Sử dụng goquery trong golang để crawler thông tin các website Việt Nam bị deface trên mirror-h.org
Bài đăng này đã không được cập nhật trong 5 năm
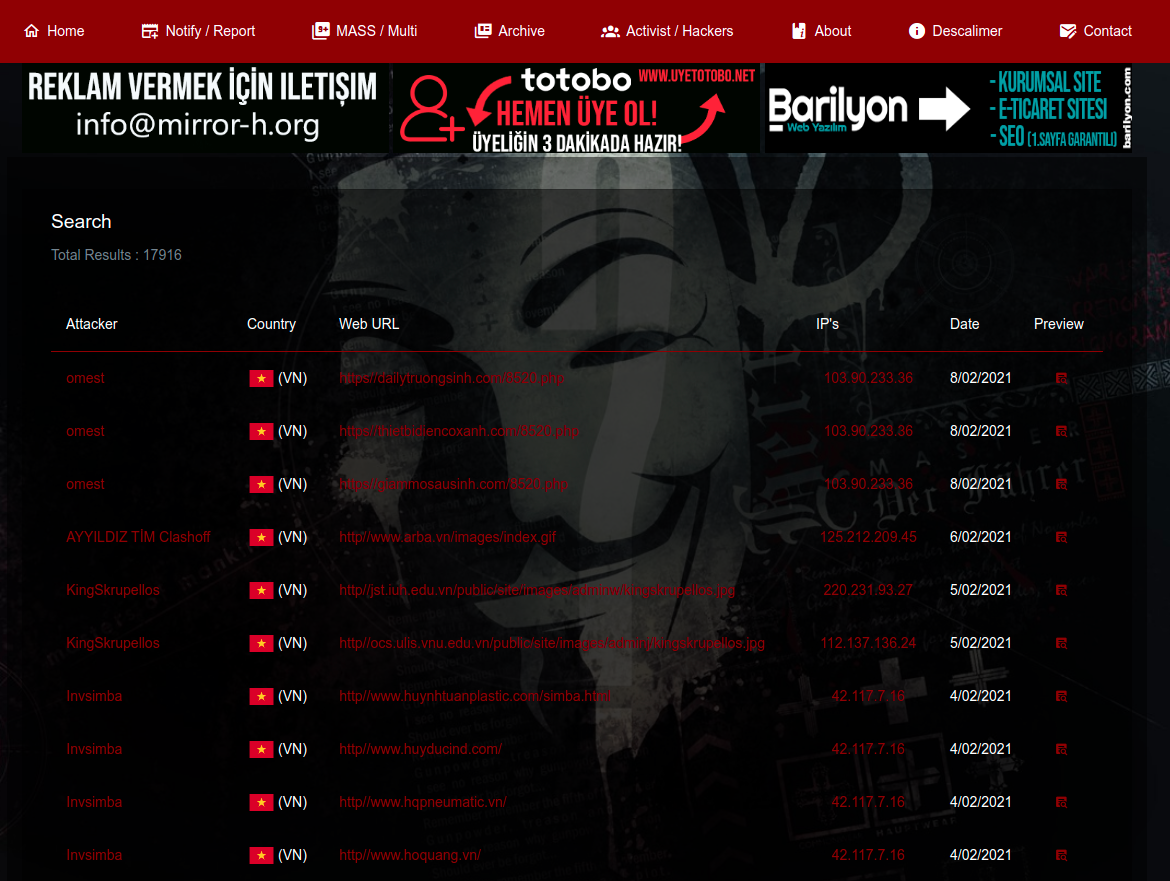
Trong bài viết này, mình sẽ cùng mọi người khám phá một package thu thập dữ liệu có tên là goquery của golang. Mục tiêu chính của chương trình crawler này sẽ là lấy thông tin các website Việt Nam bị deface (là tấn công, phá hoại website, làm thay đổi giao diện hiển thị của một trang web, khi người dùng truy cập vào địa chỉ của trang web đó thì giao diện của một trang web khác sẽ được hiển thị. Thông thường nội dung hiện lên sẽ là các thông điệp mà hacker muốn truyền tải) từ mirror-h (là một kho lưu trữ các website đã bị deface, nơi các website bị deface được ghi danh) và ghi kết quả vào tệp csv.
Các bước thực hiện
- Tính tổng số trang của danh mục.
- Sau khi lấy được tổng số trang, mình sẽ lấy tất cả đối tượng trong từng trang. Việc làm này mình sẽ tận dụng khả năng xử lý đồng thời concurrency của golang lấy đối tượng đồng thời từ các trang.
- Sau khi lấy được dữ liệu, ta lưu lại dữ liệu vào tệp csv.
