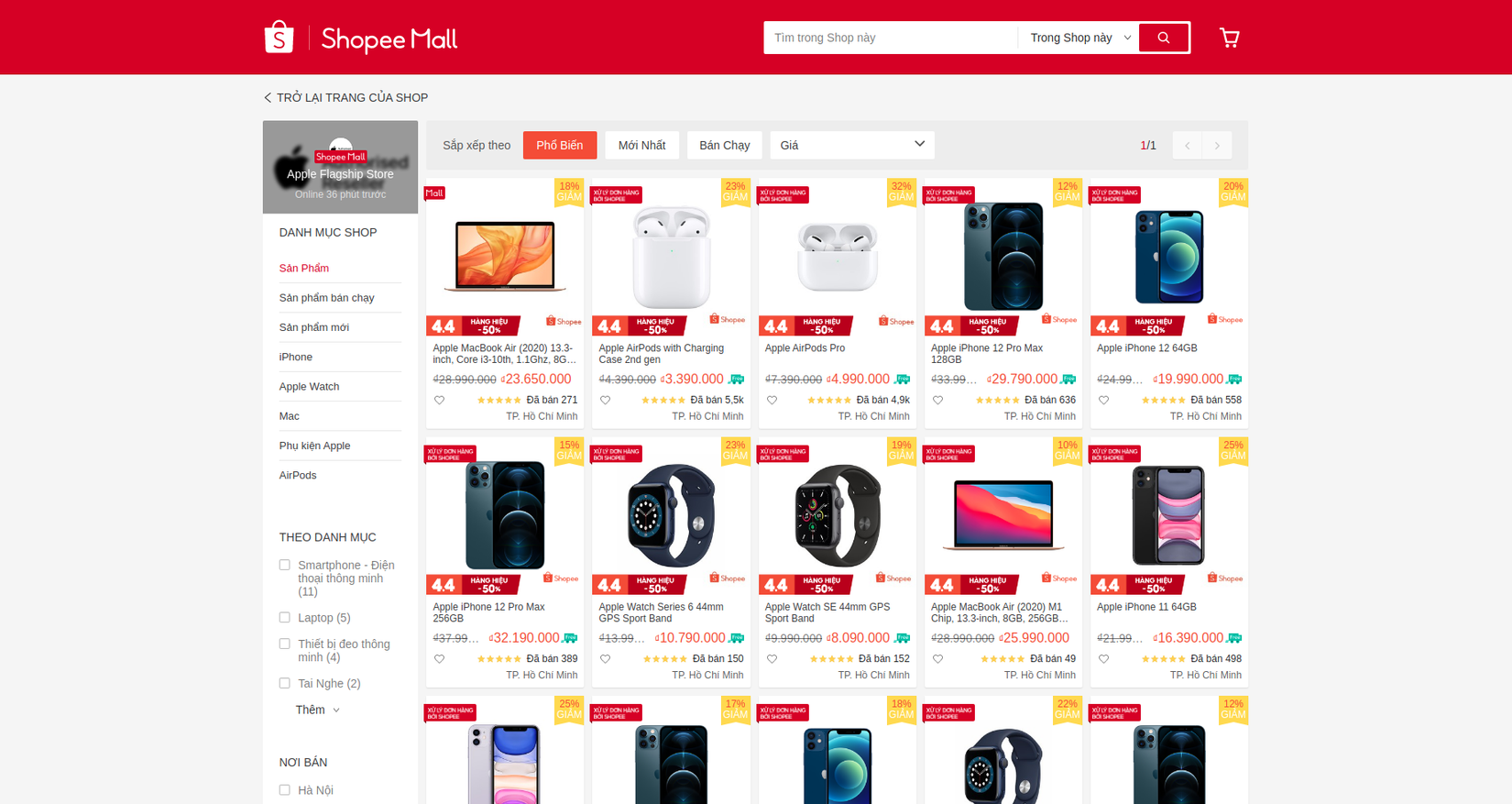
Bước vào shop Apple Flagship Store để xem có những thông tin nào mình có thể lấy được ở trang này. Quan sát và mình thấy có thể lấy được những thông tin quan trọng như: tên sản phẩm, giá gốc, giá khuyến mãi, đã bán được bao nhiêu. Hãy bật inspect và tiến hành phân tích cấu trúc trang web để có thể select những element trên DOM thật chính xác nhé =))
Tiếp theo, hãy tạo thêm 1 class ProductItem để define những dữ liệu mà mình muốn lấy ở trong file items.py như sau:
class ProductItem(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
price_sale = scrapy.Field()
sold = scrapy.Field()
Giờ thì hãy quay lại ShopeeCrawlSpider để tiến hành crawl shop này thôi, mình sẽ show code luôn và giải thích ở phía dưới nhé:
import scrapy
from scrapy_splash import SplashRequest
from demo_scrapy.items import ProductItem
class ShopeeCrawlSpider(scrapy.Spider):
name = 'shopee_crawl'
allowed_domains = ['shopee.vn']
start_urls = ['https://shopee.vn/shop/88201679/search']
render_script = """
function main(splash)
local url = splash.args.url
assert(splash:go(url))
assert(splash:wait(5))
return {
html = splash:html(),
url = splash:url(),
}
end
"""
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint='render.html',
args={
'wait': 5,
'lua_source': self.render_script,
}
)
def parse(self, response):
item = ProductItem()
for product in response.css("div.shop-search-result-view__item"):
item["name"] = product.css("div._36CEnF ::text").extract_first()
item["price"] = product.css("div._3_-SiN ::text").extract_first()
