Tập tành crawl dữ liệu với Scrapy Framework
Bài đăng này đã không được cập nhật trong 5 năm
Lời mở đầu
Chào mọi người, mấy hôm nay mình có tìm hiểu được 1 chút về Scrapy nên muốn viết vài dòng để xem mình đã học được những gì và làm 1 demo nho nhỏ.
Giả sử dạo này đang nhiều tiền muốn nhập Macbook về bán lấy hời, và giờ muốn nghiên cứu những shop khác họ bán những con Macbook nào và giá rổ ra làm sao thì chả nhẽ mình phải lên trang web của họ rồi xem trực tiếp từng sản phẩm hay sao @@. Không không, mình muốn xem những dữ liệu đấy theo dạng thống kê báo cáo cho chuyên nghiệp thay vì phải click từng sản phẩm để xem thủ công, vừa đau mắt vừa tốn thời gian. Phải nghĩ ngay tới việc dùng Scrapy sẽ giúp mình crawl dữ liệu của các em Macbook về và xuất ra dạng json, csv,... trực quan hơn và dễ thao tác để thống kê báo cáo hơn.
Giờ thì cùng mình tìm hiểu và thực hiện demo 1 chút, và ở demo này mình sẽ crawl dữ liệu cơ bản của mấy em Macbook trên thegioididong xem sao nhé 

1. Tạo project scrapy
Trước tiên, vì scrapy là 1 framework của python nên chúng ta cần cài đặt python, scrapy cái đã. Hãy follow theo các bước trên trang chủ của scrapy để tiến hành cài đặt nhé 
Tiếp theo, mình sẽ tạo project scrapy với tên là tutorial bằng câu lệnh sau:
scrapy startproject demo_scrapy
Project tutorial mà chúng ta vừa tạo có cấu trúc như sau:
demo_scrapy/
scrapy.cfg # deploy configuration file
demo_scrapy/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
2. Tạo spider
Sau khi đã tạo xong project thì giờ chúng ta cần tạo 1 con spider để tiến hành crawl bằng câu lệnh sau:
scrapy genspider macbook_tgdd www.thegioididong.com/laptop-apple-macbook
Câu lệnh trên đã tạo 1 spider MacbookTgddSpider ở trong thư mục spiders như sau:
import scrapy
class MackbookTgddSpider(scrapy.Spider):
name = 'macbook_tgdd'
allowed_domains = ['www.thegioididong.com']
start_urls = ['https://www.thegioididong.com/laptop-apple-macbook/']
def parse(self, response):
pass
Như bạn đã thấy:
- Con spider này có name là
macbook_tgddsẽ được sử dụng để chạy cmd lúc crawl. start_urls: đây là địa chỉ bắt đầu cho spider, có thể là một list các url tương ứng với domain trongallowed_domains. Tại demo này mình sẽ bắt đầu ở link các sản phẩm Macbook.parse(): Chính là function mình sẽ viết code để điều khiển spider đi crawl những data mà mình muốn lấy về từ url phía trên.