Cài đặt goquery để phân tích html
go get github.com/PuerkitoBio/goquery
Cài đặt errgroup
- errGroup được sử dụng khi có nhiều goroutines chạy đồng thời, nó sẽ chia các goroutines thành các group. Mỗi group thực hiện 1 phần công việc trong 1 công việc chung. Gói errorGroup cung cấp cơ chế đồng bộ hóa, truyền lỗi và cancel context cho các nhóm goroutines làm nhiệm vụ phụ của một tác vụ chung.
go get golang.org/x/sync/errgroup
- Tạo file crawler.go và khởi tạo các struct để lưu trữ từng mục mà mình crawler:
type Info struct {
Attacker string `json:"attacker"`
Country string `json:"country"`
WebUrl string `json:"web_url"`
Ip string `json:"ip"`
Date string `json:"date"`
}
Tính tổng số trang của danh mục
- Để lấy tổng số trang của danh mục chỉ cần biết được trang cuối cùng của danh mục là trang số bao nhiêu? mình sẽ dùng goquery để bóc tách
<ul class="pagination">để lấy ra thuộc tính href của thẻ <a> trongli:last-childtức là lấy ra đường link của trang cuối cùng.
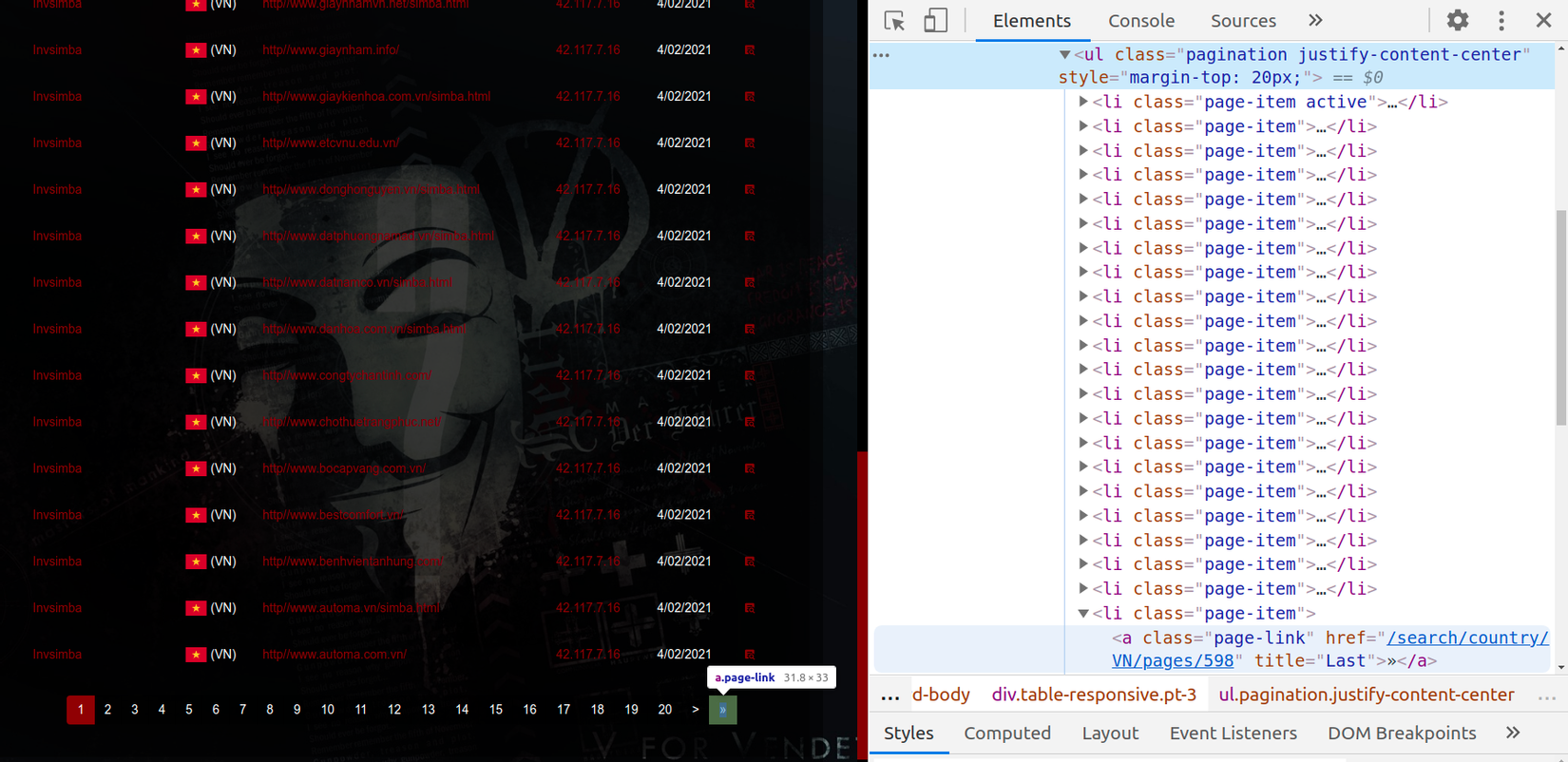
