Crawl data trong Golang với Goquery
Bài đăng này đã không được cập nhật trong 4 năm
Crawl dữ liệu
Crawl là một việc khá thường gặp trong quá trình phát triển phần mềm. Đó là việc mà ta sử dụng các công cụ (plugins, modules, tools…) để phân tích, bóc tách dữ liệu từ nguồn nội dung để thu thập những thông tin cần thiết phục vụ cho mục đích riêng của chúng ta (có thể lưu vào DB, XML, JSON, CSV...). Chẳng hạn như những công việc lấy tin tức trên báo, lấy thông tin giảm giá, ... đều là 1 dạng crawl. Cách để chúng ta crawl dữ liệu đó là phân tích HTML, đọc các thẻ và rút trích dữ liệu. Mỗi trang nội dung nguồn mà ta cần lấy dữ liệu sẽ có cấu trúc HTML khác nhau, bố cục khác nhau cho nên tùy vào từng website mà ta sẽ có cách phân tích HTML riêng.
Đối với các ngôn ngữ quen thuộc: PHP, Java,... chúng ta có nhiều thư viện sử dụng để crawl dữ liệu, nhưng hôm nay mình xin giới thiệu package Goquery của Golang thông qua 1 ví dụ nho nhỏ.
Ý tưởng
Mình cần thu thập những thông tin cơ bản của các cuốn sách điện tử (ebook) từ website thư viện tài liệu học tập: http://tailieu123.net và lưu vào file JSON. Mình sẽ lấy thông tin ebook thông qua các danh mục.
Hôm nay, với mục đích chính là giới thiệu công cụ crawl data - Goquery nên mình sẽ chỉ lấy hết ebook trong 1 danh mục. Các bạn có thể phát triển thêm bằng cách lấy hết ebook trong tất cả danh mục.
Trong danh mục, do có nhiều tài liệu nên dữ liệu đã được phân trang. Ý tưởng là mình sẽ lấy hết ebook thông qua từng page được hiển thị.
Các bước thực hiện
1. Tính tổng số trang của danh mục. 2. Sau khi lấy được tổng số trang, ta sẽ lấy tất cả ebook trong từng trang. Việc làm này mình sẽ tận dụng khả năng xử lý đồng thời concurrency của Go lấy ebook đồng thời từ các trang. 3. Sau khi lấy được dữ liệu, ta lưu lại dữ liệu vào file output.json.
Cài đặt
- Đầu tiên, bạn cần cài đặt Golang, bạn có thể tham khảo tại đây.
- Cài đặt packge Goquery để phân tích HTML:
go get github.com/PuerkitoBio/goquery
- Cài đặt package errorGroup: Được sử dụng khi chúng ta có nhiều goroutines chạy đồng thời, nó sẽ chia các goroutines thành các group. Mỗi group thực hiện 1 phần công việc trong 1 công việc chung. Gói errorGroup cung cấp cơ chế đồng bộ hóa, truyền lỗi và cancel context cho các nhóm goroutines làm nhiệm vụ phụ của một tác vụ chung. Để tìm hiểu sâu hơn, chi tiết hơn về package này, bạn có thể tham khảo tại đây.
go get golang.org/x/sync/errgroup
Code
- Tạo file main.go và khởi tạo các struct & function cần thiết:
package main
import (
"fmt"
"flag"
)
type Ebook struct {
URL string `json:"url"`
Title string `json:"title"`
Image string `json:"image"`
}
type Ebooks struct {
TotalPages int `json:"total_pages"`
TotalEbooks int `json:"total_ebooks"`
List []Ebook `json:"ebooks"`
}
func NewEbooks() *Ebooks {
return &Ebooks{}
}
func checkError(err error) {
if err != nil {
log.Println(err)
}
}
func main() {
ebooks := NewEbooks() // Khởi tạo con trỏ trỏ đến giá trị của ebook
}
- Ta cần đầu vào là URL của danh mục nên chúng ta sẽ truyền nó trong command line arguments:
func main() {
flag.Parse()
args := flag.Args()
if len(args) < 1 {
fmt.Println("Please specify start page")
os.Exit(1)
}
currentUrl := args[0] // Đây là biến lấy ra URL mà bạn muốn crawl data
fmt.Println(currentUrl)
}
Sau đó, ta có thể chạy command line: go run main.go http://tailieu123.net/danh-muc-tai-lieu/2-thpt-on-thi-thpt-qg
1. Tính tổng số trang của danh mục.
Việc này khá đơn giản, ta chỉ cần biết được trang cuối cùng của danh mục là trang số mấy? Chúng ta sẽ dùng Goquery để bóc tách <ul class="pagination"> để lấy ra thuộc tính href của thẻ a trong li:last-child tức là lấy ra đường link của trang cuối cùng.
