Sử dụng Web cho việc kiểm tra và sửa chính tả
Bài đăng này đã không được cập nhật trong 4 năm
1. ĐỊNH NGHĨA
Kiểm tra chính tả là nhiệm vụ dự đoán những từ trong tài liệu sai chính tả. Những dự đoán có thể được thể hiện với người dùng bởi đường gạch chân những từ sai chính tả. Sửa chính tả là nhiệm vụ thay thế những chính tả sai thành đúng. Kiếm tra và sửa chính tả được ứng dụng rộng rãi cho những nhiệm vụ như Nhận dạng ký tự trên ảnh.Chúng ta thiết kế, thực hiện và đánh giá một hệ thống end-to-end thực hiện kiểm tra và sửa chính tả.
2. BÀI TOÁN
Sự mới lạ quan trọng trong bài viết là hệ thống được phát triển hoàn toàn không sử dụng những nguồn được chú thích thủ công hay bất kỳ từ điển biên soạn chứa những từ đúng chính tả. Hệ thống đa giai đoạn tích hợp mô hình lỗi thống kê và những mô hình ngôn ngữ LM với một bộ phân loại học máy thông kê. Tại mỗi giai đoạn, dữ liệu được yêu cầu cho những mô hình huấn luyện và xác định những trọng số trên các bộ phân loại. Những mô hình và bộ phân loại được huấn luyện tự động từ sự đếm tần suất qua Web và dữ liệu tin tức. Hiệu năng hệ thống được thẩm định trên 1 tập dữ liệu đánh máy bới người. Hệ thống chuyển đa ngôn ngữ dễ dàng. Hầu hết những hệ thống chính tả ngày nay yêu cầu một số nguồn thủ công trong ngôn ngữ cụ thể như từ vựng, danh sách các lỗi chính tả hay các quy tắc. Những hệ thống sử dụng mô hình thống kê yêu cầu tập ngữ liệu những lỗi chính tả lớn, được chú thích, cho việc huấn luyện. Những mô hình thống kê không yêu cầu dữ liệu được chú thích. Thay vào đó, chúng ta dựa trên Web như một tập ngữ liệu nhiễu lớn theo những cách sau:
1) Chúng ta suy luận thông tin về những lỗi chính tả từ cách sử dụng từ ngữ trên Web và sử dụng điều này để xây dựng 1 mô hình lỗi.
2) Những từ được thấy nhiều nhất được cho vào một danh sách khi sửa những từ tiềm năng.
3) Những n-gram được dùng để xây dựng LM. Chúng ta sử dụng để sửa từ phù hợp với ngữ cảnh. Do mô hình lỗi dựa trên việc lấy chuỗi con, không có từ ngữ đúng chính tả cố định để xác định từ sai chính tả. Do đó mô hình lỗi cho phép cả những từ đúng và sai chính tả. Hơn nữa khi kết hợp với LM n-gram, hệ thống có thể phát hiện và sửa những từ thay thế.
Bộ phân loại tin cậy xác định những ngưỡng cho phát hiện và sửa tự động lỗi chính tả. Để huấn luyện những bộ phân loại này, chúng ta cần một số nội dung văn bản sai chính tả và đi kèm những từ đúng chính tả. Một tập con dữ liệu Web từ những trang tin tức được sử dụng bởi vì chúng ta giả định nó chứa tương đối ít lỗi chính tả. Bộ phân loại tin cậy có thể được huấn luyện đầy đủ và điều chỉnh không có lỗi chính tả mà với dữ liệu tin tức sạch được thêm lỗi chính tả bằng tay.
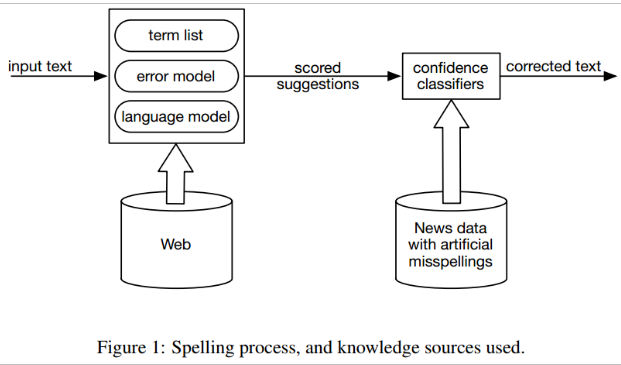
Quy trình xử lý văn bản và dữ liệu được sử dụng trong việc xây dựng hệ thống được trình bày trong hình 1 và chi tiết trong phần này. Với mỗi ký tự trong văn bản đầu vào, những gợi ý tiềm năng được lấy từ danh sách các từ và được ghi điểm sử dụng 1 mô hình lỗi. Những gợi ý tiềm năng được đánh giá trong ngữ cảnh sử dụng 1 mô hình ngôn ngữ và được xếp hạng lại. Với mỗi ký tự, chúng ta sử dụng bộ phân loại để xác định độ tin cậy của chúng liệu một từ sai chính tả hay không, và nếu sai thì tự động sửa theo gợi ý được ghi điểm tốt nhất có sẵn.