- Sau khi lấy được link của trang cuối cùng mình sẽ xử lý cắt chuỗi để lấy ra trang cuối cùng cũng chính là tổng số trang. Trong ví dụ này, mình lấy được link của trang cuối là:
https://mirror-h.org/search/country/VN/pages/598vậy số trang sẽ là 598
const url = "https://mirror-h.org/search/country/VN/pages"
func totalPage() int {
doc, err := goquery.NewDocument(url)
if err != nil {
log.Println(err)
}
lastPageLink, _ := doc.Find("ul.pagination li:last-child a").Attr("href")
split := strings.Split(lastPageLink, "/")[5]
totalPages, _ := strconv.Atoi(split)
fmt.Println("totalPage->", totalPages)
return totalPages
}
Lấy tất cả đối tượng trong từng trang
- Sau khi lấy được tổng số trang, mình sẽ lấy tất cả đối tượng trong từng trang bằng cách xác định thẻ html của từng phần tử là gì
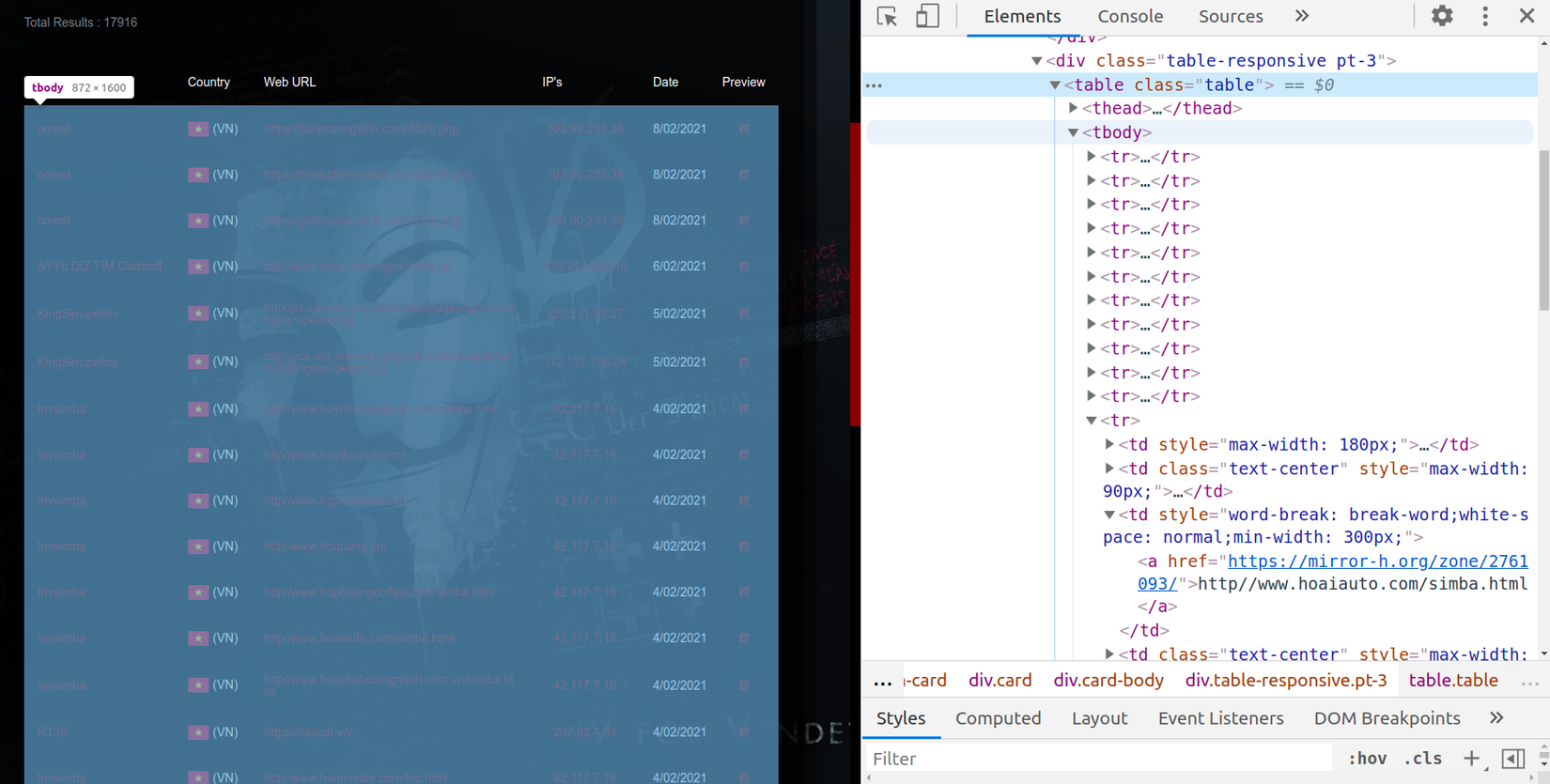
- Thấy rằng các phần tử cần crawler được gói gọn trong 1 bảng có thẻ là <table> chi tiết hơn (đi vào phần tử con của thẻ <table>) là thẻ <tbody>, bên trong thẻ <tbody> là danh sách các hàng chứa phần tử cần crawler nằm trong thẻ <tr>.