item["price_sale"] = product.css("span._29R_un ::text").extract_first()
item["sold"] = product.css("div.go5yPW ::text").extract_first()
yield item
Giờ mình sẽ giải thích những gì mà đoạn code trên đã làm:
- Về
name,domainvàstart_urlsmình đã giải thích ở bài viết trước rồi nên ở đây mình sẽ không nhắc lại nữa. - Bình thường thì Scrapy sẽ
parsetrực tiếp từ các url trong liststart_urls, nhưng vì ở đây có 1 bước dùng JS đầu tiên nên ta không thể làm vậy được, mà phải đi qua functionstart_requests, dùngSplashRequestchờ 5s và trả vềhtml,urlđã được render cho các request sắp tới bằng đoạnrender_scriptđược viết bằng lua script như ở phía trên. Có 1 gợi ý nho nhỏ là sau khi bạn mở port 8050 cho Splash thì bạn có thể truy cập vào0.0.0.0:8050để tham khảo những đoạn lua script examples mà Splash đã xây dựng sẵn cho chúng ta hoặc có thể vào docs API của Lua script nếu bạn cần viết script phức tạp hơn. - Sau khi có
htmlvàurlđã được render, request được gửi trực tiếp tới parse, lúc này response của parse sẽ là trang web đã được render cóurltương ứng vớiurlcủaSplashRequestphía trên. - Lúc này
responseđã được render đầy đủhtmlrồi, quay trở lại với việc lựa chọn selector sao cho chính xác để thu được dữ liệu mình mong muốn mà thôi, nếu khó quá thì bật inspect và copy selector thôi, nhớ phải phân tích kĩ trước khi select đó nhé :v
3.4. Tiến hành crawl data về
Okayyy, đã mất công vác đao vác kiếm đến tận shop rồi, giờ thì xem thành quả thu được sau khi chinh phạt shop này bằng câu lệnh sau:
scrapy crawl shopee_crawl -o product.json
