Solving problems with Swift - [Very] simple data compression
Bài đăng này đã không được cập nhật trong 8 năm
Introduction
Tiết kiệm không gian lưu trữ luôn luôn là một việc nên làm. Nếu bạn ở một mình, nhưng lại thuê một căn phòng quá lớn, bạn nên chọn chuyển sang một căn phòng nhỏ hơn với một chi phí gần như chắc chắn sẽ rẻ hơn. Nếu bạn sử dụng những dịch vụ lưu trữ trực tuyến tính tiền theo dung lượng, bạn sẽ muốn dữ liệu của mình càng nhỏ càng tốt, vì nó sẽ tiết kiệm chi phí hàng tháng hơn.
Trong khoa học máy tính, nén (compression) là một quá trình lấy dữ liệu đầu vào, encode (thay đổi dạng) dữ liệu bằng cách nào đó để nó chiếm ít không gian bộ nhớ hơn. Còn giải nén (Decompression) là một quá trình ngược lại, sẽ biến đổi dữ liệu đang ở trạng thái nén thành dạng dữ liệu nguyên thuỷ ban đầu.
Nếu như những ví dụ trên, việc nén dữ liệu luôn luôn là một việc nên làm, vậy tại sao tất cả dữ liệu đều không được nén? Như các bạn đã biết, việc gì cũng có hai mặt của nó, ở đây là việc đánh đổi giữa hai vấn đề: thời gian và không gian lưu trữ. Với những dữ liệu ở dạng nén, nó cần được giải nén trước khi có thể được sử dụng. Do vậy, nén dữ liệu chỉ thật sự cần thiết khi chúng ta ưu tiên không gian lưu trữ hơn là thời gian thực hiện.
Lấy ví dụ bạn muốn truyền một file lớn qua mạng Internet. Trong trường hợp này, rất dễ để có thể nhận thấy ở đây, không gian lưu trữ sẽ được ưu tiên hơn thời gian thực hiện (do file càng nhỏ thì thời gian truyền qua mạng Internet càng nhanh)
Có rất nhiều thuật toán nén được sử dụng. Tuy nhiên, trong bài này, mình sẽ đề cập đến một cách tiếp cận trước khi bạn nghĩ đến những thuật toán đó. Đó chính là xem xét thật kĩ dạng dữ liệu mà bạn sử dụng. Bản thân mình trước đây mỗi khi gặp bài tập nào liên quan đến nén dữ liệu thường là sẽ tham khảo luôn là có thuật toán nào áp dụng trên cấu trúc dữ liệu mình đang sử dụng, nhưng sau một thời gian, mình nhận thấy nên xem xét bản thân dữ liệu của mình trước, xử lý chúng trước khi áp dụng bất cứ thuật toán nào, điều đó sẽ khiến việc nén dữ liệu trở nên hiệu quả hơn rất nhiều.
Làm sao để có thể xem xét được dạng dữ liệu nào nên sử dụng? Không có gì khó, bạn chỉ cần nhìn vào kích cỡ của kiểu dữ liệu bạn đang dùng và những giá trị thực tế bạn sử dụng. Nói hơi lằng nhằng, mình sẽ lấy một ví dụ nho nhỏ:
Trong Swift, nếu một số nguyên không dấu (unsigned integer) mà bạn dám chắc rằng nó không bao giờ vượt quá giá trị 65535 nhưng lại được lưu ở kiểu UInt (là một kiểu số nguyên không dấu có cỡ 64bit) sẽ là một cách lưu trữ thiếu hiệu quả. Thay vào đó, nó nên được lưu kiểu UInt16 (là một kiểu số nguyên không dấu có cỡ 16bit). Điều này sẽ khiến không gian lưu trữ của bạn tiết kiệm tới 75% (16bit vs 64bit). Nghe bit thì nhỏ, nhưng tưởng tượng một chuơng trình lớn có hàng nghìn biến, thì bạn đang leak mất rất nhiều MB bộ nhớ.