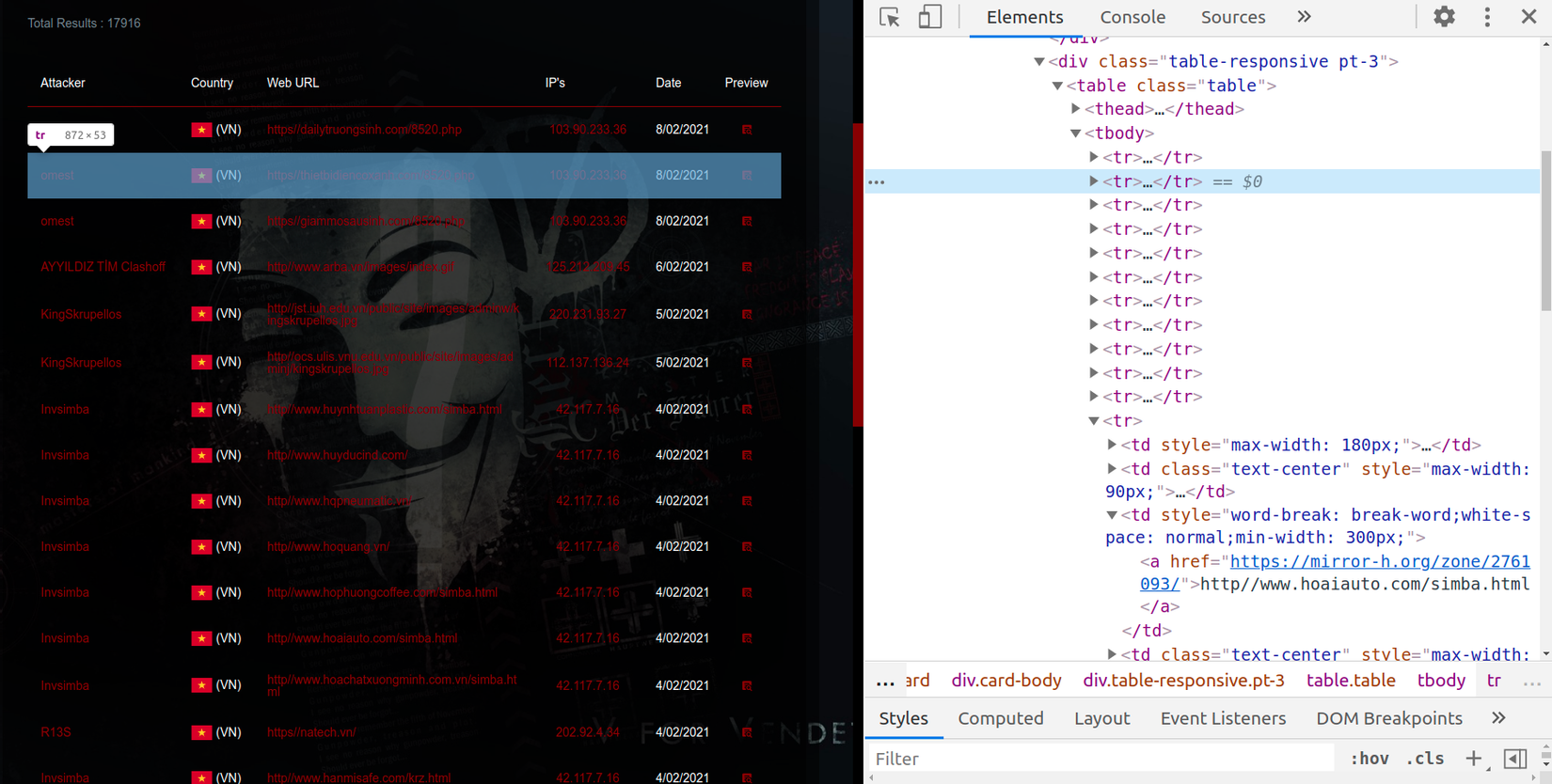
- Ý tưởng là tìm kiếm các phần tử nằm trong phạm vi thẻ <table tbody>, lặp qua các thẻ <tr>, trong từng thẻ <tr> lại bóc tách các phần tử <td> để lấy được đối tượng cần crawler
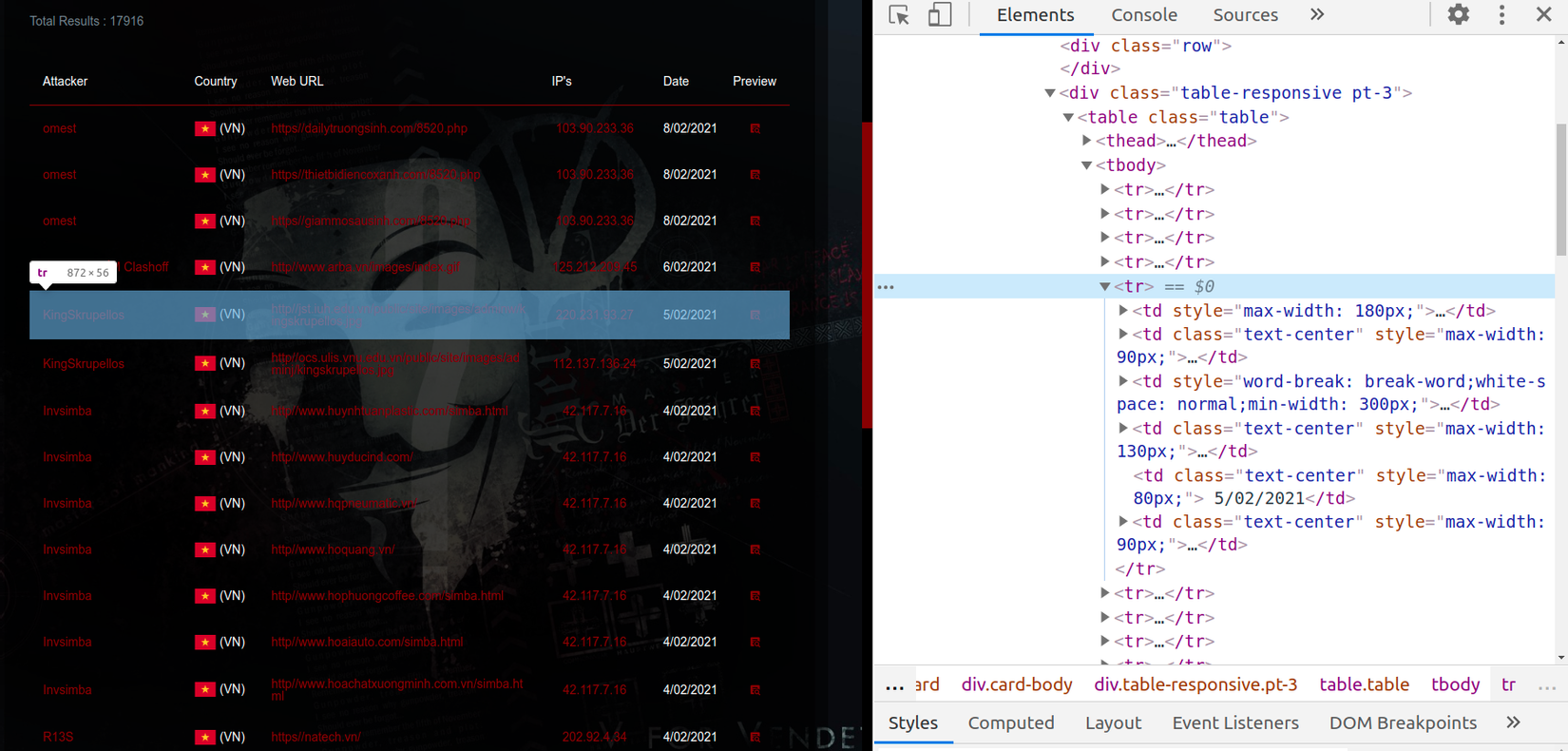
- Mình thực hiện bằng cách chuyển đổi html có dạng bảng sang dạng mảng trong golang với bảng html có dạng sau:
<html>
<body>
<table>
<tbody>
<tr>
<td>Attacker 1, Country 1, WebUrl 1, Ip 1, Date 1</td>
<td>Attacker 2, Country 2, WebUrl 2, Ip 2, Date 2</td>
<td>Attacker 3, Country 3, WebUrl 3, Ip 3, Date 3</td>
<td>Attacker 4, Country 4, WebUrl 4, Ip 4, Date 4</td>
...
<td>Attacker n, Country n, WebUrl n, Ip n, Date n</td>
</tr>
</tbody>
</table>
</body>
</html>
- Lấy phần tử trong 1 trang, tham số đầu vào sẽ là url của trang
- Khi duyệt qua từng phần tử trong thẻ <td>, mình sẽ nối từng phần tử
Attacker n, Country n, WebUrl n, Ip n, Date nvào trong một mảng chuỗi rỗng đã tạo trước đó, như vậy chuỗi mảng sau khi nối có dạng[Attacker n, Country n, WebUrl n, Ip n, Date n]và mình sẽ lấy ra được từng phần tử theo chỉ số (index) của phần tử đó ứng với vị trí index thứ 0 là Attacker, index thứ 1 là Country, index thứ 2 là WebUrl, index thứ 3 là Ip, index thứ 4 là Date. Phần còn lại là làm sạch các phần tử đã lấy được về bằng cách xử lý cắt gọt chuỗi không cần thiết như " (VN)" thành VN
func onePage(pathURL string) ([]Info, error) {
doc, err := goquery.NewDocument(url)
if err != nil {
log.Println(err)
}
infoList := make([]Info, 0)
doc.Find("table tbody").Each(func(index int, tableHtml *goquery.Selection) {
var info Info
tableHtml.Find("tr").Each(func(indexTr int, rowHtml *goquery.Selection) {
row := make([]string, 0)
rowHtml.Find("td").Each(func(ndexTd int, tableCell *goquery.Selection) {
row = append(row, tableCell.Text())
})
info.Attacker = row[0]
info.Country = strings.Replace(strings.Replace(strings.TrimSpace(row[1]), "(", "", -1), ")", "", -1)
info.WebUrl = row[2]
info.Ip = row[3]
info.Date = row[4]
infoList = append(infoList, info)
})
})
return infoList, nil
}
- Các bạn có thể áp dụng cách chuyển đổi html có dạng bảng sang dạng mảng này khi crawler những trang có cấu trúc tương tự.