Hãy nhớ cấu hình thêm User-Agent trong DEFAULT_REQUEST_HEADERS hoặc biến cục bộ USER_AGENT trong file settings.py để tránh việc bị chặn bot crawl  Giờ thì mở file
Giờ thì mở file product.json lên xem data mà mình lấy về có thực sự trùng khớp với shop hay không nhé:
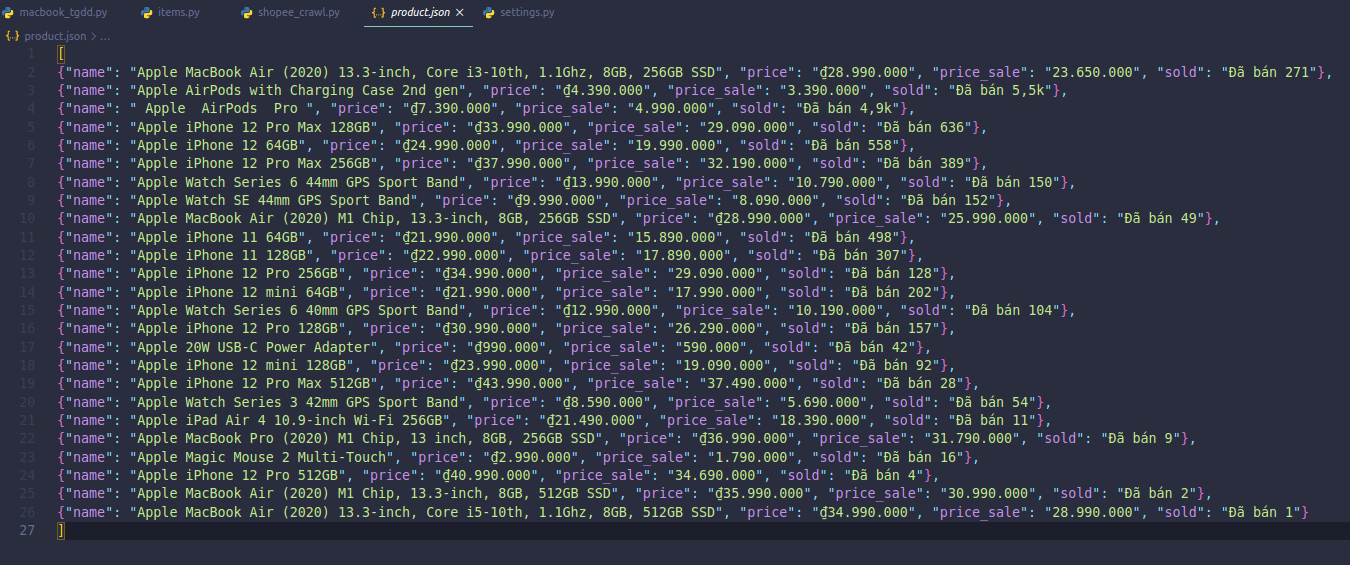
Check một chút thì thấy số lượng sản phẩm và các thông tin crawl được đều trùng khớp, thành công rồi =))
4. Kết luận
Vậy là mình thực hiện xong demo nhỏ để giới thiệu cơ bản về sự kết hợp của Scrapy và Splash. Thực sự thì đây là sự kết hợp được đánh giá rất cao so với các giải pháp khác mà mình tìm đọc được như sử dụng Requests-HTML (chỉ dành cho Python > 3.6) hay Selenium (Tiêu thụ tài nguyên hệ thống nhiều hơn khi tạo rất nhiều requests trong khi crawl => quá tải).
Như mình đã note ở bài trước, bài viết của mình có thể chỉ crawl được trong thời điểm mình viết bài, các bạn cần theo dõi cập nhập giao diện từ shopee xem họ có thay đổi HTML hay không để chỉnh lại selector cho phù hợp, tránh trường hợp HTML bị thay đổi dẫn tới sai selector không crawl được chính xác data.
Có thể trong bài viết lần sau, mình sẽ thực hiện crawl chi tiết thông tin có trong từng sản phẩm và tính tới việc trang web có phân trang sản phẩm nữa.
Cảm ơn các bạn đã giành thời gian đọc bài viết của mình, nếu có gì còn thiếu sót, góp ý, các bạn có thể để lại bình luận bên dưới bài viết để cùng nghiên cứu và cải thiện. (bow)
5. Tham khảo
https://medium.com/@doanhtu/scrapy-và-splash-sự-kết-hợp-tuyệt-vời-c7745dc9ab56
https://viblo.asia/p/thu-thap-du-lieu-voi-scrapy-splash-noi-dung-duoc-tao-boi-javascript-3Q75wBbMlWb
All rights reserved