3. Lựa chọn data muốn crawl
Đầu tiên, chúng ta cần xác định trước data mà chúng ta muốn là những gì. Ở đây mình cần thống kê thị trường Macbook được bán ở thegioididong nên mình sẽ crawl tên sản phẩm, giá gốc, giá sale và lượng vote trung bình của mỗi em Macbook. Sau khi đã lên ý tưởng những item muốn crawl thì việc tiếp theo là define những item đó trong file items.py như sau:
import scrapy
class DemoScrapyItem(scrapy.Item):
product_name = scrapy.Field()
price_sale =scrapy.Field()
price = scrapy.Field()
rate_average = scrapy.Field()
Giờ thì bắt tay vào việc chính thôi, để crawl được đúng item mình cần thì các bạn cần phải chọn được đúng tới đối tượng đó trên DOM .Có thể sử dụng Css selectors hoặc Xpath đều được, tuy nhiên mỗi cái đều có ưu nhược điểm riêng nên các bạn tự tham khảo để sử dụng cho phù hợp nhé
Ở demo này mình sẽ dùng Css selectors để select tới những item mà mình muốn lấy, bật inspect lên và copy selector của những item đó như sau:
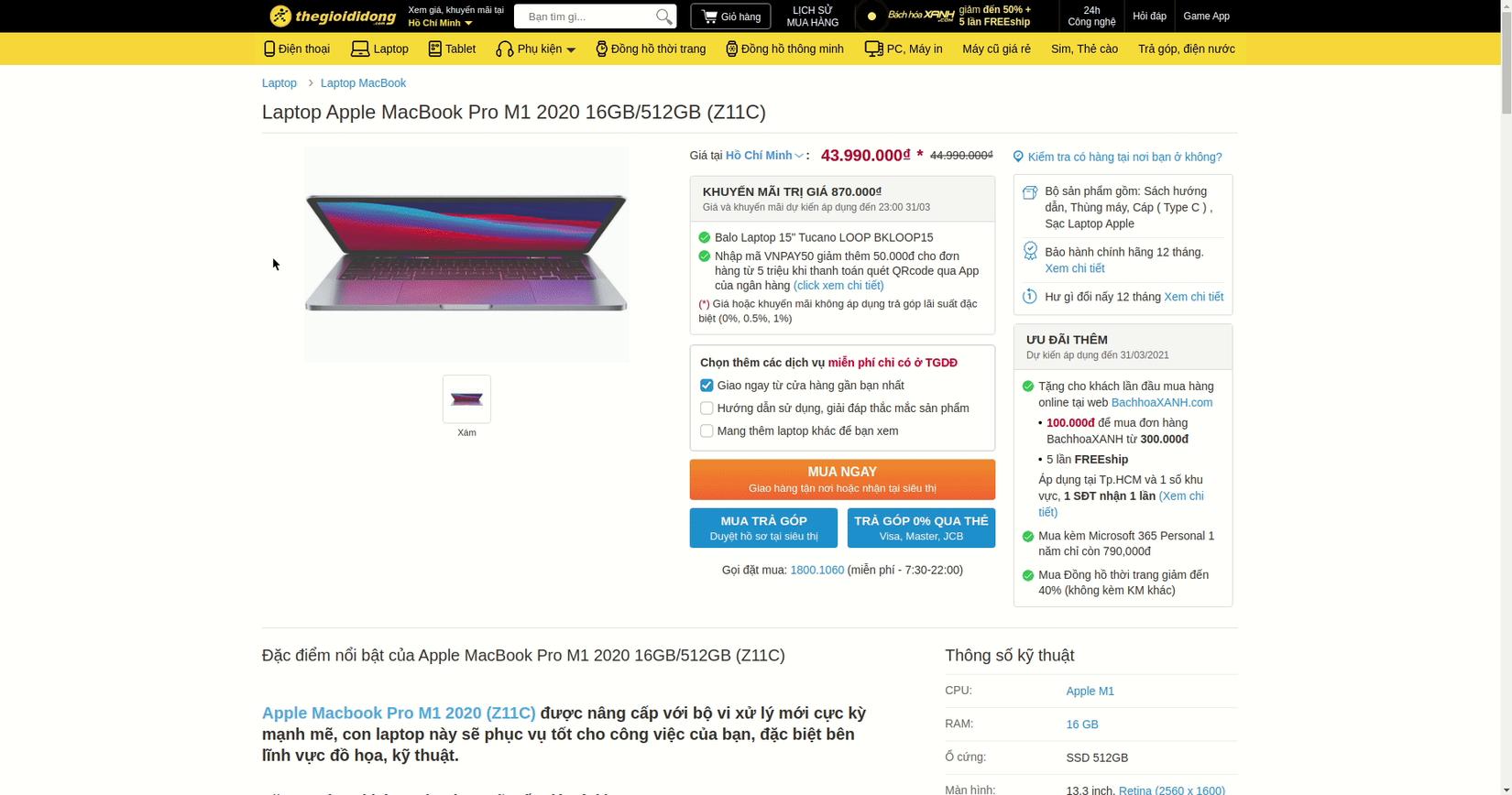
Thực hiện lần lượt với các item tiếp theo, sau một hồi code, file spiders/macbook_tgdd.py của mình sẽ như sau:
import scrapy
from demo_scrapy.items import DemoScrapyItem
class MacbookTgddSpider(scrapy.Spider):
name = 'macbook_tgdd'
allowed_domains = ['www.thegioididong.com']
start_urls = ['https://www.thegioididong.com/laptop-apple-macbook/']
def parse(self, response):
# Request tới từng sản phẩm có trong danh sách các Macbook dựa vào href
for item_url in response.css("li.item > a ::attr(href)").extract():
yield scrapy.Request(response.urljoin(item_url), callback=self.parse_macbook) # Nếu có sản phẩm thì sẽ gọi tới function parse_macbook
# nếu có sản phẩm kế tiếp thì tiếp tục crawl
next_page = response.css("li.next > a ::attr(href)").extract_first()
if next_page:
yield scrapy.Request(response.urljoin(next_page), callback=self.parse)
def parse_macbook(self, response):