OK, để có thể hiểu rõ hơn về hướng tiếp cận này, chúng ta sẽ cùng đi qua một ví dụ cụ thể sau
Compressing ADN
ví dụ này mình tham khảo ở cuốn: Algorithm, 4th Edition của tác giả Robert Sedgewick và Kevin Wayne
Nếu số lượng những giá trị có thể có của một kiểu dữ liệu lớn hơn những giá trị mà nó đang lưu, thì thường là chúng ta có thể tối ưu chúng, hãy xem xét ví dụ dưới đây:
Chúng ta đều biết một chuỗi ADN đều được tạo bởi rất nhiều các nucleotides, mỗi nucleotides có thể nhận 1 trong 4 giá trị sau: A, C, G, T. Như vậy, bạn thử suy nghĩ xem, để có thể lưu trữ một chuỗi ADN, chúng ta sẽ lưu trữ như thế nào?
Có lẽ đa phần chúng ta sẽ lưu trữ như thế này:
ACGTGCATTCGA....
Như vậy, trong trường hợp này, chúng ta đang lưu trữ gene dưới dạng một chuỗi (String), là một tập hợp của nhiều các kí tự (characters), mỗi nucleotide sẽ đựoc biểu thị bằng một kí tự.
Tạm dừng một chút, bạn có nhận ra vấn đề gì ở đây không? (hãy thử liên kết những gì mình đã đề cập suốt từ đầu bài đến bây giờ nhé)
OK, vấn đề ở đây chính là kiểu dữ liệu chúng ta lựa chọn để lưu trữ, hãy cùng tìm hiểu sâu hơn:
Trong Swift, mỗi kiểu kí tự (characters) có kích cỡ là 8bit, như vậy, sử dụng kiểu characters, chúng ta có thể lưu trữ tới 2^8 = 256 giá trị khác nhau, nhưng ở đây chúng ta chỉ cần lưu 4 giá trị khác nhau mà thôi. Vì vậy, sử dụng kiểu dữ liệu nào đó chỉ có khả năng lưu trữ 4 giá trị khác nhau (có kích cỡ 2bit) sẽ là hiệu quả hơn rất nhiều trong trường hợp này (như bạn thấy, chúng ta tiết kiệm được tới 75% với mỗi nucleotide).
Trên tinh thần đó, thay vì lưu trữ nucleotides dưới dạng String, chúng ta sẽ lưu trữ dưới dạng bit string, là một chuỗi dài tùy ý với các giá trị 0 và 1. Tuy nhiên, thư viện chuẩn của Swift lại không hỗ trợ trực tiếp cấu trúc nào để làm việc với bit string, nhưng đừng lo, chúng ta đã có một thư viện C cấp thấp, chính là Core Foundation, chứa đủ những gì chúng ta cần để làm việc. Cụ thể ở đây mình sẽ sử dụng CFMutableBitVector. Mời các bạn xem hình dưới đây để chúng ta thấy được tổng quan quá trình nén và giải nén một chuỗi gene:
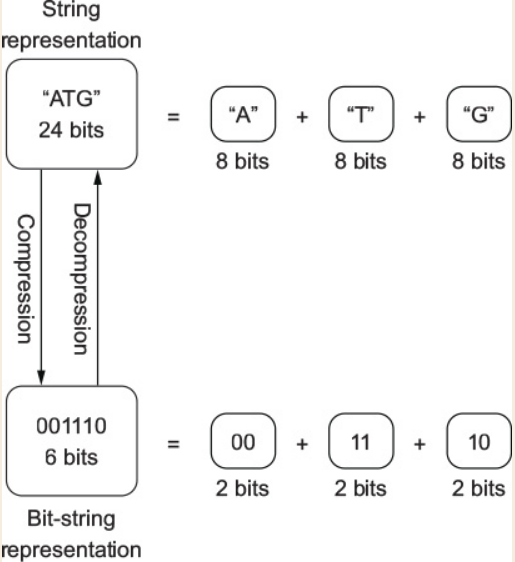
OK, chúng ta có thể tiến hành khởi tạo như sau
struct CompressedGene {
let length: Int
private let bitVector: CFMutableBitVector
init(original: String) {
length = original.count
// cấp phát mặc định, cần 2 * số lượng bits
bitVector = CFBitVectorCreateMutable(kCFAllocatorDefault, length * 2)
CFBitVectorSetCount(bitVector, length * 2) // tạm thời fill bit vector với các giá trị 0
compress(gene: original)
}
}
Như các bạn thấy, ở đây CompressedGene đã lưu một chuỗi các nucleotides dưới dạng bit string. Hàm init có nhiệm vụ khởi tạo cấu trúc CFMutableBitVector và gọi hàm compress để xử lý việc nén dữ liệu
Nói thêm về hàm CFBitVectorCreateMutable(), hàm này nhận 2 tham số là allocator (1 đối tượng cấp phát) và kích cỡ. Vì sao kích cỡ ở đây là lengh * 2? đó là vì chúng ta cần 2 bits cho mỗi nucleotide.