Lấy đối tượng trong tất cả các trang
- Mình sẽ tận dụng khả năng xử lý đồng thời trong golang bằng việc tạo số lượng goroutines tương ứng với số page đã tính được, như vậy sẽ crawler cùng một lúc đồng thời 598 trang, tốc độ sẽ nhanh hơn nhiều so với việc crawler tuần tự từng trang từ 1 đến 598.
func allPage() {
var totalResults int = 0
totalPage := totalPage()
for page := 1; page <= totalPage; page ++ {
pathURL := fmt.Sprintf("https://mirror-h.org/search/country/VN/pages/%d", page)
group.Go(func() error {
// do work
infoList, err := onePage(pathURL)
if err != nil {
log.Println(err)
}
totalResults += len(infoList)
return nil
})
}
if err := group.Wait(); err != nil {
fmt.Printf("g.Wait() err = %+v\n", err)
}
fmt.Println("crawler done!")
fmt.Println("total results:", totalResults)
}
- Ví dụ của mình crawl một lượng dữ liệu nhỏ, tạo ra 598 goroutines chạy đồng thời tương ứng với tổng số page, nhưng nếu tổng số page là 1 số rất lớn ví dụ 50k thì sao? Mặc dù goroutines trong golang rất nhẹ, chạy tốn rất ít tài nguyên (chỉ tốn khoảng 2Kb trong stack) nhưng nếu số lượng goroutines chạy đồng thời quá nhiều, thực thi nhiệm vụ phức tạp, nặng nề có thể gây nguy cơ tốn kém bộ nhớ, mất mát dữ liệu, bị deadlock giữa chừng, ... Lúc đó cần xem xét việc giới hạn số lượng goroutines chạy đồng thời cùng một lúc. Giải pháp là sử dụng semaphore trong golang. Code thay đổi như sau:
func allPage() {
sem := semaphore.NewWeighted(int64(runtime.NumCPU())) // 8 luồng CPU
group, ctx := errgroup.WithContext(context.Background())
var totalResults int = 0
totalPage := totalPage()
for page := 1; page <= totalPage; page ++ {
pathURL := fmt.Sprintf("https://mirror-h.org/search/country/VN/pages/%d", page)
err := sem.Acquire(ctx, 1)
if err != nil {
fmt.Printf("Acquire err = %+v\n", err)
continue
}
group.Go(func() error {
defer sem.Release(1)
// do work
infoList, err := onePage(pathURL)
if err != nil {
log.Println(err)
}
totalResults += len(infoList)
return nil
})
}
if err := group.Wait(); err != nil {
fmt.Printf("g.Wait() err = %+v\n", err)
}
fmt.Println("crawler done!")
fmt.Println("total results:", totalResults)
}
- Dòng
sem := semaphore.NewWeighted(int64(runtime.NumCPU()))khởi tạo semaphore theo số luồng CPU (máy của mình là 8). Cácsem.Acquirehoạt động như một khóa và chặn các goroutines.sem.Releasemở khóa để các goroutines có thể tiếp tục công việc của mình. - Với cách này sẽ chỉ có 8 goroutines chạy đồng thời tương ứng với crawler đồng thời 8 page, khi hoàn thành crawler 8 page đó thì 8 page sau tiếp tục được crawler đồng thời cho đến khi crawler hết số lượng page. Các bạn có thể để ý trong ảnh dưới đây thời gian 00:12:35 có 8 page được crawler đồng thời bằng với số goroutines được tạo ra. Bạn cũng có thể tăng số lượng goroutines lên tùy theo nhu cầu của bạn theo công thức x*(runtime.NumCPU()).
- Bạn có thể thấy tổng số đối tượng crawler về được ở dòng
total results: 17916đúng với số lượng trên trang mirror-h tại thời điểm mình crawler (08/02/2021)

Ghi kết quả vào tệp csv
- Sau khi lấy được thông tin các trang web thì mình cần triển khai một cách để lưu trữ nó. Trong phần này, mình sẽ hướng dẫn bạn cách ghi dữ liệu vào tệp CSV. Tất nhiên, nếu bạn muốn lưu trữ dữ liệu theo cách khác, hãy thoải mái làm điều đó. Mình tạo một tệp có tên info_web_deface.csv và tạo ra các cột
Attacker, Country, Web Url, Ip, Date
func allPage() {
fileName := "info_web_deface.csv"
file, err := os.Create(fileName)
if err != nil {
log.Fatalf("Could not create %s", fileName)
}
defer file.Close()
writer := csv.NewWriter(file)
defer writer.Flush()
writer.Write([]string{"Attacker", "Country", "Web Url", "Ip", "Date"})
sem := semaphore.NewWeighted(int64(runtime.NumCPU())) // Tạo ra số lượng group goroutines bằng số luồng CPU (8), cùng đồng thời đi thu thập thông tin
group, ctx := errgroup.WithContext(context.Background())
var totalResults int = 0
totalPage := totalPage()
for page := 1; page <= totalPage; page ++ { // Lặp qua từng trang đã được phân trang
pathURL := fmt.Sprintf("https://mirror-h.org/search/country/VN/pages/%d", page) // Tìm ra url của từng trang bằng cách nối chuỗi với số trang
err := sem.Acquire(ctx, 1)
if err != nil {
fmt.Printf("Acquire err = %+v\n", err)
continue
}
group.Go(func() error {
defer sem.Release(1)
// do work
infoList, err := onePage(pathURL) // Thu thập thông tin web qua url của page
if err != nil {
log.Println(err)
}
totalResults += len(infoList)
for _, info := range infoList {
writer.Write([]string{info.Attacker, info.Country, info.WebUrl, info.Ip, info.Date})
}
return nil
})
}
if err := group.Wait(); err != nil { // Error Group chờ đợi các group goroutines done, nếu có lỗi thì trả về
fmt.Printf("g.Wait() err = %+v\n", err)
}
fmt.Println("crawler done!")
