Stream và Table trong Apache Kafka:
Bài đăng này đã không được cập nhật trong 3 năm
Đây là series tìm hiểu về các nguyên tắc cốt lõi trong Kafka và các lớp xử lý cũng như cách mà các lớp này tương tác với nhau. Trong phần này, chúng ta bắt đầu với cái nhìn tổng quan về stream và table. Phần tiếp theo sẽ nhìn kỹ hơn vào các lớp xử lý trong Kafka - là hệ thống tập tin phân tán cho stream và table.
Event, stream, và table
Apache Kafka là cái gì? Apache Kafka là một nền tảng stream dữ liệu phân tán. Nó cung cấp rất nhiều chức năng, xây dựng theo nguyên tắc có thể mở rộng , chịu lỗi và đáng tin cậy:
- Nó cho phép bạn gửi (publish) và nhận (subscribe) các events
- Nó cho phép bạn lưu trữ events bao lâu tùy thích
- Nó cho phép bạn xử lý và và phân tích events
Nghe như đây là một công nghệ rất thú vị, nhưng mà events đang nói đến là cái gì mới được!
Event là một sự kiện ghi lại các thông tin cho một sự việc đã xảy ra. Cơ bản nó sẽ chứa thông tin như sự việc đó là gì, xảy ra như thế nào, xảy ra ở đâu và lúc nào. Ví dụ:
- Tên sự kiện: “Ăn sinh nhật”
- Địa điểm tổ chức: “Tại gia”
- Thời gian: “Dec. 3, 2021 at 9:06 a.m.”.
Sự kiện được một nền tảng phát trực tuyến ghi lại thành các luồng sự kiện (event streams). Luồng sự kiện ghi lại tất cả các sự kiện diễn ra theo thứ tự mà nó xuất hiện (Giống như việc bạn xếp hàng mua vé xem phim vậy đó, sự kiện (event) là người mua và hàng đợi chính là event streams)
So sánh với stream, table là nơi chứa trạng thái của một sự việc tại một thời điểm cụ thể nào đó. Một table ví dụ là bảng ghi trạng thái hiện tại của bàn cờ trong một trận đấu cờ vua. Table có thể hiểu là một dạng xem của event stream, và nó được cập nhật liên tục khi có một event mới được tạo.
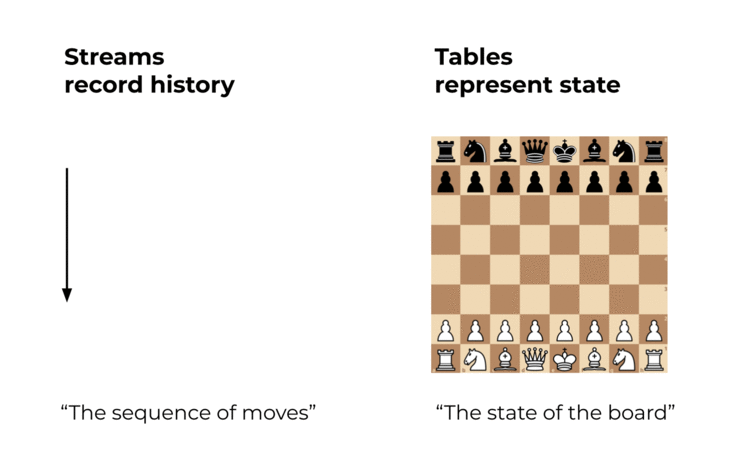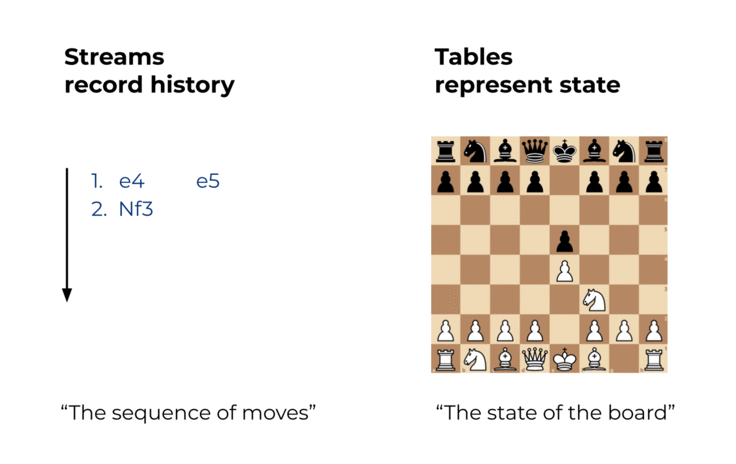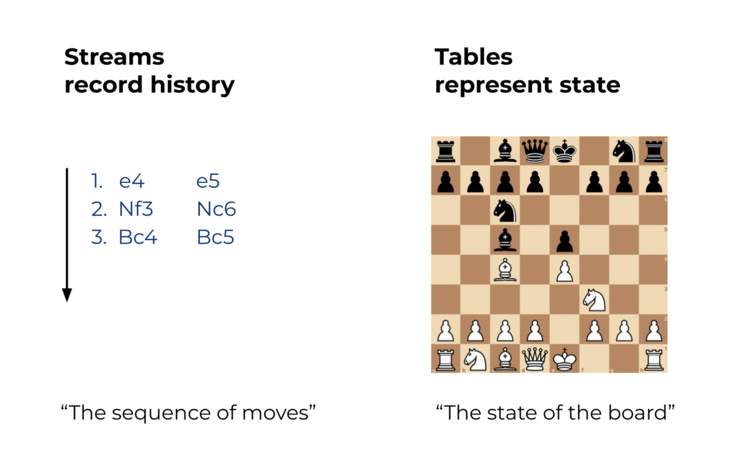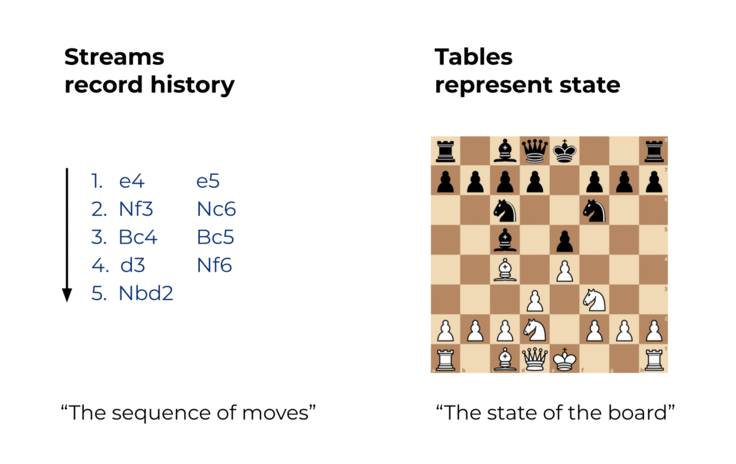
Streams và tables trong Kafka khác nhau theo một số cách, đặc biệt là về việc liệu nội dung của chúng có thể thay đổi được hay không (Nếu bạn là người dùng Kafka Streams: khi mình nói table, mình đề cập đến cái được gọi là KTable trong Kafka Streams. Mình không nói về các state stores mà chúng ta sẽ đề cập ở phần sau)