a. Danh sách các từ: (Term List)
Chúng ta yêu cầu 1 danh sách các từ để sử dụng khi sửa các từ tiềm năng sai. Thay vì cố gắng xây dựng 1 từ điển các từ đúng chính tả, chúng tôi lấy những ký tự xuất hiện nhiều nhất trên Web. Chúng tôi đã sử dụng một mẫu lớn những trang Web (hơn 1 tỷ), đánh ký tự chúng, và lấy 10 triệu ký tự xảy ra nhiều nhất, với những bộ lọc đơn giản cho non-words (quá nhiều dấu câu, quá ngắn hoặc quá dài) . Danh sách các từ là quá lớn do nó sẽ chứa những từ đúng chính tả nhất, nhưng cũng có một số lượng lớn những từ non-words hoặc sai chính tả.
b. Mô hình lỗi
Chúng tôi sử dụng 1 mô hình lỗi chuỗi con để ước lượng P(w|s). Để lấy được mô hình lỗi, đặt R là một phân vùng của s thành những chuỗi con liên tiếp, và tương tự đặt T là một phân vùng của w, sao cho |T|=|R|. Những phân vùng được liên kết 1-1 và cho phép những phân vùng trống, những mô hình liên kết chèn và xóa các chuỗi con.
c. Những bộ phân loại tin cậy cho việc kiểm tra và sửa lỗi
Kiểm tra chính tả và tự động sửa được thực hiện như là một quy trình gồm 3 giai đoạn. Những bộ phân loại tin cậy cân bằng “độ chính xác gọi lại” tới những cấp độ mong muốn cho cả kiểm tra chính tả và tự động sửa. Đầu tiên, tất cả những gợi ý s cho 1 từ w được xếp hạng theo xác suất P(s|w) của chúng. Thứ hai, một bộ phân loại kiểm tra chính tả được dùng để dự đoán liệu w có sai chính tả. Thử ba, nếu w được dự đoán sai chính tả và s không rỗng, một bộ phân loại sửa tự động được dùng để dự đoán liệu gợi ý được xếp hạng đầu có đúng. Bộ phân loại kiểm tra chính tả được thực hiện sử dụng 2 bộ phân loại nhúng, một trong chúng được dùng khi s rỗng, và bộ còn lại dùng khi s không rỗng. Thiết kế này được chọn bởi vì những tín hiệu hữu ích cho dự đoán liệu một từ đã sai chính tả có thể khác khi không có những gợi ý có sẵn, và bởi vì những đặc trưng nhất định chỉ có thẻ áp dụng khi có những gợi ý. Những thử nghiệm của chúng tôi sẽ so sánh 2 kiểu phân loại. Cả hai dựa trên huấn luyện dữ liệu để xác định những giá trị ngưỡng và trọng số huấn luyện. Một bộ phân loại “simple” so sánh giá trị của log(P(s|w)) - log(P(w|w)) cho từ gốc w và gợi ý được xếp hạng đầu s , với một giá trị ngưỡng. Nếu không có những gợi ý khác hơn w, thì log(P(s|w)) được bỏ qua. Một bộ phân loại hồi quy logic sử dụng 5 tập đặc trưng. Tập đầu là một đặc trưng xác suất tổ hợp theo thông tin
(i) log(P(s|w)) - log(P(w|w)) cho gợi ý được xếp hạng đầu s.
(ii) LM ghi sự khác nhau giữa từ gốc w và gợi ý đầu s.
(iii) log(P(s|w)) - log(P(w|w)) cho gợi ý được xếp hạng đầu thứ hai s.
(iv) LM ghi sự khác nhau giữa w và s được xếp hạng đầu thứ hai. *
(v) Mã hóa thông tin về dấu đầu dòng, số lượng các gợi ý sẵn có, độ dài ký tự, và số lượng ngữ cảnh trái và phải.
Một số loại ký tự được cho vào danh sách đen và không bao giờ được dự đoán là sai chính tả. Chúng là những số, dấu câu và những ký tự, ký hiệu ký tự đơn. Quy trình huấn luyện gồm 3 giai đoạn:
Ngữ cảnh ghi trọng số được huấn luyện, được miêu tả trong phần 3.3.
Bộ phân loại kiểm tra chính tả được huấn luyện, và điều chỉnh trên dữ liệu phát triển đã lấy ra.
Bộ phân loại sửa tự động được huấn luyện trên những trường hợp với gợi ý mà bộ phân loại kiểm tra chính trả dự đoán là đã sai chính tả, và nó cũng được điều chỉnh trên dữ liệu phát triển đã lấy ra.
Đây là tổng quan về việc phát hiện lỗi và sửa chính tả sử dụng phương pháp nghiên cứu mới dựa trên Web. Chi tiết mọi người có thể tham khảo từ nguồn dưới.
Danh sách tài liệu tham khảo: http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/en/us/pubs/archive/36180.pdf
All rights reserved