item = DemoScrapyItem()
item['product_name'] = response.css(
'div.rowtop > h1 ::text').extract_first() # Tên macbook
out_of_stock = response.css('span.productstatus ::text').extract_first() # Tình trạng còn hàng hay không
if out_of_stock:
item['price'] = response.css(
'strong.pricesell ::text').extract_first()
else:
item['price'] = response.css(
'aside.price_sale > div.area_price.notapply > strong ::text').extract_first()
discount_online = response.css('div.box-online.notapply').extract_first() # Check nếu có giảm giá khi mua online hay không
if discount_online:
item['price_sale'] = response.css(
'aside.price_sale > div.box-online.notapply > div > strong ::text').extract_first()
else:
item['price_sale'] = response.css(
'span.hisprice ::text').extract_first()
item['rate_average'] = response.css('div.toprt > div.crt > div::attr(data-gpa)').extract_first()
yield item
Mình sẽ giải thích 1 chút đoạn code phía trên:
parse(): Vì các dữ liệu của từng sản phẩm ở bên ngoài danh sách Macbook có thể chưa đáp ứng đủ nhu cầu crawl của mình nên cần vào từng link sản phẩm bên trong thẻliở trong list đó, mỗilichứa 1 sản phẩm. Dựa vào href của mỗi sản phẩm, mình sẽ gửiscrapy.Requesttới url của sản phẩm đó và gọi tớiparse_macbook()để thực hiện crawl.parse_macbook(): Ở hàm này, mình sẽ tiến hành crawl những item mà mình define trongDemoScrapyItem(). Hãy xem xét kĩ trang web và inspect để select đúng tới item đó trên DOM nhé :v, ví dụ như khi shop hết hàng thì selector của giá sản phẩm sẽ khác, hoặc selector của giá sale cũng sẽ khác khi mua hàng online. Nên cân nhắc kĩ khi Copy selector chứ đừng copy luôn kẻo crawl không ra đúng data nhé =))
4. Tiến hành crawl
Giờ thì có thể lôi đống data của Macbook trên thegioididong về, Scrapy hỗ trợ xuất dữ liệu sang các định dạng khác nhau như JSON, CSV và XML. Tại mình quen nhìn JSON rồi nên ở đây mình sẽ xuất ra JSON :v