- Stream cung cấp các data không thể thay đổi (immutable data). Nó chỉ hỗ trợ thêm mới event, trong khi không thể thay đổi, xóa hay sửa các event tồn tại.
- Table thì cho phép thay đổi data. Tức là vừa có thể thêm mới, xóa event hoặc thay đổi, cập nhật các event đang tồn tại
| Stream | Table | |
|---|---|---|
| First event with key bob arrives | Insert | Insert |
| Another event with key bob arrives | Insert | Update |
| Event with key bob and value null arrives | Insert | Delete |
| Event with key null arrives | Insert | <ignored> |
Stream-table duality
Bất chấp sự khác biệt của chúng, chúng ta có thể nhận thấy rằng có một mối quan hệ chặt chẽ giữa Stream và Table. Chúng ta gọi đây là tính hai mặt Stream-table. Điều này có nghĩa là:
- Chúng ta có thể biến Stream thành Table bằng cách tổng hợp Stream với các phép toán như COUNT() hoặc SUM() chẳng hạn. Tương tự cờ vua của chúng ta, chúng ta có thể xây dựng lại trạng thái mới nhất của bàn cờ (table) bằng cách chơi lại tất cả các nước đi đã ghi (Stream).
- Chúng ta có thể biến Table thành Stream bằng cách ghi lại những thay đổi được thực hiện đối với Table — chèn, cập nhật và xóa — thành một “luồng thay đổi”. Quá trình này thường được gọi là thu thập dữ liệu thay đổi hoặc CDC. Trong tương tự cờ vua, chúng ta có thể đạt được điều này bằng cách quan sát nước đi được chơi cuối cùng và ghi lại (vào Stream) hoặc cách khác, bằng cách so sánh trạng thái của bàn cờ (Table) trước và sau nước đi cuối cùng và sau đó ghi lại sự khác biệt của những gì đã thay đổi ( vào Stream), mặc dù tùy chọn này có thể chậm hơn tùy chọn đầu tiên.
Trên thực tế, Table được xác định đầy đủ bởi luồng thay đổi cơ sở của nó. Nếu bạn đã từng làm việc với cơ sở dữ liệu quan hệ như Oracle hoặc MySQL, thì những luồng thay đổi này cũng tồn tại ở đó! Tuy nhiên, ở đây, chúng là một chi tiết triển khai ẩn — mặc dù là một chi tiết hoàn toàn quan trọng — và có các tên như redo log hoặc binary log. Trong event streaming, redo log không chỉ là một chi tiết triển khai. Đó là một thực thể hạng nhất: một luồng. Chúng ta có thể biến luồng (Stream) thành bảng (Table) và bảng (Table) thành luồng (Stream), đó là một lý do tại sao chúng ta nói rằng event streaming và Kafka đang chuyển cơ sở dữ liệu từ trong ra ngoài.