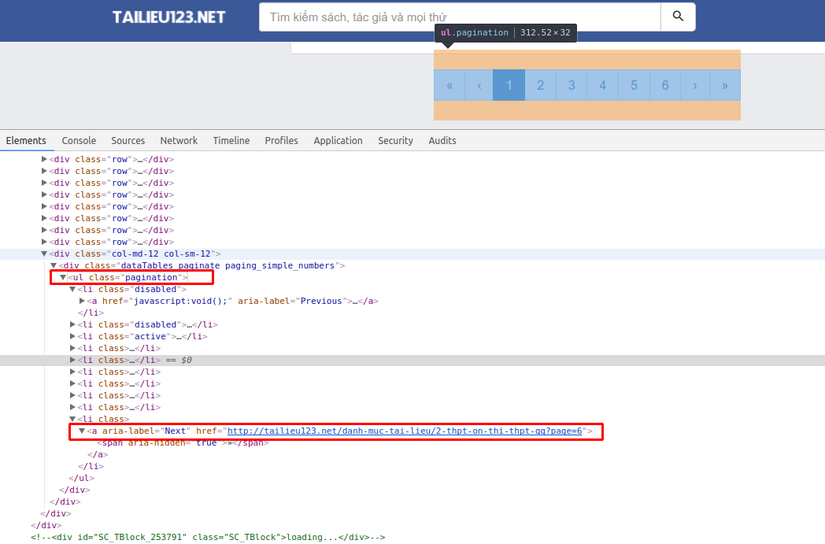 Sau khi lấy được link của trang cuối cùng ta sẽ split nó để lấy ra trang cuối cùng - cũng chính là tổng số trang.
Trong ví dụ này, mình lấy được link của trang cuối là: http://tailieu123.net/danh-muc-tai-lieu/2-thpt-on-thi-thpt-qg?page=6 => Số trang sẽ là 6
Sau khi lấy được link của trang cuối cùng ta sẽ split nó để lấy ra trang cuối cùng - cũng chính là tổng số trang.
Trong ví dụ này, mình lấy được link của trang cuối là: http://tailieu123.net/danh-muc-tai-lieu/2-thpt-on-thi-thpt-qg?page=6 => Số trang sẽ là 6
func (ebooks *Ebooks) GetTotalPages(url string) error {
doc, err := goquery.NewDocument(url)
if err != nil {
return err
}
lastPageLink, _ := doc.Find("ul.pagination li:last-child a").Attr("href") // Đọc dữ liệu từ thẻ a của ul.pagination
if lastPageLink == "javascript:void();" { // Trường hợp chỉ có 1 page thì sẽ không có url
ebooks.TotalPages = 1
return nil
}
split := strings.Split(lastPageLink, "?page=")
totalPages, _ := strconv.Atoi(split[1])
ebooks.TotalPages = totalPages
return nil
}
2. Sau khi lấy được tổng số trang, ta sẽ lấy tất cả ebook trong từng trang.
Chúng ta cần xác định thẻ HTML của mỗi ebook là thẻ gì? Ở đây mình đã tìm ra đó là class .2pin trong class .col-left

- Lấy ebook trong 1 trang: Tham số đầu vào sẽ là url của trang.
func (ebooks *Ebooks) getEbooksByUrl(url string) error {
doc, err := goquery.NewDocument(url)
if err != nil {
return err
}
doc.Find(".col-left ._2pin").Each(func(i int, s *goquery.Selection) { // Lặp dữ liệu qua DOM: .col-left ._2pin
docTitle, _ := s.Find(".ellipsis a").Attr("title") // Lấy tiêu đề của ebook
docLink, exists := s.Find(".ellipsis a").Attr("href") // Lấy link của ebook
if !exists {
docLink = "#"
}
docImg, _ := s.Find("a._3if7 img").Attr("src") // Lấy ảnh của ebook
ebook := Ebook { // Gán dữ liệu thu thập được vào struct Ebook
URL: docLink,
Title: docTitle,
Image: docImg,
}
ebooks.TotalEbooks++ // Đếm số ebook
ebooks.List = append(ebooks.List, ebook) // Đẩy ebook đã thu thập được thông tin vào mảng
})
return nil
}
- Lấy ebook trong tất cả các trang: Đến đây, mình sẽ tận dụng khả năng xử lý đồng thời trong Go bằng việc tạo số lượng goroutines tương ứng với số page đã tính được ở bước 1.