scrapy crawl macbook_tgdd -o macbook_tgdd.json
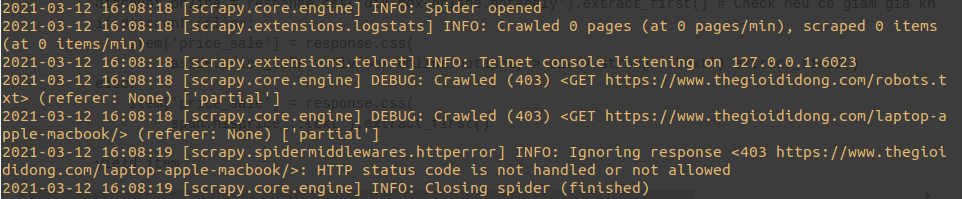
Kết quả là mình thu được lỗi 403  . Do các website thường có cơ chế chặn bot crawl data của họ. Phải xử lý ngay lỗi này bằng việc cấu hình thêm
. Do các website thường có cơ chế chặn bot crawl data của họ. Phải xử lý ngay lỗi này bằng việc cấu hình thêm User-Agent trong DEFAULT_REQUEST_HEADERS mà Scrapy comment đi ở file settings.py như sau, à đồng thời các bạn cấu hình thêm utf-8 để tránh lỗi font nha:
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:48.0) Gecko/20100101 Firefox/48.0',
}
FEED_EXPORT_ENCODING = 'utf-8'
Ok, giờ thì chạy lại lệnh crawl ở trên xem thu được gì nào:
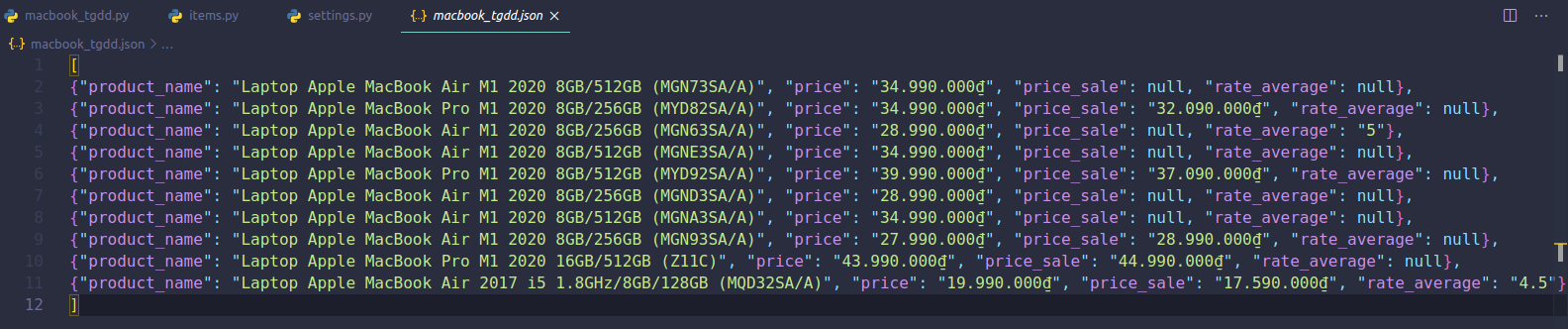
Hãy check thủ công lại một chút so với web thegioididong xem mình đã crawl đúng hay chưa :v, sau khi check thì thấy một số price_sale null do con Macbook đó không được sale, còn rate_average null thì do con Macbook đó chưa có ai rate luôn :v, còn lại thì đều match 100%. Vậy là thành công rồi đó =))
Kết luận
Như vậy là mình đã crawl được 1 số thông tin giúp ích cho việc nghiên cứu thị trường để kinh doanh Macbook của mình rồi, tuy nhiên đây chỉ là 1 demo cơ bản và số lượng Macbook được bán ở thegioididong vẫn còn ít nên bạn thấy nghiên cứu thủ công sẽ nhanh hơn =)) Nhưng trong trường hợp có nhiều sản phẩm hơn và được phân trang tới hàng chục hàng trăm thì có mà nổ đom đóm mắt :v
Lưu ý một chút là bài viết của mình có thể chỉ crawl được trong thời điểm mình viết bài, các bạn cần theo dõi cập nhập giao diện từ thegioididong xem họ có thay đổi HTML hay không để chỉnh lại selector cho phù hợp, tránh trường hợp HTML bị thay đổi dẫn tới sai selector không crawl được chính xác data.
Cảm ơn các bạn đã giành thời gian đọc bài viết của mình, nếu có gì còn thiếu sót, góp ý, các bạn có thể để lại bình luận bên dưới bài viết để cùng nghiên cứu và cải thiện. (bow)
All rights reserved