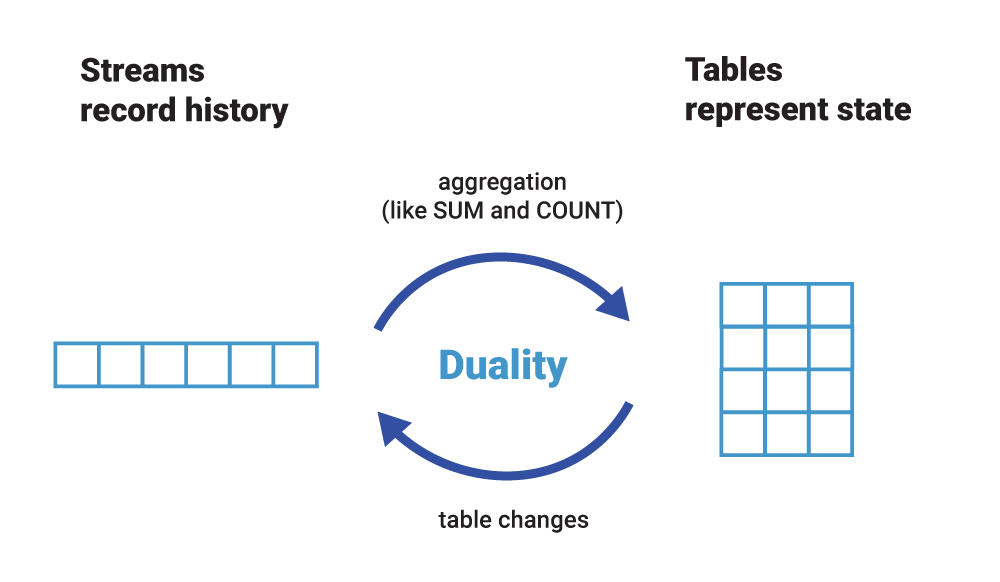
Figure 2: Do tính hat mặt stream-table, chúng ta có thể dễ dàng biến một luồng thành một bảng và ngược lại. Thậm chí, chúng ta có thể thực hiện việc này một cách liên tục, event streaming để cả luồng và bảng luôn được cập nhật các sự kiện mới nhất.
Dưới đây là ví dụ về việc sử dụng COUNT() để tổng hợp một luồng vào một bảng. Vì lý do minh họa, mình không hiển thị dấu thời gian của sự kiện. Bảng liên tục được cập nhật khi các sự kiện mới đến trong luồng, tương tự như một dạng xem cụ thể hóa trong cơ sở dữ liệu quan hệ, nhưng nó hỗ trợ hàng triệu sự kiện mỗi giây. Hãy coi điều này giống như việc thực hiện CDC trên một bảng tạo ra một dòng thay đổi đầu ra của bảng. Thực hiện tổng hợp trên một luồng sự kiện thì ngược lại: luồng đóng vai trò là luồng thay đổi đầu vào cho bảng.

Chúng ta có thể nhìn khai quát hơn ví dụ COUNT() để cũng hiển thị luồng thay đổi (đầu ra) của bảng. Luồng thay đổi có thể được sử dụng để phản ứng trong thời gian thực với các thay đổi của bảng, chẳng hạn, để tạo cảnh báo. Nó cũng có thể được sử dụng cho các mục đích hoạt động, chẳng hạn như di chuyển bảng từ máy A sang máy B trong trường hợp cơ sở hạ tầng bị lỗi hoặc khi mở rộng một cách đàn hồi một ứng dụng vào và ra.
 Chúng ta sẽ quay trở lại khái niệm hai mặt stream-table ở phần sau của loạt bài này, vì nó không chỉ hữu ích khi viết các ứng dụng của riêng bạn mà còn rất cơ bản đến mức Kafka tận dụng nó để có khả năng mở rộng đàn hồi và khả năng chịu lỗi, có thể kể đến một vài cái tên!
Chúng ta sẽ quay trở lại khái niệm hai mặt stream-table ở phần sau của loạt bài này, vì nó không chỉ hữu ích khi viết các ứng dụng của riêng bạn mà còn rất cơ bản đến mức Kafka tận dụng nó để có khả năng mở rộng đàn hồi và khả năng chịu lỗi, có thể kể đến một vài cái tên!
Kết luận
Phần này hoàn thành phần đầu tiên của loạt bài này, nơi chúng ta đã tìm hiểu về các yếu tố cơ bản của nền tảng phát trực tuyến sự kiện: sự kiện, luồng và bảng. Chúng ta cũng đã giới thiệu tính hai mặt của bảng truyền trực tuyến và có cái nhìn đầu tiên về lý do tại sao nó là trung tâm của một nền tảng phát trực tuyến sự kiện như Apache Kafka. Nhưng tất nhiên, đây chỉ là sự khởi đầu! Phần 2 sẽ đi sâu vào các chủ đề, phân vùng và nguyên tắc cơ bản về lưu trữ của Kafka, nơi chúng ta khám phá các chủ đề và — theo ý kiến của mình, khái niệm quan trọng nhất trong Kafka: phân vùng.
All rights reserved