fmt.Println("total results:", totalResults)
}
Lặp lại và thử lại http trong golang
- Trong thực tế khi crawler không phải lúc nào kết nối internet cũng thông thoáng thuận lợi đôi khi bị mất kết nối mạng trong 1 khoảng vài giây hay vài phút hoặc hơn, hoặc trang cần crawler bị time out thì việc xử lý chờ đợi để việc crawler được tiếp tục khi mọi thứ trở lại bình thường là hết sức cần thiết nếu không muốn script crawler dừng ngay tại thời điểm sự cố mạng, vì thế mình sẽ tham khảo một cách nho nhỏ để xử lý vấn đề này
- Mình sẽ đặt một mảng các thời gian định trước (tùy hứng hoặc phân tích theo từng đối tượng web) để http được gọi lại sau lần lượt các mốc thời gian đó từ lần thử lại đầu tiên cho đến lần thử lại cuối cùng.
var backoffSchedule = []time.Duration{
10 * time.Second,
15 * time.Second,
20 * time.Second,
25 * time.Second,
30 * time.Second,
}
Cùng sửa lại tận dụng cách thử lại http trên và đoạn mã chương trình cuối cùng trông như thế này:
package main
import (
"context"
"encoding/csv"
"fmt"
"github.com/PuerkitoBio/goquery"
"golang.org/x/sync/errgroup"
"golang.org/x/sync/semaphore"
"log"
"net/http"
"os"
"runtime"
"strconv"
"strings"
"time"
)
const (
url = "https://mirror-h.org/search/country/VN/pages"
errUnexpectedResponse = "unexpected response: %s"
)
type HTTPClient struct{}
var (
HttpClient = HTTPClient{}
)
var backoffSchedule = []time.Duration{
10 * time.Second,
15 * time.Second,
20 * time.Second,
25 * time.Second,
30 * time.Second,
}
func (c HTTPClient) GetRequest(pathURL string) (*http.Response, error) {
req, _ := http.NewRequest("GET", pathURL, nil)
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return nil, err
}
c.info(fmt.Sprintf("GET %s -> %d", pathURL, resp.StatusCode))
if resp.StatusCode != 200 {
respErr := fmt.Errorf(errUnexpectedResponse, resp.Status)
fmt.Sprintf("request failed: %v", respErr)
return nil, respErr
}
return resp, nil
}
func (c HTTPClient) GetRequestWithRetries (url string) (*http.Response, error){
var body *http.Response
var err error
for _, backoff := range backoffSchedule {
body, err = c.GetRequest(url)
if err == nil {
break
}
fmt.Fprintf(os.Stderr, "Request error: %+v\n", err)
fmt.Fprintf(os.Stderr, "Retrying in %v\n", backoff)
time.Sleep(backoff)
}
// All retries failed
if err != nil {
return nil, err
}
return body, nil
}
func (c HTTPClient) info(msg string) {
log.Printf("[client] %s\n", msg)
}
func checkError(err error) {
if err != nil {
log.Println(err)
}
}
type Info struct {
Attacker string `json:"attacker"`
Country string `json:"country"`
WebUrl string `json:"web_url"`
Ip string `json:"ip"`
Date string `json:"date"`
}
func totalPage() int {
response, err := HttpClient.GetRequestWithRetries(url)
checkError(err)
defer response.Body.Close()
doc, err := goquery.NewDocumentFromReader(response.Body)
checkError(err)
lastPageLink, _ := doc.Find("ul.pagination li:last-child a").Attr("href") // Đọc dữ liệu từ thẻ a của ul.pagination
split := strings.Split(lastPageLink, "/")[5]
totalPages, _ := strconv.Atoi(split)
fmt.Println("totalPage->", totalPages)
return totalPages
}
func onePage(pathURL string) ([]Info, error) {
response, err := HttpClient.GetRequestWithRetries(pathURL)
checkError(err)
defer response.Body.Close()
doc, err := goquery.NewDocumentFromReader(response.Body)
checkError(err)
infoList := make([]Info, 0)
doc.Find("table tbody").Each(func(index int, tableHtml *goquery.Selection) {
var info Info
tableHtml.Find("tr").Each(func(indexTr int, rowHtml *goquery.Selection) {
row := make([]string, 0)
rowHtml.Find("td").Each(func(ndexTd int, tableCell *goquery.Selection) {
row = append(row, tableCell.Text())
})
info.Attacker = row[0]
info.Country = strings.Replace(strings.Replace(strings.TrimSpace(row[1]), "(", "", -1), ")", "", -1)
info.WebUrl = row[2]
info.Ip = row[3]
info.Date = row[4]
infoList = append(infoList, info)
})
})
return infoList, nil
}
func allPage() {
fileName := "info_web_deface.csv"
file, err := os.Create(fileName)
if err != nil {
log.Fatalf("Could not create %s", fileName)
}
defer file.Close()
writer := csv.NewWriter(file)
defer writer.Flush()
writer.Write([]string{"Attacker", "Country", "Web Url", "Ip", "Date"})
sem := semaphore.NewWeighted(int64(runtime.NumCPU())) // Tạo ra số lượng group goroutines bằng số luồng CPU (8), cùng đồng thời đi thu thập thông tin
group, ctx := errgroup.WithContext(context.Background())
var totalResults int = 0
totalPage := totalPage()
for page := 1; page <= totalPage; page ++ { // Lặp qua từng trang đã được phân trang
pathURL := fmt.Sprintf("https://mirror-h.org/search/country/VN/pages/%d", page) // Tìm ra url của từng trang bằng cách nối chuỗi với số trang
err := sem.Acquire(ctx, 1)
if err != nil {
fmt.Printf("Acquire err = %+v\n", err)
continue
}
group.Go(func() error {
defer sem.Release(1)
// do work
infoList, err := onePage(pathURL) // Thu thập thông tin web qua url của page
if err != nil {
log.Println(err)
}
totalResults += len(infoList)
for _, info := range infoList {
writer.Write([]string{info.Attacker, info.Country, info.WebUrl, info.Ip, info.Date})
}
return nil
})
}
if err := group.Wait(); err != nil { // Error Group chờ đợi các group goroutines done, nếu có lỗi thì trả về
fmt.Printf("g.Wait() err = %+v\n", err)
}
fmt.Println("crawler done!")