func (ebooks *Ebooks) GetAllEbooks(currentUrl string) error {
eg := errgroup.Group{}
if ebooks.TotalPages > 0 {
for i := 1; i <= ebooks.TotalPages; i++ { // Lặp qua từng trang đã được phân trang
uri := fmt.Sprintf("%v?page=%v", currentUrl, i) // Tìm ra url của từng trang bằng cách nối chuỗi: *"url ban đầu + ?page= + số trang"*
// https://golang.org/doc/faq#closures_and_goroutines
eg.Go(func() error { // Tạo ra số lượng group goroutines bằng với số page, cùng đồng thời đi thu thập thông tin ebook
err := ebooks.getEbooksByUrl(uri) // Thu thập thông tin ebook qua url của page
if err != nil {
return err
}
return nil
})
}
if err := eg.Wait(); err != nil { // Error Group chờ đợi các group goroutines done, nếu có lỗi thì trả về
return err
}
}
return nil
}
3. Sau khi lấy được dữ liệu, ta lưu lại dữ liệu vào file output.json. Phần việc còn lại là khá đơn giản, khi dữ liệu mà ta lấy ra đã có kiểu dữ liệu là Ebooks
func main() {
flag.Parse()
args := flag.Args()
if len(args) < 1 {
fmt.Println("Please specify start page")
os.Exit(1)
}
currentUrl := args[0]
ebooks := utilities.NewEbooks() // Khởi tạo ebook
err := ebooks.GetTotalPages(currentUrl) // Lấy tổng số trang đã phân trang
checkError(err)
err = ebooks.GetAllEbooks(currentUrl) // Lấy tất cả ebook
checkError(err)
ebooksJson, err := json.Marshal(ebooks) // Chuyển kiểu dữ liệu Ebooks sang JSON
checkError(err)
err = ioutil.WriteFile("output.json", ebooksJson, 0644) // Ghi dữ liệu vào file JSON
checkError(err)
}
Kết quả mà mình đã thu thập được từ danh mục tài liệu: http://tailieu123.net/danh-muc-tai-lieu/2-thpt-on-thi-thpt-qg
Số trang: 6.
Số ebook: 139.

Đây là toàn bộ source code của mình, các bạn có thể tham khảo thêm.
Nhận xét
- Trên đây chỉ là 1 ví dụ đơn giản để mình giới thiệu đến các bạn về package Goquery của Golang dùng để crawl data.
- Ví dụ của mình crawl 1 lượng dữ liệu nhỏ, chỉ tạo ra 6 goroutines chạy đồng thời. Mặc dù goroutines trong Go rất nhẹ, chạy tốn rất ít tài nguyên (chỉ tốn khoảng 2Kb trong stack) nhưng nếu số lượng goroutines chạy đồng thời quá nhiều, thực thi nhiệm vụ phức tạp, nặng nề có thể gây nguy cơ tốn kém bộ nhớ, mất mát dữ liệu, bị deadlock giữa chừng, ... Lúc đó chúng ta cần xem xét việc giới hạn số lượng goroutines chạy đồng thời.
- Việc crawl một trang bằng cách đọc HTML thuần có thể sẽ không hoạt động đúng trong 1 số trường hợp như: website được load bằng ajax (lúc đọc HTML sẽ chưa thấy dữ liệu đâu mà crawl cả) hay phải login thì mới vào được trang.
- Các bạn có thể phát triển thêm ứng dụng của mình bằng 1 số gợi ý sau đây:
- Thu thập tất cả các danh mục, thay vì mới chỉ thu thập dữ liệu từ 1 danh mục như ví dụ này của mình.
- Thu thập thêm nhiều thông tin khác của ebook nữa như direct link file, tác giả, mô tả, nội dung chứ không chỉ đơn giản là 3 field: title, image, url như ví dụ.
- Setup crontab trên server cho ứng dụng này, ví dụ cứ 30 phút sẽ tự động thu thập dữ liệu 1 lần.
- Sau khi lấy dữ liệu ngoài việc lưu vào DB, XML, JSON, CSV, ... có thể tự động post lên fanpage Facebook, Google Plus, Twitter.
Hy vọng qua ví dụ nhỏ này của mình sẽ giúp ích phần nào đó để các bạn có thể sử dụng Golang để crawl dữ liệu.
Đây là bài viết đầu tay của mình trên Viblo chắc hẳn sẽ có nhiều sai sót cộng với nguồn kiến thức hạn hẹp, mình rất mong nhận được những ý kiến đóng góp của các bạn để những bài viết sau của mình tại Viblo có chất lượng tốt hơn. Mình xin cảm ơn! 
All rights reserved