Tiếp theo, chúng ta sẽ xây dựng hàm compress()
private func compress(gene: String) {
for (index, nucleotide) in gene.uppercased().enumerated() {
let nStart = index * 2 // điểm bắt đầu của mỗi nucldeotides
switch nucleotide {
case "A": // 00
CFBitVectorSetBitAtIndex(bitVector, nStart, 0)
CFBitVectorSetBitAtIndex(bitVector, nStart + 1, 0)
case "C": // 01
CFBitVectorSetBitAtIndex(bitVector, nStart, 0)
CFBitVectorSetBitAtIndex(bitVector, nStart + 1, 1)
case "G": // 10
CFBitVectorSetBitAtIndex(bitVector, nStart, 1)
CFBitVectorSetBitAtIndex(bitVector, nStart + 1, 0)
case "T": // 11
CFBitVectorSetBitAtIndex(bitVector, nStart, 1)
CFBitVectorSetBitAtIndex(bitVector, nStart + 1, 1)
default:
print("Unexpected character \(nucleotide) at \(index)")
}
}
}
Hàm compress sẽ đọc từng kí tự trong chuỗi nucleotides, khi gặp kí tự A, nó sẽ thêm 00 vào bit string, tuơng tự với các kí tự còn lại. Kết quả chúng ta nhận được là mỗi kí tự trong chuỗi nucleotides đầu vào sẽ được * 2 để tìm được indẽ của chúng trong chuỗi bit string
Cuối cùng, chúng ta sẽ tạo hàm decompression()
func decompress() -> String {
var gene: String = ""
for index in 0..<length {
let nStart = index * 2 // điểm bắt đầu của mỗi nucleotides
let firstBit = CFBitVectorGetBitAtIndex(bitVector, nStart)
let secondBit = CFBitVectorGetBitAtIndex(bitVector, nStart + 1)
switch (firstBit, secondBit) {
case (0, 0): // 00 A
gene += "A"
case (0, 1): // 01 C
gene += "C"
case (1, 0): // 10 G
gene += "G"
case (1, 1): // 11 T
gene += "T"
default:
break
}
}
return gene
}
Hàm decompress() đọc 2 bit 1 lần trong chuỗi đầu vào. Từ những chuỗi đầu vào, nó sẽ xây dựng nên chuỗi đầu ra giống hệt như chuỗi nguyên thủy trước khi nén.
Conclusion
Vậy là chúng ta đã cùng nhau xây dựng xong một chuơng trình nén/giải nén các chuỗi DNA vô cùng đơn giản. Mặc dù đơn giản, nhưng lại có một số khái niệm và tư tưởng mà mình muốn nhấn mạnh:
- Trong khi nén dữ liệu, hãy tập trung vào việc tối ưu các kiểu dữ liệu lưu trữ trước khi áp dụng những thuật toán nén
- Tận dụng triệt để những khả năng, công cụ mà ngôn ngữ lập trình bạn đang sử dụng
- Sau khi đã áp dụng 2 phương pháp trên, chúng ta hãy sử dụng những thuật toán nén, như vậy, hiệu quả sẽ tăng lên rất rất nhiều
Chúc các bạn thành công!
All rights reserved