fmt.Println("total results:", totalResults)
}
func main() {
allPage()
}
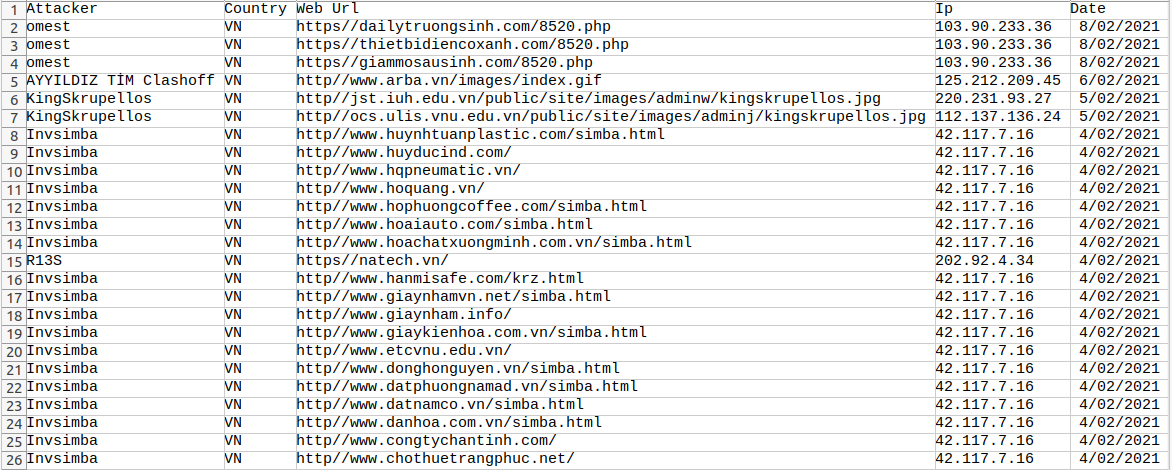
Đây là kết quả mình nhận được khi chạy chương trình, sẽ có một tệp mới trong thư mục làm việc. Nếu bạn mở nó bằng excel (hoặc một chương trình tương tự), thì nó sẽ trông như thế này:
Nhận xét
- Trên đây là một ví dụ để các bạn có thêm một lựa chọn khi crawler các dữ liệu trên internet bên cạnh các framework, thư viện nổi tiếng như scrapy, beautifulSoup của python hay colly của golang,...
- Việc crawl một trang bằng cách đọc html thuần có thể sẽ không hoạt động đúng trong 1 số trường hợp như website được load bằng ajax (lúc đọc html sẽ chưa thấy dữ liệu đâu mà crawl cả) hay phải đăng nhập thì mới vào được trang.
- Các bạn có thể phát triển thêm ứng dụng của mình bằng 1 số gợi ý sau đây:
- Đặt lịch tự động crawler sau một khoảng thời gian định trước.
- Thu thập từ nhiều mục khác nhau như lấy hết các thông tin website bị deface trên toàn thế giới thay vì chỉ lấy ở VN.
- Lưu trữ vào cơ sở dữ liệu khác thay vì csv như elasticsearch,... (khuyến khích bạn dùng elasticsearch để lưu trữ dữ liệu crawler với số lượng đối tượng crawler về được như mình là 17916, các bạn sẽ thấy tốc độ crawler rất nhanh còn chưa đến 1 phút), bạn hãy tự thử nghiệm nhé.
- Đây là bài viết đầu tiên của mình trong năm 2021, chúc bạn đọc năm mới vạn sự như ý, có vấn đề gì các bạn bình luận dưới đây để mình cùng thảo luận nhé, cảm ơn các bạn đã đọc.
Mã nguồn
Tài liệu tham khảo
All rights reserved
